







零
近年来,“操作系统”一词比以往更加热门,经常与缺“芯”少“魂”一同出现,其中的“魂”指的就是“操作系统”
在计算机的世界里,我们天天与操作系统打交道,然而,操作系统仍然是我们国家目前需要不断加强的基础设施,也是我们必须要自己掌握的核心技术。了解历史,才能更好的开创未来,让我们来回顾操作系统的前世今生。
1. 批处理操作系统:GM-NAA I/O
GM-NAA I/O是历史上的第一个操作系统,Robert L. Patrick和Owen Mock于1956年建设,GM是美国通用汽车公司的缩写,NAA是北美航空的缩写,这两家公司共同开发了这个操作系统,用来控制计算机的输入输出,即I/O,GM-NAA运行在IBM 704计算机上,这是第一个大规模生产的支持浮点计算的计算机。
主要功能:批处理运行任务

操作员将需要计算的公式放在纸带上,输入计算机,等待计算,然后从纸带得到输出结果,再接着输入记录下一个需要计算的纸带。
| 我们看到的Android操作系统,不过是把操作对象从庞大的IBM 704计算机换成了小巧的手机,把操作的方式从纸带换成了触摸屏,本质还是一个让“人”来操作“机器”的“系统” |
2. 通用操作系统:OS/360

1964年,IBM的Gene Amdahl等人提出操作系统应与硬件解耦,于是打造出了 System/360 OS,这也是一个具有划时代意义的操作系统,这是首个通用操作系统,首次将操作系统与计算机分离,标志着操作系统从专用向通用的转变。
在此之前,操作系统是与计算机硬件绑定的,也就是说“新造一台计算机,就要重写一个操作系统”。IBM当时有四条产品线,也就意味着需要四个操作系统。
将操作系统与硬件解耦的理论思想,对于后来软件和硬件的设计都产生了巨大影响。
| 架构师:Gene Amdahl——>Amdahl's Law 项目经理:Fred Brooks——>《人月神话》,1999年图灵奖得主 由此诞生了软件工程学科 |
3. 其他操作系统(如:Multics,UNIX,Linux)
Linux是现代意义上的操作系统,也是现代最流行的开源操作系统
Linux受UNIX影响非常深,UNIX的前身是Multics
分时与多任务:Multics,UNIX,Linux

GE、贝尔实验室和MIT三个logo的组合
Multics使用的一个概念:ring,也就是特权级;
ring层层嵌套,最里面的ring权限最高,用来运行内核,管理所有的资源。越往外,权限越低,一共有64层。
Multics还提出了分时、文件系统、动态链接等,这些设计一直沿用至今。
Multics支持热插拔,动态增加或拔除CPU、内存和存储设备,这些功能在现在的很多计算机上还没有,只有在一些高端的服务器上应用。
Multics理论太过超前,最后失败了,有句话说“领先一步是先驱,领先三步是先烈”。
UNIX开发只用了一个月,比Multics简单很多,因为只用来运行游戏,而且是不是从零开始,而是站在了Multics的肩膀上,复用了很多组件。
UNIX很多概念至今仍在沿用,如:Shell,层次化文件系统;比如,在home目录下,为每个用户创建一个目录等等。
AT&T希望用UNIX赚钱,导致很多人不能够自由地使用。于是在1991年,来自芬兰的学生Linus Torvalds在学习操作系统时尝试自己写一个操作系统,并且开放给全世界的人来用,这个操作系统就是Linux,这个开源模式获得了巨大的成功。
今天的Windows,MacOS,Android,iOS都是图形化的操作方式。
三个有代表的图形化操作系统:施乐公司的Alto,苹果的LISA(早期Mac OS的代号)和微软的Windows。
Xerox Alto(1973):第一个图形化操作系统,首次使用鼠标来操作计算机(Chunck Thacker,2009年获得图灵奖)。

施乐公司的研究中心是当时最前沿的一个研究中心,Alto的名字来自Palo Alto,也是斯坦福大学的所在地,位于硅谷的中心。
1979年,乔布斯访问Xerox PARC意识到GUI的重要性,买下了GUI进行研究,随后再1983年,推出了LISA操作系统和Macintosh。
两年后(1985),比尔盖茨也推出了同样的图形化操作界面——Windows。
| 当时苹果和微软为此打了很长时间的官司 微软:图形界面也不是你苹果原创的,我们两家有一个富裕的邻居,我本来想去偷一个电视机,结果去了才发现电视机被你偷走了,我只能偷个音响。 |
操作系统的发展经历了一个漫长的过程,其推动力来自底层硬件和上层应用的变化。
如:
硬件方面:有IBM计算机的不断推陈出新,促使操作系统的功能集合不断变化。
应用方面:图形界面、触摸等新的操作模式,使操作系统与人的交互模式不断改变。
世界上最赚钱的两家公司:微软和苹果,尤其是苹果。
操作系统一直随硬件和应用的持续创新而不断发生变化,未来的操作系统一定与我们今天所使用的操作系统大不相同,这里有巨大的机会需要我们去把握!
1. AIoT
我们正在进入一个AI的时代,各种AI的硬件算法不断的渗透到我们生活的方方面面,我们身边几乎所有的事物都会智能化。锁变成智能锁,车变成智能车,电视变成智能电视,甚至镜子、墙、窗户都会变得智能。对于这些硬件来说,现在的操作系统并不是最合适的,我们需要符合AIoT新的操作系统
2. 5G
2019年,5G正式商用,将会成为整个信息社会的基础设施。
构筑万物互联的智能世界!
趋势1:从封闭到开放,再到封闭
当前越来越多的企业围绕自建的操作系统构筑自己的平台和生态
例子1:18年10月起Google正式对欧盟区域的Android进行收费,初步高达40美元每设备
例子2:2018年10月IBM340亿美元收购RedHat,构筑其云计算竞争力
例子3:2016年起谷歌投入600+人力,数十亿美元,研发面向智能端设备的自研OSFuchsia
操作系统并不是免费的午餐,而是构筑与控制生态的黑土地。
趋势2:从专用到通用,再到专用

DSA:domain-specific architecture
从通用计算走向领域计算,各种xPU不断繁荣 GPU、TPU、NPU、IPU等
智能存储,存算一体、非易失内存内存与持久存储走向融合
数据中心的网卡:时延600纳秒,网络速度已经很接近CPU的处理速度
趋势3:从简单到复杂,到更复杂
Linux代码规模已超过2000万行,每年以200万行的数量在增加/更新
Linux 0.1是非常简单的
有的设备有多个操作系统:例如,机器人,需要多个操作系统一起工作
一个芯片上的OS不是一个单一的OS,而是一组OS,如,海思麒麟的SOC(System on Chip)芯片
分布式的,可编程的异构设备
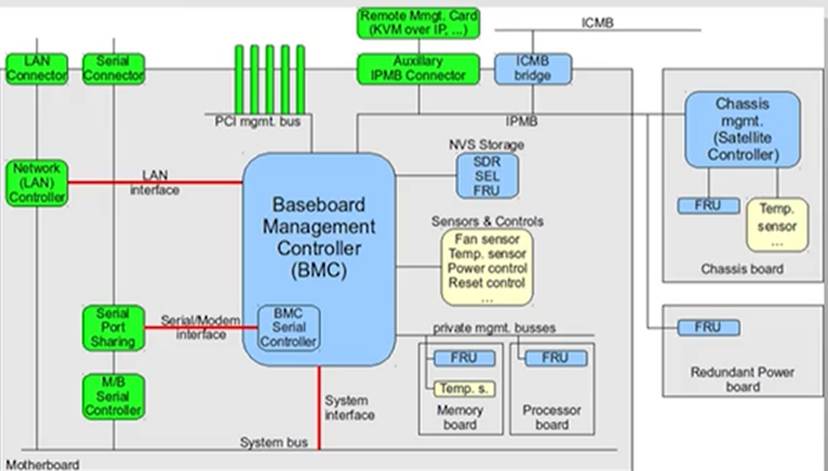
Intel的管理引擎(ME),拥有最高级的权限,能够远程开关计算机,每块Intel芯片都会运行一个Linux,有人戏称可能Minix才是最流行的操作系统
智能驾驶、智能家庭等新的场景需要新的操作系统
一
操作系统是管理计算机硬件、软件资源,并为计算机程序提供公共服务的系统软件?
操作系统不是技术词汇其概念有一定的模糊性,没有精确的定义
内核(kernel):运行在内核态的代码
| 对于Linux操作系统,Java虚拟机是一个应用程序 对于早期的Android,Java虚拟机是其框架的重要组成部分,属于Android操作系统的一部分 对于Java开发的app,微信,是应用程序 对于微信小程序,用JavaScript或HTML5写的是应用程序 微信对于小程序就是操作系统 |
操作系统是个宽泛的概念而不是个准确的技术词汇,用内核态和用户态表达更准确,又不能直接与操作系统与应用程序直接对应
操作系统的一些组件运行在用户态,如:驱动和文件系统,libc可以看成操作系统,也可以看成应用程序,取决于不同的角度
| 操作系统并不是一成不变的,其内涵随着时代的发展而不断演变,其形态在不同的设备上也 各不相同 操作系统有两点是不变的:管理硬件和软件资源,提供公共服务,如,对CPU、内存设备的管理,通过进程、文件等抽象向上提供服务 |
操作系统是管理硬件资源控制程序运行改善人机界面和为应用软件提供支持的一种系统软件
——计算机百科全书(第2版)
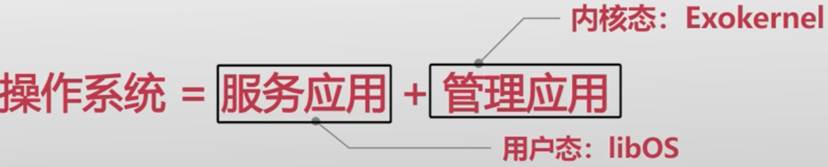
两个主要的功能:服务应用,管理应用
从Hello World开始:

操作系统为应用提供的一些服务:
- 为应用提供计算资源的抽象
- CPU: :进程/线程,数量不受物理CPU的限制
- 内存:虚拟内存,大小不受物理内存的限制
- I/O设备:将各种设备统一抽象为文件,提供统一接口
- 为应用提供线程间的同步
- 应用可以实现自己的同步原语(如spinlock)
- 操作系统提供了更高效的同步原语(与线程切换配合,如pthread_mutex)
- 为应用提供进程间的通信
- 应用可以利用网络进行进程间通信 (如loopback设备)
- 操作系统提供了更高效的本地通信机制(具有更丰富的语义,如Shell pipe)
系统调用:应用与操作系统的交互
例如: printfO -> writeO->sys_write()
write(1, "Hello World!\n", 13)

- 生命周期的管理:应用的加载、迁移、销毁等操作
- 计算资源的分配:
- CPU:线程的调度机制
- 内存:物理内存的分配
- I/O设备:设备的复用与分配
- 安全与隔离
- 应用程序内部:访问控制机制
- 应用程序之间:隔离机制,包括错误隔离和性能隔离
例子:避免一个流氓应用独占所有资源
方法-1:每10ms发生一个时钟中断 (时间片),调度器决定下一个要运行的任务
方法-2:可通过信号等打断当前任务执行,如: kill -9 1951
通过嵌套fork依然可以让整个系统卡死
| C |
如何解决这个问题?
- 资源配额:cgroup/Linux
- 虚拟化:虚拟机
- 万能方法:重启方法:重启机器
- 制度约束:AppStore的程序预审准入机制
操作系统=管理+服务,管理与应用这两个服务有时会发生冲突
服务的目标:单个应用的运行效率最大化
管理的目标:系统的资源整体利用效率最大化
例:单纯强调公平性的调度策略往往资源利用率低
- 如细粒度的round-robin导致大量的上下文切换
解决办法:
"机制与策略相分离"的原则:
- 机制是相对稳定的策略是动态可调的
- 让操作系统兼具通用性与灵活性
| 操作系统的定义:
|
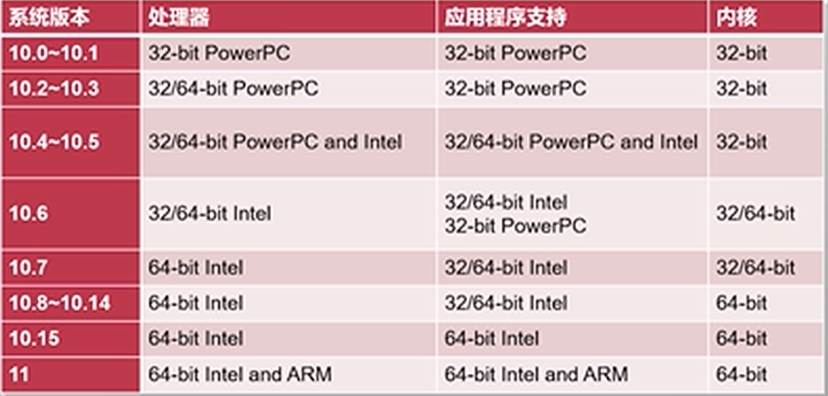
(三)MacOS的演变:从POWER到X86再到ARM64

Apple l
1976年,Apple发布第一个桌面计算机Apple l:
Apple l的OS最便宜、最快、最可靠、完全无bug的!
Apple l没有OS!
1977年,Apple ll:
使用Apple DOS对存储设备进行管理

Apple Macintosh
1984年,Apple Macintosh搭载 System Software 1.0 操作系统 (System 1)
单任务操作系统,使用Motorola68000,处理器(Motorola 68k)
1987年,操作系统演进到System 5 引入MultiFinder拓展
允许同时运行多个不同程序,但是需要程序配合,主动把处理器让给其他程序
1988年,System 6 发布
带来图形化界面,需要使用Motorola68030处理器提供硬件支持
1991年,System 7
全新的图形界面、更多的软件和许多其他新特性
System 7.6 => Mac OS 7.6
1994年,开始发布Power Macintosh使用PowerPC架构
Mac OS 7 同时支持Motorola 68k 和 PowerPC
Mac OS 7 内置 68k 处理器模拟器可以在 PowerPC 上运行 68k 程序
1999 年, Mac OS 9 发布
2001 年, Mac OS 9.2.2 发布——>经典 Mac OS 系统的最后一个版本
Mac OS X(X表示10) 与NeXTSTEP
Mac OS X 基于NeXTSTEP 系统
NeXTSTEP 是SteveJobs离开苹果公司后创建的 NeXT 公司所研发的操作系统,NeXT被苹果公司收购后,Steve Jobs 回到苹果公司,基于 NeXTSTEP 研发了Mac OS X。
早期使用 PowerPC 的 Mac OS X 系统中会存在一个兼容层来支持运行此前经典MacOS上的程序。直到苹果开始使用 Intel 处理器,对经典 Mac OS 的支持才被取消。
从 PowerPC到 Intel x86
2005年WWDC,SteveJobs宣布将逐步使用Intel 处理器
2006 年第一台使用 Intel 处理器的,Macintosh 与 Mac OS X 10.4.4 Tiger共同发布
此时的 Mac OS × 同时支持 PowerPC 和 x86 架构同样地,在 Mac OS X 中内置了 Rosetta 技术,能将 PowerPC 指令动态翻译成 Intel 处理器上的 x86指令进行执行
2009年, Mac OS X 10.6 Snow Le0pard 中移除了对 PowerPC 的支持,在此后的版本中也移除了 Rosetta 技术,意味着无法再运行PowerPC 程序。
32位到64位
2012年,苹果公司发布了OSX Mountain Lion(10.8)

OSX Mountain Lion(10.8)
除了在名字中去除了 Mac 字样之外,OS X 10.8 是一个只支持 64-bit 的操作系统
从 Intel x86 到 Apple Silicon ARM
2020年WWDC: Tim Cook,宣布在两年内完成从 Intel x86,处理器到 Apple Silicon ARM,处理器的转换

2020年Apple全球开发者大会
新发布的 macOS Big Sur 同时支持 x86-64 和,ARM64两种指令级架构
同时, Rosetta 2 技术可以动态地将 x86-64 ,指令转换成ARM64指令执行,因此可以在ARM处理器上运行x86程序
从POWER到Intel再到ARM
(四)ChCore架构简介
ChCore:微内核架构操作系统
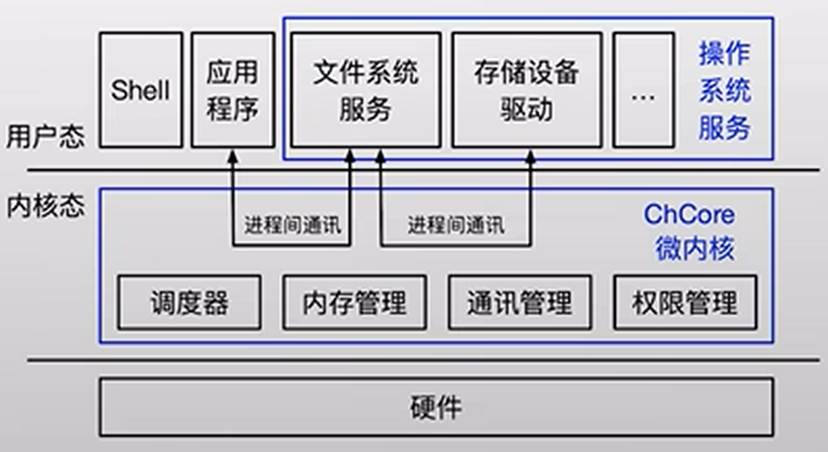
内核中仅负责必要的功能:启动,内存管理,进程管理,异常处理,IPC等
其他的系统服务会被实现为用户态系统服务:文件系统,驱动等
ChCore最先执行的是引导代码,引导代码将ChCore内核的代码加载到内存中,并完成其他硬件设置,如:处理器特权级,MMU配置
ChCore启动后,会进行内存管理,进程管理,进程间通信(IPC),调度等
对上与对下的交互方式:
内核与应用的交互:通过系统调用和异常,与用户态进程进行交互
内核与硬件的交互:通过处理硬件中断响应硬件请求
将中断和异常捕获并且,重定向到对应的处理函数中
用户态程序被分为两个部分:
一部分是用户的进程
另一部分是用户态系统服务(用户态系统服务包括了文件系统,驱动等)
用户态程序通过ChCore提供的IPC接口通信
ChCore中还实现了微内核中的能力(capability)机制
ChCore内核会记录用户态进程所持有的能力(cap)包括了所持有的物理资源,,对系统服务的调用
ChCore通过能力(cap)的管理,限制了用户态程序的权力,进一步预防了程序异常和内核bug
| ChCore实验:5个固定实验,1个自选实验 前5个实验将会完成内核的启动,内存的管理,用户进程,异常处理,多核处理,进程间通信(IPC),文件系统,Shell 实验6具有挑战性 |
二
(一)为什么选择ARM
ARM:广泛使用的指令集(手机,5G基站,笔记本……)

