






+ 分段 MTU
-
路由协议
-
交换机 二层
-
路由器 三层
-
自治系统
-
内部路由协议
- RIP
- OSPF
- IGRP
-
外部路由协议
- BGP
-
-
R Introduction to Computer Networks and Cybersecurity 计算机网络与网络安全导论 12-13章 路由协议
-
R Computer Networking A Top-Down Approach 6th 计算机网络:自顶向下方法 路由器内部处理方式
-
-
数据包解析
思考题
当我们无法访问外部网站的时候,你觉得可能的原因会有哪些,你的排查手段是什么?你可以参考数据包的流转过程,尝试给出尽可能全面的答案。
-
原因
-
本机网络有问题
- DNS
- 无法连网
-
服务崩了
-
-
检查本地网络是否正常(ping)
- baidu
- 网关
- 局域网其他机器
17|巨人的肩膀:HTTP协议与Go标准库原理
操作系统处理数据包流程
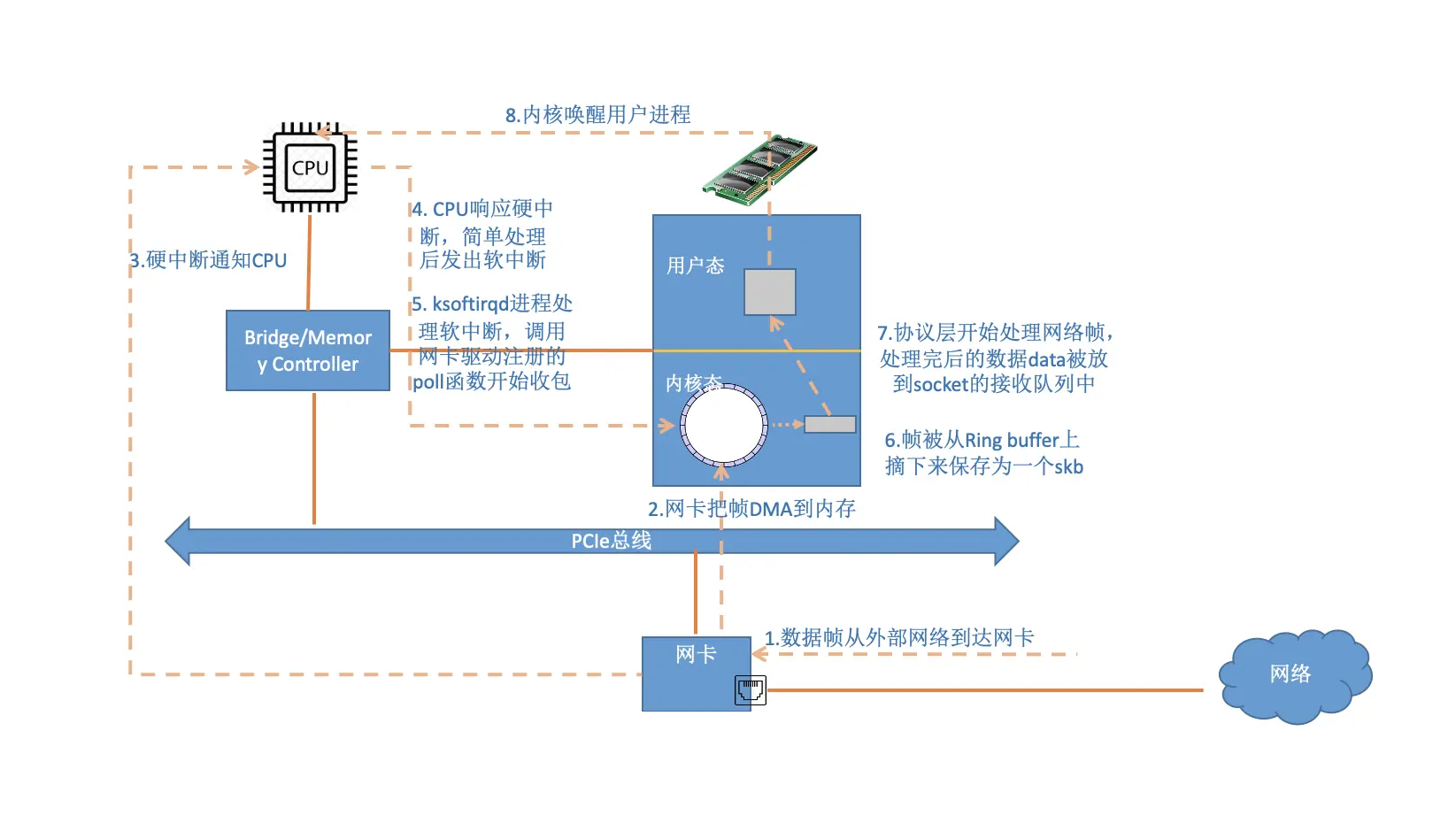
- 当网络设备接收到数据,并储存到设备的缓冲区后(该缓冲区可能位于设备的内存,也可能通过 DMA 写入到主机内存),会首先通知操作系统内核对已接收的数据进行处理。
- 接收到新的数据包后,网卡设备将生成一个硬件中断信号。这个信号通常是由设备发送给中断控制器,再由中断控制器转发给 CPU。CPU 接到信号后,当前执行的任务被打断,转而执行由设备驱动注册的中断处理程序,中断处理程序将处理对应的设备事件。
- Linux 将中断处理程序分为两个部分:上半部和下半部,这是深思熟虑的结果。中断处理程序的上半部接受到中断时就立即执行,但是只做比较紧急的工作,这些工作都是在所有中断被禁止的情况下完成的。所以上半部要快,否则其他的中断就得不到及时的处理,导致硬件数据丢失。而耗时又不紧急的工作被推迟到下半部去做。上半部处理程序会将数据帧加入到内核的输入队列中,通知内核做进一步处理,并快速返回。
