






许多网友表示:SD3难以生成正确的人体(尤其是女性)!比如下图这样的典型案例:

原本指望SD3开源后,能让大家免费用上超越Midjourney或DALL E3的工具,没想到在最关键的人体结构掉链子:


甚至本来已经被逐渐克服的手部表现能力,也开起倒车:
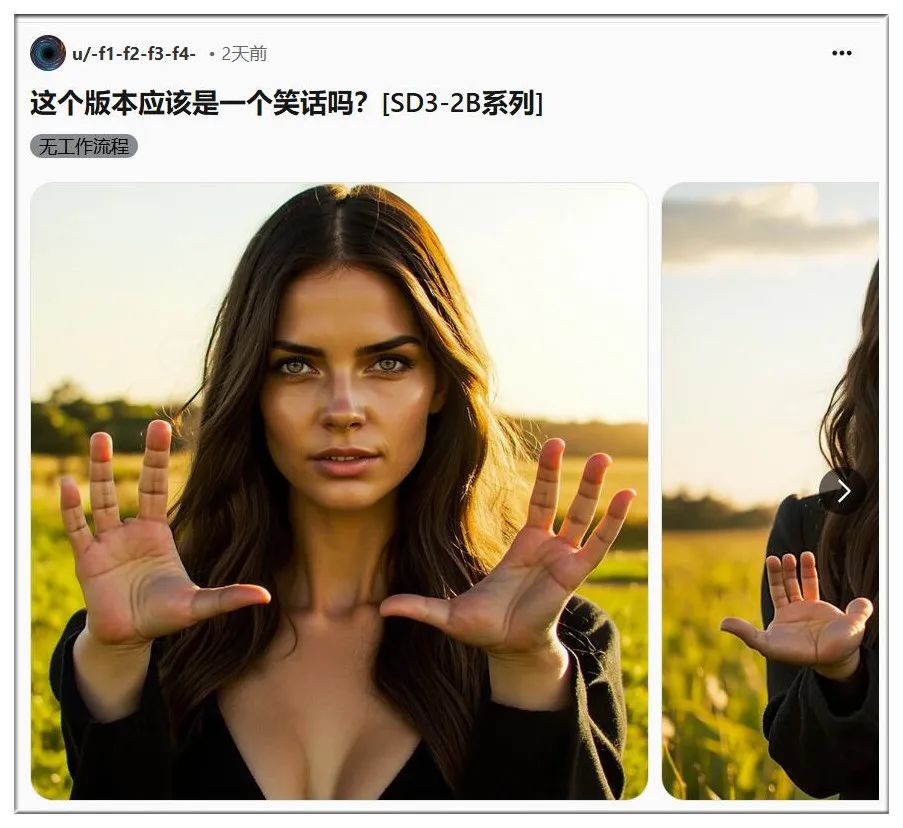