麒麟9000与A14
厂商自研的处理器

微软SQ2处理器与苹果M1处理器
ARM:正在走向服务器

鲲鹏920处理器(有64个核心)
ARM开发板

ARM开发板
ARMv8
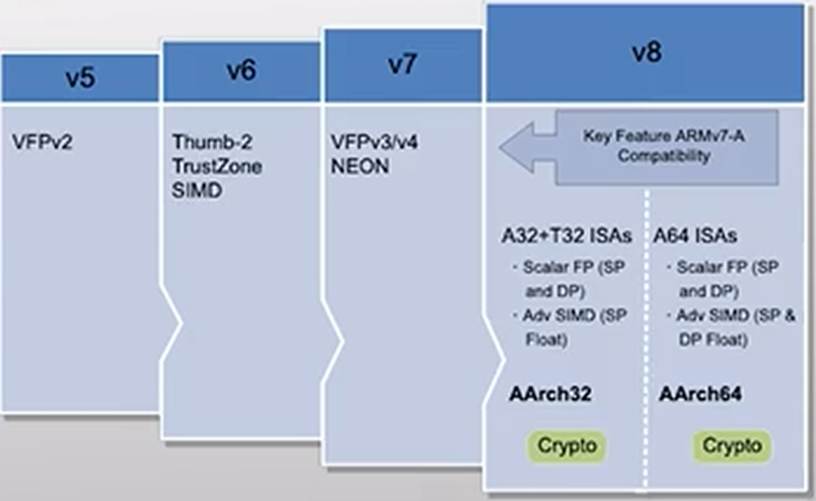
- 扩大物理寻址
- 4GB以外的物理地址
- 支持64位指令集
- TrustZone (自ARMv6开始)
- 硬件提供隔离的执行环境
- 低功耗高性能设计
- 如,自旋锁的优化
- AArch64
- 支持A64指令集
- AArch32
- 支持A32、T32、T16指令集
(二)AArch64体系结构
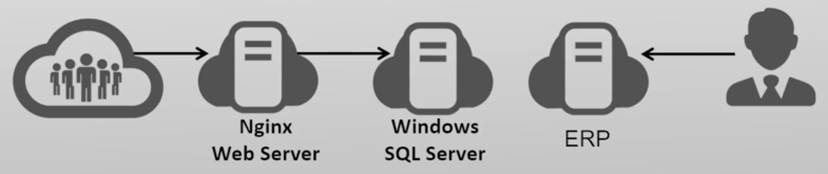
指令集架构——ISA(Instruction Set Architecture)
- CPU与软件的桥梁
- 包括CPU提供给软件的状态和指令
ISA的具体内容列举
- 执行模式
- 指令集、特权级、寄存器
- 安全扩展、性能加速扩张等
AArch64 ISA:软件能让CPU干什么?
PC (程序计数器): 指向当前执行的指令
指令长度相同 (RISC, 32bit)
PC 会被跳转指令修改:B,BL
AArch64 ISA的特点:
RISC
固定长度指令格式
简化访存指令:Load/store
简化寻址方式
AArch64特权级:不同软件使用CPU的权限
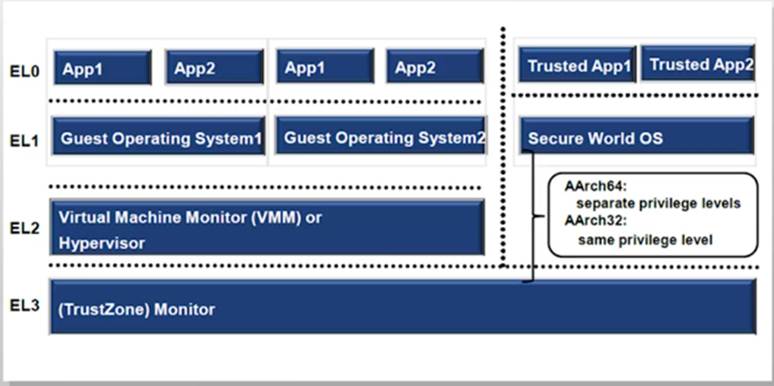
ELO:用户态程序
EL1: 内核
EL2: hypervisor
EL3: monitor
寄存器:信息存在哪里
31个64位通用寄存器
X0-X30
4个栈寄存器(切换时保存SP)
1SP_EL0,SP_EL1,SP_EL2,SP_EL3
3个异常链接寄存器(保存异常的返回地址)
ELR_EL1, ELR_ EL2, ELR _EL3
3个程序状态寄存器(切换时保存进程状态PSTATE)
SP_EL0, SP_EL1, SP_EL2, SP_EL3
系统状态寄存器
抽象进程状态信息(PSTATE)
条件标记 (Condition flags)
执行状态(Execution state controls)
异常掩码(Exception mask bits)
用户如何通过OS和外设交互的?
外设:CPU,键盘,内存,鼠标,硬盘显示器,网卡
输入
以键盘为例,OS接收键盘输入:键盘等外设具有控制器和缓冲区,将输入存入缓冲区
OS获取该输入的可能方法:
轮询:OS不断去读该缓冲区中的值(效率低)
中断:当控制器接收到输入后,打断CPU正常执行,OS进行处理(效率高)
高速设备——>万兆网卡:当满负荷接收网络数据时,用轮询的方式效率会更高一些,避免了来来回回的打断任务和恢复任务
输出:
显示器的显示过程
显示器与操作系统的交互主要是通过显存
- 操作系统将需要显示的内容放到显存
- 显示器以一定的频率扫描显存
比如30Hz、60Hz或144Hz,也就是每秒钟扫描的次数,可以理解为显示器“轮询”显存
| 显示器与操作系统的交互主要是通过显存,然后将显存的内容显示在显示器上,不是通过中断的方式 |
中断是如何被CPU感知的?
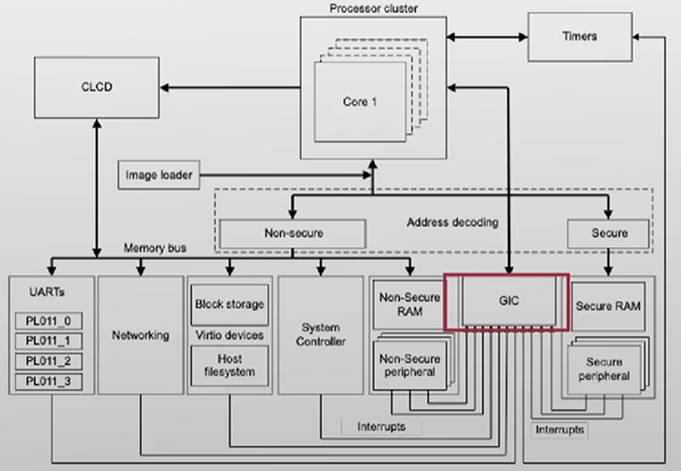
ARM的SOC结构
中断与异常的概念
中断(Interrupt)
- 外部硬件设备所产生的信号
- 异步:产生原因和当前执行指令无关,如程序被磁盘读打断
异常(Exception):
- 软件的程序执行而产生的事件
- 包括系统调用(System Call)
- 用户程序请求操作系统提供服务
- 同步:产生和当前执行或试图执行的指令相关
中断与异常的不同:
- 中断是来自CPU外部,主要是外部设备;而异常来自CPU内部,CPU甚至可以通过执行某条特定的指令来主动触发异常,从而实现从用户态到内核的态主动切换
- 中断一般是异步的,操作系统和CPU没有办法预测中断何时产生
例如:在磁盘读取数据的过程中,磁盘将数据准备好了之后发送中断信号到CPU, 通知CPU来将数据从磁盘读取到内存中,这个时间点CPU事先是不知道的
异常是同步的,当CPU执行到某一条非法指令时,一定会触发异常
例如:如果内存数据被交换到磁盘了,那么在访问这块内存时,也一定会触发异常
不同体系结构术语的对应关系
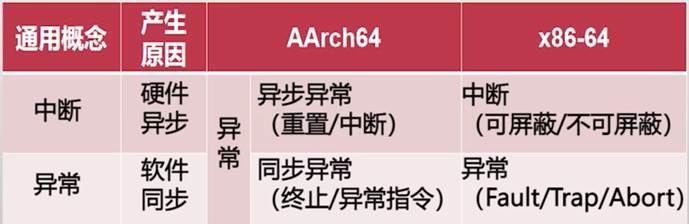
通用概念中的中断与异常
软硬件协同的处理流程
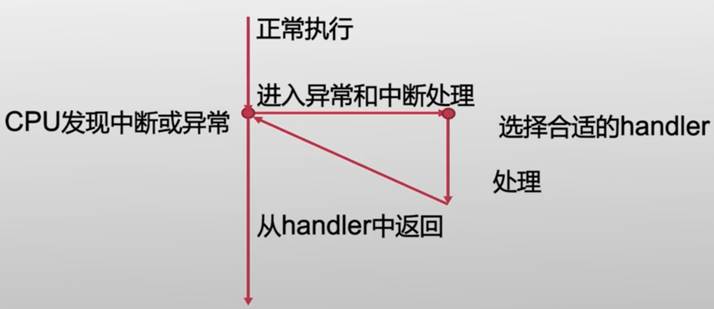
中断与异常的处理机制
中断与异常的处理使用同一套机制,差异仅在选择handler(处理函数)中体现
- 返回,eret 指令
| ELR_EL1 -> PC 恢复PC状态 SPSR_EL1 ->PSTATE 恢复处理器状态 降至EL0,硬件自动使用SP_ELO作为栈指针 恢复执行 |
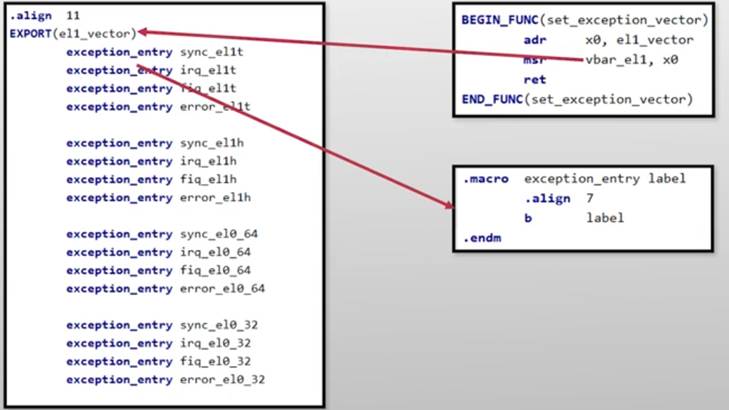
ChCore异常向量表配置
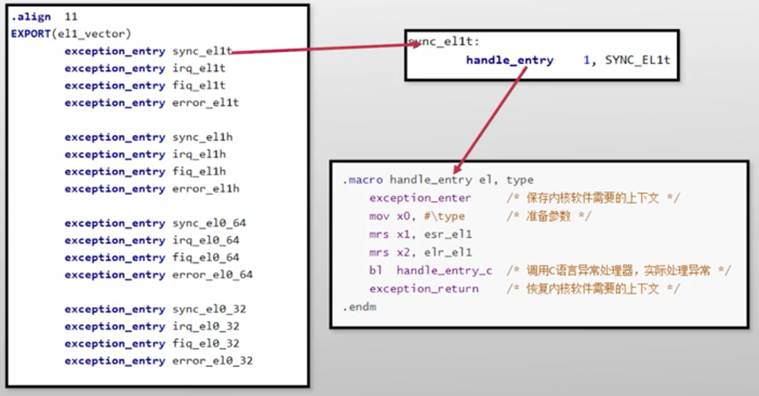
ChCore异常处理器
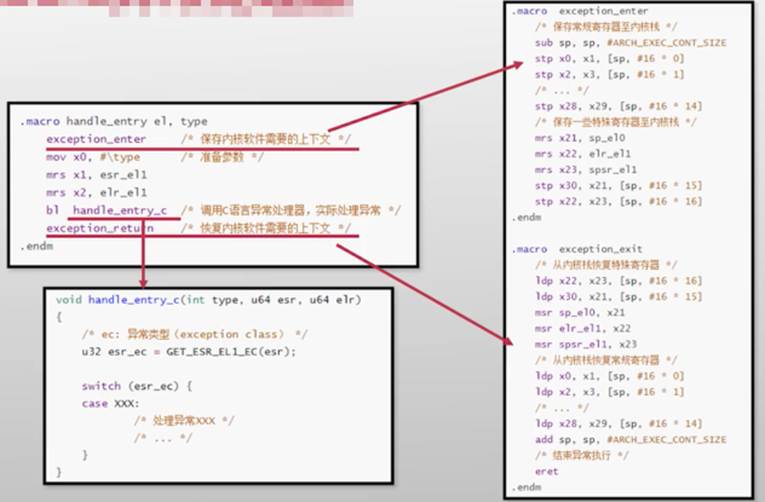
恢复
系统调用(Syscall)
- 指运行在用户空间的程序向操作系统内核,请求需要更高权限运行的服务
- 系统调用提供用户程序与操作系统之间的接口
系统调用方式-程序员视角
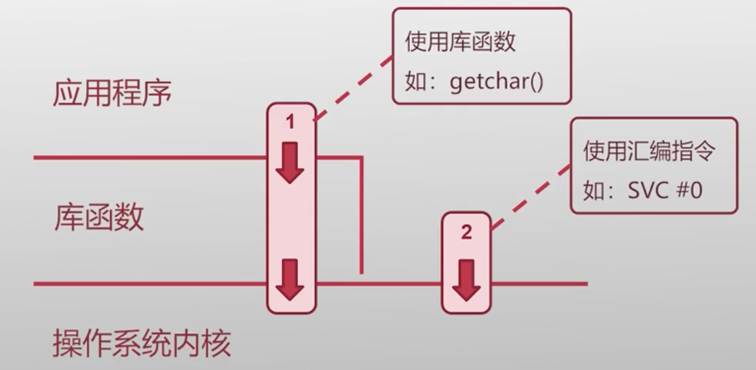
系统调用方式-硬件视角
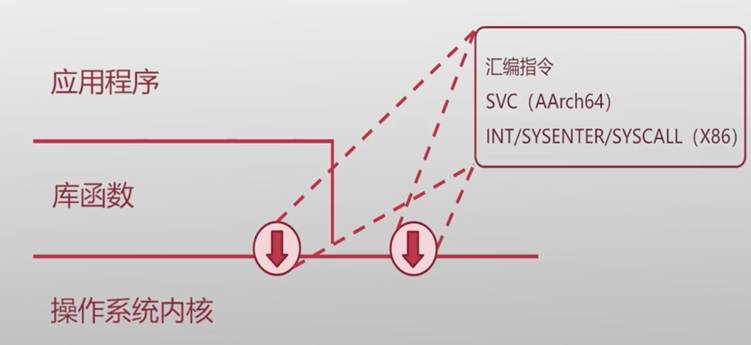
Linux的常用系统调用

用户指针检测
完备的指针检测十分耗时
需要遍历用户进程的所有合法内存区域进行检测
如果每一次内核使用来自用户的指针都要做如此耗时的检查,对性能的影响是非常大的
Linux解决办法:非全面检查
即使通过初步检测,用户指针仍然可能非法(如指向尚未分配的栈空间等)
直接将非法的指针交给内核使用会导致内核出现页错误,内核态的页错误通常被认为是bug,内核会打印异常信息并中止用户进程
处理用户指针问题:
内核代码仅使用特定代码片段访问用户指针(如copy_from_user)
由访问用户指针而导致内核内存错误的代码段是确定的
当内核发生页异常(Page Fault)时,内核会检查异常发生的PC
若异常发生的PC属于访问用户指针的代码段,Linux尝试对其进行修复
若不属于,则报告问题并终止用户程序
Linux中很多地方违反了这一规定,导致了许多安全漏洞
操作系统对上对下的交互
- ARM
在手机上广泛应用的架构、并且逐渐走向服务器
- ISA
软件与CPU的桥梁
- 在AArch64架构下,硬件中断的过程、处理器异常的过程、系统调用的过程本质上都是异常处理
- 内核与硬件、软件的交互方式
- 中断、异常(异常向量表)
- 系统调用(系统调用表)
三
案例——瓦萨沉船:
1626年到1628年间,瑞典国王下令建造的一艘军舰,由于追求极致的续航力、容量、火力及防护力,整船被建成不合乎物理常规地高大笨重,再加上在建造时没有填入足够的压舱物,瓦萨号即便在港口停靠时也不能依靠自身保持平衡。
尽管有着严重的结构缺陷瓦萨号依然被允许起航:不出所料的是,在出海航行不到几分钟后,瓦萨号便被一阵微风吹倒,继而全船倾覆。

瓦萨号沉船
操作系统中的“瓦萨号”:
1991-1995年,IBM投入20亿美元打造Workplace操作系统
由于目标过于宏伟,系统过于复杂,导致项目失败;间接导致IBM全力投入扶植Linux操作系统
在2020年,IBM对Linux的代码贡献依然排在前十,我国在Linux社区的贡献也逐步变大,例如:在Linux 5.10版本中,华为贡献了最多的Patch数
- 复杂系统的构建必须考虑其内部结构
- 不同目标之间往往存在冲突
- 不同需求之间需要进行权衡
- 操作系统的不同目标
- 用户目标:方便使用,容易学习,功能齐全,安全,流畅……
- 系统目标:容易设计、实现,容易维护,灵活性,可靠性,高效性……
- 降低操作系统复杂性
重要设计原则:策略与机制的分离
- 策略(Policy):要做什么——相对动态
- 机制(Mechanism):怎么做——相对静态
操作系统可仅通过调整策略来适应不同应用的需求

- M.A.L.H方法
- 模块化(Modularity)——>“分而治之”(Divide and Conquer)原则
一个复杂系统分解为一系列可以通过明确的接口进行交互的模块,并严格保证模块之间的界限
| 模块划分并不是越细越好,过多的模块反而会因为模块之间联系过多而无益于复杂度的控制;模块的划分要充分考虑高内聚和低耦合,使模块有独立性 现代操作系统中的模块化结构存在于:进程管理、内存管理、网络协议栈、设备驱动等 |
- 分层(Layering)
分层是指通过将模块按照一定的原则进行层次的划分,约束每层模块之间和跨模块之间的交互方式,从而有效的减少模块和模块之间的交互
| 分层原则:一个模块只能和同层模块以及相邻的上层或下层模块进行交互,而不能跨一层和再上一层或再下一层的模块进行交互 |
- 抽象(Abstraction)
抽象是在模块化的基础上,将接口和内部实现进行分离,从而使模块之间只需要通过抽象的接口进行相互调用,而无需关心各个模块之间的内部的实现
| 一个重要的抽象原则:宽进严出(避免错误或者恶意输入的效果在模块内传播) 尽可能严格的控制模块对外的输出,从而减少错误在模块间的传播 例如:Unix系列操作系统所提供的虚拟内存为物理内存提供了良好的抽象,使应用程序无需关心物理地址的具体位置,而只需要针对独立的、连续的虚拟地址空间进行设计。 |
- 层级(Hierarchy)
层级是另外一种模块的组织方式
| 首先将一些功能相近的模块组成一个具有清晰接口的自包含子系统,,然后再将这些子系统递归式地组成一个具有清晰接口的更大子系统 例如:一个公司组织架构中,一个经理管理一组成员,一组经理构成个部门,多个部门构成一个事业部,多个事务部构成一个公司 |
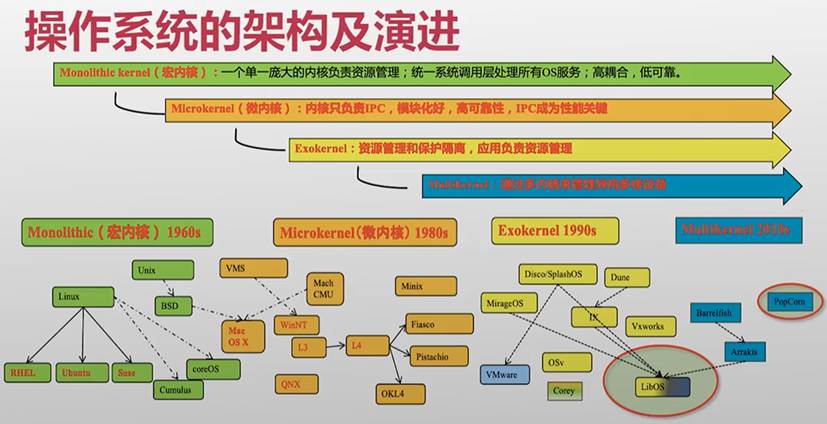
操作系统的架构组合及其演进
Minix是专门为教学设计的微内核,QNX是黑莓的微内核(广泛应用于车载、航空航天等对实时性和可靠性有极高要求的领域)
操作系统的架构不是一成不变的,而是根据不同的需要而不断变化
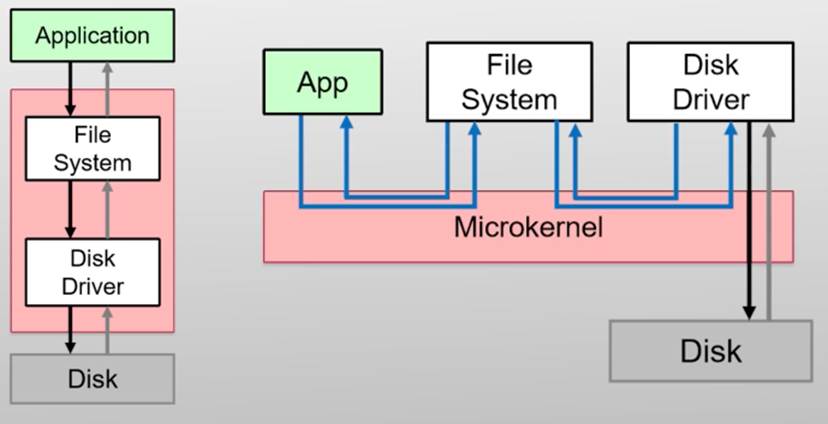
宏内核(Monolithic Kernel)——>平时最常见的Linux就是宏内核架构
整个系统分为内核与应用两层(kernel+shell,最早由UNIX提出)
- 内核:运行在特权级,集中控制所有计算资源
- 应用:运行在非特权级,受内核管理,使用内核服务
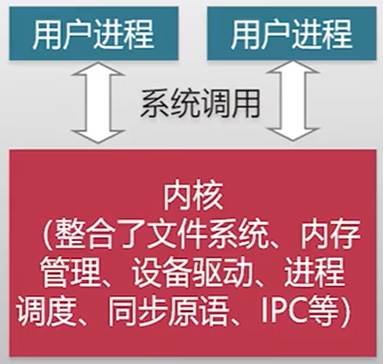
宏内核架构示意图
- 拥有有巨大的统一的社区和生态
- 针对不同场景优化了30年
- 安全性与可靠性问题:模块之间没有很强的隔离机制(牵一发动全身)
- 实时性支持:系统太复杂导致无法做最坏情况时延分析
- 系统过于庞大而阻碍了创新:Linux代码行数已经过2800万
- 向上向下的扩展:很难去剪裁/扩展一个宏内核系统支持从KB级别到TB级别的场景
- 硬件异构性:很难长期支持一些定制化的方式去解决一些特定问题
- 功能安全:一个广泛共识:Linux无法通过汽车安全完整性认证(ASIL-D)
- 信息安全:单点错误会导致整个系统出错,而现在有数百个安全问题(CVE)1
- 确定性时延:Linux花费10+年合并实时补丁,目前依然不确定是否能支持确定性时延
引入:宏内核的问题在与所有的模块都整合在一起,导致系统越来越复杂,牵一发而动全身,那么自然会想到是不是可以把内核变小,把功能放到用户态作为应用运行
安装一个应用是很简单的,不用的时候还可以直接删掉,那么如果我们需要增加新的操作系统功能,就像安装一个新应用一样简单
设计原则:最小化内核功能
将操作系统功能移到用户态,称为“服务”(Server),在用户模块之间,使用消息传递机制通信
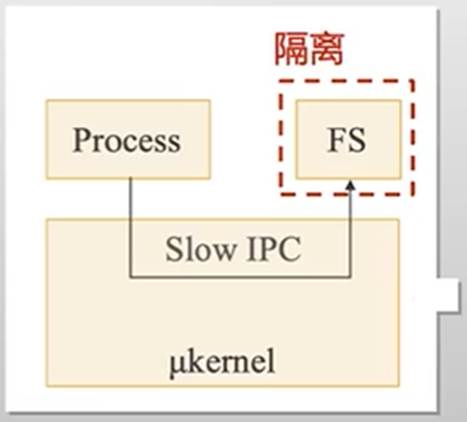
例:文件的创建
| 创建一个文件,就要从应用通过微内核调用文件系统,文件系统通过微内核调用磁盘驱动,然后再依次返回 优点:可以随时安装新的文件系统和磁盘驱动,即使出现安全漏洞或者一些bug,也不能直接影响整个系统 |
- 1969年,RC4000多路编程系统
- 提出模块化设计,允许模块间交互
- 提出复杂消息通信机制用于交互
- 提出"分离策略与机制"的原则
- 提出"管程”(Monitor)的概念
- Per Brinch Hansen等开发者
- 启发了后来的微内核
Lauesen,S.(1975).Alargesemaphorebased
operatingsystem.Commun.ACM,18,377-389.
- 1985年,Mach 发布(公认的第一个真正意义上的微内核)
- 由CMU开发,RickRashid领导
- 对操作系统发展产生了重大影响
- 1986年,Mach 2.5(性能比UNIX差25%)
- 包含大量BSD的代码,,如1:1的task与process映射,导致内核比UNIX更大
- 取得了商业成功,用于NeXT,最终被苹果收购

- 1990年, Mach 3.0(性能比UNIX差67%)
- 规避法律风险(内核还是微内核架构),去掉了BSD的代码,重写了IPC以提高性能
- 提出"continuation",为用户态应用提供了更多控制,允许应用自己在切换的时候保存/恢复上下文,减小microkernel
Mach实现了哪些功能?
- 任务和线程管理
- 任务,是资源分配的基本单位;线程,是执行的基本单位(对CPU的抽象)
- 对应用提供调度接口应用程序可实现其自定义的调度策略
- 进程间通信(IPC)
- 通过端口 (port)进行通信
- 内存对象管理(对内存资源的基本抽象)
- 虚拟内存
注:Mach允许用户态代码直接实现内存换页,应用程序可以在一定程度上管理自己的虚拟内存
- 系统调用重定向(允许用户态处理系统调用)
- 支持对系统调用的功能扩展,例如,二进制翻译、跟踪、调试
- 设备支持
- 通过IPC实现(通过port来连接设备)
- 支持同步设备和异步设备
- 用户态的多进程
- 类似用户态的线程库,支持waitO/signal0等原语
- 支一个或多个用户态线程可映射到同一个内核线程
- 分布式支持
- 可透明地将任务与资源映射到集群的不同节点
L3/L4:极大提升IPC的性能(Mach的性能一直被诟病,主要原因是IPC的性能差)
- L4的IPC性能比Mach快20倍
- IPC仅传递信息:使用寄存器传参,限制消息长度
- 内核去掉了IPC的权限检查等功能,交给用户态判断
- 系统服务的接口直接暴露给用户态,可能导致DoS攻击
- 启发了大量相关系统:Pistachio.L4/MIPS.Fiasco等

seL4:被形式化证明的微内核
- 基于L4的微内核
- IPC机制:端点 (endpoint)
- 通过Capability进行IPC的权限判断
- Capability可被复制和传输
- 第一个完成形式化验证的内核
- 8700行C,bug-free
- 没有缓冲区溢出、空指针等错误
- bug的定义:取决于specification

- 对C的限制,以方便验证
- 栈变量不得取引用,必要时用全局变量
- 不使用函数指针
- 不适用union
- 用Haskell构造原型
- 用于验证
- 再手动转换为C(executable suspication,可以去辅助证明C代码与SUSPICATION是一致的)
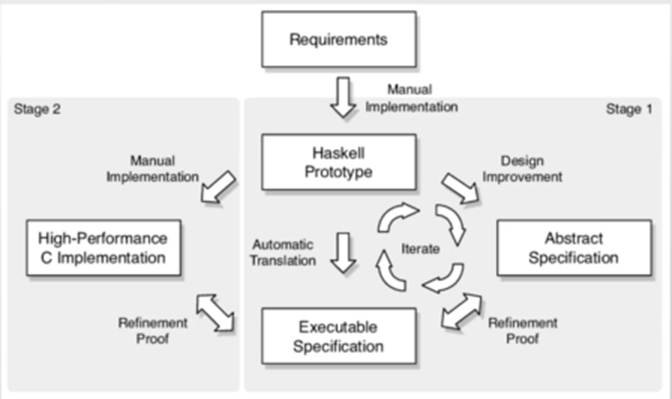
Comprehensive Formal Verification of an OS
Microkernel,2004
| 此项目整整用了20个人年(9个人年用于开发,11个人年用于形式化验证) 验证成本:大约为每行代码200~400美元(考虑到bug free,这个成本还是可以接受的) |
- QNX:Quick UNIX
- 使用Neutrino微内核
- 1980年发布
- 2004年被Harman国际收购
- 2010被黑莓收购
广泛应用于于交通、能源、医疗、航天航空领域,如波音(证明了自己的安全和可靠性)
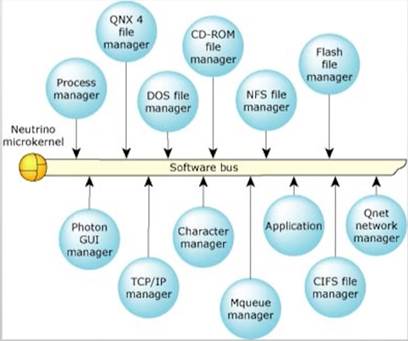
QNX
- Google开发的全新OS
- 试图覆盖多个领域,具体用途未知
- 使用Zircon微内核
- 仅提供IPC、进程管理、地址空间管理等功能
- 教学用的微内核
- 阿姆斯特丹自由大学,Andrew Tanenbaum教授

- 被用于Intel的ME模块
- 也许是世界上用的最多的操作系统.
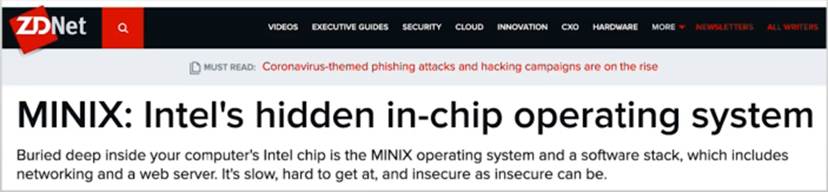
- 优点:
- 易于扩展:直接添加一个用户进程即可为操作系统增加服务
- 易于移植:大部分模块与底层硬件无关
- 更加可靠:在内核模式运行的代码量大大减少
- 更加安全:即使存在漏洞,服务与服务之间存在进程粒度隔离
- 更加健壮:单个模块出现问题不会影响到系统整体
由于这些优点,在上世纪80/90年代,“微内核”一度成为下一代操作系统的代名词
- 缺点:
- 性能较差:内核中的模块交互由函数调用变成了进程间通信