- 硬中断完成后,有可能会直接执行下半部处理程序,也有可能有更重要的任务要执行。当出现第二种情况,在后续会由每一个 CPU 中都维护的 ksoftirqd 内核线程完成下半部处理程序。下半部处理程序中,操作系统会检查并剥离数据包 Header,判断当前数据包应该被哪一个上层协议接收,依次传递到上层处理。整个过程中还穿插了 hook 函数,可以提供防火墙和拦截的功能(这是 iptables 等工具的工作原理)。
- R: Understanding Linux Network Internals 深入理解Linux内幕
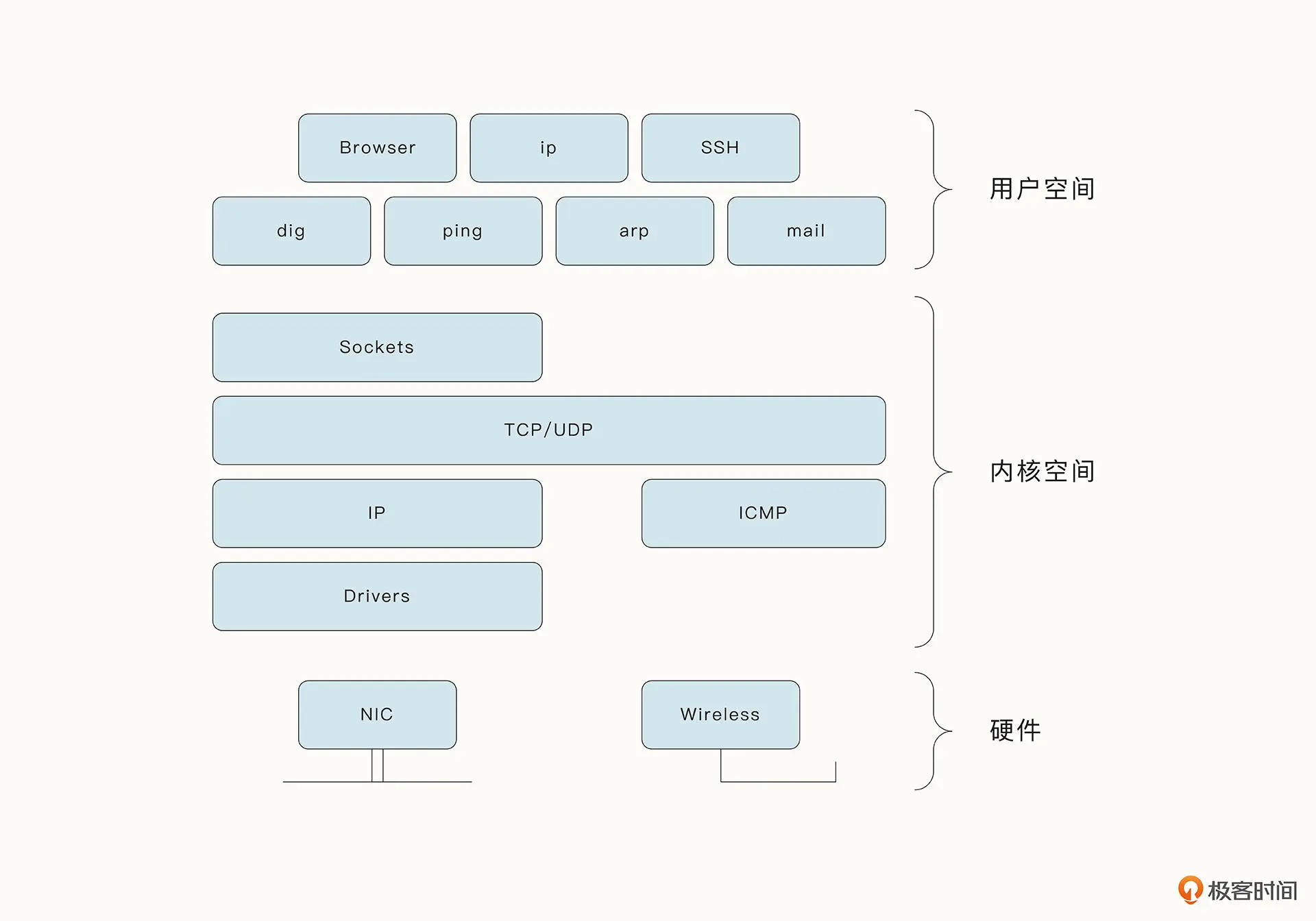
硬件、操作系统内核、用户态空间中分别对应的组件和交互:
- R: UNIX Network Programming UNIX网络编程
- R: Systems Performance, 2nd Edition 性能之巅
HTTP解析
TCP 协议的处理是在操作系统内核实现的。操作系统最终会剥离 TCP Header,识别具体的端口号,并通过 Socket 接口将数据传递到指定的应用程序,例如浏览器。当今使用最广泛的网络协议 HTTP 就位于应用层,对 HTTP 协议的处理也是在应用程序中完成的。
问题
- 服务器返回了一个 499 状态码是什么意思
- 如何让程序模拟浏览器访问服务器
- 如果使用 HTTP 代理访问外部网络,HTTP 协议有什么问题
- 为什么需要 HTTPS、HTTP/2。
Curl过程
» curl www.baidu.com -vvv
\* Trying 110.242.68.3...
\* TCP_NODELAY set
\* Connected to www.baidu.com (110.242.68.3) port 80 (#0)
