






存储容量 = 磁头数 × 磁道(柱面)数 × 每道扇区数 × 每扇区字节数图3中磁盘是一个 3个圆盘6个磁头,7
个柱面(每个盘片7个磁道) 的磁盘,上图中每条磁道有12个扇区,所以此磁盘的容量为:存储容量 6
- 7 12 512 = 258048
每个磁道的扇区数一样是说的老的硬盘,外圈的密度小,内圈的密度大,每圈可存储的数据量是一样 的。新的硬盘数据的密度都一致,这样磁道的周长越长,扇区就越多,存储的数据量就越大。
4、磁盘读取响应时间
1.寻道时间:磁头从开始移动到数据所在磁道所需要的时间,寻道时间越短,I/O操作越快,目前磁 盘的平均寻道时间一般在3-15ms,一般都在10ms左右。
2.旋转延迟:盘片旋转将请求数据所在扇区移至读写磁头下方所需要的时间,旋转延迟取决于磁盘转 速。普通硬盘一般都是7200rpm,慢的5400rpm。
3.数据传输时间:完成传输所请求的数据所需要的时间。
小结一下:从上面的指标来看、其实最重要的、或者说、我们最关心的应该只有两个:寻道时间;旋转 延迟
读写一次磁盘信息所需的时间可分解为:寻道时间、延迟时间、传输时间。为提高磁盘传输效率,软件 应着重考虑减少寻道时间和延迟时间。(类似于CPU缓存行,把随机读改成顺序读写)
5、块/簇
磁盘块/簇(虚拟出来的)。 块是操作系统中最小的逻辑存储单位。操作系统与磁盘打交道的最小单位是磁盘块。每个块可以包括2、4、8、16、32、64…2的n次方个扇区。
为什么存在磁盘块?
读取方便:由于扇区的数量比较小,数目众多在寻址时比较困难,所以操作系统就将相邻的扇区组合在 一起,形成一个块,再对块进行整体的操作。分离对底层的依赖:操作系统忽略对底层物理存储结构的 设计。通过虚拟出来磁盘块的概念,在系统中认为块是最小的单位。(就是类似于班级,小组等)
6、page
操作系统经常与内存和硬盘这两种存储设备进行通信,类似于“块”的概念,都需要一种虚拟的基本单
位。所以,与内存操作,是虚拟一个页的概念来作为最小单位。与硬盘打交道,就是以块为最小单位。
7、扇区、块/簇、page的关系
1.扇区: 硬盘的最小读写单元
2.块/簇: 是操作系统针对硬盘读写的最小单元
3.page: 是内存与操作系统之间操作的最小单元。
扇区 <= 块/簇 <= page
8、计算机读取数据流程
当需要从磁盘读取数据时,系统会将数据地址传给磁盘,即确定要读的数据在哪个磁道,哪个扇区。为 了读取这个扇区的数据,需要将磁头放到这个扇区上方,为了实现这一点,磁头需要移动对准相应磁 道,这个过程叫做 寻道 ,所耗费时间叫做 寻道时间 ,然后磁盘旋转将目标扇区旋转到磁头下,这个过程耗费的时间叫做旋转时间。
1.3局部性原理,磁盘预读,CPU缓存行,磁盘IO
1、 由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的十万分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格 按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长 度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用。程序运行期间所需要的数据通常比较集中。 由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序 来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存 和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此 时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然 后异常返回,程序继续运行。
下图是计算机硬件延迟的对比图,供大家参考:

2、磁盘IO的问题
mysql的数据一般以文件形式存储在磁盘上,检索需要磁盘I/O操作。与主存不同,磁盘I/O存在机械运 动耗费,因此磁盘I/O的时间消耗是巨大的。
2.索引
2.1索引概述
MySQL官方对索引的定义为:索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据 之外,数据库系统还维护者满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数 据, 这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。如下面的示意图所示 :