- 生态欠缺:尚未形成像Linux一样具有广泛开发者的社区
- 重用问题:重用宏内核操作系统提供兼容性,带来新问题
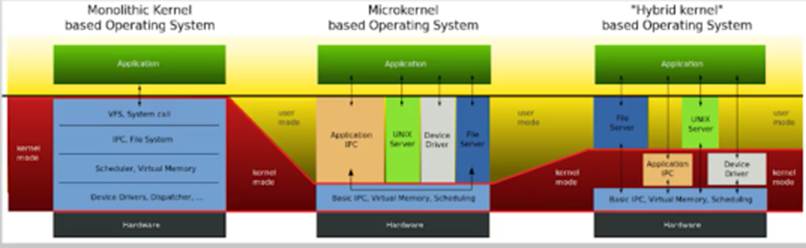
微内核
- 混合内核架构(宏内核与微内核的结合)
- 将需要性能的模块重新放回内核态
- 例:macOS /iOS=Mach微内核+BSD 4.3+系统框架
- 例:Windows NT = 微内核+内核态的系统服务+系统框架
- · Integral子系统(用户态)
负责处理I/O、对象管理、安全、进程等
- ·环境子系统(用户态)
POSIX
- Executive (内核态)
- 为用户态子系统提供服务
- Microkernel
- 提供进程间同步等功能
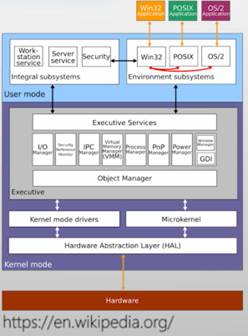
- XNU内核
- 基于Mach-2.5打造
- BSD代码提供文件系统网络、POSIX接口等
- macOs与iOs
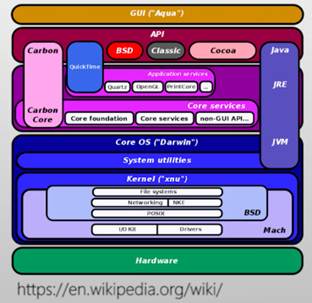
这种混合架构在现实架构中获得了巨大的成功,但同时也丧失了微内核的高安全、高可靠等优势
(四)外核Exokernel
外核是由Frans Kaashoek等教授提出的一种内核架构

Frans Kaashoek
- 外核(Exokernel不提供硬件抽象)
- 只要 内核提供抽象,就不能实现性能最大化
- 只有应用才知道最适合的抽象 (end-to-end原则)
- Exokernel不管理资源,只管理应用
- 负责将计算资源与应用的绑定,以及资源的回收
- 保证多个应用之间的隔离
- 外核的功能
- 追踪计算资源的拥有权
- 保证资源的保护
- 回收对资源的访问权
计算资源与应用绑定,应用就可以完全独占对资源的访问,但内核依然有回收资源的能力,防止恶意应用或者出现问题的应用占了资源而不归还
将LibOS与计算资源绑定
- 可用性:允许某个LibOS访问某些计算资源(如物理内存)
- 隔离性:防止这些计算资源被其他LibOS访问
- 库OS(LibOS)
- 策略与机制分离:将对硬件的抽象以库的形式提供
- 高度定制化:不同应用可使用不同的LibOS,或完全自定义
- 更高性能:LibOS与应用其他代码之间通过函数调用直接交互
- Exokernel的性能提升
- 未修改应用性能最多提升4x
- 定制化应用性能最多提升8x
Unikernel(单内核)
虚拟化环境下的LibOS
- 每个虚拟机只使用内核态
- 内核态中只运行一个应用+LibOS
- 通过虚拟化层实现不同实例间的隔离
| 适合容器等新的应用场景
|
Exokernel架构的优缺点分析
- 优点
- OS无抽象,能在理论上提供最优性能
- 应用对计算有更精确的实时等控制
- LibOS在用户态更易调试,调试周期更短
- 缺点
- 对计算资源的利用效率主要由应用决定,难度大
- 定制化过多,导致维护难度增加,应用生态天然难以统一
(五)多内核/复内核(Multikernel)
- OS内部维护很多共享状态
- Cache一致性的保证越来越难
- 可扩展性非常差,核数增多,性能不升反降
- GPU等设备越来越多
- 设备本身越来越智能设备有自己的CPU
- 通过PCIe连接,主CPU与设备CPU之间通信非常慢
- 通过系统总线连接,异构SoC(System on Chip)
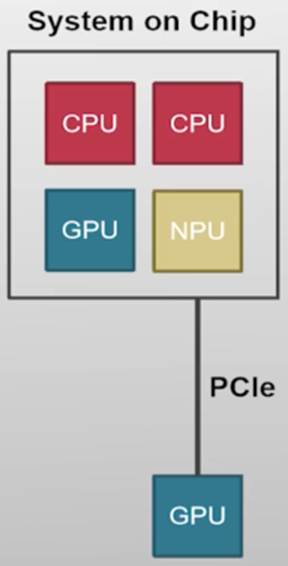
为了既有CPU的可扩展性持应用的可用性,把分布式的思路应用到多核场景——>Multikernel
Multikernel的设计
- 在每个core上运行一个小内核
- OS整体是一个分布式系统
- 应用程序依然运行在OS之上
Barrelfish操作系统(Multikernel操作系统)
- 来自ETHZurich和微软研究院
- 支持异构CPU
- 在CPU核与节点之间提供通用异构消息抽象
- 大约10,000行C,500行汇编代码
除了CPU的核心外,计算机里的智能设备越来越多,如:智能网卡,智能SSD,GPU,AI加速器等
这些设备相当于一台小型计算机,包含了自己的CPU、内存,能够运行第三方代码,如 :
- 智能网卡,往往包含ARM CPU,允许系统中关于网络相关的操作,如:将TCP协议栈部署到网卡中运行,进一步解放CPU
- 智能SSD:在智能SSD的ARM CPU上运行了一个数据库;运行自己的操作系统,用来管理以及服务第三方的应用
- 支持异构体系结构——ARM、x86等
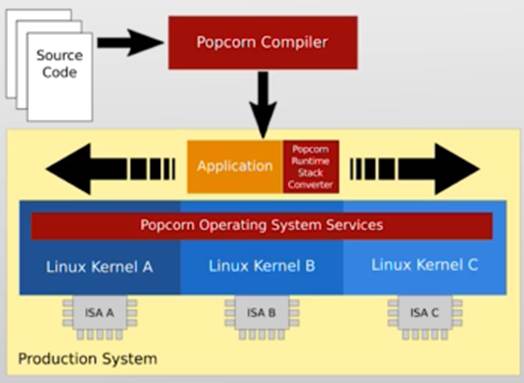
Popcorn Linux系统
- 多个Linux内核副本
- 套代码编译不同副本
- 不同ISA不同副本
- 多个副本同时向上提供OS服务
| 除了设备与设备之间有异构性,设备与设备之间的连接也存在异构性:
|
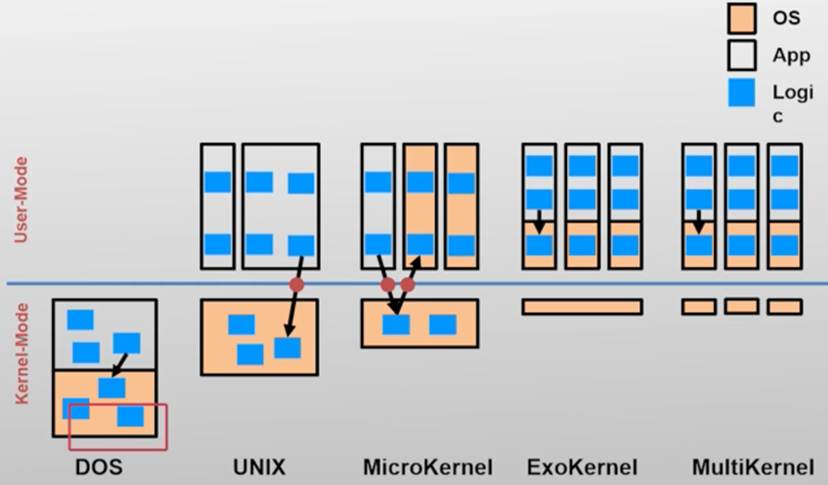
简单结构(如:DOS)
DOS没有考虑内核态与用户态的分离,而是把应用和操作系统都运行在内核态,所以隔离能力很差,一旦出了问题,就不得不整个机器重启
这种结构和Unikernel很像,不同之处是Unikernel运行在虚拟机中,隔离能力较好
- 系统软件需要一条演进之路
- 尽可能集成现有的POSIXAPI/LinuxABI
- 避免棘手的系统调用(如fork)
- 避免不可扩展的POSIXAPI
- 系统软件一直在不断演化
- 例: Linux Userspace I/O (UlO),向微内核近了一步
- 单节点下也存在更多的分布式、低时延的可编程设备
- 非易失性内存的出现可能推动存储层次在OS中的完全改革,用户态文件系统可能会成为主流
四
4.1 为什么要有进程?
在我们的电脑中,同时运行着很多不同类型的程序,比如我们编程使用的工具,听音乐时用的播放器,休息时玩的游戏等等。现代操作系统可以同时运行成百上千个程序。
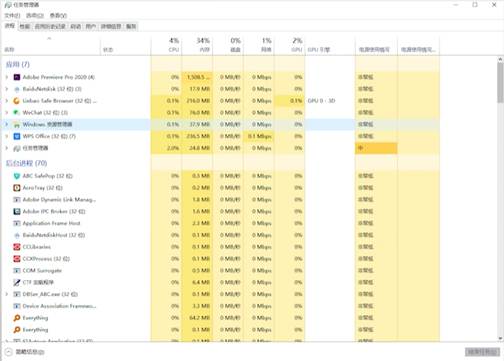
Windows资源管理器
在资源管理器里,除了启动的工具、游戏、播放器以外,还能看到很多操作系统启动的程序。通常程序的数量都超过一百个。由于运行中的程序数量多、特征各异,管理起来相当麻烦。
为了方便操作系统对运行中的程序进行管理,首先需要一个统一的抽象
| 虽然编程工具、游戏、音乐播放器这些程序的功能各异,但它们也有很多共同点
基于这些共同点,操作系统提出了进程这一抽象,每个进程都对应一个运行中的程序 |
由于进程反映的是不同程序之间的共同特点,因此它需要包括以下两类内容:
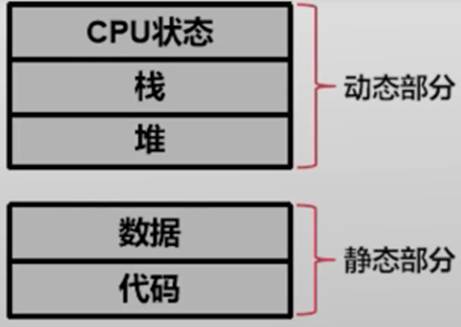
- 静态内容:程序运行过程中所需的代码和数据,原本保存在可执行文件中,进程需要包含这些内容才能正常运行
- 动态内容:在运行过程中,进程还会动态地产生很多状态。一般来说,每个进程都有自己的栈结构用来保存运行过程中产生的临时变量;另外,每个进程还会有堆结构,一般用来保存存活时间较长的变量和数据。此外,“动态"内容还包括了一些硬件的状态,比如CPU中寄存器的状态等等。
播放器、编程器,游戏等等,在操作系统视角下都是包含数据、代码、堆栈等内容的“进程”。在进程抽象的基础上,操作系统实现了对于运行程序的高效管理。
4.2进程"同时"运行的奥秘:分时复用与上下文切换
进程“同时”运行的奥秘
操作系统到底是使用了什么方法,来支持在有限的资源上“同时”运行数十倍甚至数百倍数量的进程呢?
答案是:“分时复用”的机制
就是让进程轮流使用CPU资源。由于操作系统通过进程这一抽象实现了对于运行程序的统一管理,它可以任意控制进程的运行和暂停,也可以控制CPU资源由哪个进程使用
| 假设我们有两个进程A和B,一个CPU。操作系统可以首先把CPU资源交给A执行。在A执行一段时间后,让它暂停,然后把CPU资源交给B执行。在B执行一段时间后,又让它暂停,把CPU资源又交还给A,这样循环往复就实现了a和b这两个进程对于cpu资源的分时复用 |
每个进程的单次执行时间其实是非常短的。比如在Linux操作系统中,单次执行时间通常不会超过100毫秒。也就是说,在短短一秒内,操作系统已经让A和B两个进程交替执行了几十次甚至上百次,正是因为进程以如此高的频率切换执行,而我们并不能识别出如此高频率的切换,因此才产生了同时执行多个应用程序的错觉
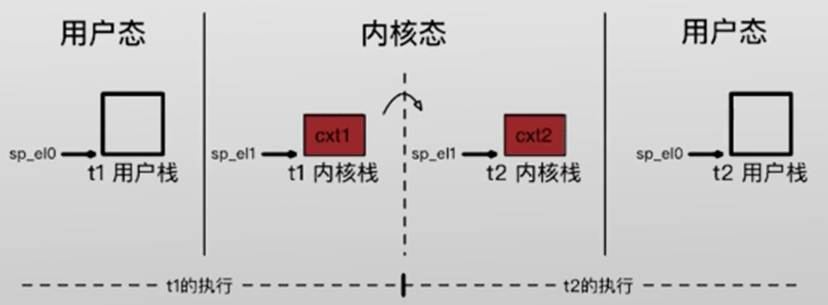
假设CPU上正在执行进程A,此时操作系统准备暂停进程A,并把CPU交给进程B执行。但是,此时CPU中还保存着进程A的数据,这些数据往往不能被进程B直接使用
此时进程A的代码在通用寄存器X1中保存了值1而进程B在上次执行时在X1中保存了值0。如果操作系统直接将CPU交给进程B执行,不对CPU中的寄存器数据进行恢复的话,那么进程B就会使用错误的数据继续执行,很可能导致程序错误甚至崩溃
| 为了解决这个问题,操作系统提出了“上下文”,即context的概念。操作系统提出了上下文的概念。每个进程都有自己的上下文,其中包含了进程运行过程中的所有状态上面例子中提到的CPU中的寄存器数据就是上下文中的重要组成部分 每当操作系统需要将CPU从一个进程手里交给另一个进程时,它会首先对前一个进程的上下文进行保存然后对后一个进程的上下文进行恢复,这样才能使进程正确地交替执行。而这个上下文保存与恢复的机制,就称为上下文切换,它是实现分时复用(也就是交替执行)的关键。 |
过程:在引入了上下文切换的机制后,当操作系统需要从进程A切换到进程B执行时
- 首先把进程A包含寄存器X1在内的上下文状态保存起来
- 之后,操作系统会找到进程B的上下文,将其中的寄存器状态(比如X1中的值)重新载入到CPU中,完成上下文的恢复
- 最后,操作系统把CPU交给进程B,让它执行
- 可以看到,在引I入上下文切换后,每个进程总是可以从上次暂停的地方,使用保存好的状态继续执行,不会出现前面看到的寄存器状态错误的情况了
4.3 进程的创建
我们总是希望能以一个编程者的视角看待事物。在我们编程的过程中,我们应当如何与进程打交
道,我们编写的代码又会对计算机中的进程带来什么样的影响呢?
实际上,操作系统已经定义了很多对进程进行操作的接口,使用这些接口可以对进程进行创建运行、暂停、终止等等
接口—fork
Linux中用于进程创建的接口——fork
- 这一接口可以说将"极简主义"用到了极致:它的名字很短,不需要任何参数,返回值也很简单,是整型
fork这个接口之所以能描述进程的创建过程,是因为它的创建方式比较特别,
- 当一个进程调用fork时,操作系统会创建一个和它“一模一样"的新进程,两个进程拥有完全相同的“静态"内容(代码和数据)和“动态"”内容(堆、栈、CPU状态等),但是这两个进程是完全独立,互不干扰的
| C |
首先将x复制为42
然后调用fork接口(此时,操作系统会创建一个“一模一样”的新进程,两个进程都是刚调用完fork正要返回的样子)
- 怎么区分哪个是新进程,哪个是旧进程呢?
| 操作系统为了解决这个问题,为两个进程加入了一点不同,使它们并不完全一样:对于新进程,操作系统会将返回值设为0;而对于新进程,操作系统则会将返回值设为非0 因此,在程序中通过对于fork返回值的判断,就可以辨别出新旧进程,并进行相应的处理 |
两个进程的x都是42,输出结果相同
最后如果在命令行观察输出结果,会发现一个有趣的事:
代码有时候输出的是"new:x=42(换行)old:x=42",有有的时候输出的是"old:x=42(换行) new: x=42"
两个进程虽然“长得很像”,但它们是独立执行互不影响的,它们执行的顺序只依赖于操作系统决定先将CPU资源给哪个进程
fork是如何实现的?
操作系统首先需要找到进程所包含的所有状态,这就包括了之前介绍的“静态”内容(即代码和数据)和“动态"内容 (即堆、栈等),操作系统可以把这些状态完整地复制一份作为新进程的状态
| 比如上个例子,旧进程保存了一个值为42的变量,那么新进程也会获得一个相同的拷贝,值也为42。最后,操作系统再制造一点微小的不同:把新进程和旧进程的返回值分别置为0和非0,让我们能够分辨 |
4.4进程的执行:exec
fork的局限性
由于fork只能创建出与原进程“一模一样”的新进程,这其实只是一种“复制”
- 例子:如果一个音乐播放器进程调用了fork,那么产生的新进程也只能是音乐播放器
| 如果我们要听音乐,用鼠标点击音乐播放器打开它,此时任务管理器里会多一个“音乐播放器”进程,而不会是在一个音乐播放器上点击"fork"创建出一个一模一样的音乐播放器,由此可知,哪怕是对于我们日常生活中创建进行的操作,fork也是不够的,因此,需要另一个接口来帮忙,即exec |
引入exec
exec:与fork单纯进行“复制”不同,exec会让进程“变身”,转变为与原进程完全不同的进程
提出的需求:在用鼠标点击音乐播放器后,操作系统可以使用fork任意创建一个新进程,再立即调用exec使其“变”成音乐播放器进程
- 组合使用fork和exec两个接口,满足日常生活中对于进程创建的需要
exec是通过更改进程对应的可执行文件来实现的
exec的接口
- 注意
我们说exec是"一个"接口但实际上它是一组接口,可以用于不同场景
在Linux里输入man exec,可以看到有execl,execlp,execle,execv等等接口
简单的execv
- execv共接收两个参数,其中第一个参数就是可执行文件的所在地址
- 当execv被调用时,它就会根据指定的地址加载新的可执行文件,替换掉原有的可执行文件,并开始全新的执行
例子:将第一个参数指定为音乐播放器可执行文件的所在地址
- 比如:D盘下的player.exe文件就可以使进程变成一个音乐播放器了
第二个参数是传给新进程的参数
- main函数的申明方式:①参数的数量②保存参数的数组
- main函数里的参数就和execv被调用时指明的参数一一对应
- 当execv被调用时,操作系统会计算出参数的数量,并帮助将这些参数传给新进程的main函数
fork和exec两个接口可以实现比较强大的功能了
例子:shell程序
- 通过fork和exec两个接口就可以实现一个简单的简单的shell程序了
用fork和exec来实现shell
- Shell的程序逻辑比较简单
- 不断地接收用户的输入
- 输入的字符串用来执行
- 简单的shell程序的C语言实现
| C |
包含了一个while循环,不断地读取用户的输入,然后解析用户的输入
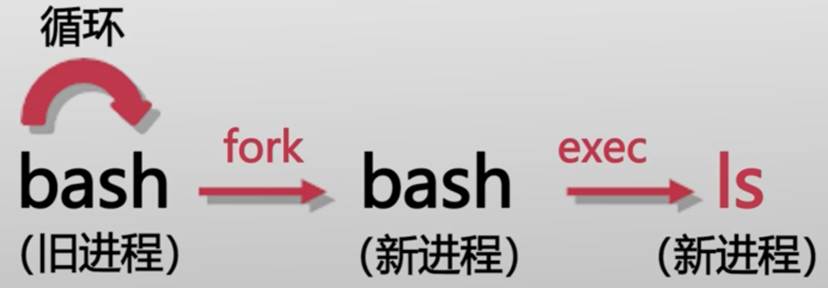
比如:shell程序发现用户输入了ls,因此知道它实际上是要调用/bin文件下的ls命令,之后它会fork出一个新的进程,然后使用execv,使这个新进程变身成一个ls进程,这样就达到了执行ls命令的效果
4.5为什么要引入线程?线程有什么特点?
| 例子: 假设我们的小明同学有一台“四核”的笔记本电脑,也就是说这台电脑同时能运行四个程序。小明带着这台笔记本去报名参加了一个编程竞赛,这个比赛要求尽量快地对数据进行分析处理。因此,小明希望能够充分利用笔记本上的四个“核心”让它们都参与数据分析处理。 小明怎样才能充分利用这些计算资源呢? |
方法一:创建多个进程
- 小明使用C++编写数据分析处理的程序,运行这个程序,调用fork创建出四个“一模一样“的进程,因此可以在四个CPU上同时处理
fork出来的四个进程可分别在四个“核心”上独立运行,所以可以把CPU资源都利用起来
存在的问题:
- 对数据的修改
- 在数据分析的过程中,会对数据进行修改,在单个进程里,由于数据是被进程独享的,这种修改是没有任何问题的
如果一个进程要修改数据它要怎么告知其他进程呢?
如果两个进程要同时修改数据里的同一块,它们要如何进行协调呢?
- 每个进程都是相互独立的,都以为自己独占这块数据,因此,与其他进程的协调就变得比较复杂
- 协调次数过多,就会把大部分时间都花在协调上,也就不能充分利用CPU的资源了
由于多个进程的数据共享和协调比较麻烦,那么我们能不能就只跑一个进程?
- 单个进程独占数据,也不存在数据共享导致的问题
- 但是单个进程同时只能跑在一个核心上,又不能充分利用CPU资源了
- 这种抽象是一种可并行的单元,
- 可以独立运行在不同的核心上,这样可以充分利用CPU资源
- 这些并行单元又运行在同一个进程中,又能比较方便进行数据共享和协调同步,开销比较低
这种并行单元就是——“线程”
优势:
- 轻量级
- 独立并行执行
- 依附于进程存在
- 进程的好的补充
线程是进程内部更加轻量级的运行单元
线程的诞生时间比进程更晚
- 20世纪60年代,操作系统只有进程的概念,当时也是因为硬件资源有限,没有必要使用细粒度的并行单元
- 在1967年,IBM/OS操作系统中出现了类似线程的概念(称为"task"),但没有得到广泛的应用
- 到了1991年,在Linux操作系统诞生的时候,没有对线程提供直接的支持
- Red Hat的研究人员对Linux内核进行了修改,为线程提供了原生支持
- 2003年,进入了Linux主线,并一直沿用到了现在
进程内部引入线程这样的抽象,对进程会带来怎样的变化呢?
- 会对进程包含的内容、上下文、接口实现等方面都会产生影响
进程包含的内容:
- “静态”内容:代码和数据
- “动态”内容:进程的堆、栈、寄存器状态等
- “静态”内容:所有线程会共享代码和数据
- “动态”内容:每个线程也是独立的执行单元 ,因此它们拥有一部分自己私有的状态(各自私有的栈结构,以及寄存器状态),但每个线程会共享同一个堆结构,因此堆结构就可以用来比较方便地去实现多个数据线程之间的共享
例子:
小明可以在堆上申请一大块内存,用来保存需要共享的数据(数据共享方便)
| 如果多个线程都要对同一部分的数据进行修改 ,怎么对它们进行协调呢?
由于线程都在同一个进程内部,所以同步原语的结构一般比较简单,同步协调的效率也比进程之间的同步高很多 每个线程都是可以独立执行的单元,它们也都需要拥有各自的上下文,保存各自的状态 |
- 操作系统的上下文切换需要一些修改:
- 如果一个进程拥有多个线程,那么每次上下文切换时,操作系统只选择其中一个线程并让其在一个CPU上执行
“先保存一个上下文,再恢复另一个上下文”,只不过切换的单元有进程变成了线程
- 线程的引入还会对进程提供的接口产生影响
假设一个进程创建了两个线程现在它调用fork,产生的模一样”进程包含几个线程呢? 答:当一个包含两个线程的进程调用 fork() 时,产生的子进程会复制父进程中所有线程的状态。但是,在子进程中实际上只有一个线程是运行的,即调用 fork() 的那个线程。 |
4.6进程与线程的关系是什么?两者有什么异同?(小结)
我们使用四核计算机时,会同时打开多个文件(不只4个),任务管理器的这些程序都是在不断的暂停和重启的高速切换中,在任何具体的时刻只有4个程序真正在运行,但是因为暂停和重启的切换速度非常快,因此我们会误以为这些程序都在同时执行
- 我们平时使用计算机的时候有时候打开的程序太多了,计算机就可能出现卡顿的现象。用本章的知识,你们能分析出原因吗?
计算机卡死现象产生的原因:打开的程序多,管理的进程多,上下文切换不及时,就卡死了
- 有时候打开的程序不多,也会出现卡顿,这可能是什么原因呢?
卡顿原因:程序是多线程的,操作系统把线程作为调度的基本单元,所以还是有可能切换不过来
有时候即使打开比较少的程序,而且它们都是单线程的,还有可能卡顿的情况,为什么?
且听下回分解!
五
5.1内存管理的挑战
- 常说的"内存条"就是指物理内存
- 数据从磁盘中加载到物理内存后,才能被CPU访问
- 操作系统的代码和数据
- 应用程序的代码和数据