> GET / HTTP/1.1
> Host: www.baidu.com
> User-Agent: curl/7.64.1
> Accept: \*/\*
>
< HTTP/1.1 200 OK
< Accept-Ranges: bytes
< Content-Length: 2381
< Content-Type: text/html
< Date: Mon, 27 Jun 2022 16:04:17 GMT
< Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
<
<!DOCTYPE html>
...
\* Closing connection 0
- curl 命令是执行 HTTP 请求的常见工具。其中,www.baidu.com是域名。
- 2: 通过 DNS 解析出它对应的 IP 地址为 110.242.68.3。
- 3:
TCP_NODELAY set 表明 TCP 正在无延迟地直接发送数据,TCP_NODELAY 是 TCP 众多选项的一个。 - 4:
port 80代表连接到服务的 80 端口, 80 端口其实是 HTTP 协议的默认端口。 - 有> 标识的 5-8 行数据才是真正发送到服务器的 HTTP 请求。
- 5; 数据 GET / HTTP/1.1 表明当前使用的是 HTTP 的 GET 方法,并且协议版本是 HTTP1.1。
- HTTP 协议可以在请求头中加入多个 key-value 信息。
- 6:
Host: www.baidu.com表示当前请求的主机,我们这里是百度的域名。 - 7;
User-Agent表示最终用户发出 HTTP 请求的计算机程序,在这里是 curl 工具。 - 7: Accept 标头还告诉我们 Web 服务器客户端可以理解的内容类型。这里 / 表示类型不限,可能是图片、视频、文字等。