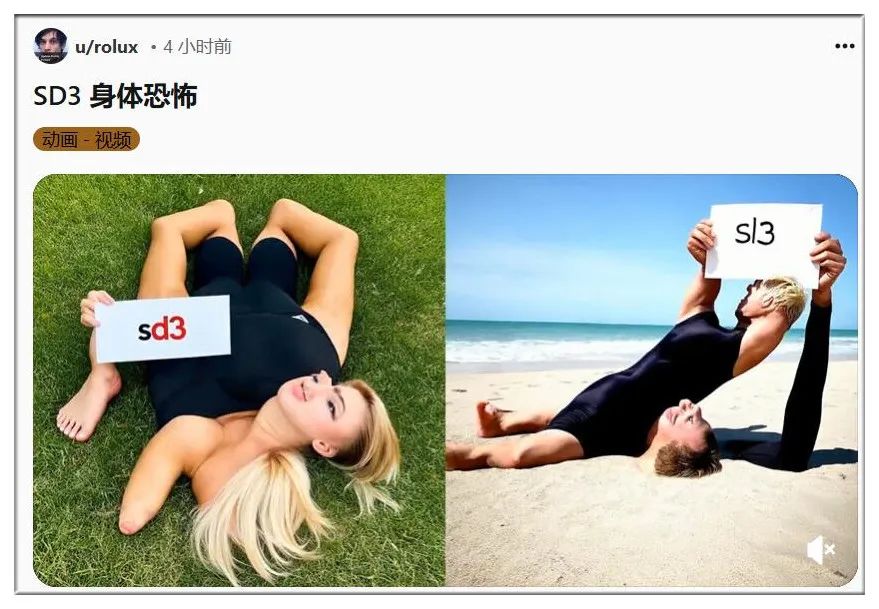
生成正常的图像,可能得到毫无道理的结果:
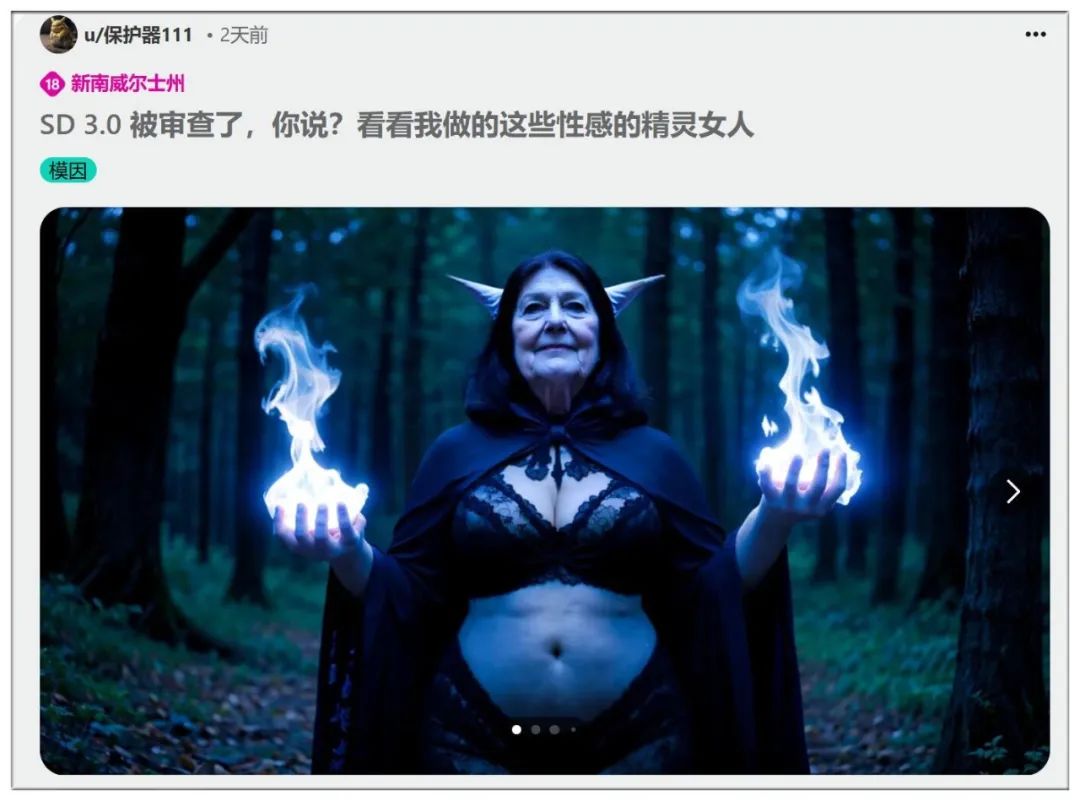
SD3匪夷所思的表现让网友极度失望,发动群嘲:







有人用SDXL和SD3做了“绘制女性”对比,结果SDXL完胜:


即使调用SD3 API(80亿参数),也比本地部署的SD3 Medium(20亿参数)表现好得多:
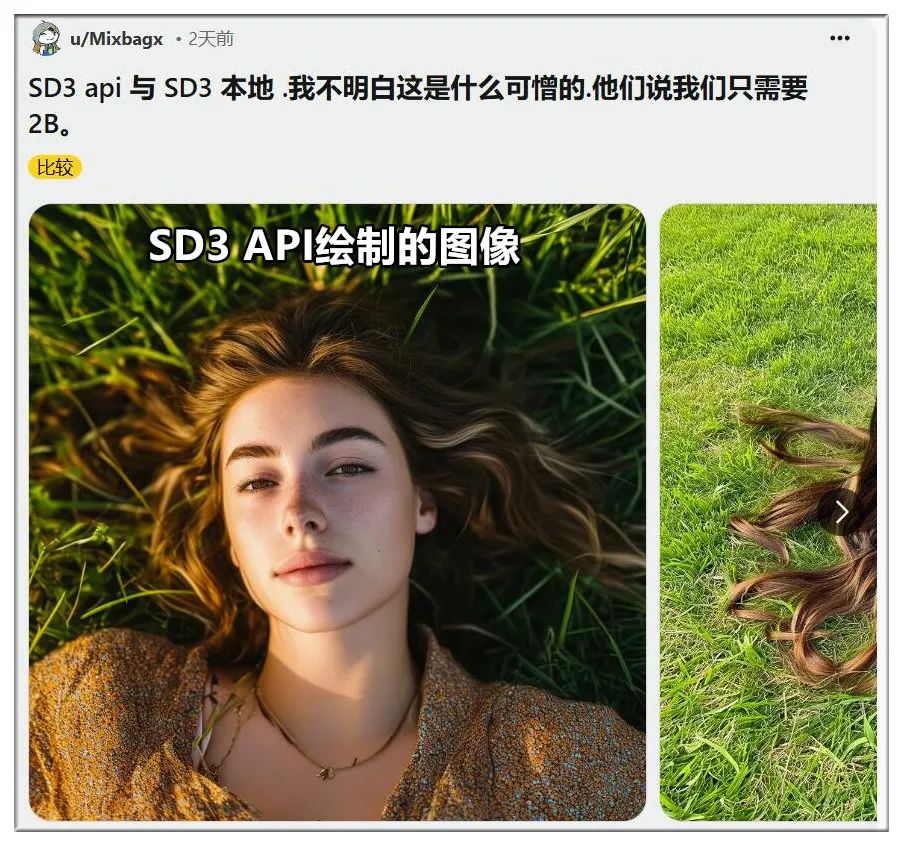

目前为止,网友将问题的原因归咎于Stability AI坚持从SD3训练数据中过滤掉成人内容(即“NSFW”内容)
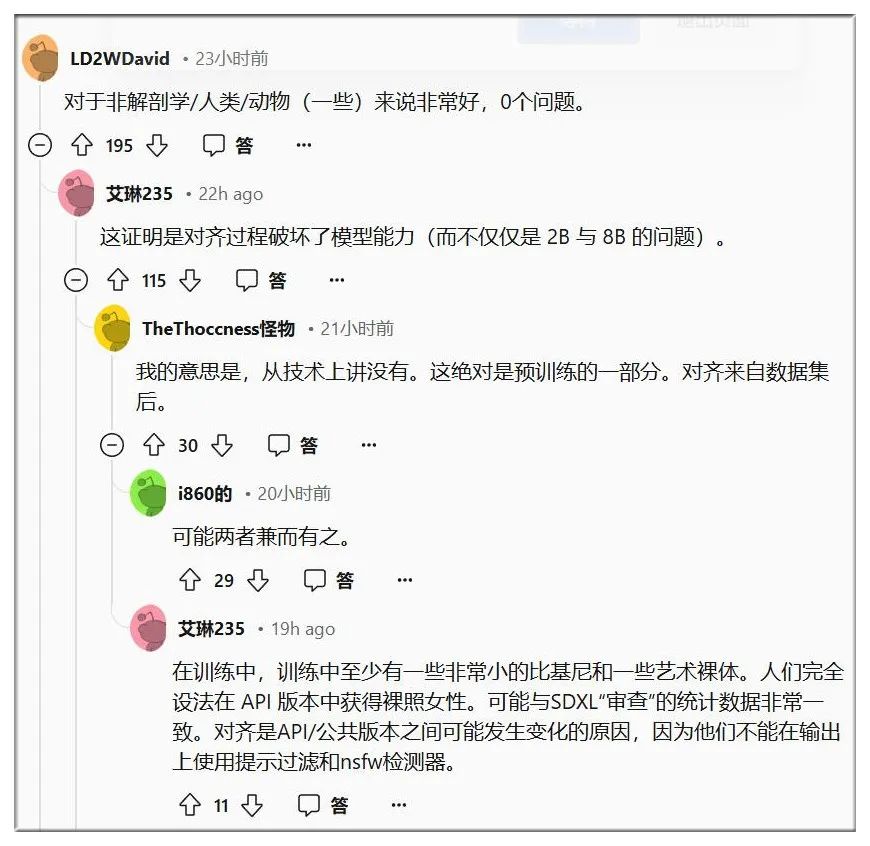
一位AIGC爱好者表示:“严格审查模型也会导致人体结构错误”。
从原理来看,当模型预训练期间,如果研究人员从数据集中删除NSFW的过滤器过于挑剔,可能意外地删除正常的图像,导致只要出现女性的身体描述,就出现问题。