内存条
在计算机中,CPU不能直接访问存储设备(如:磁盘),而是只能访问内存,所以CPU只有先把代码和数据从存储设备(如:磁盘)加载到内存上,才能访问和执行
- 硬件
- 物理内存容量小
- 软件
- 单个应用程序+(简单)操作系统
- 直接面对物理内存编程
- 各自使用物理内存的一部分
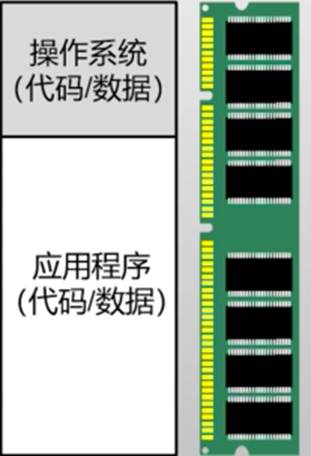
- 多用户程序
- 计算机昂贵,多人同时使用(远程连接)
- 分时复用CPU资源
- 保存恢复寄存器速度很快,所以CPU开销小
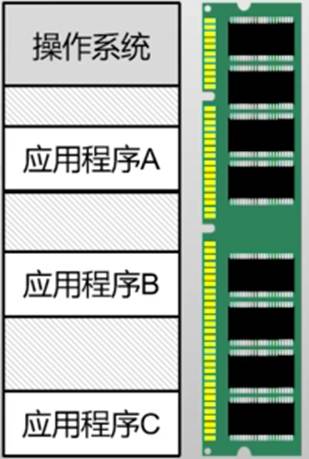
- 分时复用物理内存资源
- 将全部内存写入磁盘开销太高
- 同时使用、各占一部分物理内存
- 没有安全性(隔离性)
如何让OS与不同的应用程序都高效又安全地使用物理内存资源?
IBM 360的内存隔离:Protection Key
- Protection key机制
- 内存被划分为一个个大小为2KB的内存块(Block)
- 每个内存块有一个4bit的key,保存在寄存器中。因此,1MB内存需要512个保存key的寄存器,占256Byte
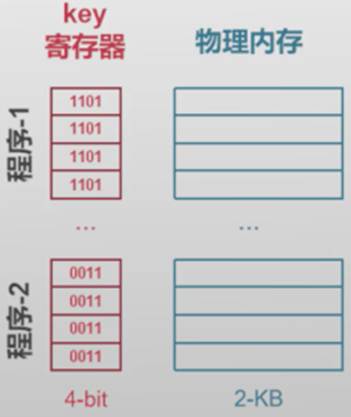
- 每个程序对应一个Key
- CPU用另一个专门的寄存器,保存当前运行程序的key(不同程序的key不同)
一个程序访问一块内存时,CPU检查程序的Key与内存的Key是否匹配,匹配则可以访问,不一致则不能,从而实现不同程序之间的隔离
Protection Key机制的挑战
- 应用加载与隔离
- 不同应用被加载到不同的物理地址段
- 不同应用的key不同,以保证隔离
| 问题:同一个二进制文件,程序-1加载到0000-1000地址段,程序-2加载到5000-6000地址段 如果要运行"JMP 42",程序-1能执行,程序-2会出错,因为程序2的地址最低也是5000 |
- 解决方法
- 代码中所有地址在加载过程中都需要增加一个偏移量,如改为:"JMP 5042"
- 加载过程变得更慢
- 如何在代码中定位所有的地址?如“MOVREG1,42”,其中的42是地址还是数据?
物理地址对应用是可知的,导致:
- 一个应用会因其他应用的加载而受到影响
- 一个应用可通过自身的内存地址,猜测出其他应用的加载位置
是否可以让应用看不见物理地址?(虚拟化)
- 不用关心其他进程,不受其他进程的影响
- 看不见其他进程的信息,更强的隔离能力
"All problems in computer science can be solved by another level of indirection"
--- David Wheeler
- 以虚拟内存抽象为核心的内存管理
- CPU支持虚拟内存功能,新增了虚拟地址空间
- 操作系统配置并使能虚拟内存机制
- 所有软件(包括OS)均使用虚拟地址,无法直接访问物理地址
5.2 虚拟内存
- 虚拟内存抽象下,程序使用虚拟地址访问主存
- 虚拟地址会被硬件"自动地"翻译成物理地址
- 每个应用程序拥有独立的虚拟地址空间
- 应用程序认为自己独占整个内存
- 应用程序不再看到物理地址
- 应用加载时不用再为地址增加一个偏移量
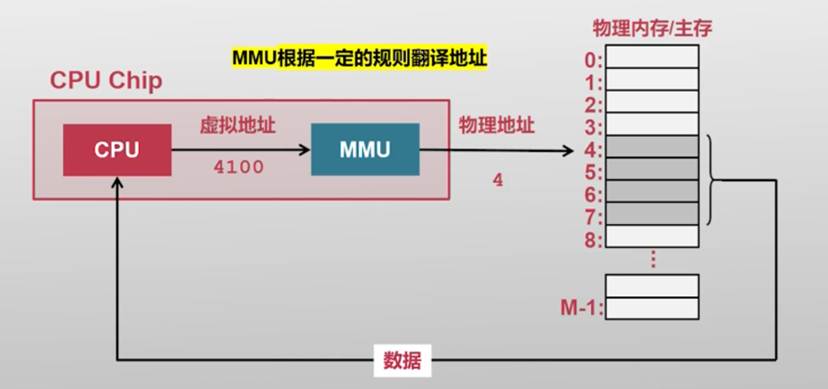
地址翻译过程
1. 分段机制
- 虚拟地址空间分成若干个不同大小的段(如:代码段、数据段)
- 段表存储着分段信息,可供MMU查询
- 虚拟地址分为:段号+段内地址 (偏移)
- 物理内存也是以段为单位进行分配
- 虚拟地址空间中相邻的段,对应的物理内存可以不相邻
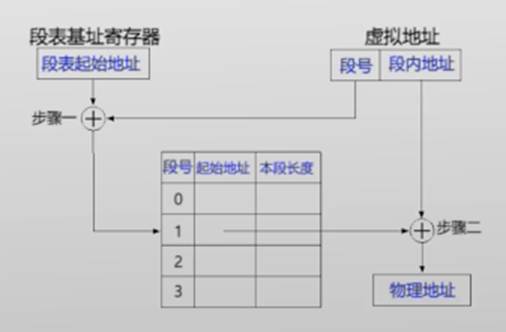
- 存在问题:段与段之间留下碎片空间,降低主存利用率
2. 分页机制
更细粒度的内存管理
- 物理内存也被划分成连续的等长的物理页
- 虚拟页和物理页的页长相等
- 任意虚拟页可以映射到任意物理页
- 有效避免分段机制中常见的外部碎片
- 虚拟地址分为:虚拟页号+页内偏移
- 主流CPU均支持分页机制,可替换分段机制

页表包含多个页表项,存储虚拟页到物理页的映射
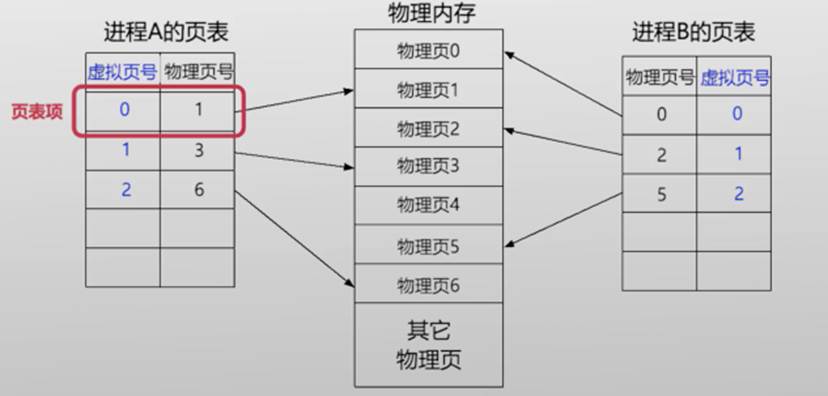
每个进程都有自己独立的页表(需要占用多少空间?)
若使用单级页表结构,一个页表有多大?
- 32位地址空间,页4K,页表项4B,页表大小:2^32/ 4K*4=4MB
- 64位地址空间,页4K,页表项8B,页表大小:2^64/ 4K*8=33,554,432GB
- 使用多级页表减少空间占用
- 若某级页表中的某条目为空,那么对应的下一级页表无需存在
- 实际应用的虚拟地址空间大部分都未被使用,因此无需分配页表
- 减少空间的原因:允许页表中出现“空洞”
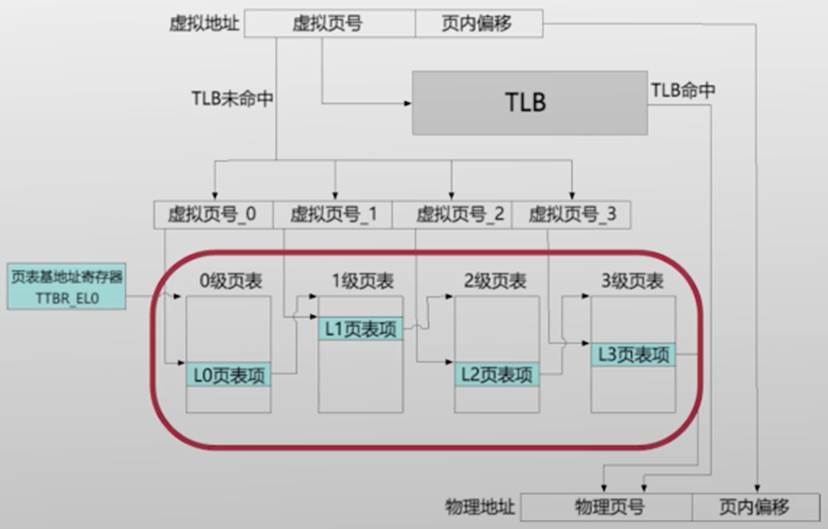
AARCH64的4级页表
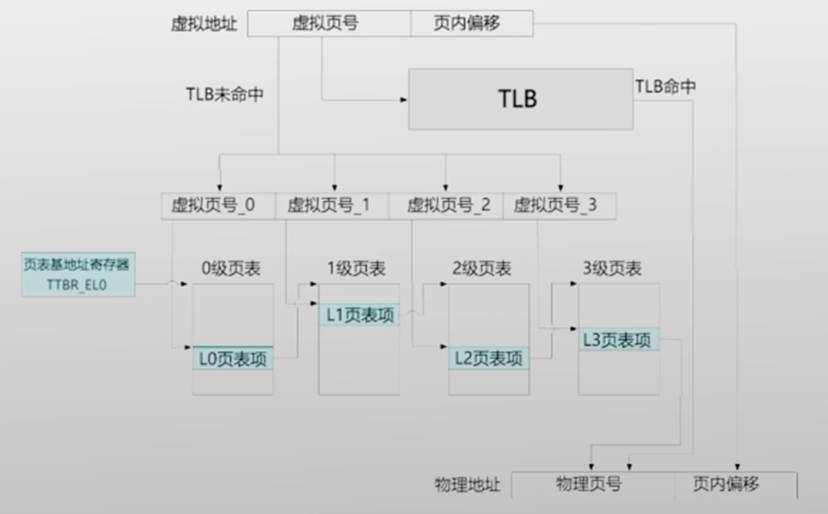
「47:39」0级页表索引|
「38:30」1级页表索引
「29:21」2级页表索引
「20:12」3级页表索引
「63:48」由于只有低于48位地址参与翻译,所以虚拟地址的高16位必须全部是0或者全部是1,也意味着虚拟地址空间大小最大是2^48字节
64位虚拟地址翻译
页表基地址寄存器(Translation Table Base Register)
- AArch64 有两个
- TTBR0_EL1 & TTBR1_EL1
- 根据虚拟地址第63位选择,若为0则选择TTBR_EL0
- 通常 (以Linux为例):应用程序使用TTBR0_EL1,操作系统使用TTBR1_EL1
| 对比x86_64,只有一个CR3寄存器 |
每级页表有若干离散的页表页,每个页表页占用一个物理页
- 第0级(顶层)页表有且仅有一个页表页
- 页表基地址寄存器存储的就是该页的物理地址
- 每个页表页中有512个页表项
每项为8个字节,4096/8,用于存储物理地址和权限
- 多级页表的设计是典型的用时间换空间的设计
- 能够减小页表所占的空间
- 但是增加了访存次数(逐级查询,级数越多越慢)
Tradeoff是计算机中经典而永恒的话题(时间换空间的设计)
- TLB:地址翻译的加速器(避免查询列表地址)
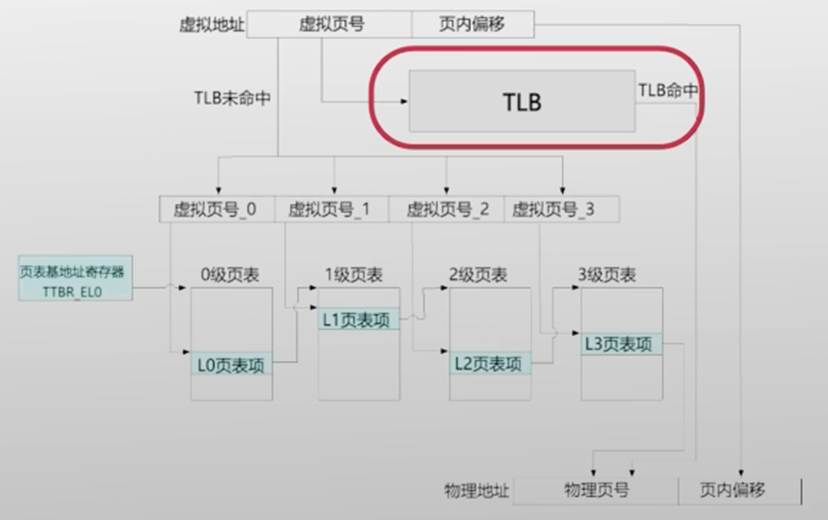
TLB: Translation Lookaside Buffer
- TLB位于CPU内部
- 缓存了虚拟页号到物理页号的映射关系
- 有限数目的TLB缓存项
- 在地址翻译过程中,MMU首先查询TLB
- TLB命中,则不再查询页表(fast path)
- TLB未命中,再查询页表
TLB刷新(TLB Flush)
- TLB使用虚拟地址索引
- 切换页表时需要全部刷新
- AARCH64上内核和应用程序使用不同的页表
- 分别存在TTBR0_EL1和TTBR1_EL1
- 系统调用过程不用切换
- x86_64上只有唯一的基地址寄存器
- 内核映射到应用页表的高地址
- 避免系统调用时TLB刷新的开销
在切换应用程序的过程中,切换页表无可避免
如何尽量避免页表切换,刷新TLB的开销?
- 为不同的页表打上标签
- TLB缓存项都具有页表标签,切换页表不再需要刷新TLB
- x86 64: PCID
- PCID,存储在CR3的低位中
- AARCH64:ASID
- OS为不同进程分配8/16 ASID, 将ASID填写在TTBR0_EL1的高8/16位
- ASID位数由TCR_EL1的第36位(AS位)决定
TLB与多核
- 使用了ASID之后
- 切换页表不再需要刷新TLB
- 修改页表映射后,仍需要刷新TLB
- 在多核场景下
- 需要刷新其它核的TLB吗?
需要!一个程序可能在多个核上运行
- 如何知道需要刷新哪些核?
操作系统知道进程调度信息(操作系统负责应用程序的调度)
- 怎么刷新其它核?
x86_64:发送IPI中断某个核,通知它主动刷新
AARCH64:可在本核上刷新其它核TLB
如何利用虚拟内存抽象实现物理内存的超售(Over-commit)和按需分配
| 情景1:有一位同学的笔记本配了4g的物理内存,他首先打开了应用程序ps用来编辑大量的高清图片,总共需要占用2G的物理内存,然后他又打开了一个游戏,需要占用3G的物理内存,发现打开游戏的过程要比平时慢一些,不过最终还是成功打开了,它很好奇操作系统如何使用虚拟内存抽象,使原本只有4G的内存,能够同时运行两个总共需要5G内存的应用程序 ?为什么游戏打开的速度会变慢呢? |
| 情景2:这个同学编写了一个应用程序,但是它不知道在运行时,实际会使用多少内存,于是在程序中向操作系统预先申请一个足够大的虚拟内存,但实际上其中大部分的虚拟页都不会被用到,那么操作系统应该如何利用虚拟内存抽象,做到根据实际使用情况来分配珍贵的物理内存资源?而不是根据申请的大小来分配物理内存资源呢? |
- 换页的基本思想
- 将物理内存里面存不下的内容放到磁盘上
- 虚拟内存使用不受物理内存大小的限制
- 如何实现?
- 磁盘上划分专门的Swap分区
- 把物理内存页换出到该分区;从该分区换入物理内存页
缺页异常(Page Fault)
- 缺页异常
- CPU控制流传递
- 提前注册缺页异常处理函数
| 找到一个空闲的物理页,将之前写入磁盘上的数据内容重新加载到这块物理页中,并且在列表中填写虚拟地址到这一物理页的映射,这一过程就是“页换入”的过程,之后CPU可以回到发生缺页异常的地方,继续往下执行 |
- x86_64
- 异常号#PF(14),错误地址在CR2
- AARCH64
- 触发(通用的)同步异常(8)
- 根据ESR信息判断是否缺页,错误地址在FAR_EL1
5.3物理内存分配
- 为操作系统提供了易用的物理内存抽象
- 逐字节可寻址的"大数组'
- 屏蔽了硬件细节
- 操作系统的物理内存管理变得简单
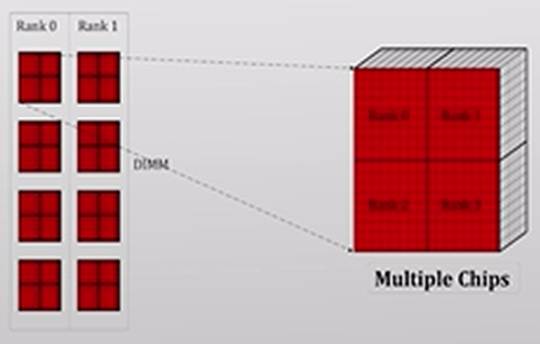
操作系统对物理内存的管理主要在于分配和回收物理内存
- 外部碎片(空闲的但不连续,无法被使用)

- 内部碎片(分配大小大于实际需要)

这两种碎片本质上都是对物理内存的浪费
- 内存资源利用率
- 外部碎片和内部碎片程度有多高
- 分配速度
- 复杂的算法可以更好地解决碎片问题(但是内存分配操作的性能同样重要)
- 分配时间长——>性能差(Tradeoff再一次出现,需要权衡)
物理内存管理之buddy system
- 伙伴系统(外部碎片能避免吗?)
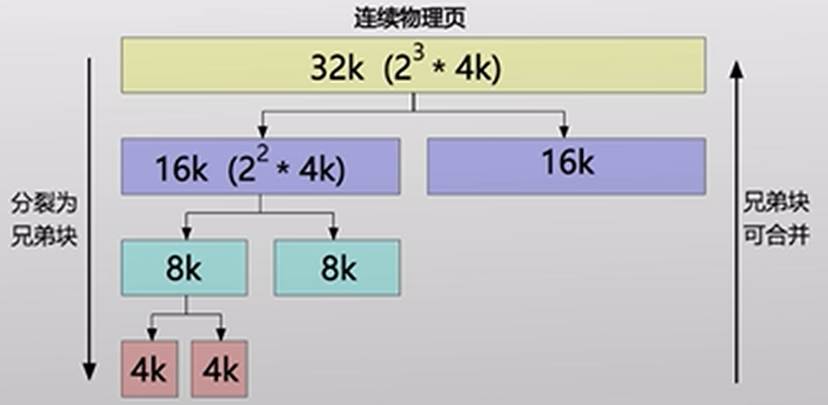
- 分配适合大小的块:什么是“合适”?
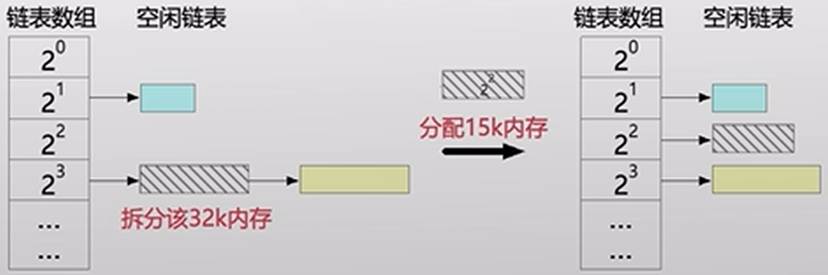
思考:分裂和合并都是级联操作,什么时候会级联?
- 高效地找到伙伴块(互为伙伴块的物理地址仅有一位是不一样的)
- 一个是0,另一个是1,而且块的大小决定是哪一位
- 怎么样来分配内存
- buddy system的问题就在于它只能分配2的N次方的页,当然可以把分配粒度做的非常小,但是分的太小的话,物理内存的管理会非常复杂。所以一般操作系统的的方式就是,会用一个buddy system来管理页。
- 但是页的粒度是4k,而操作系统里面很多数据结构的大小实际上是小于4k的,甚至只有几十个bytes
- 那再怎么来管理这些小的内存分配呢?
- 像linux这样的操作系统,它有一个内存分配器的家族,叫SLAB
SLAB分配器家族
- SLAB分配器
- SLUB分配器
- SLOB分配器
这些分配器都是为了解决,伙伴系统分配分配最小单位是4k,会导致几十个甚至几百个的字节内存碎片的问题
SLAB分配器
- 目标:快速分配小内存对象(预先分配好一系列针对特定大小的内存单元)
- SLAB分配器历史
- 上世纪 90 年代, Jeff Bonwick在Solaris 2.4中首创SLAB
- 07年左右,Christoph Lameter在Linux中提出SLUB
Linux-2.6.23之后成为默认分配器
- 基本思想
- 从伙伴系统获得大块内存
- 进一步细分成固定大小的小块内存进行管理
- 块大小通常是 2^n个字节 (一般来说, 3 ≤ n < 12,2^12正好是4k)
- 可以额外增特殊大小,如:198字节从而减小内部碎片
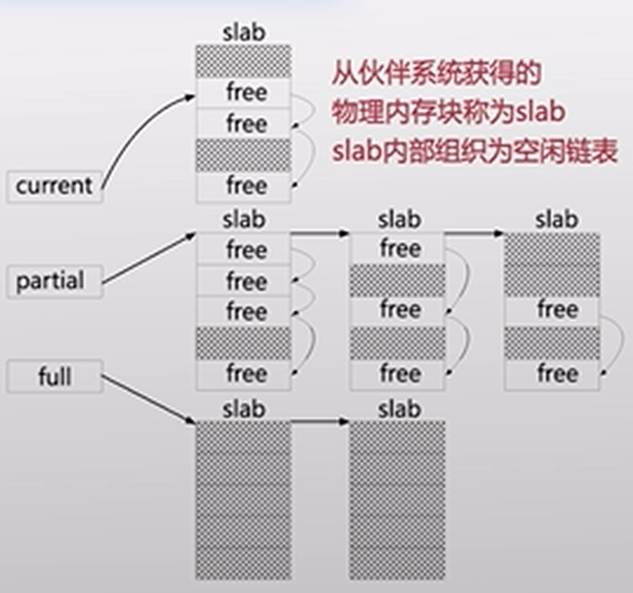
SLUB设计
- 只分配固定大小块
- 对于每个固定块大小,SLUB分配器都会使用独立的内存资源池进行分配
- 采用best fit定位资源池