- 十到十七行表示服务端返回的信息,“HTTP/1.1 200 OK ”是服务器的响应。服务器使用 HTTP 版本和响应状态码进行响应。状态码 1XX 表示信息,2XX 表示成功,3XX 表示重定向,4XX 表示请求有问题,5XX 表示服务器异常。在这里状态码为 200 ,说明响应成功了。
- 12:“Content-Length: 2381 ”表明服务器返回消息的大小为 2381 字节。
- 13: “Content-Type: text/html ”表明当前返回的是 HTML 文本。
- 14:“Date: Mon, 27 Jun 2022 16:04:17 GMT ”是当前 Web 服务器生成消息时的格林威治时间。
- 15:
Set-Cookie的意思是,服务器让客户端设置 cookie 信息,这样客户端再次请求该网站时,HTTP 请求头中将带上 cookie 信息,这样服务器可以减少鉴权操作,从而加快消息处理和返回的速度。 - 一连串响应头的后面是百度返回的 HTML 文本,这就是我们在浏览器上访问页面的源代码,并最终被浏览器渲染。
- 最后 * Closing connection 0 表明连接最终被关闭。
- R HTTP: The Definitive Guide Http权威指南
- R web性能权威指南(High Performance Browser Networking)
HTTP协议的问题
- 更多的资源分布在不同的主机中,当我们访问一个网页时,这个网页的图片等资源可能来自于外部几十个网站;
- 资源占用的空间也越来越大;
- 相对于网络带宽,网络往返延迟变成最大的瓶颈。
性能问题:
- 头阻塞问题
新的协议
- HTTP/2
- QUIC
- R: HTTP/2 in Action
- QUIC协议文档
- HTTP/3 From A To Z: Core Concepts