早在2022年发布的SD2.0也有类似情况,后来在SD2.1和SDXL中有所改善,但依然未能完全取代SD1.5(也因此,基于后者的各种模型至今仍然是NSFW内容的主力军)。
“违背人性”的Stability AI一下子从“开源英雄”变成了众矢之的:
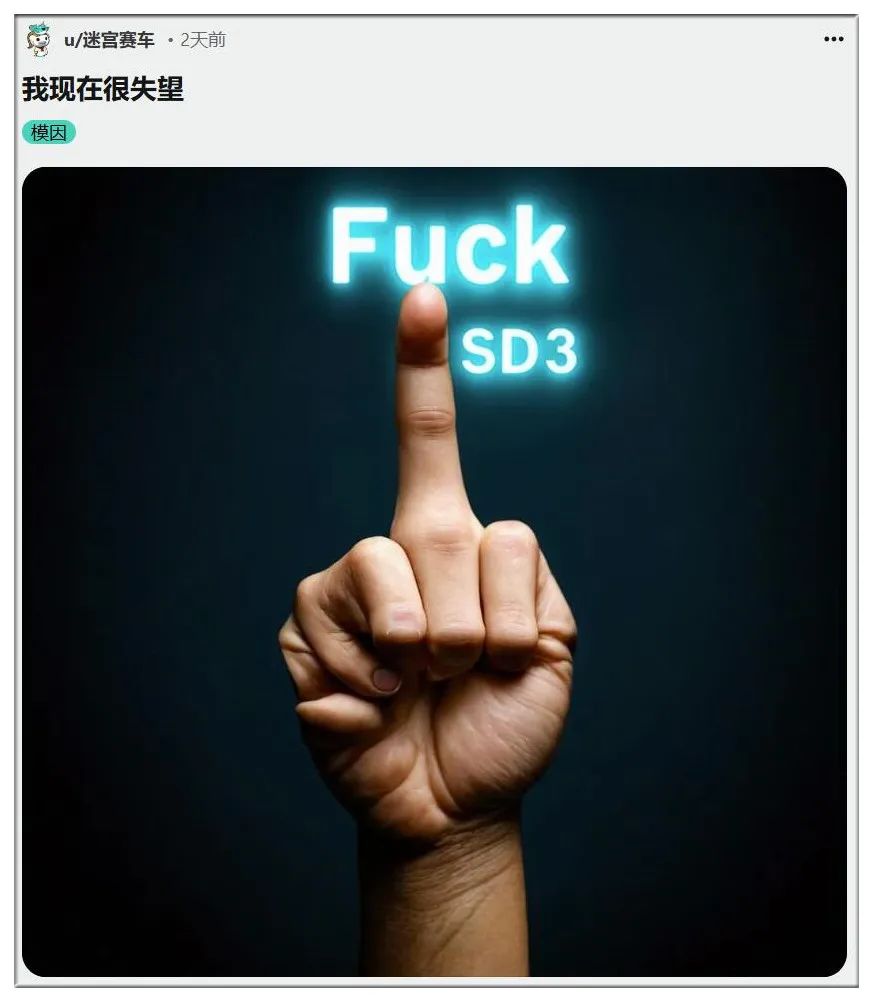