SLUB数据结构
- 三个指针
- current仅指向一个slab
- partial指向未满slab链表
- full指向全满slab链表
- 分配使用current slab
- 若满发生两个移动
- 释放到对应的slab
- 移动full到partial
- 若partial全free则还给伙伴系统
5.4内存管理功能
- 基本功能
- 节约内存,如:共享库
- 进程通信,传递数据
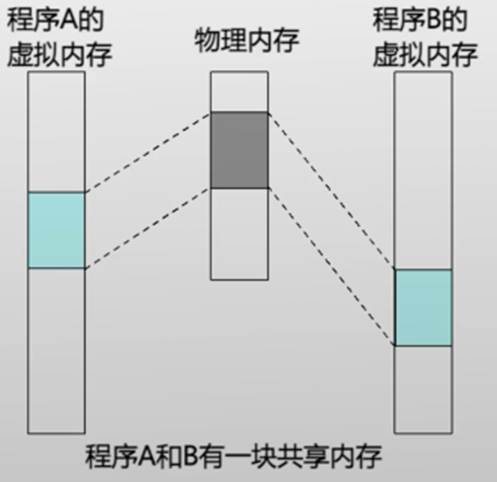
写时拷贝(copy-on-write)
- 实现
- 修改页表项权限
- 在缺页时拷贝、恢复
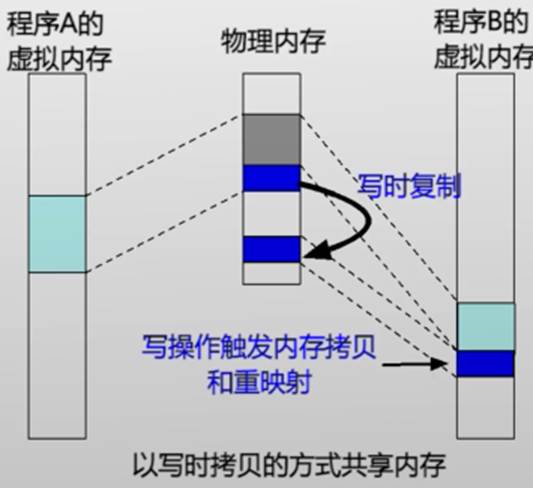
- 典型场景fork
- 节约物理内存
- 性能加速
- Memory deduplication(操作系统发起,对用户态透明)
- 基于写时拷贝机制
- 在内存中扫描发现具有相同内容的物理页面
- 执行去重
- 典型案例:Linux KSM
- Kernel same-page merging
- 基本思想
- 当内存资源不充足的时候,选择将一些“最近不太会使用”内存页进行数据压缩,从而释放出空闲内存。
- Windows 10
- 压缩后数据仍然存放在内存中
- 当访问被压缩的数据时,操作系统将其解压即可
思考:对比交换内存页到磁盘?
- Linux
- zswap,换页过程中磁盘的缓存
- 将准备换出的数据压缩并先写入 zswap区域(内存)
| 好处:减少甚至避免磁盘I/O;增加设备寿命 |
大页:再次回顾4级页表
- 在4级页表中,某些页表项只保留两级或三级页表
- L2页表项的第1位:标识着该页表项中存储的物理地址上(页号)是指向 L3 页表页(该位是 1)还是指向一个 2M 的物理页(该位是 0)
- L1页表项的第1位:类似地,可以指向一个1G的物理页
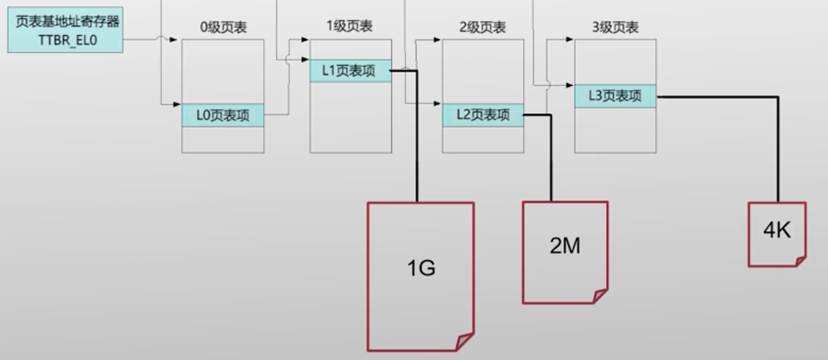
好处:
- 减少TLB缓存项的使用,提高TLB 命中率
- 减少页表的级数,提升遍历页表的效率
- 提供API允许应用程序进行显示的大页分配
- 透明大页(Transparent Huge Pages) 机制(Linux中)
弊端:
- 未使用整个大页而产生大量碎片,造成物理内存资源浪费
- 增加管理内存的复杂度
六
6.1进程、线程调度
线程在切换时发生了什么?操作系统如何决定t1切换到t2?
- 任务(Task):线程、单线程进程
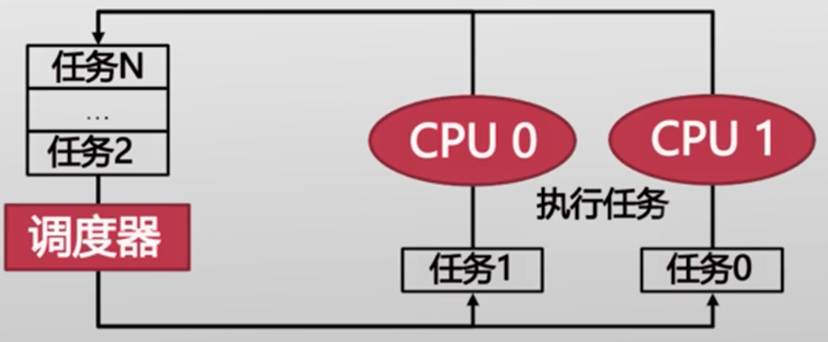
- 任运行队列(Run Queue)——任务1在CPU0,任务0在CPU1,剩下的任务在任运行队列中
- 触发上下文切换:
- 执行时间用尽
- 等待I/O请求
- 睡眠
- 中断
- ……
- 调度决策:
- 下一个执行的任务
- 执行该任务的CPU
- 执行的时长

一些共有的目标:
- 高资源利用率
- 多任务公平性
- 低调度开销
- 降低周转时间:任务第一次进入系统到执行结束的时间(调度什么时候可以执行完)
- 降低响应时间:任务第一次进入系统到第一次给用户输出的时间(可以优化用户体验)
- 实时性:在任务的截止时间内完成任务
- 公平性:每个任务都应该有机会执行,不能饿死
- 开销低:调度器是为了优化系统,而非制造性能BUG
- 可扩展:随着任务数量增加,仍能正常工作
- 缺少信息(没有Oracle)
- 工作场景动态变化
- 调度目标多样性
- 不同的系统可能关注不一样的调度指标
- 调度目标间的权衡
- 调度开销V.S.调度效果
- 优先级V.S.公平(效率优先?公平优先?)
- 能耗 V.S. 性能(性能高VS能耗高,能耗低VS性能低)
需要找到最优的解决方案
6.2 经典调度
“学霸”的烦恼

类比
学霸调度“问题”<——>CPU调度“任务”
当前假设每个问题只提一个问题
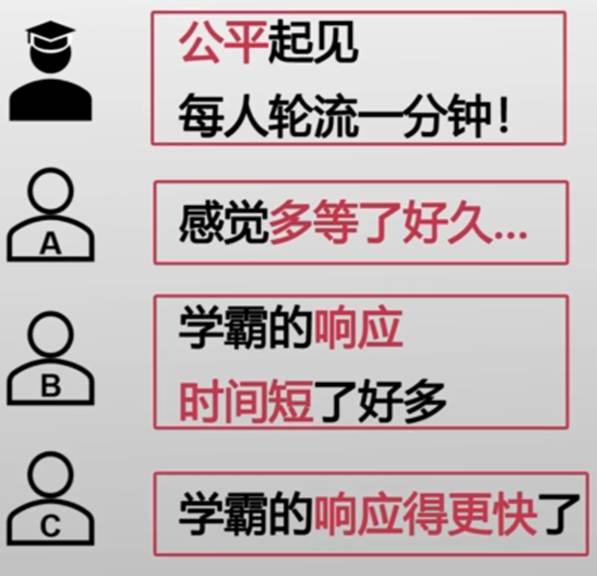
最简单的调度策略——先到先得(First Come First Served)
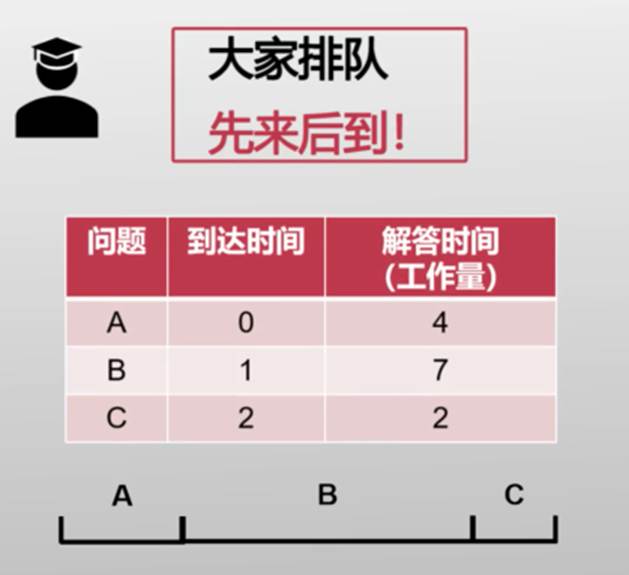
A:得嘞,我第一
B:C,先来后到(B的问题需要7分钟才能解决,C的只用2分钟)
C:学霸的响应得更快了(C解答时间短,但是要等A和B解答完猜到C,等了11分钟 )
- 好处:简单、直观
- 问题:
- 平均响应时间过长
- 对于短任务不友好
由此得到另一个调度策略——短任务优先(Shortest Job First)
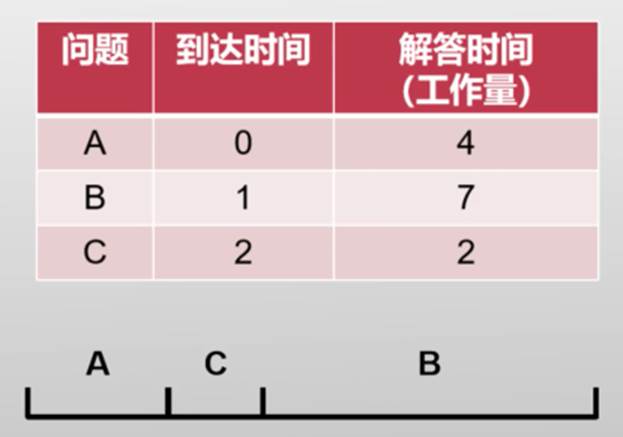
- 与先到先得相比:
- A的周转时间没有变化,B的周转时间增加2分钟,C的周转时间减少7分钟
- 好处:平均周转时间短
- 问题:不公平,任务饿死(只要后面的解答时间小于B的7分钟,B就一直不能够得到解答)
- 平均响应时间过长
抢占式调度(Preemptive Scheduling)
- 每次任务执行
- 一个时间片后会被切换到下一任务
- 而非执行至终止
- 时间片
- 任务被调度一次后,可以执行的时间
通过定时触发的时钟中断实现
时间片轮转(Round Robin)
- 好处:公平;平均响应时间短
- 问题:牺牲周转时间
| 什么情况下RR(时间片轮转)的周转时间问题最为明显? 在任务长度相同的情况下,每个任务都会等很多轮,然后才能结束 |
一直轮流执行这些任务,造成平均周转时间非常的长
时间片长短应该如何确定?
- 过长的时间片会导致什么问题?(时间片过长也会导致平均周转时间被拉长)
- 过短的时间片会导致什么问题?(过短的时间片会导致上下文切换开销过大)
6.3优先级调度
操作系统中的任务是不同的,例如:系统 V.S.用户、前台 V.S.后台……如果不加以区分
系统关键任务无法及时处理,“后台运算"导致"视频播放"卡顿
- 优先级确保:重要的任务被优先调度

多级队列(Multi-level Queue)
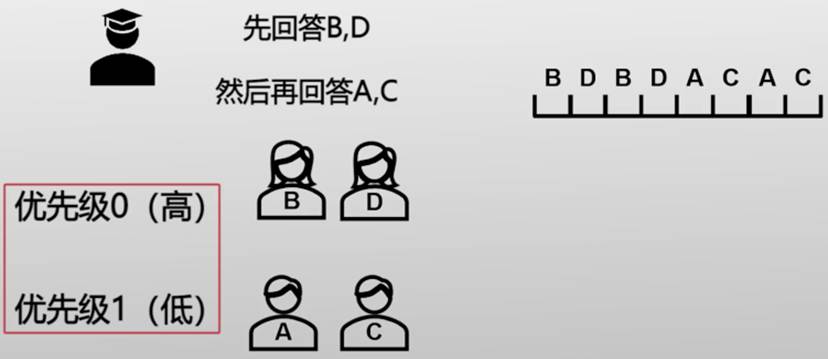
添加条件:阅读银杏书(类似I/O操作)
学霸告诉同学需要看银杏书
- (学霸只有一本银杏书,同一时间只有一个同学能够阅读)
- 阅读完银杏书后同学再和学霸确认知识点
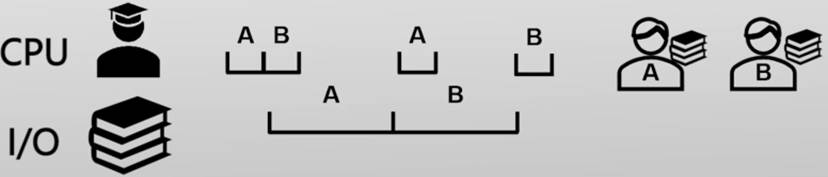
问题1:低资源利用率
女同学的问题由学霸解答,男同学的问题需要阅读银杏书,学霸和银杏书没有同时被利用起来
只有调度到低优先级的问题是才会使用银杏书
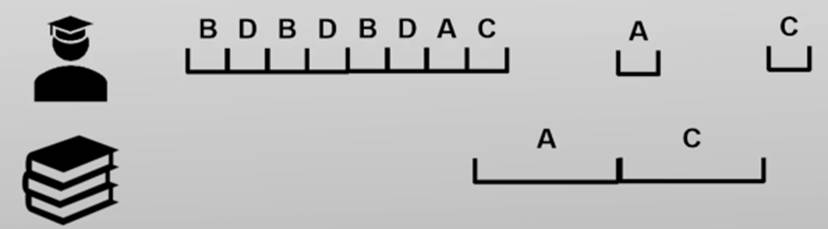
什么样的任务应该有高优先级?(没有固定的答案,应该由实际应用需求来看)
- I/O绑定的任务
- 资源利用率
- 用户设置的重要人物
- 时延要求极高高(必须在短时间内完成)的任务
- 等待时间过长的任务
- 公平性
在时间系统中,多种策略可以同时存在,互相配合
问题2:优先级反转
- 高、低优先级任务都需要独占共享资源
- 通常使用信号量、互斥锁实现独占
- 低优先任务占用资源->高优先级任务被阻塞
6.4公平共享调度
在云平台中,计算资源是有价值的
租户在意自己的CPU时间(资源)
- 两个花销相同租户
- 应均分CPU时间
- 而非被每个的任务数量决定
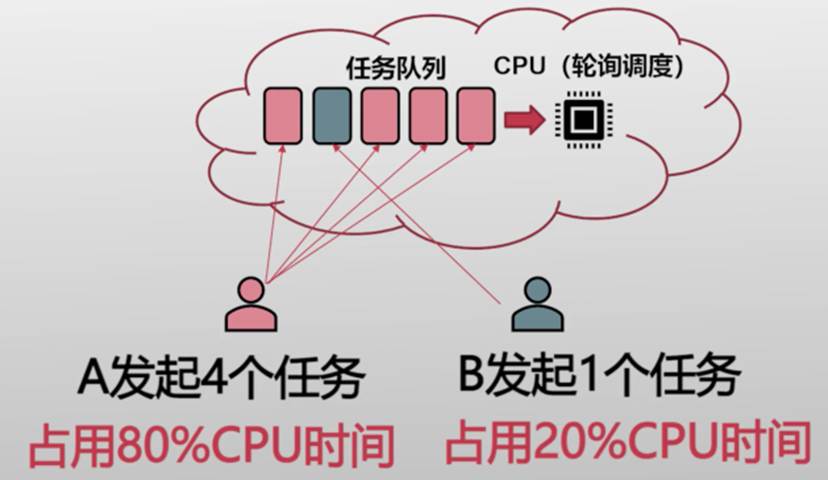
公平共享(Fair Share)
- 每个用户占用的资源是成比例的,而非被其它因素决定
- 每个用户占用的资源是可以被计算的,设定“份额(Share)以确定相对比例
- 例:份额为4的用户使用资源是份额为2用户的2倍
添加条件:一个同学会问多个问题(学霸的例子)
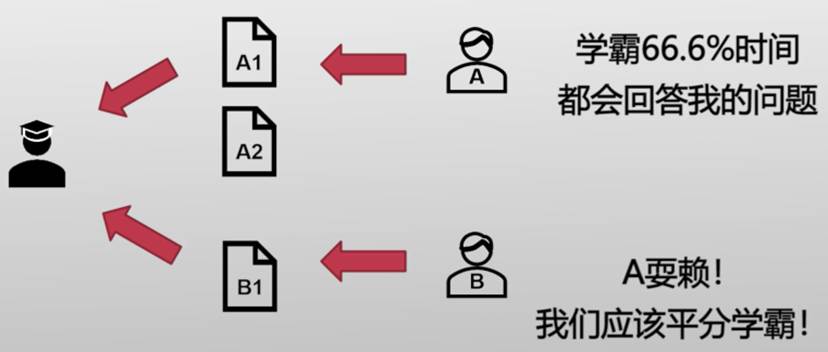
使用"ticket"表示份额
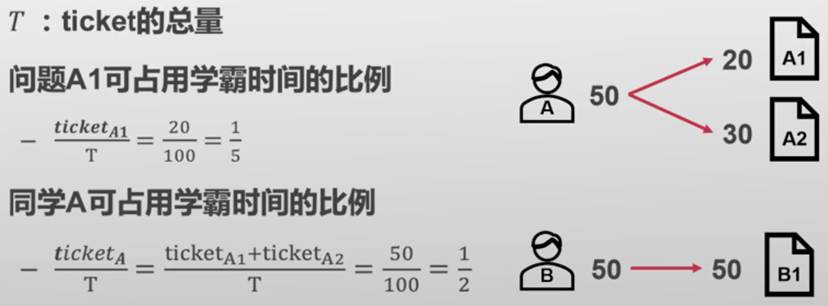
彩票调度(Lottery Scheduling)
每次调度时,生成随机数R ∈ [0,T)(真随机)
| C |
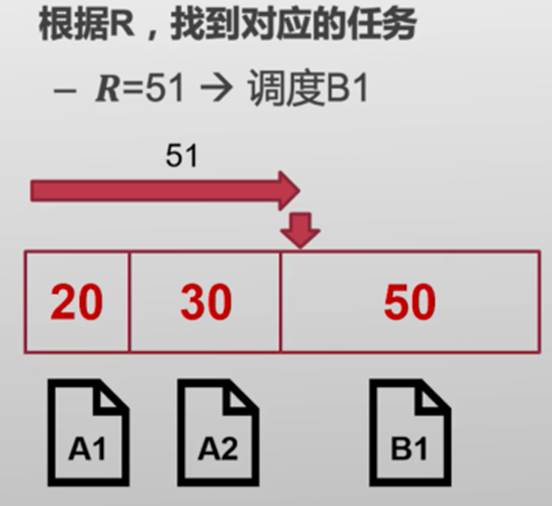
在一定的统计区间内,随机数调到每一个任务区间的期望次数和每个任务拥有的ticket数量是成正比的
- 优先级影响任务对CPU的使用顺序
- 优先级高的任务-定会先执行
- 份额影响任务对CPU的占用比例
- 份额大的任务一般可以使用更多资源
优先级只考虑相对大小;份额还考虑相对比例
两个任务优先级的相对比例没有意义,而份额的相对比例有意义
- 它们的优先级为4和2,第一个任务优先级从4降到3也没有区别,都是第一个任务先执行
- 两个任务的份额分别为4:2,其中一个任务的份额改变了,那么资源的占比也会相应改变
在调度次数较少的情况下,两个份额相同的任务,它们被调度次数之比远不同于1:1
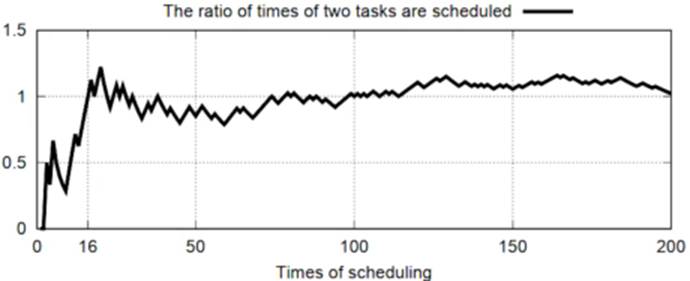
| X轴是调度次数,Y轴是调度次数之比。当调度次数小于16时,调度次数之比与1:1相差很远。显然,如果服务器上跑的任务,执行时间较短,那么任务被调度的次数就比较少。由于彩票调度的不确定性,仍然无法保证调度的公平性 |
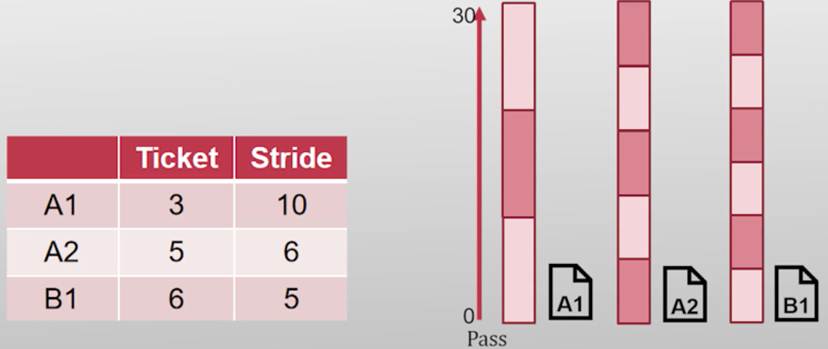
步幅调度(Stride Scheduling)
确定性版本的彩票调度
- 任务被调度次数之比=Ticket之比
- Stride(步幅)
- 任务一次执行增加的虚拟时间
- Pass
- 累计执行的虚拟时间
| C |
| Stride = MaxStride/ticket MaxStride是一个足够大的整数 本例中设为所有tickets的最小公倍数 |
- 经典调度
- 优先级调度
- 公平共享调度
- 缺少动态场景信息
- 调度目标多样性
- 调度目标间的权衡
七
7.1两个隔离的进程之间为什么要交互?
进程
- 独立进程:一个进程就是一个应用
- 不会去影响其他进程的执行也不会被其他进程影响
将邮件功能划分
- 大量重复实现
- 聊天软件和邮件软件都依赖数据库
- 各自实现一份在自己的进程中
- 低效实现
- 聊天软件的数据库实现经过精心的优化
- 邮件软件团队的开发重心在其他组件上
- 借用低效的某数据库开源实现
- 没有信息共享
- 邮件和聊天软件都需要监控系统资源信息
- 没有信息共享:即使邮件软件已经完成了计算,聊天软件也要重新计算一遍
- 协作进程
- 和独立进程相反,可以影响其他进程执行或者被影响
- 好处
- 模块化:数据库单独在一个进程中,可以被复用
- 加速计算:不同进程专注于特定的计算任务,性能更好
- 信息共享:直接共享已经计算好的数据,避免重复计算
7.2共享内存机制
进程间通信(Inter-process Communication, IPC)
两个(或多个)不同的进程,通过内核或其他共享资源进行通信,来传递控制信息或数据
- 交互的双方:发送者/接收者、客户端/服务端、调用者/被调用者
- 通信的内容一般叫做"消息"
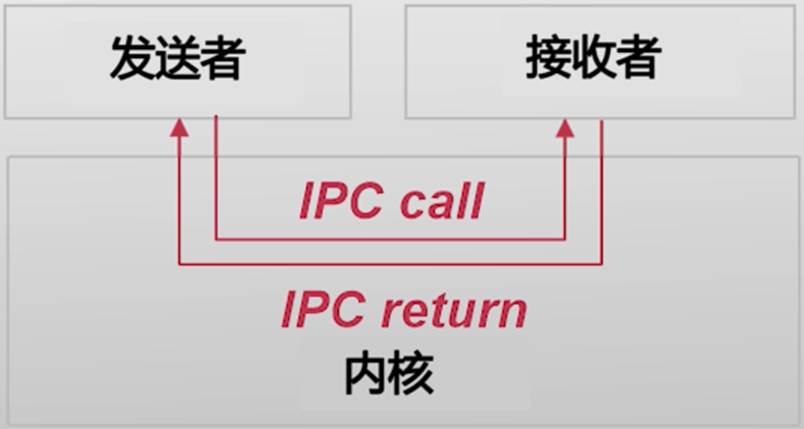
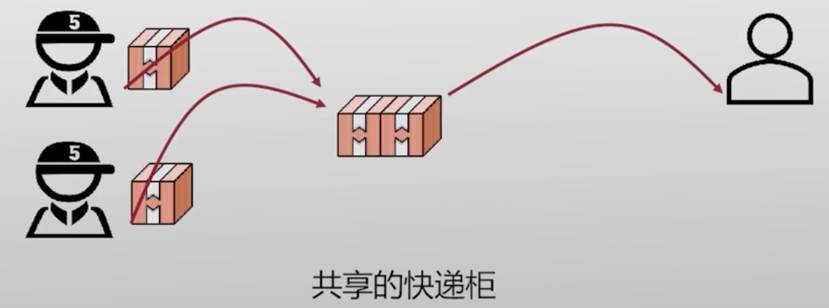
快递员不能送快递到家门口
小明的手机被没收了
快递员和小明怎么联络呢?(通过快递架)
快递员问题——>进程间通信问题
- 系统内核为两个进程映射共同的内存区域
- 快递员和小明的快递桌
- 挑战:做好同步
- 发送者不能覆盖掉未读取的数据(新快递把旧的快递挤下桌)
- 接收者不能读取别的数据(小明拿错了快递)
基础实现:共享区域(快递桌)
| C |
基础实现:发送者(快递员)
| C |
基础实现:接收者(小明)
| C |
- 轮询导致资源浪费
- 小明时不时就得下楼检查一下快递桌子
- 快递员需要等待桌子有空闲空间
- 小明一天大部分时间都花在了上下楼和检查快递上了
- 固定一个检查时间,时延长
- 小明每天晚上检查一下有没有新的快递过来
- 早上到达的快递要晚上才能拿到
7.3消息传递机制
小明终于承诺不打游戏,从而说服了妈妈拿到了手机
消息系统 (手机)
- 通过中间层(如内核)保证通信时延,仍可以利用共享内存传递数据