HTTP请求原理
借助 epoll 多路复用的机制和 Go 语言的调度器,Go 可以在同步编程的语义下实现异步 I/O 的网络编程。
- 当 http.Get 函数完成基本的请求封装后,会进入到核心的主入口函数 Transport.roundTrip,参数中会传递 request 请求数据。
- Transport.roundTrip 函数会选择一个合适的连接来发送这个 request 请求,并返回 response。
整个流程主要分为两步:
- 使用 getConn 函数来获得底层 TCP 连接;
- 调用 roundTrip 函数发送 request 并返回 response,此外还需要处理特殊协议,例如重定向、keep-alive 等。
并不是每一次 getConn 函数都需要经过 TCP 的 3 次握手才能建立新的连接。具体的 getConn 函数如下:
// 获取链接
func (t \*Transport) getConn(treq \*transportRequest, cm connectMethod) (pc \*persistConn, err error) {
...
// 第一步,查看idle conn连接池中是否有空闲链接,如果有,则直接获取到并返回。如果没有,当前w会放入到idleConnWait等待队列中。
if delivered := t.queueForIdleConn(w); delivered {
pc := w.pc
return pc, nil
}
// 如果没有闲置的连接,则尝试与对端进行tcp连接。
// 注意这里连接是异步的,这意味着当前请求是有可能提前从另一个刚闲置的连接中拿到请求的。这取决于哪一个更快。
t.queueForDial(w)
// Wait for completion or cancellation.
// 拿到conn后会close(w.ready)