左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的记录在磁盘 上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点 分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找快速获取到相应 数据。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。 索引是数据库中用来提高性能的最常用的工具。
2.2索引优势劣势
优势
1)类似于书籍的目录索引,提高数据检索的效率,降低数据库的IO成本。
2)通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗。劣势
1)实际上索引也是一张表,该表中保存了主键与索引字段,并指向实体类的记录,所以索引列也是要 占用空间的。
2)虽然索引大大提高了查询效率,同时却也降低更新表的速度,如对表进行INSERT、UPDATE、
DELETE。因为更新表时,MySQL 不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。
2.3索引结构
索引是在MySQL的存储引擎层中实现的,而不是在服务器层实现的。所以每种存储引擎的索引都不一定 完全相同,也不是所有的存储引擎都支持所有的索引类型的。MySQL目前提供了以下4种索引:
BTREE 索引 : 最常见的索引类型,大部分索引都支持 B 树索引。
HASH 索引:只有Memory引擎支持 , 使用场景简单 。
R-tree 索引(空间索引):空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少,不做特别介绍。
Full-text (全文索引) :全文索引也是MyISAM的一个特殊索引类型,主要用于全文索引,
InnoDB从Mysql5.6版本开始支持全文索引。MySAM、InnoDB、Memory三种存储引擎对各种索引类型的支持
| 索引 | InnoDB引擎 | MyISAM引擎 | Memory引擎 |
|---|---|---|---|
| BTREE索引 | 支持 | 支持 | 支持 |
| HASH 索引 | 不支持 | 不支持 | 支持 |
| R-tree 索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本之后支持 | 支持 | 不支持 |
我们平常所说的索引,如果没有特别指明,都是指B+树(多路搜索树,并不一定是二叉的)结构组织的 索引。其中聚集索引、复合索引、前缀索引、唯一索引默认都是使用 B+tree 索引,统称为索引。
2.3.1索引数据结构的选型
从第一块内容中我们明白了磁盘是怎么存储文件的,而我们的mysql的数据文件又是存储在磁盘上的, 所以我们有必要去研究一下,mysql是怎么保障数据在磁盘上存储,效率还能比较高的原因。首先,在 数据库文件存储在磁盘时,为了提升查询效率,一定会选用合适的数据结构进行文件的存储。
接下来咱们探讨一下:
1、数组和链表
肯定不能选,这种最基本的数据结构,各自的劣势太明显。数据库对查询要求是最很高的所以链表这种 查询必须全表遍历的基本数据结构是不能用的。数组这种结构在添加数据时成本太大,插入数据时太过 于频繁。
2、HASH
类似与咱们的hashmap,这样行吗? 速度快,但是只要是hash就会产生无序的问题,所以不常用但也有。
3、树
看来看去也就是树这种结构比较合理了。二叉查找树可以吗?在查找一个数据时,二叉树是读取根节 点,小则从左找,大则从右找,每次读取一个数据。没有办法合理的利用局部性原理与磁盘预读,IO次 数太多太多,其次就是树的层次还是偏高,所以不适合。那每次读多个数据,每一个节点存多个数据的 结构就只有B-树和B+树了;
接下来就讨论这两种数据结构的选型。
4、B-树
B-树,这里的 B 表示 balance( 平衡的意思),B-树是一种多路自平衡的搜索树
它类似普通的平衡二叉树,不同的一点是B-树允许每个节点有更多的子节点。下图是 B-树的简化图.