- 好处:
- 1)低时延 (消息立即转发)
- 2)不浪费计算资源
- 基本操作:
- 发送消息Send(message)
- 接收消息Recv(message)
如果两个进程P和Q希望通过消息传递进行通信,需要:
- 建立一个通信连接
- 通过Send/Recv接口进行消息传递
快递员和小明通过快递网站交换手机号来建立连接
- 手机号唯一地标识了快递员和小明
- Send(P,message): 给P进程发送个消息
- Recv(Q, message): 从Q进程接收一个消息
直接通信下的连接
- 连接的建立是自动的 (通过标识,即手机号)
- 一个连接唯一地对应一对进程
- 一对进程之间也只会存在一个连接
- 连接可以是单向的,但是在大部分情况下是双向的
发送者(快递员)
| C |
| C |
小明的Recv会阻塞,直到快递员的Send发送消息过来
小明沉迷学习经常不接听电话这可怎么办?
- 小快递员执行Send的时候,小明还没有Recv
- 快递员知道小明妈妈经常在家,希望建立一个聊天群,在群里发布快递信息
- 小明不接听时可以拜托妈妈下来拿快递
消息的发送和接收需要经过一个“信箱”
- 聊天群 (所有在群内的人都可以接收消息)
- 每个“信箱”有自己唯一的标识符 (这里的群号)
- 发送者往“信箱”发送消息,接收者从、“信箱”读取消息
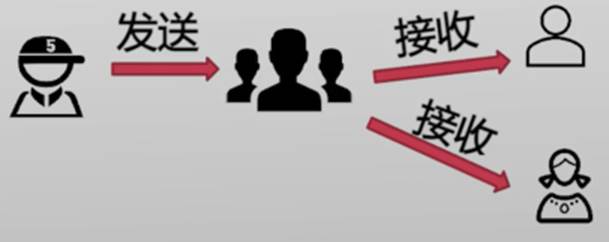
- 间接进程间通信的操作
- 进程间连接的建立发生在共享一个信箱时
- 每对进程可以有多个连接(共享多个信箱)
- 连接同样可以是单向或双向的
创建一个新的信箱——>通过信箱发送和接收消息——>销毁一个信箱
- Send(M,message): 给信箱M发送一个消息
- Recv(M, message): 从信箱M接收一个消息
| C |
接收者(小明):Recv(Mailbox, Msg);
接收者(小明妈妈):Recv(Mailbox, Msg);
快递员有好多苦恼(2)
快递信息发布到群里,经常是小明和妈妈一起下来了。我都被投诉好几次了,这可怎么办好?
怎么解决“信箱”共享带来的多接收者的问题呢?
信箱的共享
- 进程P1、P2和P3共享一个信箱M
- P1负责发送消息,P2、P3负责接收消息
- 当一个消息发出的时候谁会接收到最新的消息呢?
- 可能的解决方案
- 让一个连接(信箱)只能被最多两个进程共享,避免该问题
- 同一时间,只允许最多一个进程在执行接收信息的操作
- 让消息系统任意选择一个接收者 (需要通知发送者谁是最终接收者)
消息的传递可以是阻塞的,也可以是非阻塞的
- 阻塞通常被认为是同步通信
- 阻塞的发送/接收:发送者/接收者一直处于阻塞状态,直到消息发出/到来
- 同步通信通常有着更低时延和易用的编程模型(不会被投诉)
- 非阻塞通常被认为是异步通信
- 发送者/接收者不等待操作结果,直接返回
- 异步通信的带宽一般更高(快递员可以送更多的快递)
为了好评,快递员选择:
- 尽可能等待 (同步的通信)
- 但是一旦超过一个值 (如15分钟),就先带走快递,等下再配送
Send(A, message, Time-out)
- 超过Time-out限定的时间就返回错误信息
- 两个特殊的超时选项:①一直等待(阻塞);②不等待(非阻塞
- 避免由通信造成的拒接服务攻击等
7.4进程间通信的接口
微内核的IPC:进程间通信接口
微内核进程间通信(IPC)
相比宏内核,微内核对性能的要求更高
| 案例:Mach微内核系统IPC Mach是早期的微内核系统 其IPC的设计和抽象在当今的微内核系统中仍被广泛使用 |
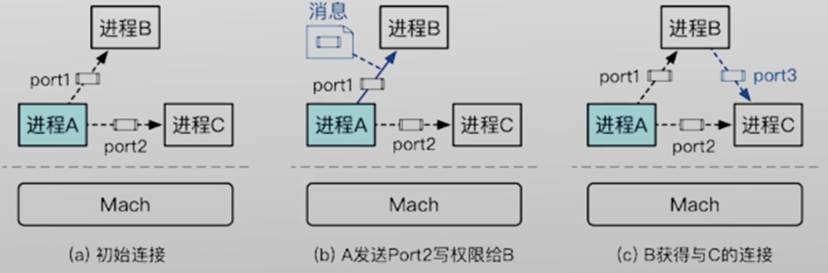
- 端口和消息是MachIPC中的两个基本抽象端口
- 通信的进程之间会有自己的端口
- 端口会连向其他端口
- 进程通过端口与其他进程交换数据
- 进程之间通过端口流通的数据,就是消息
通信的收发角度:发送者端口和接收者端口
- 微内核通过权限系统区分端口的特性
发送者端口访问权限的进程,可以向这个“信箱”中发送信息;而接收者进程(拥有接收者端口)则可以从、“信箱"中读取信息
Mach中一个信箱的发送者端口可以有多个但其接收者端口只能有一个
发送者端口:入队操作
接收者端口:出队操作
发送者(快递员)
| //将一个消息发送到指定的目标端口中(端口在消息头部中指定) msg_send(message, timeout); //在消息头部中指定的端口中接收一个消息内容,或直接监听默认的端口 msg_receive(message, timeout); //发送一个消息,并且等待和接收一个返回消息 msg_rpc(message, rev_size, send_timeout, receive_timeout); |
消息是由头部和数据段来部分组成的
Mach中:定长的头部+变长的数据段
Mach消息的传递端口
| 通过进程间通信来传递端口的思想,在后续大部分的微内核系统中都继承了下来,主要的应用场景——>用来建立通信的连接 |
7.5宏内核的IPC:UNIX管道与消息队列
Unix管道
- 管道是Unix等宏内核系统中非常重要的进程间通信机制
- 管道(Pipe):两个进程间的一根通信通道
- 一端向里投递,另一端接收
- 管道是间接消息传递方式,通过共享一个管道来建立连接
- 管例子:我们常见的命令ls | grep

命令行的shell采用管道技术串联ls和grep这两个应用程序的输入和输出内容
Unix系统,管道的常见的操作和抽象
| C |
Unix管道
管道的特点:
- 单向通信,当缓冲区满时阻塞
- 一个管道有且只能有两个端口:一个负责输入(发送数据),一个负责输出 (接收数据)
- 数据不带类型,即字节流
- 基于Unix的文件描述符使用
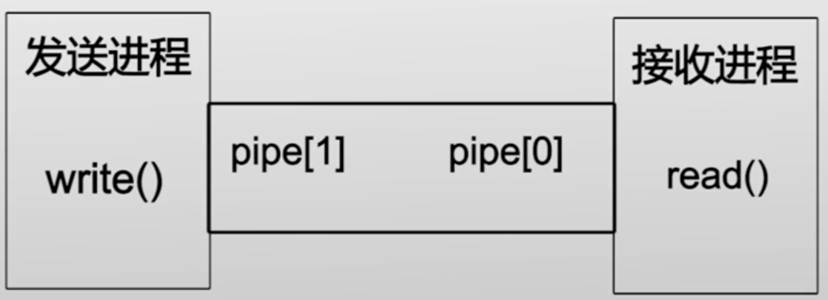
- 优点:设计和实现简单
- 针对简单通信场景十分有效
- 问题:
- 缺少消息的类型,接收者需要对消息内容进行解析
- 缓冲区大小预先分配且固定
- 只能支持单向通信
- 只能支持最多两个进程间通信
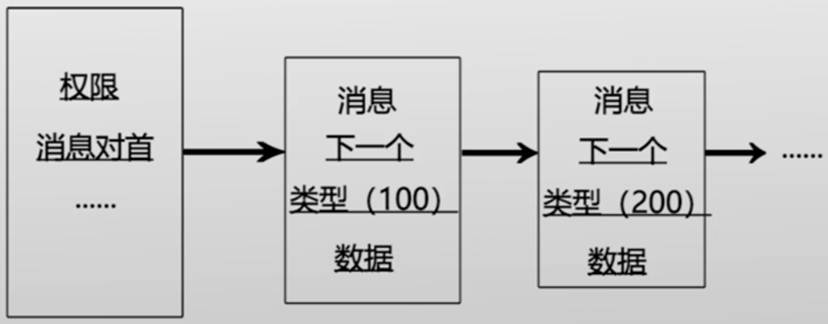
- 消息队列:以链表的方式组织消息
- 任何有权限的进程都可以访问队列,写入或者读取
- 支持异步通信 (非阻塞)
- 消息队列是间接消息传递方式
- 通过共享一个队列来建立连接
| C |
- 消息的格式:类型+数据
- 类型:由一个整型表示,具体的意义由用户决定
- 消息队列的组织
- 基本遵循FIFO(First-In-First-Out)先进先出原则
- 消息队列的写入:增加在队列尾部
- 消息队列的读取:默认从队首获取消息
- 允许按照类型查询:Recv(A,type,message)
- 类型为0时返回第一个消息(FIFO)
- 类型有值时按照类型查询消息,如type为正数,则返回第一个类型为type的消息
消息队列VS.管道
- 缓存区设计:
- 消息队列:链表的组织方式,动态分配资源,可以设置很大的上限
- 管道:固定的缓冲区间,分配过大资源容易造成浪费
- 消息格式:
- 消息队列:带类型的数据
- 管道:数据 (字节流)
- 连接上的通信进程:
- 消息队列:可以有多个发送者和接收者
- 管道:两个端口,最多对应两个进程
- 消息的管理:
- 消息队列:FIFO+基于类型的查询
- 管道:FIFO
共享内存VS.消息传递
- 共享内存可以实现理论上的零内存拷贝的传输
- 将数据从内存上的一块区域拷贝到另一块区域通常通过CPU访存指令来实现
- 操作系统辅助传递的方式通常需要将数据先从发送者用户态内存拷贝到内核内存
L4微内核系统中,就利用了内存重映射的系统技术能够做到一次拷贝完成数据传递第一,操作系统辅助传递的抽象更简单
- 消息传递优势
- 第一,操作系统辅助传递的抽象更简单
- 内核可以保证每一次通信接口的调用都是一个消息被发送或接收(或者出现异常错误),并且能够较好支持变长的消息,而共享内存则需要用户态软件封装来实现这一点
- 第二,操作系统辅助传递的安全性保证通常更强,并且不会破坏发送者和接收者进程的内存隔离性
- 第三,在多方通信时,在多个进程间共享内存区域是复杂且不安全的,而操作系统辅助传递可以避免此问题
八
8.1 OS为什么需要提供同步功能?临界区问题与竞争条件
- 在 2000 年之前,CPU的发展路线主要是提高CPU的运行频率
- 由于能耗等原因,核心频率很难进一步上升,因此如今处理器通过添加核心数来进一步提升处理器性能
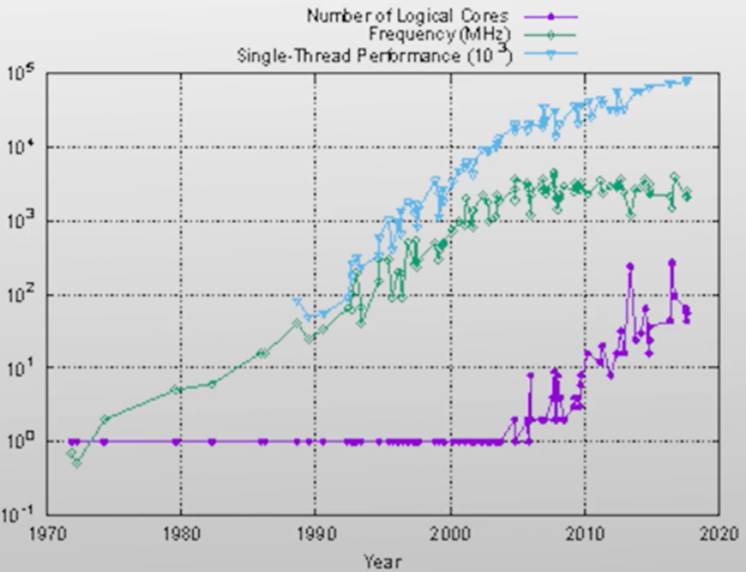
单核性能、单核频率、核心数三项指标随年份变化示意图
- 单核性能提升遇到瓶颈
- 不能通过一味提升频率来获得更好的性能
- 通过增加核心数来提升软件的性能
- 桌面/移动平台均向多核迈进

一核有难,八核围观
假设现在需要建房子:工作量=1000人/年;工头找了10万人,需要多久?
我们如何合理协调不同工人使用有限的资源共同完成一个任务,避免出现争抢甚至全意外? 在操作系统中,存在很多类似的同步问题。操作系统提供了一套易用而且有效的工具来帮助上层应用来解决类似的同步问题——同步原语 |
同步原语(Synchronization Primitives) 是一个平台(如操作系统)提供的用于帮助开发者实现线程之间同步的软件工具
- 既有需要操作系统支持才能实现的同步原语,也有不依赖于操作系统
- 操作系统中有些组件也需要使用合适的同步原语保证在多核下正确性
基础实现:生产者(快递员) 快递满的时候, <快递员等待快递柜有空闲的格子>,一旦有空闲的格子,快递员会快递放入快递柜
| C |
小明等待快递柜中存在货物

小明从快递柜拿快递
- 通过两个计数器来协调:生产者(快递员)与消费者 (小明)
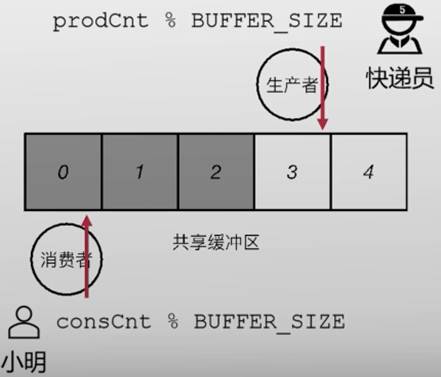
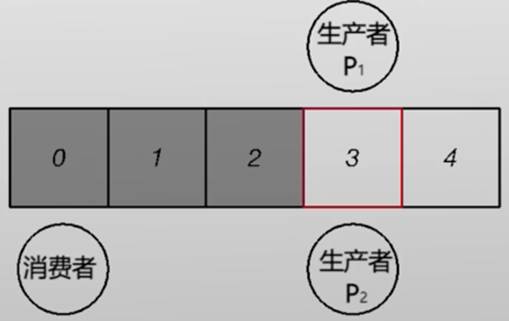
- 假设同一时刻有多个生产者:
| C |
prodCnt = 3
buffer[3] = pkg1;
prodCnt = 3
buffer[3] = pkg1;
prodCnt = 3
buffer[3] = pkg2;
将快递碰到地上
prodCnt = 3
buffer[3] = pkg1;
prodCnt = 4
prodCnt = 3
buffer[3] = pkg2;
将快递碰到地上
竞争条件RaceCondition
如何确保他们不会将新产生的数据放入到同一个缓冲区中,造成数据覆盖?
此时产生了竞争条件(竞争冒险、竞态条件):
- 当多个线程同时对共享的数据进行操作
- 该共享数据最后的结果依赖于这些线程特定的执行顺序
竞争条件 Race Condition
- 先放入快递柜的快递可能会被丢弃
- 而快递员到达的顺序可能不同,最终导致留在快递柜中的快递与他们到达的顺序相关
- 如何确保他们不会将新产生的数据放入到同一个缓冲区中,造成数据覆盖
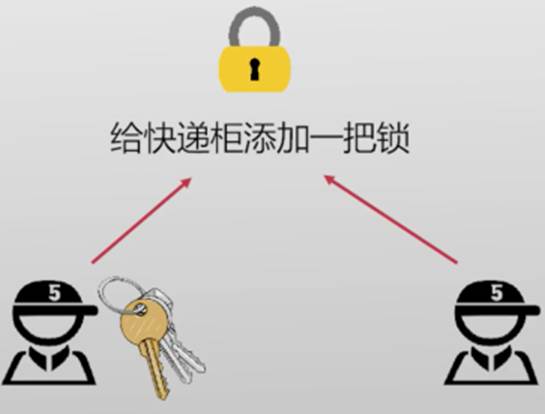

- 互斥访问:在同一时刻,有且仅有一个线程可以进入临界区(一个快递员放快递)
- 有限等待:当一个线程申请进入临界区之后,必须在有限的时间内获得许可进入临界区而不能无限等待(快递员还要送其他)
- 空闲让进当没有线程在临界区中时必须在申请进入临界区的线程中选择一个进入临界区,保证执行临界区的进展(没人放快递时要选一个快递员去放)
程序中什么代码需要放入临界区?
- 需要保证互斥访问的部分:如程序中对共享数据的修改

最终还是导致两个包裹都放到了3号格内
8.2互斥锁:软件实现与硬件实现
软件实现:皮特森算法
flag[2]:用于记录线程0或线程1是否申请进入临界区
turn:用于决定如果两个线程都希望进入临界区时谁能进入临界区


|
虽然皮特森算法能够解决临界区问题,而且后续算法使其能够支持大于两个线程的情况,算法本身比较复杂,有没有更简单的方法?
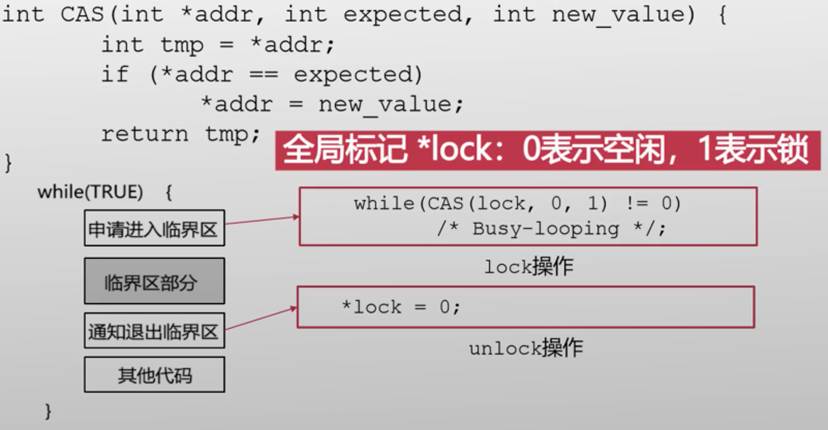
多个核心同时执行CAS
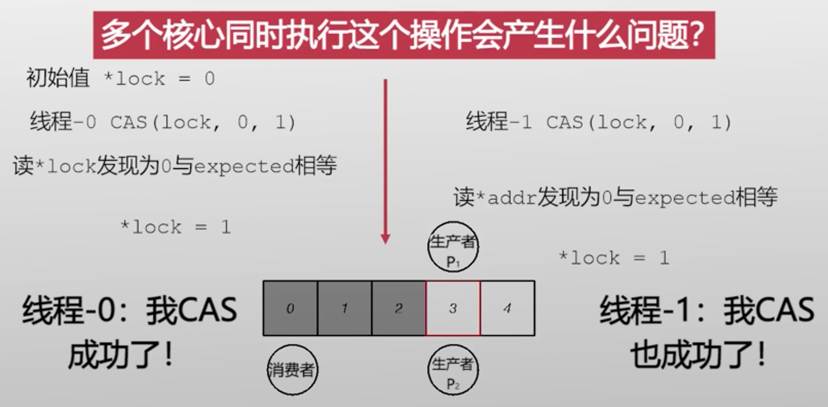
不满足互斥访问
比较并替换操作,并不能保证同时完成,中间有一个时间差,多个线程可能在这个时间差内,改变比较对象的状态,从而导致出现错误
- 原子操作:
- 不可被打断的操作集合
- 如同执行一条指令
- 其他核心不会看到中间状态all-or-nothing
| C |

| C |

自旋锁
- 思考:我们如何保证竞争者的公平性?
- 通过遵循竞争者到达的顺序来传递锁
owner:表示当前在吃的食客 next:表示目前放号的最新值
my_ticket = atmoic_FAA(&next, 1)
while(owner != my_ticket); |


排号锁实现

8.3 条件变量
条件变量:提供睡眠/唤醒机制,避免无意义的等待
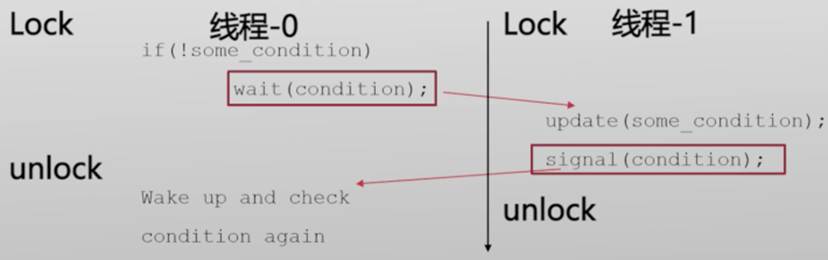

为什么这里要原子的atomic_block_unlock?

条件变量依赖于操作系统提供原子阻塞并放锁或者类似的机制
- 唤醒的接口:void cond signal(struct cond *cond);
- 检查等待队列
- 如果有等待者则移出等待队列并唤醒
| C |
| C |

8.4同步原语带来的问题
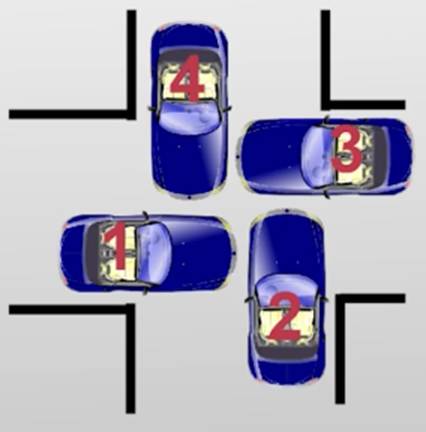
十字路口的“困境”
- 主要原因车之间出现了循环等待
·1号车等待2号车
·2号车等待3号车
·3号车等待4号车
·4号车又等待1号车