select {
case <-w.ready:
return w.pc, w.err
// 处理请求的退出与
case <-req.Cancel:
return nil, errRequestCanceledConn
...
}
return nil, err
}
}
Go 标准库在这里使用了连接池来优化获取连接的过程。之前已经与服务器完成请求的连接一般不会立即被销毁(HTTP/1.1 默认使用了 keep-alive:true,可以复用连接),而是会调用 tryPutIdleConn 函数放入到连接池中。
使用连接池的收益是非常明显的,因为复用连接之后就不用再进行 TCP 三次握手了,这大大减少了请求的时间。
在使用了 HTTPS 协议时,在三次握手基础上还增加了额外的鉴权协调,初始化的建连过程甚至需要花费几十到上百毫秒。
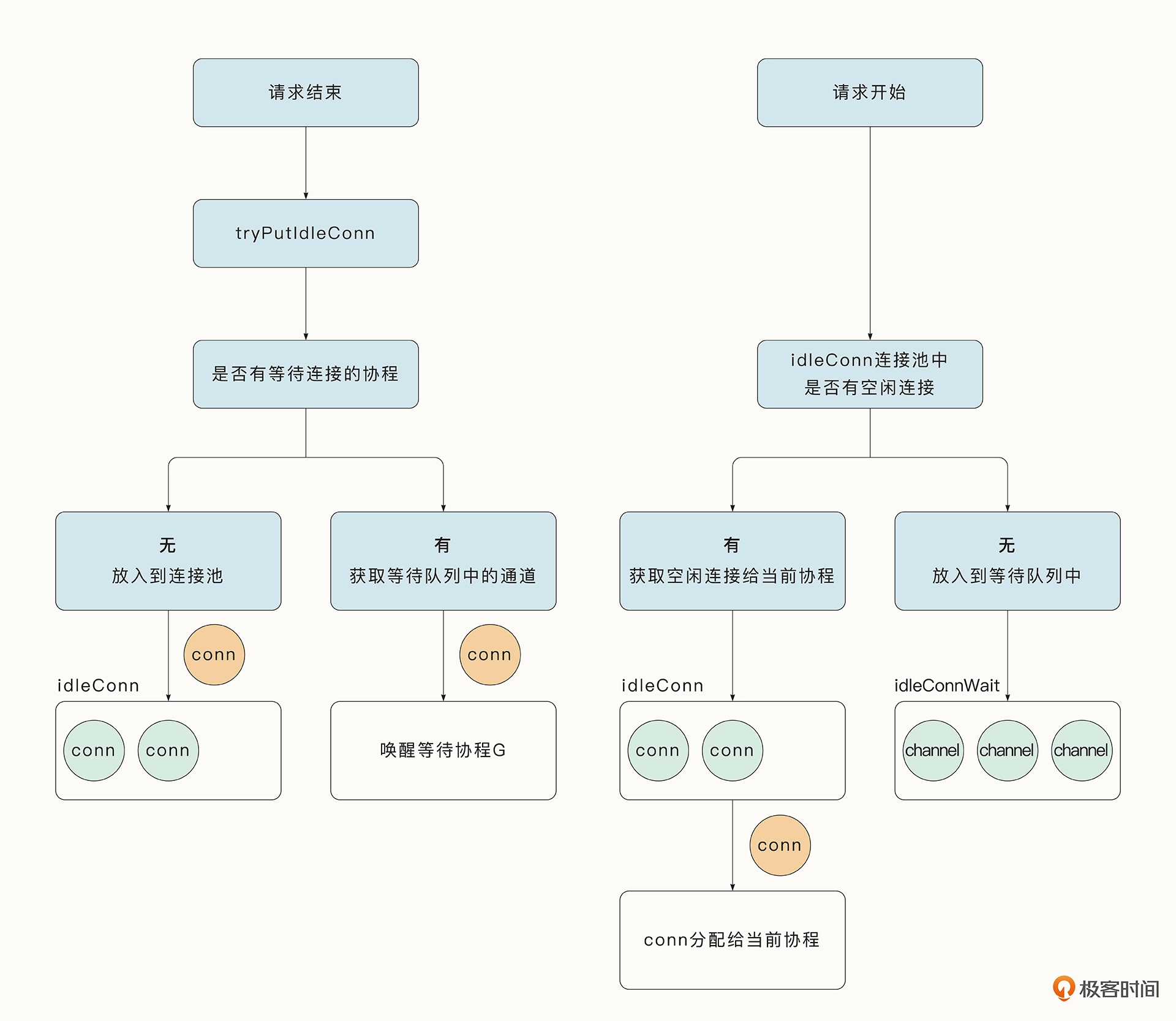
另外连接池的设计也很有讲究,例如连接池中的连接到了一定的时间需要强制关闭。获取连接时的逻辑如下:
- 当连接池中有对应的空闲连接时,直接使用该连接;
- 当连接池中没有对应的空闲连接时,正常情况下会通过异步与服务端建连的方式获取连接,并将当前协程放入到等待队列中。
连接的第一步是通过 Resolver.resolveAddrList 方法访问 DNS 服务器,获取www.baidu.com 网站对应的 IP 地址。下面这张图展示了借助 DNS 协议查找域名对应的 IP 地址的过程。
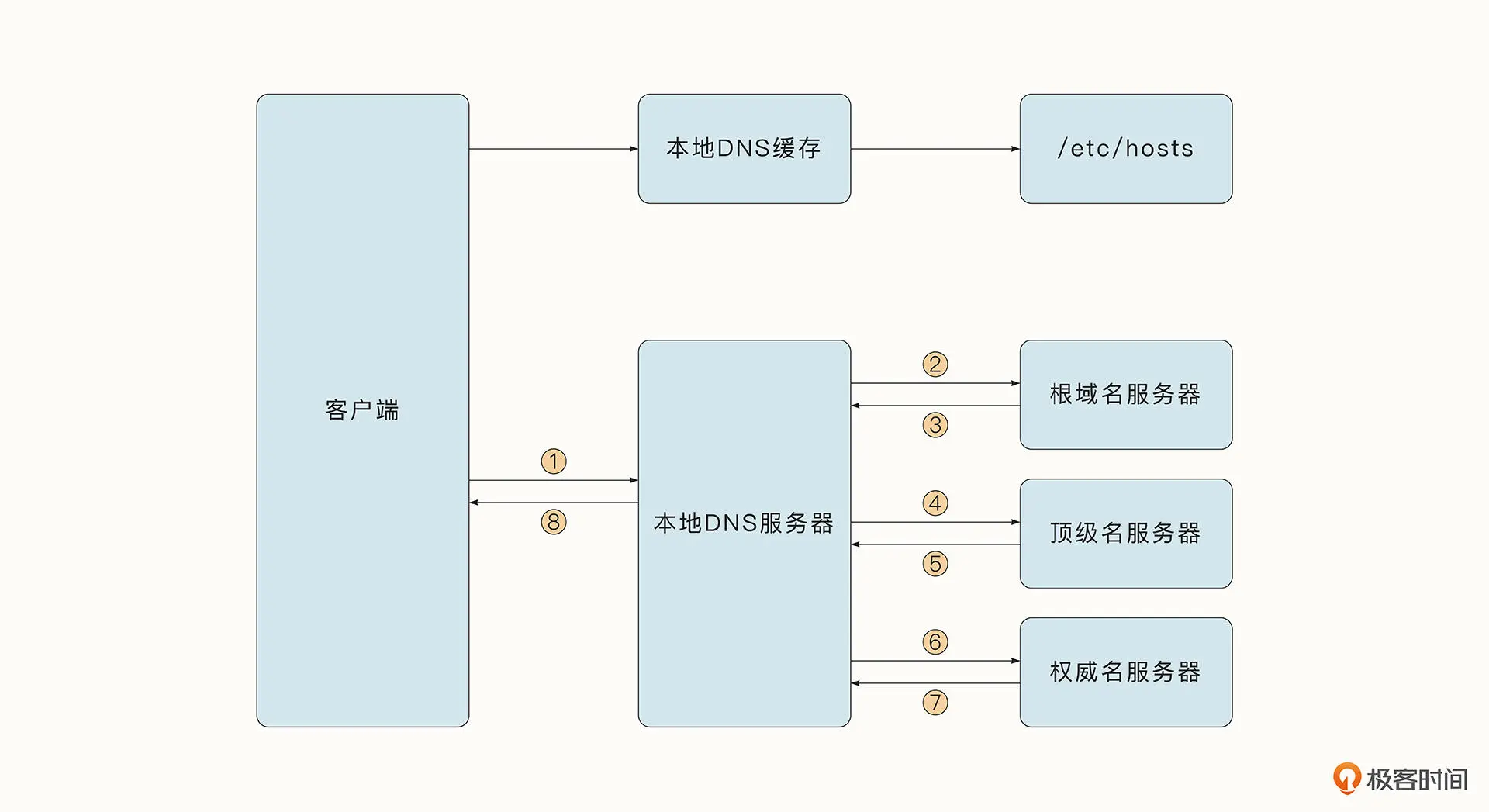
客户端首先查看是否有本地缓存,如果没有,则会用递归方式从权威域名服务器中获取 DNS 信息并缓存下来。
- R: 计算机网络与网络安全导论(Introduction to Computer Networks and Cybersecurity)第二章 DNS