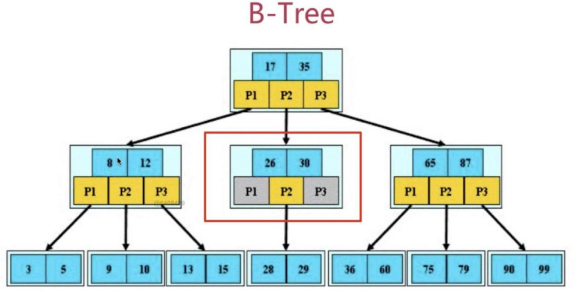
B-树有如下特点:
1.所有键值分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.在关键字全集内做一次查找,性能逼近二分查找
5、B+ 树
mysql默认是主键,如果没有主键则使用唯一索引,唯一索引也没有则使用rowid,行号。所以一定要建 立主键。
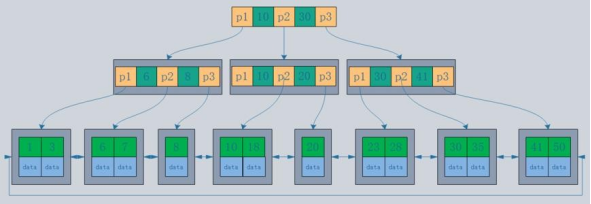
B+树是B-树的变体,也是一种多路搜索树, 它与 B- 树的不同之处在于:
1.所有关键字存储在叶子节点出现,内部节点(非叶子节点并不存储真正的 data)
2.为所有叶子结点增加了一个链指针
简化 B+树 如下图
6、为什么使用B-/B+ Tree
红黑树等数据结构也可以用来实现索引,但是文件系统及数据库系统普遍采用B-/+Tree作为索引结构。
MySQL 是基于磁盘的数据库系统,索引往往以索引文件的形式存储的磁盘上,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。为什么使用B-/+Tree,还跟磁盘存取原理有关。
MySQL(默认使用InnoDB引擎),将记录按照页的方式进行管理,每页大小默认为16K(这个值可以修 改).linux 默认页大小为4K
7、为什么使用 B+树
1.B+树更适合外部存储,由于内节点无 data 域,一个结点可以存储更多的内结点,每个节点能索引的范围更大更精确,也意味着 B+树单次磁盘IO的信息量大于B-树,I/O效率更高。
2.Mysql是一种关系型数据库,区间访问是常见的一种情况,B+树叶节点增加的链指针,加强了区间访 问性,可使用在范围区间查询等,而B-树每个节点 key 和 data 在一起,则无法区间查找。
2.3.2MySQL中的B+Tree
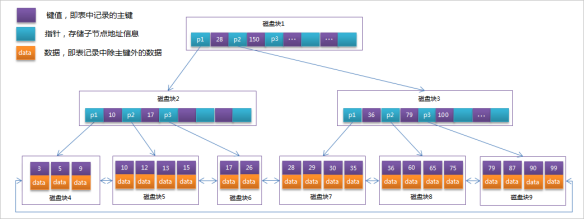
MySql索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的 链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能。
MySQL中的 B+Tree 索引结构示意图:
2.4索引分类
1)单值索引 :即一个索引只包含单个列,一个表可以有多个单列索引
2)唯一索引 :索引列的值必须唯一,但允许有空值
3)复合索引 :即一个索引包含多个列
2.5索引语法
索引在创建表的时候,可以同时创建, 也可以随时增加新的索引。准备环境:
create database demo_01 default charset=utf8mb4;
use demo_01;
CREATE TABLE `city` (
`city_id` int(11) NOT NULL AUTO_INCREMENT,
`city_name` varchar(50) NOT NULL,
`country_id` int(11) NOT NULL, PRIMARY KEY (`city_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `country` (
`country_id` int(11) NOT NULL AUTO_INCREMENT,
`country_name` varchar(100) NOT NULL, PRIMARY KEY (`country_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `city` (`city_id`, `city_name`, `country_id`) values(1,'西安',1);
insert into `city` (`city_id`, `city_name`, `country_id`) values(2,'NewYork',2); insert into `city` (`city_id`, `city_name`, `country_id`) values(3,'北京',1); insert into `city` (`city_id`, `city_name`, `country_id`) values(4,'上海',1);
insert into `country` (`country_id`, `country_name`) values(1,'China'); insert into `country` (`country_id`, `country_name`) values(2,'America'); insert into `country` (`country_id`, `country_name`) values(3,'Japan'); insert into `country` (`country_id`, `country_name`) values(4,'UK');
2.5.1创建索引
语法 :
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name(index_col_name,...)