如果在T1时刻,线程A已经获取了A锁将要获取B锁,而线程B已经获取了B锁将要获取A锁,那么线程A将无法拿到B锁,同理,线程B也无法拿到A锁,便产生了“死锁”
- 互斥访问
在有互斥访问的前提下,线程才会出现等待,则刚才的例子中的两个线程都可以获取对方的锁并进入临界区执行
- 持有并等待:
线程持有一些资源,并等待一些资源只有在等待的时候持有一部分资源,这样才会产生依赖关系,一个线程等待,不会对任何线程产生任何影响
- 资源非抢占
- 一旦一个资源被持有,除非持有者主动放弃,其他竞争者都得不到这个资源
- 任意一个线程可以抢占其他线程持有的锁,不会造成死锁
- 循环等待
刚才的持有并等待的依赖关系出现了闭环,最终导致整个系统无法进一步运行下去
刚才的十字路口的例子中,车辆0-4之间就出现了循环等待
1. 出问题再处理:死锁的检测与恢复
- 出问题再处理——>检测出到底是否出现了死锁
出现死锁前三个条件都是由于固有性质导致的,而只有最后一个循环等待是在系统运行时会产生的
- 检测死锁——>判断是否出现了循环等待
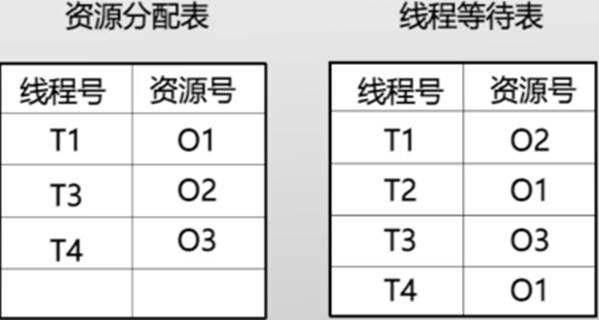
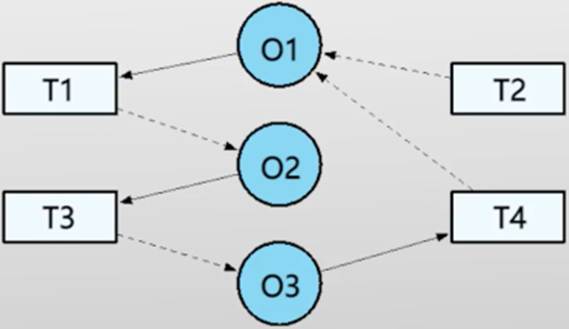
资源分配图(实线表示持有关系,虚线表示等待关系)
打破死锁就是打破循环等待(找到环)
- 直接kill所有循环中的线程
- Kill一个,看有没有环,有的话继续kill
2. 设计时避免:死锁预防
- 避免互斥访问:通过其他手段 (如代理执行)
- 不允许持有并等待:一次性申请所有资源

trylock非阻塞立即返回成功或失败
- 资源允许抢占:需要考虑如何恢复
- 打破循环等待:按照特定顺序获取互斥锁
- 所有互斥锁进行编号
- 所有进程递增获取
任意时刻:获取最大号的互斥锁的进程可以继续执行,然后释放资源
3. 运行时避免死锁:死锁避免
活锁:由于多个线程之间出现了一定的依赖关系导致系统阻塞的问题
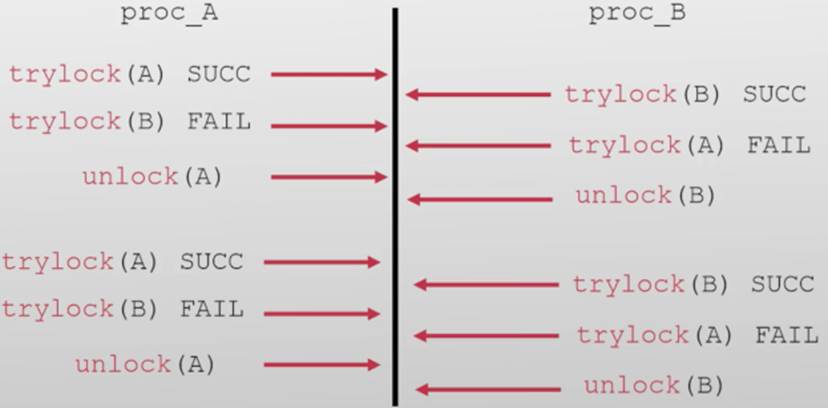
如此往复,线程A与线程B一直重复这个流程,导致相互谦让,谁也无法同时获取锁A与锁B,导致系统无法进展
死锁是无法恢复的,但是活锁可能自己恢复
九
9.1为什么复制1000个小文件比复制1个大文件要慢?
- 文件系统可能是操作系统中和我们关系最密切的一个组件了
- 我们常见的照片、视频、文档等,都是以文件的形式保存在硬盘中
|
文件就是一段“有名字的字符序列”
- 这里的"名字”,可以是一个数字ID,也可以是一个字符串
- 这里的“字符”,就是0和1组成的数据
- 定义中"字符序列"本身被称为"文件数据”
- 定义中"字符序列"的长度、创建时间、拥有者、是只读还是可写等描述文件数据的属性以及支撑文件功能的其他信息,则称为文件元数据
- 文件数据和文件元数据的操作
- 我们可以直接操作的是文件数据
- 而文件元数据则是文件系统替我们操作的
| 比如,在一个文本文件中增加了一个字符时,文件系统会自动将这个文件的大小+1;当我们创建一个新的文件时,文件系统会先帮我们分配一块磁盘空间来保存元数据,并对元数据进行初始化 |
9.2 基于inode的文件系统:如何从文件名找到磁盘块?
磁盘块与磁盘块ID
磁盘的最小读写单位是块(block)
- 每一个块都有一个编号,即块ID
- 对文件系统来说,磁盘就是一个大数组,数组中的每一项就是一个块
- 文件系统若要读取某个块,可向磁盘发送块ID,磁盘会返回这个块的数据;写块的过程也是类似
每个块的大小通常是固定的,为便于理解,后续我们假定块的大小为4KB,每个块ID是64位,即8个字节
可以用磁盘块ID做文件名么?
- 可以!前提是所有文件的大小均不超过4KB
- 可以简单的用块ID来作为文件的名字
- 文件就是一个有名字的字符序列
- 如果文件需要多个磁盘块才能存下
- 那么就需要一个数据结构来记录文件和多个块ID之间的对应关系
- 这个数据结构,就是inode,即index node,其中的index就是块ID
inode-第一版
第一版inode的一些问题
- inode仅仅记录块ID是不够的,因为4KB的粒度太粗,不可能所有文件大小正好都是4KB的整数
- 因此,需要在inode中额外记录下文件的大小,以Byte为单位
- 还有一些其他元数据也都记录在inode中
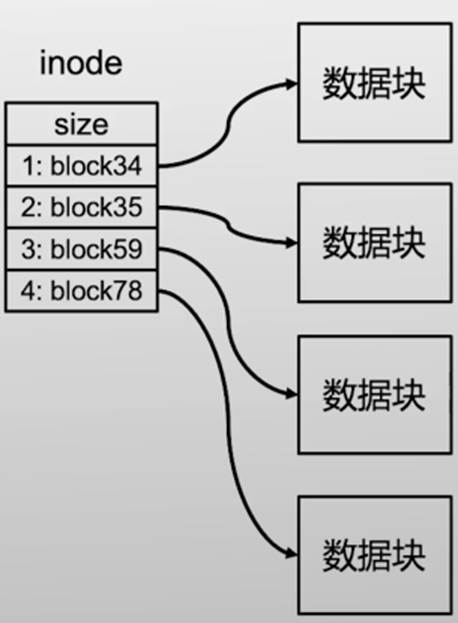
第二版inode的问题:太大啦!
每个inode自己应当占多少磁盘呢?
- 如果inode太小,对应的文件大小也会受限
- 对于一个4GB大小的文件,需要有100万个4KB的磁盘块,这些块ID的大小为8MB(即100万x8字节)
- 为了让文件系统支持最大4GB的单个文件需要为每个inode预留8MB的空间;但磁盘中大部分文件其实远小于4GB,这样就造成了磁盘的浪费
| 我们之前的例子中
|
多层次的inode
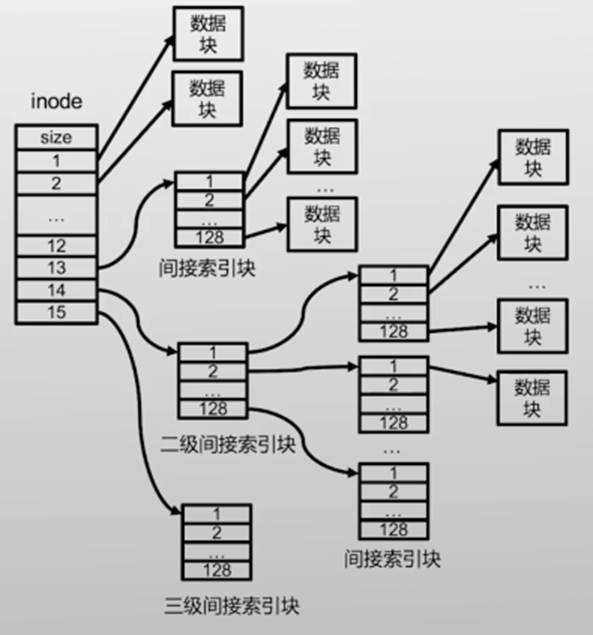
多层次的inode
|
多层结构可以有效减少inode的大小使其与对应的文件数据大小相匹配(和页表结构有点像)
- 文件小,inode也小;
- 文件变大,iinode可以动态增加索引|块
inode在磁盘中的位置
- 所有的inode都放在一起,保存在磁盘中固定的地方,以方便寻找在磁盘的头部有一块区域存放inode表,这个表就是一个大数组,每一项就是一个inode,每个inode的大小都是一样的
- 每个inode就可以用数组的索引来作为名字
- 第一个inode就是inode0,第二个就是inode 1
- 这个索引就是inode号(inode number)
inode的大小与磁盘块大小没有直接关系,通常来说一个磁盘块可以存放多个inode
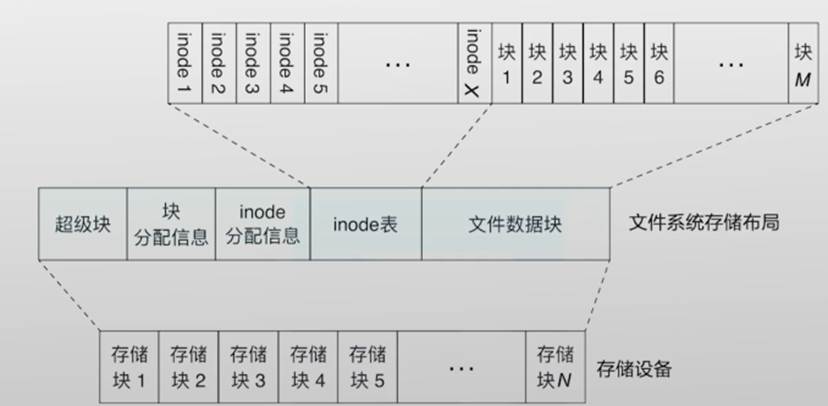
文件系统的存储布局
磁盘格式化的过程其实就是将磁盘划分成不同区域的过程
在格式化后可用磁盘空间会变少一些,原因就在于一部分磁盘区域被inode表等元数据占了,所以留给文件数据的磁盘块就变少了。
inode号就是文件名为什么不好?
一个基础的文件系统已经完备了:
- 我们可以通过inode号来找到对应的文件及其数据块
- 从文件的定义来看,文件已经拥有了一个名字,即inode号
| 然而,用inode号作为文件名并不是一个好主意: 一方面,inode号太难记了! 另一方面,inode号是与文件系统相关的,一个文件从一个磁盘复制到另一个磁盘,inode号就变了,这样也很不方便
|
目录:把字符串映射到inode号
文件名是一个我们可以自由改变的字符串
那么,这个字符串是怎么和文件绑定的呢?——>答案是:通过目录
|
目录需要用一种新的抽象么?不!
- 文件系统巧妙的将目录也作为一种文件保存起来
- 在inode中增加了一个类型字段,,目录文件和普通文件各自具有不同的类型
这是一个非常漂亮的设计!
- 意味着每个目录也对应一个inode号,因此目录的大小也可以扩展
- 意味着目录也可以拥有字符串的名字,这个名字记录在上一级目录中
- 意味着目录具有了层次,可以形成一棵目录树,从而更加方便人们使用
这个目录树的根,就是我们熟悉的根目录“/”
当需要查找“/bin/ls”这个文件时:
- 文件系统首先找到根目录的inode,位置通常在inode表的第一个
- 找到根目录inode中保存的根目录数据的磁盘块ID
- 根据磁盘块ID读取磁盘块,搜索“bin”字符串,并找到后面跟着的inode号
- 根据bin的inode号找到bin的inode
| 重复上面的2-4步,找到字符串"ls"所对应的inode号,最终定位到保存ls文件数据的所有磁盘块 |
9.3 文件系统API:创建与删除、硬链接与软链接
文件系统API
文件系统对应用程序提供了一系列的接口常用的包括
- open()、read()、write()、close()
- creat()、link()、unlink()、symlink()
- sync()、rename()
- mount()、umount()
- 应用程序以系统调用的形式调用这些接口
open():打开一个文件
- 当程序使用openO打开文件成功,会得到一个文件描述符(fd,file descriptor)作为返回值
- 之后的读写操作均需要以此fd作为参数,告知文件系统对哪个文件进行操作
- 文件描述符就是是“打开的文件”的名字
creat()、llink()和unlink()
- 就是在当前目录中新建一个文件
- 具体操作包括分配一个inode,在当前目录中增加一项,记录新的文件名到新分配的inode号的映射
- 和creat()类似,也是在当前目录中增加一项
- 记录新的文件名到一个已分配的inode号的映射
则与link()相反,是在当前目录中删掉某个文件名到inode号的映射
link与硬链接
一个inode是可以对应多个字符串作为文件名的
- 这么设计带来的一个直观的用处,是可以为一个路径很长层次很深的文件建立一个比较简短的“别名”,从而方便使用(别名,又称为“硬链接”)
- 其作用类似于Windows下的快捷方式
- 注意只是作用类似,Windows快捷方式的原理是不同的
- 对文件系统来说,同一个文件的不同文件名的地位都是等价的,没有主次之分
inode的引用计数器
为了记录某个inode有多少个文件名,文件系统为每个inode新增了一项元数据引用计数器
- 当用link0为某个inode新增一个文件名时,引用计数器会+1
当删除某个文件时,更准确的说是删除某个文件名时,文件系统需要判断该文件名所对应的inode的引|用计数器是否为1:
- 若大于1,表示该inode还有别的文件名,则不能把该inode也删掉,而仅仅在目录中删除改该文件名与inode的映射
- 若引l用计数器等于1,表示该文件名已经是对应inode的最后一个文件名了,那么就会把inode也一同删除
用link()创建的硬链接,文件名只能指向同一个文件系统中的inode
- 因为同一个inode号,在不同文件系统中会指向不同的文件
- 如果把一个基于inode文件系统的U盘挂载到了/mnt/usb目录下,U盘中有一个文件foo.txt;然后希望在/home/alice/目录下建立一个硬链接foo.lnk到/mnt/usb/foo.txt,就会失败。
symlink与软链接
软链接可以解决前面提到的问题
软链接(soft link)又称符号链接 (symbolic link)
- 是一种特殊的文件类型(与目录文件、普通文件并列)
- 其本身拥有独立的inode,并不依赖其所指向的目标文件
- 软链接的一个简单实现是将目标文件的路径字符串直接保存在inode中,占据原本用于保存数据块指针的空间
当文件系统打开软链接时,会读取该路径字符串,以此为文件名找到对应的目标文件并打开;若无法找到目标文件,则报错“找不到文件“;若目标文件还是一个软链接,则进一步重复上述的查找过程,直到找到普通文件或次数超过某个上限为止。
软链接与硬链接都可以通过一个新的路径访问已有文件,但两者的原理和行为是不同的
- 软链接可能指向一个不存在的目标文件,硬链接所对应的inode一定存在
- 软链接与目标文件能够属于不同的文件系统,硬链接则必须与目标文件在同一个文件系统中
- 软链接可以指向任意文件,包括目录;硬链接则不能指向目录(两个特殊的目录,“."和“.."除外)
重命名文件(RENAME)的操作其实就是link与unlink两个操作的组合
两个操作的结合
| 例如,mv(/a/old_file,/b/new_file)这个操作,会先尝试用unlink删除b目录下的new_file(若不存在该文件则忽略),然后用link在b目录下创建new_file这个文件名到old_file的inode号的映射,最后用unlink把a目录下的old_file删除 |
9.4 文件系统API:fsync与磁盘缓存
为什么拔U盘之前要安全移除?
例如,当我们把文件从磁盘复制到U盘后,在Windows下需要点击“安全移除设备”才能把U盘拔出;如果在文件复制刚刚结束,没有移除设备而是直接拔U盘的话,会发生什么呢?
页缓存机制:PageCache
页缓存机制通过将数据缓存在内存中来提高对磁盘读操作和写操作的性能
- 对磁盘读操作来说提供缓存功能(即cache) :
- 将最近读过的数据放在内存中,下次若访问同样的数据则可以直接读内存
- 对磁盘写操作来说则提供缓冲功能 (即buffer)
- 磁盘的访问粒度是磁盘块,通常是4KB,而内存访问粒度是cacheline,大约64字节;因此,写磁盘时需要先在内存中准备好4KB的数据,然后一次性写入磁盘。但如果写入磁盘的新数据不到4KB怎么办呢?那就需要先从磁盘读取4KB到Page Cache写入新的数据,然后再把4KB写回磁盘。这个过程被称为read-before-write
- 如果对于一个磁盘块有多次写操作,则可以通过页缓存将其合并成一次磁盘写操作,从而进一步提升了性能
fsync与文件系统缓存
- 引入页缓存及之后,在内存中的数据与在磁盘中的数据往往是不同步的在内存中的数据会更新一些。因此,在数据还未完全写入到磁盘的情况下,如果发生断电,则所有内存中新的数据都会丢失;同样,在我们前面的例子中,突然拔出U盘,同样会导致还没来得及写入U盘的数据丢失。
- fsync()的引l入就是为了解决这个问题。当应用程序调用fsyncO后,操作系统会将所有在PageCache中的数据写入磁盘,并等待写入操作结束才返回;因此应用程序在fsyncO返回后就能够确认之前通过write0写入磁盘的数据已经“落盘”了,即使发生了断电,数据也已经完整地保存在磁盘上了。
write与fsync的解耦
为什么不把write()实现成当数据全部都写回磁盘后再返回呢?
- 应用程序就不用再担心数据的同步问题了;
- 我们看到文件复制到U盘结束,也不用再点击“安全删除设备”就可以拔出了
其实这就意味着每次在write()之后都运行fsync()
- 这样虽然能保证每次往磁盘写数据都能落盘但性能也会变得非常差
- 而通过将write()与fsync()分开,则可以让应用程序在性能和数据持久性之间做出选择
fsync与fdatasync
为了向应用程序提供更好的灵活性,POSIX还提供了
fdatasync(系统调用,其与fsync的区别在于:
- fdatasync仅仅将缓存中的文件数据写入磁盘
- fsync则会将文件和inode的数据-同写入磁盘
- Linux还有一个专门的命令sync,用来触发全系统的fsync()
如何不使用PageCache?
有些应用,如数据库,希望自己来管理文件系统的缓存,从而可以利用应用的语义来进一步提高缓存利用的效率
- 例如,数据库通常会有自己的日志文件,这些文件对持久性的要求与其他文件不同,需要单独对待
- 此时,让数据库来管理其日志文件的缓存,会比让操作系统管理更合适
操作系统提供了Direct I/O机制,允许应用程序在打开文件的时候不使用Page Cache
9.5 文件系统API:mount、unmount
一台主机上同时安装了多块硬盘,每块硬盘都可以安装不同的文件系统
- 为硬盘安装文件系统的过程,通常叫做放“格式化”
一块硬盘也可以安装多个文件系统
- 文件系统的最小单位是分区区(Partition),即如果要在一块硬盘上同时安装两个不同的文件系统,那么可以将该硬盘分为两个分区,为每个分区单独做格式化
- 每个分区可以有自己超级块、元数据块和数据块,彼此互相隔离
如果有多个文件系统,根目录该如何确定呢?
- 对UNIX操作系统来说,根目录只能有一个;但对每个文件系统来说,都有各自的根目录;我们需要有一种方法告诉操作系统,哪个文件系统的根目录才是系统的根目
- 在Linux中,通常,我们会在系统启动的时候通过传参的方式来指定一个文件系统作为“根文件系”(即rootfs),从而确定唯一的根目录
其他文件系统则需要挂载到这个根文件系统的某一个目录下
例如
- U盘挂载到根文件系统的"/mnt/usb/"目录下,那么U盘上的文件"/test/a.txt",现在就可以通过 "/mnt/usb/test/a.txt访问
- 此时根文件系统“/mnt/usb/"目录下如果有其他文件,那么在挂载U盘后,这些文件是不能被访问的,因为“"/mnt/usb/"现在已经是U盘了
- 当通过umount命令取消挂载后,"/mnt/usb/"中原有的文件才能被访问
挂载一个文件系统到根文件系统的某个一目录时:发生了目录项的改变
例子
- 进行mount操作后"/mnt/"目录中保存的勺“usb”目录项所对应的inode,不再是硬盘上的一个文件,而是修改为U盘的根目录
- 当系统打开“/mnt/usb/test/a.txt"的过程中,会在打开"usb”这个目录项时切换到U盘文件系统的根目录,再进行接下来的操作
- 需要注意的是,修改后的勺“usb”目录项仅仅保存在内存而不是硬盘中,所以重启后需要重新执行挂载U盘
chroot与改变根目录
Chroot系统调改变当前进程的根目录
- 对文件路径的解析都会以此新的根目录作为开始
Chroo非常适合用来做沙盒隔离
- 通过设置某个进程的根目录,可以将这个进程对文件系统的操作限制在这个目录中,而无法访问这个目录之外的其他文件
9.6 为什么有很多不同的文件系统?
- 用一个专门的分区来放Windows自己的文件
- 每个分区都可以有一个字母编号,系统分区的编号就是C,因为A和B两个编号已经被软驱占用了,而软驱由于速度太慢,已经被淘汰不用了。(C盘的完整的名称应该是“编号为C的一个磁盘分区”)
C盘与D盘是哪个根文件系统呢?
- Windows允许多个根目录,每个分区有自己的根目录,不需要全局根目录;相应的路径也要以盘符为根,如:C:\WINDOWS\SYSTEM\
- 启动时,系统仍然需要一个启动文件系统,一般就是C盘下的文件系统了
那为什么要把硬盘划分成C盘和D盘呢?C盘没空间了也没法用D盘的空间,很麻烦
- 划分的目的主要是为了给C盘预留足够多的空间,保证系统不受其他应用的干扰
- 如果不分区的话,一旦下载很多数据把整个硬盘都用完了,可能导致操作系统都无法正常运行
- 一旦分区,把下载之类的任务都放在非系统盘(比如D盘),那么当D盘空间用完后也不会影响到C盘
如果现在有两个分区,现在调整一下分区,让一个分区缘一部分给另一个分区,该怎么做呢?
下载一个分区调整工具
如果要把D盘的空间给C盘,需要有以下步骤:
- 先从D盘划一部分出来给C盘
- 从D盘再划一部分出来,作为拆迁安置
- 在D盘新的头部位置放置新的元数据
- 把侵占的数据搬家,为元数据腾出空间
- 更新元数据,使其与新的分区大小相匹配
关键:元数据的调整
- 当文件操作到一半时发生断电,元数据一半是新的一半是旧的,导致不一致,怎么办?
- 在新的存储介质上,比如SSD和非易失性内存,现有的文件系统该如何改进以更好的适应?
- 对于新的应用场景,比如大规模分布式系统,文件系统的结构该如何调整?
这些不同的场景,不同的硬件对文件系统提出了新的要求,文件系统也在不断地演变
十
10.1 设备概述与设备抽象
操作系统的主要任务是对下管理硬件,对上提供服务。其中对下管理硬件,除了管理CPU和内存外,计算机系统还存在大量的设备
- 听筒、麦克风、摄像头、闪光灯:语音/视频通话 、拍照
- 触摸屏:人机交互
- Wifi:无线上网
- 导航定位:北斗卫星导航、全球卫星定位(GPS)
- 陀螺仪、重力感应器、加速传感器:计步、游戏操纵
- 触控按钮:生物识别指纹解锁
- 根据不同需求和场景,人们发明了大量设备
- 通信、存储、智能计算、安全协处理器等
- 每种设备有自己的协议、规范
- 如何标准化设备接口?
操作系统的担当:把复杂留给自己,把简单留给应用
因此,会通过抽象的方式,尽可能屏蔽底层设备的异构性,从而让应用程序更容易使用设备提供的功能,为应用开发提供便利
从设备的用途,总结设备的规律,通过这些规律去发现操作系统设计设备抽象的原理
例子:GPIO LED
- 有专门的 INPUT/OUTPUT 管脚
- 通过管脚进行控制
- 每个01组合只显示一种状态

例子:PS/2键盘控制器
- 电信号→数字信号→信息编码(Scan Code)
- 每次只能键入一个字符

例子:UART(串口)
- 通用异步收发传输器(Universal Asynchronous Receiver/Transmitter)
- 半双工
- 每次只能传输一个字符
- 串口是一种很基础的通信方式,现在嵌入式板子的开发调试还需依赖于它

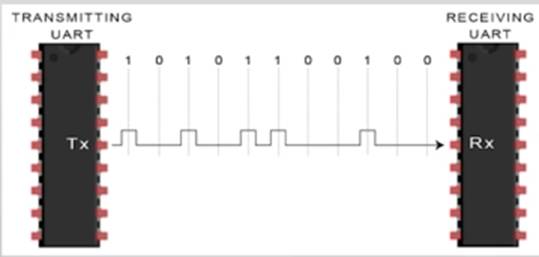
这些设备共同特点:只能表示一种状态或只能传输一个字符
例子:Flash闪存
- 按照页/块的粒度进行读写/擦除
- 支持页/块随机访问
- 通常是以块的粒度进行读写(常见大小是4KB)
- 4KB(读写的粒度是4KB,如果只是写入一个字符,也要先把4KB的块读出来)

固态硬盘SSD、相机SD卡也有以上的特点
例子:Ethernet网卡
- 按每次传输一块数据(以太网帧),传输大小由以太网的协议决定
- WiFi、蓝牙与此类似(同样能实现网络传输,不过彼此的协议与控制方式均不相同)