许多网友认为,如果Stability AI继续这样政治正确下去,迟早要“以一种安全和合乎道德的方式破产”。


为了表达讽刺,还有人用快手可灵的图生视频功能,来“拯救”SD3扭曲的人体。

其实公平地讲,除了不能色色,SD3依然是一个强劲的模型,对于提示词的对齐能力相当优秀,尤其是生成场景时:


生成人物,只要不过多暴露身体,并且有耐心慢慢调试提示词,效果也是相当具有质感:
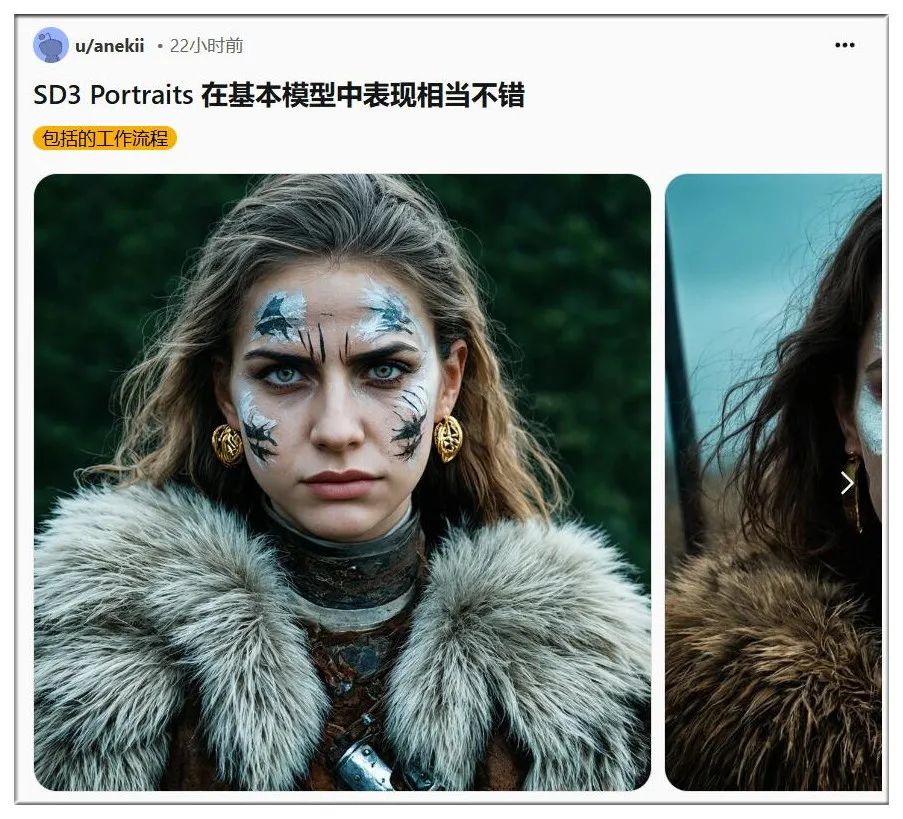
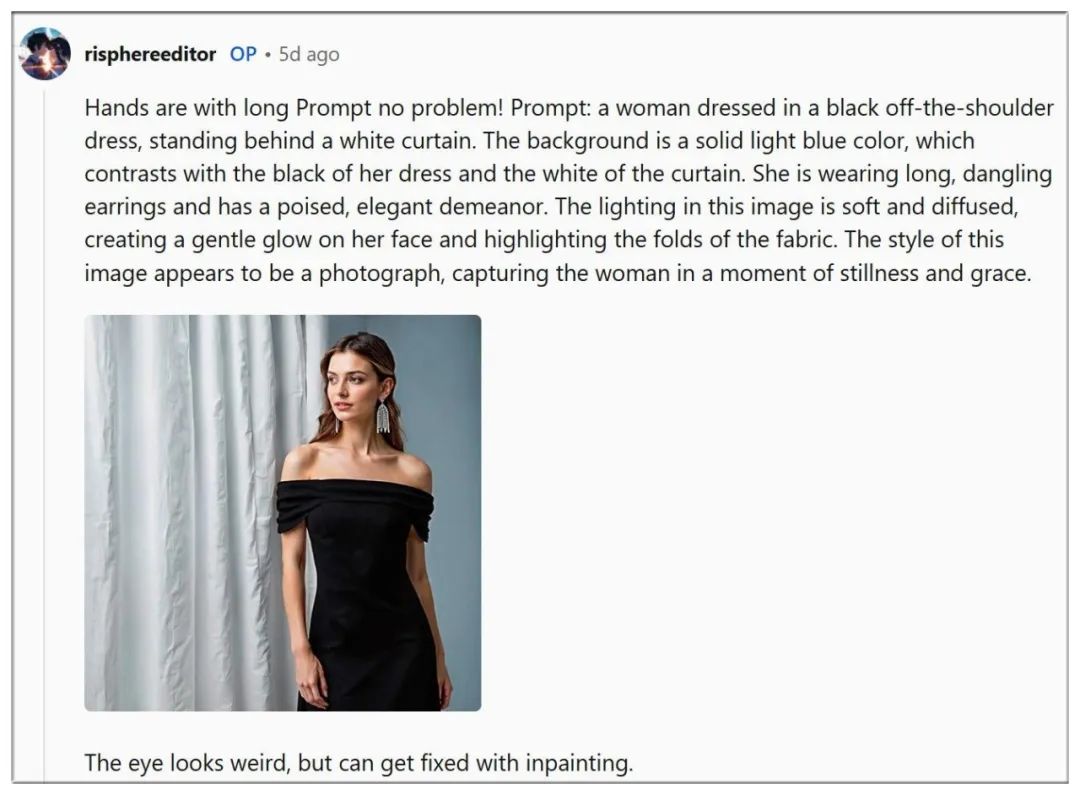