index_col_name : column_name[(length)][ASC | DESC]
示例 : 为city表中的city_name字段创建索引 ;

2.5.2查看索引
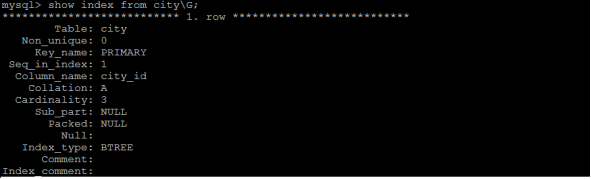
语法:
show index from table_name;
示例:查看city表中的索引信息;
2.1.1 查看索引
语法:

| img |
示例:查看city表中的索引信息;
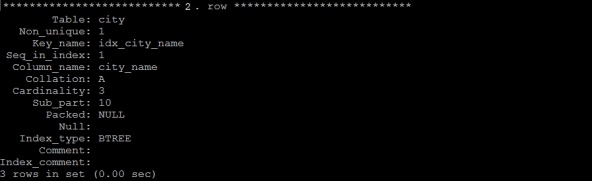
2.1.2 删除索引
语法 :
| img |
| img |
示例 : 想要删除city表上的索引idx_city_name,可以操作如下:
2.1.3 ALTER命令
| img |
2.1 索引设计原则
索引的设计可以遵循一些已有的原则,创建索引的时候请尽量考虑符合这些原则,便于提升索引的使用 效率,更高效的使用索引。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-agKvTG5I-1646894776824)(C:\Users\ADMINI~1\AppData\Local\Temp\ksohtml\wps3D63.tmp.png)]对查询频次较高,且数据量比较大的表建立索引。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Cm1FoNkG-1646894776824)(C:\Users\ADMINI~1\AppData\Local\Temp\ksohtml\wps3D73.tmp.png)]索引字段的选择,最佳候选列应当从where子句的条件中提取,如果where子句中的组合比较多, 那么应当挑选最常用、过滤效果最好的列的组合。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZInnAdlK-1646894776824)(C:\Users\ADMINI~1\AppData\Local\Temp\ksohtml\wps3D74.tmp.png)]使用唯一索引,区分度越高,使用索引的效率越高。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UNaOecPb-1646894776825)(C:\Users\ADMINI~1\AppData\Local\Temp\ksohtml\wps3D75.tmp.png)]索引可以有效的提升查询数据的效率,但索引数量不是多多益善,索引越多,维护索引的代价自然 也就水涨船高。对于插入、更新、删除等DML操作比较频繁的表来说,索引过多,会引入相当高的 维护代价,降低DML操作的效率,增加相应操作的时间消耗。另外索引过多的话,MySQL也会犯 选择困难病,虽然最终仍然会找到一个可用的索引,但无疑提高了选择的代价。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-icnVMwd8-1646894776825)(C:\Users\ADMINI~1\AppData\Local\Temp\ksohtml\wps3D76.tmp.png)]使用短索引,索引创建之后也是使用硬盘来存储的,因此提升索引访问的I/O效率,也可以提升总 体的访问效率。假如构成索引的字段总长度比较短,那么在给定大小的存储块内可以存储更多的索 引值,相应的可以有效的提升MySQL访问索引的I/O效率。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wHmM54yJ-1646894776826)(C:\Users\ADMINI~1\AppData\Local\Temp\ksohtml\wps3D87.tmp.png)]利用最左前缀,N个列组合而成的组合索引,那么相当于是创建了N个索引,如果查询时where子 句中使用了组成该索引的前几个字段,那么这条查询SQL可以利用组合索引来提升查询效率。