在与远程服务器建连的过程中,当前的协程会进入阻塞等待的状态。正常情况下,当前请求的协程会等待连接完毕。但是因为建立连接的过程还是比较耗时的,所以如果在这个过程中正好有一个其他连接使用完了,协程就会优先使用该连接。
这种巧妙的设计依托了轻量级协程的优势,获取连接的具体流程如下图右侧所示:
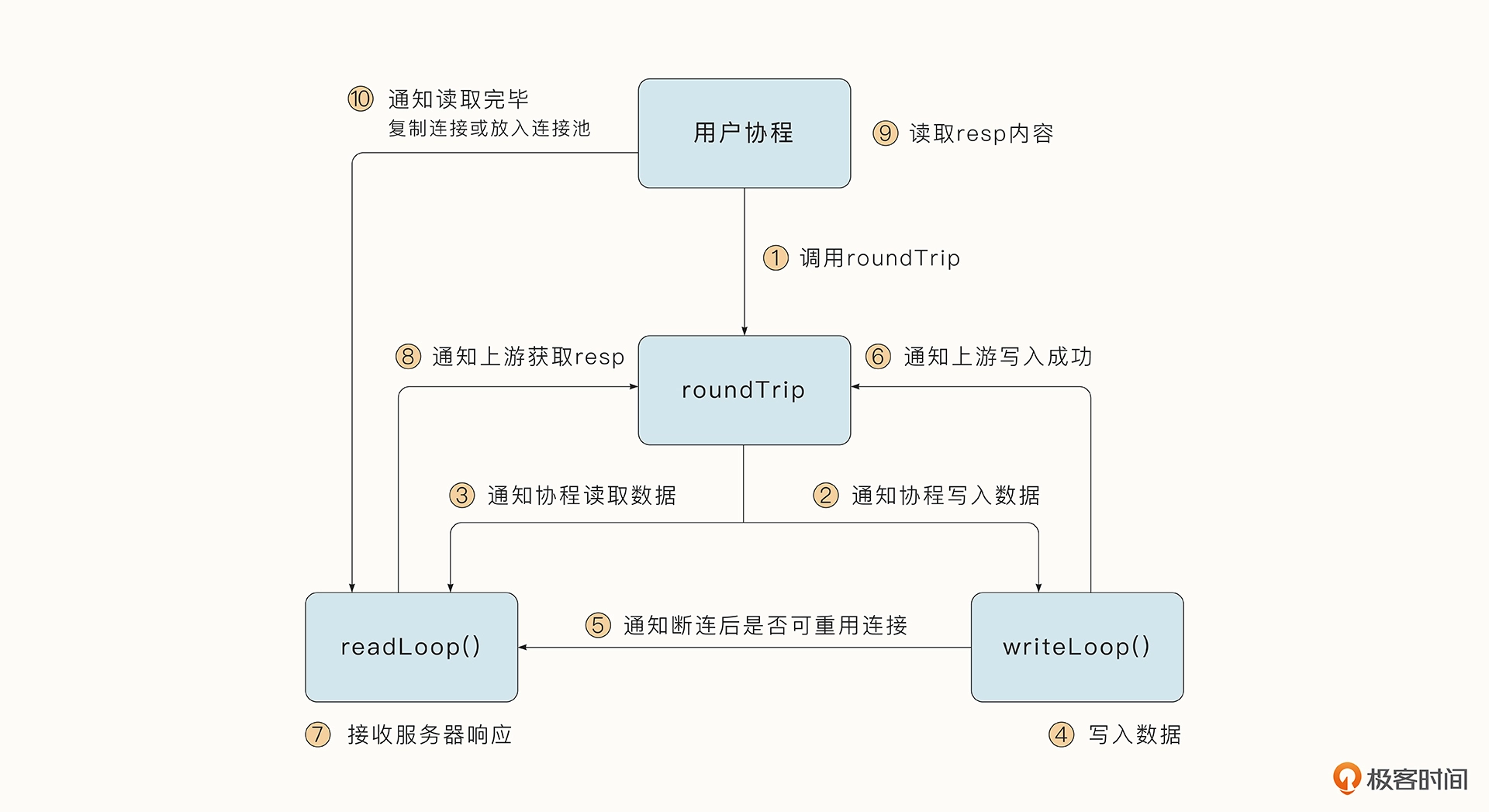
为利用协程并发的优势,Transport.roundTrip 协程获取到连接后,会调用 Transport.dialConn 创建读写 buffer 以及读数据与写数据的两个协程,分别负责处理发送请求和服务器返回的消息:
func (t \*Transport) dialConn(ctx context.Context, cm connectMethod) (pconn \*persistConn, err error) {
...
// buffer
pconn.br = bufio.NewReaderSize(pconn, t.readBufferSize())
pconn.bw = bufio.NewWriterSize(persistConnWriter{pconn}, t.writeBufferSize())
// 创建读写通道,writeLoop用于发送request,readLoop用于接收响应。roundTrip函数中会通过chan给writeLoop发送
// pconn.br给readLoop使用,pconn.bw给writeLoop使用
go pconn.readLoop()
go pconn.writeLoop()
}
整个处理流程和协程间协调如下图所示:















 4111
4111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