尤其写实人物,已经基本不再有以前那种油腻AI感:
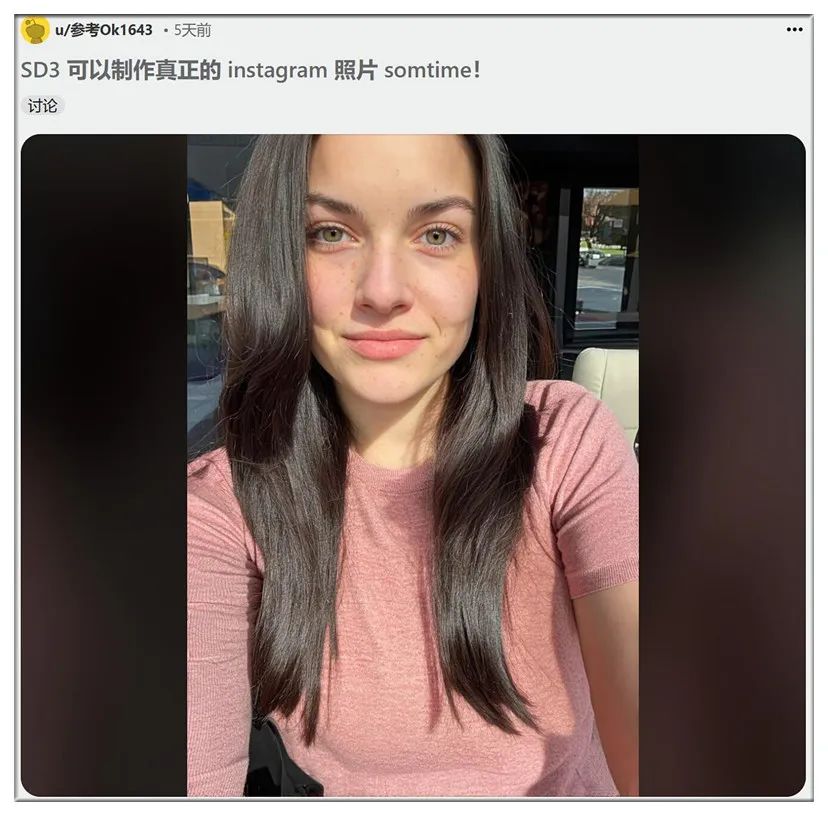
因此一些网友依然对SD3的未来保有信心:


希望他们是对的!

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。

二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的AIGC全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