| img |
1. 视图
1.1 视图概述
视图(View)是一种虚拟存在的表。视图并不在数据库中实际存在,行和列数据来自定义视图的查询中 使用的表,并且是在使用视图时动态生成的。通俗的讲,视图就是一条SELECT语句执行后返回的结果 集。所以我们在创建视图的时候,主要的工作就落在创建这条SQL查询语句上。
视图相对于普通的表的优势主要包括以下几项。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ouzbyn1v-1646894776826)(C:\Users\ADMINI~1\AppData\Local\Temp\ksohtml\wps3D89.tmp.png)]简单:使用视图的用户完全不需要关心后面对应的表的结构、关联条件和筛选条件,对用户来说已 经是过滤好的复合条件的结果集。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PusRBFu1-1646894776827)(C:\Users\ADMINI~1\AppData\Local\Temp\ksohtml\wps3D9A.tmp.png)]安全:使用视图的用户只能访问他们被允许查询的结果集,对表的权限管理并不能限制到某个行某 个列,但是通过视图就可以简单的实现。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xbquutak-1646894776827)(C:\Users\ADMINI~1\AppData\Local\Temp\ksohtml\wps3D9B.tmp.png)]数据独立:一旦视图的结构确定了,可以屏蔽表结构变化对用户的影响,源表增加列对视图没有影 响;源表修改列名,则可以通过修改视图来解决,不会造成对访问者的影响。
1.2 创建或者修改视图
创建视图的语法为:
| img |
MERGE 引用视图和视图定义的语句的文本被合并,使视图定义的部分取代语句的相应部分。意味着视图只是一个规则,语句规则,当查询视图时, 把查询视图的语句比如:where…那些与创建时的语句where子句等合并,分析,形成一条select语句。
我们先创建一张视图查询所有商品价格大于3000的商品

然后我们再查询视图的时候,再加上一个where条件<5000
| img |
这时候它就会把两条语句合并分析最终形成这样一条select语句
| img |
TEMPTABLE 视图中的结果被检索到一个临时表中,然后用来执行语句。
UNDEFINED MySQL选择使用哪种算法。如果可能的话,它更倾向于MERGE而不是TEMPTABLE,因为MERGE通常更有效率,而且如果使用临时表,视图无法更新。
官方给出的说法:MERGE通常更有效率
merge 和 temptalbe 有一个显著的区别,
 merge最终去查的还是原表,而temptable去查的是虚拟表。修改视图的语法为:
merge最终去查的还是原表,而temptable去查的是虚拟表。修改视图的语法为:
| img |
示例 , 创建city_country_view视图 , 执行如下SQL :
| img |
查询视图 :

1.3 查看视图
| img |
从 MySQL 5.1 版本开始,使用 SHOW TABLES 命令的时候不仅显示表的名字,同时也会显示视图的名字,而不存在单独显示视图的 SHOW VIEWS 命令。
同样,在使用 SHOW TABLE STATUS 命令的时候,不但可以显示表的信息,同时也可以显示视图的信息。
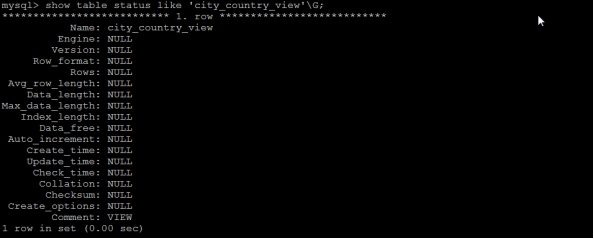
| img |
如果需要查询某个视图的定义,可以使用 SHOW CREATE VIEW 命令进行查看 :
1.4 删除视图
语法 :
| img |
示例 , 删除视图city_country_view :
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oxRjNTMR-1646894776833)(C:\Users\ADMINI~1\AppData\Local\Temp\ksohtml\wps3DC7.tmp.png)]
2. 存储过程和函数
2.1 存储过程和函数概述
存储过程和函数是 事先经过编译并存储在数据库中的一段 SQL 语句的集合,调用存储过程和函数可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率 是有好处的。
存储过程和函数的区别在于函数必须有返回值,而存储过程没有。函数 : 是一个有返回值的过程 ;
过程 : 是一个没有返回值的函数 ;
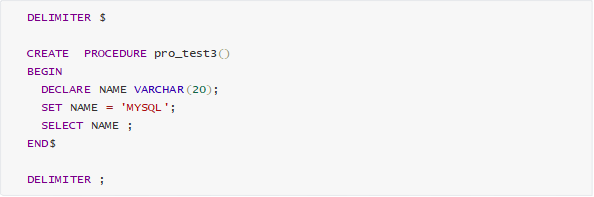
2.2 创建存储过程
| img |
示例 :
| img |
知识小贴士
DELIMITER
该关键字用来声明SQL语句的分隔符 , 告诉 MySQL 解释器,该段命令是否已经结束了,mysql是否可以执行了。默认情况下,delimiter是分号;。在命令行客户端中,如果有一行命令以分号结束,那么回车 后,mysql将会执行该命令。
2.3 调用存储过程
| img |
2.4 查看存储过程
| img |
2.5 删除存储过程
| img |
2.6 语法
存储过程是可以编程的,意味着可以使用变量,表达式,控制结构 , 来完成比较复杂的功能。
2.6.1 变量
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5ectcoJl-1646894776835)(C:\Users\ADMINI~1\AppData\Local\Temp\ksohtml\wps3DCD.tmp.png)]DECLARE
通过 DECLARE 可以定义一个局部变量,该变量的作用范围只能在 BEGIN…END 块中。
| img |
示例 :
| img |
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AliyiNu9-1646894776836)(C:\Users\ADMINI~1\AppData\Local\Temp\ksohtml\wps3DE0.tmp.png)]SET
直接赋值使用 SET,可以赋常量或者赋表达式,具体语法如下:
| img |
示例 :
也可以通过select … into 方式进行赋值操作 :
| img |
2.6.2 if条件判断
语法结构 :
| img |
需求:
| img |
示例 :
| img |
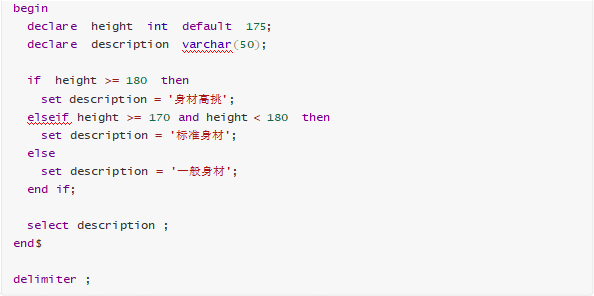
| img |
调用结果为 :
2.6.3 传递参数
语法格式 :
| img |
IN - 输入
需求 :
| img |
示例 :
最后
每年转战互联网行业的人很多,说白了也是冲着高薪去的,不管你是即将步入这个行业还是想转行,学习是必不可少的。作为一个Java开发,学习成了日常生活的一部分,不学习你就会被这个行业淘汰,这也是这个行业残酷的现实。
如果你对Java感兴趣,想要转行改变自己,那就要趁着机遇行动起来。或许,这份限量版的Java零基础宝典能够对你有所帮助。

- |
| | img |
需求:
| img |
示例 :
| img |
| img |
调用结果为 :
2.6.3 传递参数
语法格式 :
| img |
IN - 输入
需求 :
| img |
示例 :
最后
每年转战互联网行业的人很多,说白了也是冲着高薪去的,不管你是即将步入这个行业还是想转行,学习是必不可少的。作为一个Java开发,学习成了日常生活的一部分,不学习你就会被这个行业淘汰,这也是这个行业残酷的现实。
如果你对Java感兴趣,想要转行改变自己,那就要趁着机遇行动起来。或许,这份限量版的Java零基础宝典能够对你有所帮助。
[外链图片转存中…(img-BooM3UkX-1725907728029)]















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