复用"文件”抽象
设备抽象的作用
- 操作系统将设备细节和协议封装在接口的内部
如下示例代码可以运行在不同设备上
- 为应用程序提供的相同的抽象接口(文件接口)
| C |
| 对于应用程序而言,这些设备都是为了实现数据发送和接收,操作系统通过抽象把设备的细节和协议的区别都隐藏起来,使应用程序通过一套接口实现数据的接发 |
以Linux为代表的操作系统,借鉴了UNIX的设计哲学——“一切都是文件”
将设备抽象成文件,对于应用程序而言,操作设备和操作文件可以使用同一套接口,包括
open/close(实现打开和关闭)、read/write(实现数据的读写)
Linux常见设备分类
- 字符设备
例子:
- 键盘、鼠标、串口、LED等
访问模式:
- 顺序访问,以字节为粒度进行读写
- 调用驱动程序和设备直接交互
通常使用文件抽象:
- open(), read(), write(), close()
- 块设备
例子:
- 磁盘、U盘、闪存等(以存储设备为主)
访问模式:
- 随机访问,以块粒度进行读写
- 在系统层增加一层缓存,避免和慢设备频繁交互
通常使用文件抽象:
- 内存映射文件(Memory-Mapped File):直接访问数据(无需显示系统调用接口,减少用户态与内核态模式切换的开销)
- 同样可以使用文件抽象,但内存抽象更受欢迎(灵活性更好)
- 网络设备
例子:
- 以太网、WiFi、蓝牙等(以通信设备为主,有自己的格式化报文,如:以太网帧)
访问模式:
- 面向格式化报文的收发
- 在驱动层以上维护多种协议,支持不同策略
通常使用文件抽象:
- socket(), send(), recv(), read(), write(), close(), etc
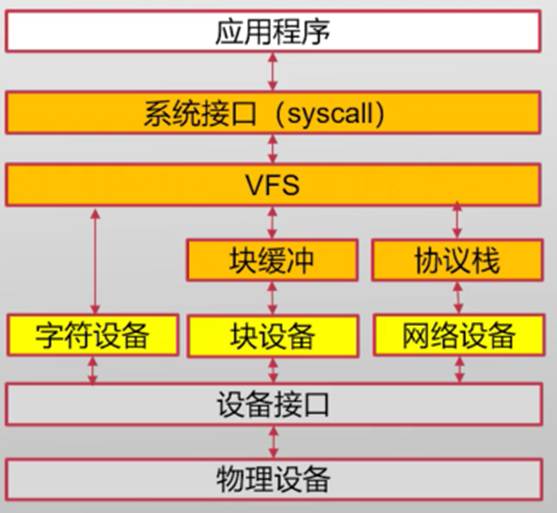
这些设备抽像,在Linux中都是以文件接口的形式向用户提供服务
Linux设备抽像
- 对设备进行分类
- 字符设备(char):LED、键盘、串口
- 块设备(block):闪存
- 网络设备(network):Ethernet网卡
- 对设备进行管理
- 字符抽象:文件系统(read/write)
- 块抽象:文件系统充(read/write),mmap
- 网络抽象:socket,文件系统兼容(用read/write读写socket)
| 假设有一个word的文档需要打印,但笔记本并没有直接连接打印设备,
这个过程操作了三种不同类型的设备,但只需调用open、read、write、close这一套接口,对于应用来说是不是很简单呢? |
10.2 操作系统与设备的交互
10.3 _Linux中断处理:两个阶段
- 关闭中断
操作系统就是一行行指令顺序执行,和普通应用程序一样;一旦打开中断,操作系统的执行流会被打断,去处理中断,然后再恢复原来的执行过程
如果有多个设备同时产生了中断,同时发给了CPU,操作系统如何响应?
- 中断优先级
操作系统会区分来自不同设备的中断优先级,优先处理高优先级的中断。如果在处理低优先级中断的时候,来了高优先级中断,那么操作系统会暂停当前中断处理,先去处理高优先级的中断,处理完后再回到被中断的低优先级中断处理函数继续执行。(这个过程被称为“中断嵌套”)
由于发生中断时,高优先级的中断会导致低优先级的中断得不到响应,导致低优先级中断响应速度变慢,该如何解决这样的问题?
将中断的过程分为两个阶段:确认阶段和处理阶段
Linux中
最小化公共例程:
因为中断被屏蔽,所以不要做太多事情(时间、空间)将中断请求放入队列(或设置flag),将中断延迟处理 (和正常的硬件中断响应一样,唯一不同的是该响应并没有真正处理完中断请求,而是提前告知中断处理器中断已经响应完成,中断请求的真正处理被推迟到下半部来执行) |
提供可以推迟完成任务的机制
这些下半部机制都可以被中断 |
软中断(Softirqs)
在编译内核时静态确定好:
| Priority Type 0 High-priority tasklets 1 Timerin terrupts 2 Network transmission 3 Network reception 4 Block devices 5 Tasklets |
| 内核在几个关键的运行节点会检查是否有挂载的softirqs,如果有则执行对应的下半部进行处理,然而softirqs的处理函数不能执行sleep函数,这是因为softirqs没有对应的线程,上下文无法参与调度,因此,如果在处理逻辑中存在可能会阻塞的操作,比如:操作磁盘等 |
工作队列(Work Queue)
工作队列使用内核线程上下文
工作方式:
- 操作系统在内核空间创建FIFO队列
- 硬中断负责enqueue(fn, args),workqueue,内核线程负责dequeue并执行fn(args)
将下半部的执行交割内核线程,也就是tasklets来完成,由于内核线程具有自己的上下文可以参与调度,所以执行过程中可以调用sleep,从而避免系统上的用户任务被饿死,是一种非常灵活的方式
10.4 设备驱动
设备的种类有很多,每一种设备都有自己的操作方式,那么一个操作系统怎么才能控制这么多不同类型的设备呢?
答案是:驱动程序
设备的代码——驱动
- 使操作系统和设备间能相互通信的特殊程序
例子:操作系统CPU的“驱动”
- 硬盘的驱动程序一方面负责通过操作硬盘的寄存器进行读写,另一方面对上提供磁盘读写的接口,封装掉具体操作的细节,
驱动程序可以由设备厂商提供,这样就能与操作系统的其他部分解耦开,一个成熟的操作系统,会开发一套驱动模型,方便不同设备驱动开发和移植,比如:MMIO管理、DMA管理、中断管理
驱动程序利用这些模块提供的函数开发,可以大大的简化工作量
- 操作系统还要向上为用户态的应用提供一套相对统一的接口,允许应用程序直接借助驱动和设备进行交互。
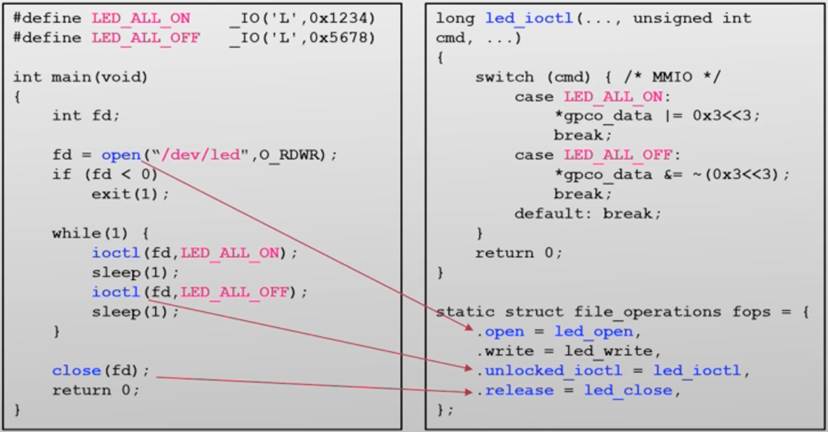
- 在Linux中,所有的设备统一抽象为文件,应用程序可通过open、read、write、close等接口来操作设备。文件系统的接口是有限的对于一些设备特殊的操作,比如设置黑白打印或彩色打印,该调用什么接口呢?
如果为每个这种特殊操作都引入一个新的接口,就会导致接口数量爆炸,为此Linux采用的一种方法是——引入一个ioctl的通用接口,以参数的形式传递不同的操作命令,允许驱动自定义命令,从而在支持特殊操作的同时,避免了接口数量的爆炸
- 既然操作系统内核可以通过MMIO的方式来操作设备,那么是否可以通过MMIO将设备寄存器映射到用户态的虚拟地址空间,这样用户态的应用程序不就能绕过内核而直接操作设备了么?
- 可以通过这种方式在用户态直接操作硬件设备。然而,如果有一个应用程序通过这种方式操作设备,也就意味着这个应用“独占”了这个设备,无论是操作系统内核,还是其他应用,都不能再通过同样的方式去操作设备,否则就可能导致冲突。
- 宏内核
- 驱动在内核态
- 优势:性能更好
- 劣势:容错性差
- 微内核
- 驱动在用户态(独占设备管理的应用)
- 优势:可靠性好(如果驱动程序存在bug而发生错误或者崩溃,其影响会限制在用户态应用中,而不会扩散到微内核;非常方便安装新的驱动,就像安装应用程序一样简单)
- 劣势:性能开销(IPC)(调用驱动由原来的函数调用变成了进程见通信)
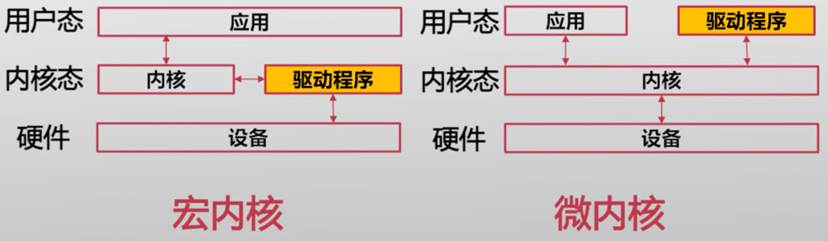
| 对于Linux来说,驱动程序是最容易出现bug的地方,是因为设备的类型众多,驱动程序的代码也非常庞大,这固然为Linux提供兼容性的优势,也导致出问题的概率上升,不同于由社区专门的维护人员管理的通用代码,如:内存管理、CPU调度这样的模块,设备厂商代码由设备厂商维护,因为只有他们对设备的协议最熟悉、最有能力也最有动力来提供驱动的实现,因此驱动代码的质量往往参差不齐,成为内核崩溃或被攻击的一个重要原因,为了减轻驱动故障带来的影响,像Linux这样的宏内核也已经开始支持用户态的驱动了,可以看到微内核和宏内核的技术正在融合 |
10.5 设备的识别:设备树与ACPI
计算机设备的类型有很多,操作系统预装的驱动程序也有很多,操作系统是如何识别各种不同的设备,并选择正确的驱动程序的呢?
在操作系统启动之前,由负责启动内核的bootloader,扫描安装了哪些设备,比如无线网卡、显示屏等,生成一个列表后传给操作系统
Device Tree
- 描述硬件设备的专用数据结构
硬件信息可通过 Device Tree Source (DTS)
传递给操作系统内核
- 避免在内核中编码大量硬件细节
- Bootloader会首先在加载操作系统内核前将子“设备树”文件放到物理内存的特定位置
- 内核中有专门负责解析设备树文件的代码,通过分析该文件即可得知该主板的具体设备信息。设备树使用专门描述硬件设备的专用数据结构。原本这些信息是分散在不同的驱动程序的,设备树源文件将这些信息集中到了一起。
串口:
- 名称:uart0
- 波特率:115200
| C |
| C |
ACPI(高级配置与电源接口)
高级配置与电源接口
- 不仅提供电源管理能力,还提供设备的枚举与发现能力
内核启动后,直接通过询问ACPI接口查询当前主板上都有哪些设备
- 也提供了类似设备树的树状数据结构
每种设备都有自己可识别的名称,比如:串口、网卡,显示器、鼠标、蓝牙、触摸屏、耳机等等



其次是设备寄存器所在的物理内存位置和区间:通常在平台手册中事先标记好了,
中断号:即设备通知CPU到底是通过几号终端来的(操作系统应该怎么把中断处理函数放在中断向量表的哪个位置)
其他的设备信息或属性,比如网卡的工作速率(百兆或是干兆)、或者串口的传输速率,这些属性根据设备的不同类型而各不相同。
通过设备树或ACPI操作系统就可以很方便地在启动时获取所有的设备信息,从而根据相应的设备驱动与之对应,这样就完成了设备驱动与软件的映射
十一
11.1 为什么需要系统虚拟化?
现代IT公司的部署方式:云
- 云服务器代替物理服务器
- 云服务器配置与物理服务器一致
- 所有云服务器维护由服务商提供
- 按需租赁、无需机房租赁费
- 无需雇佣物理服务器管理人员
- 可以快速低成本地升级服务器
云计算的核心支撑技术
新引入的一个软件层
- 上层是操作系统 (虚拟机)
- 底层是硬件

"Any problem in computer science can be solved by another level of indirection"
--- David Wheeler
- 服务器整合:提高资源利用率
- 方便程序开发
- 简化服务器管理
单个物理机资源利用率低
- CPU利用率通常20%
利用系统虚拟化进行资源整合
- 一台物理机中同时运行多台虚拟机
| 提升物理机资源利用率 降低云服务提供商的成本(规模效应) |
- 单步调试操作系统
- 查看当前虚拟硬件的状态
寄存器中的值是否正确
内存映射是否正确
- 随时修改虚拟硬件的状态
- 可以在一台物理机上同时运行在不同的操作系统
- 测试应用程序在不同操作系统上的兼容性
- 虚拟化技术可以让服务器管理者直接通过软件接口管理虚拟机
- 通过软件接口管理虚拟机
- 创建、开机、关机、销毁
- 方便高效
- 虚拟机热迁移
- 方便高效
11.2 虚拟机与虚拟机监控器
虚拟化首先要确认在那个层次,系统虚拟化需要向上运行的虚拟机提供接口,通常,操作系统的接口层有三层:ISA,ABI,API
操作系统中的接口层次:ISA
ISA层
- Instruction Set Architecture
- 区分硬件和软件
- 用户ISA
| 用户态和内核态程序都可以使用 mov x0, sp add x0, x0, #1 |
系统ISA
- 只有内核态程序可以使用
- msr vbar_el1, x0
操作系统中的接口层次:ABI
ABI
- Application Binary Interface
- 提供操作系统服务或硬件功能
- 包含用户ISA和系统调用
许多软件可以运行在Windows7上,也可以运行在Windows10上,这正是由于Windows各个版本向这个软件提供了兼容的ABI
操作系统中的接口层次:API
API
- Application Programming Interface
- 不同用户态库提供的接口
- 包含库的接口和用户ISA
UNIX环境中的clib:
支持UNIX/C编程语言
使用Python语言写的脚本,无论操作系统和硬件架构如何改变,只要当前运行环境安装了Python,那么这个Python脚本就能运行,正是由于他们提供给Python脚本的API是相同的
Hello world
- 使用了APl,因为我写的Hello world脚本在装了python的电脑上都能运行。
- 在Windows上用Visual Studio写的C++的Hello world程序。只能在Windows上跑,在Linux上运行不起来所以应该是用ABI才对。
这个问题需要根据具体情况进行讨论:
①如果某个程序直接使用了操作系统提供的系统调用,那么它就使用了ABI
②如果它完全依赖于语言运行时的接口,那么它就是使用了API
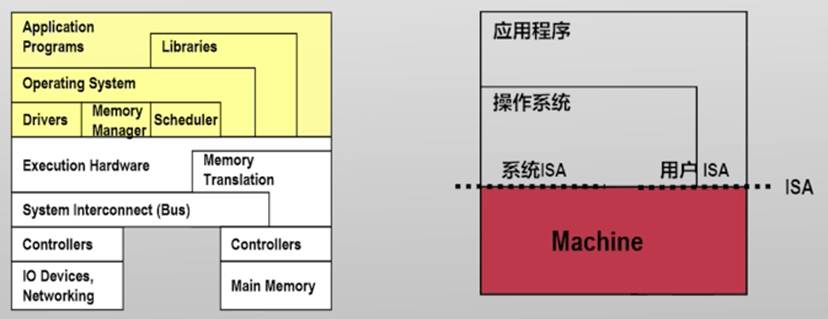
从操作系统角度看"Machine'
- ISA提供了操作系统和Machine之间的界限
虚拟机监控器(VMM/Hypervisor)
- 向上层虚拟机暴露其所需要的ISA
- 可同时运行多台虚拟机(VM)
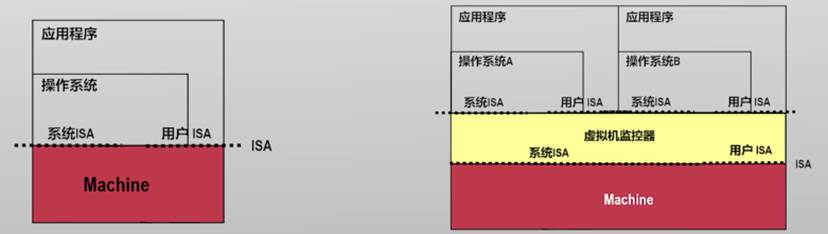
Type-1虚拟机监控器
直接运行在硬件之上
- 充当操作系统的角色
直接管理所有物理资源
提供调度、文件系统、网络等服务
- 性能损失较少
- 例如Xen, VMware ESX Server

Type-2虚拟机监控器
依托于主机操作系统
- 主机操作系统管理物理资源
虚拟机监控器以进程/内核模块的形态运行
- 易于实现和安装
- 例如QEMU/KVM

当前Type-2市场占比远超Type-1,Type-2类型有什么优势?
|
在已有的操作系统之上将虚拟机当做应用运行
复用主机操作系统的大部分功能
- 文件系统
- 驱动程序
- 处理器调度
- 物理内存管理

处理器虚拟化
- 捕捉系统ISA
- 控制虚拟处理器的行为
内存虚拟化
- 提供“假”物理内存的抽象
设备虚拟化
- 提供虚拟的I/O设备
11.3 处理器虚拟化
回顾:ARM的特权级
ELO:用户态进程
EL1:操作系统内核

将虚拟机监控器运行在EL1
将客户操作系统和其上的进程都运行在ELO
当操作系统执行系统ISA指令时下陷
- 写入TTBRO_EL1
- 执行WFI指令

- Trap:在用户态EL0执行特权指令将陷入EL1的VMM中
- Emulate:这些指令的功能都由VMM内的函数实现

非可虚拟化架构:Non-virtualizable
ARM不是严格的可虚拟化架构
| 敏感指令
|
| 特权指令
在ARM中:不是所有敏感指令都属于特权指令 |
| 例子:CPSID/CPSIE指令
内核态执行:PSTATE.{A,I,F}可以被CPS指令修改 在用户态执行:CPS被当做NOP指令,不产生任何效果(不是特权指令) |
方法1:解释执行
使用软件方法一条条对虚拟机代码进行模拟
- 不区分敏感指令还是其他指令
- 没有虚拟机指令直接在硬件上执行
使用内存维护虚拟机状态
- 例如:使用uint64_t x[30]数组保存所有通用寄存器的值
这种方法本质上运行的不是虚拟机而是模拟器,把虚拟机内存中的指令一条一条取出来执行,这样性能就会非常差
所有的状态都是软件状态,所有的模执行都是软件模拟
优点:
- 解决了敏感函数不下陷的问题
- 可以模拟不同ISA的虚拟机
- 易于实现、复杂度低
缺点:
- 非常慢:任何一条虚拟机指令都会转换成多条模拟指令
方法2:二进制翻译
提出两个加速技术
- 在执行前批量翻译虚拟机指令
- 缓存已翻译完成的指令
使用基本块(BasicBlock)的翻译粒度(为什么?)
- 每一个基本块被翻译完后叫代码补丁
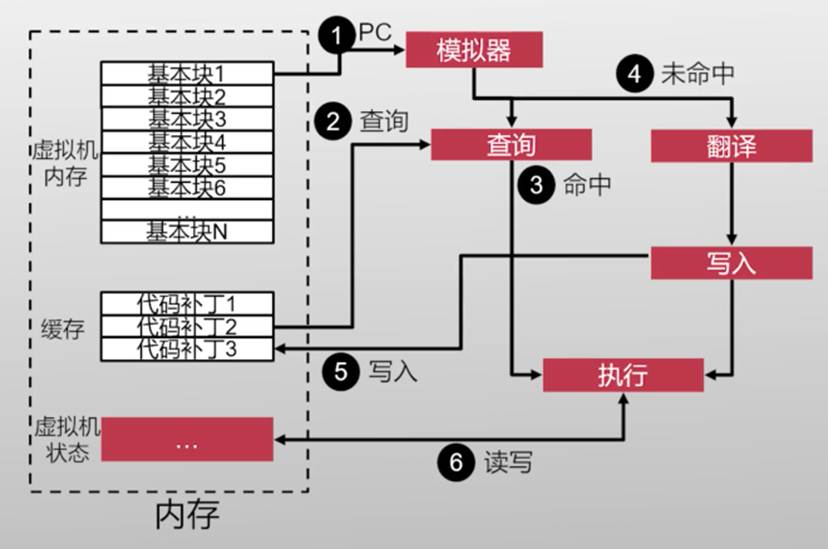
不能处理自修改的代码(Self-modifying Code)
中断插入粒度变大
- 模拟执行可以在任意指令位置插入虚拟中断
- 二进制翻译时只能在基本块边界插入虚拟中断(为什么?)
方法3:半虚拟化(Para-virtualization)
协同设计
- 让VMM提供接口给虚拟机,称为Hypercall
- 修改操作系统源码,让其主动调用VMM接口
Hypercall可以理解为VMM提供的系统调用
- 在ARM中是HVC指令
将所有不引起下陷的敏感指令替换成超级调用
| 在IO场景下,如果guest不知道自己在虚拟机中,那么就会按照真实设备逻辑进行操作,这会产生很多额外的工作和trap要处理,而现在guest OS知道自己运行在虚拟机中,那么就能大大的减少工作流程(简化工作流程),从而大幅提高性能。缺点在于需要修改操作系统代码,从而难以用于闭源操作系统,即便是开源操作系统,在不同版本的适配工作量也可能很大 |
方法4:硬件虚拟化 (改硬件)
ARM和x86都引l入了全新的虚拟化特权级
ARM引I入了EL2
- VMM运行在EL2
- EL2是最高特权级别,控制物理资源
- VMM的操作系统和应用程序分别运行在EL1和ELO
ARM的VM Entry和VMExit
VM Entry
- 使用ERET指令从VMM进入VM
- 在进入VM之前,VMM需要主动加载VM状态
| VM内状态:通用寄存器、系统寄存器、 VM的控制状态:HCR_EL2、VTTBR_EL2等 |
ARM的VM Entry和VM Exit
VM Exit
- 虚拟机执行敏感指令或收到中断等
- 以Exception、IRQ、FIQ的形式回到VMM调用VMM记录在vbar_el2中的相关处理函数
- 下陷第一步:VMM主动保存所有VM的状态
11.4 内存虚拟化
为虚拟机提供虚拟的物理地址空间
- 物理地址从0开始连续增长
隔离不同虚拟机的物理地址空间
- VM-1无法访问其他的内存
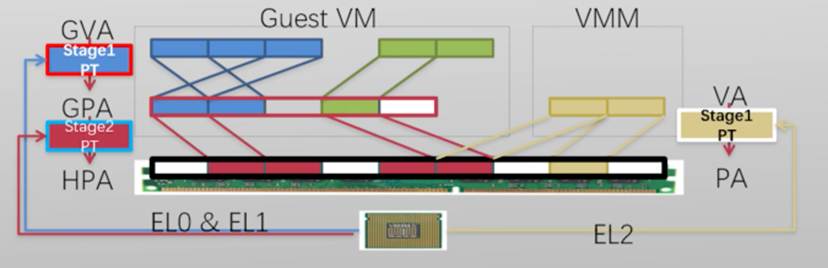
- 客户虚拟地址(Guest Virtual Address,GVA)
- 虚拟机内使用的虚拟地址
- 客户物理地址(Guest Physical Address, GPA)
- 虚拟机内使用的”假”物理地址
- 主机物理地址(Host Physical Address,HPA)
- 真实寻址的物理地址
- GPA需要翻译成HPA才能访存
- 影子页表(Shadow Page Table)
- 直接页表(Direct Page Table)
- 硬件虚拟化
InteIVT-x和ARM硬件虚拟化都有对应的内存虚拟化
- Intel Extended Page Table (EPT)
- ARM Stage-2 Page Table (第二阶段页表)
新的页表
- 将GPA翻译成HPA
- 此表被VMM直接控制
- 每一个VM有一个对应的页表
第一阶段页表:虚拟机内虚拟地址翻译(GVA->GPA)
第二阶段页表:虚拟机客户物理地址翻译(GPA->HPA)
- VTTBR_EL21
总共24次内存访问
- 为什么?
- 25-1
- 第一次访问寄存器
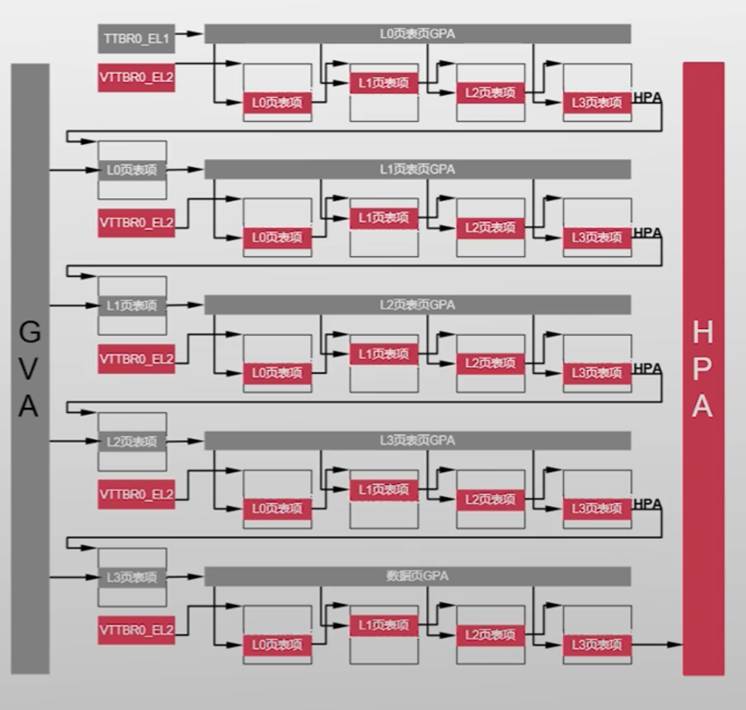
TLB:缓存地址翻译结果
回顾:TLB不仅可以缓存第一阶段地址翻译结果
TLB也可以第二阶段地址翻译后的结果
- 包括第一阶段的翻译结果(GVA->GPA)
包括第二阶段的翻译结果(GPA->HPA)
大大提升GVA->HPA的翻译性能:不需要24次内存访问
切换VTTBR_EL2时
- 理论上应将前一个VM的TLB项全部刷掉
两阶段翻译的缺页异常分开处理
- 第一阶段缺页异常(GVA->GPA)
- 直接调用VM的Page faulthandler
- 修改第一阶段页表不会引起任何虚拟机下陷
- 第二阶段缺页异常(GPA->HPA)
- 虚拟机下陷,直接调用VMM的Page fault handler
优点
- VMM实现简单
- 不需要捕捉GuestPageTable的更新
- 减少内存开销:每个VM对应一个页表
缺点
- TLBmiss时性能开销较大
总的来说,内存虚拟化这部分相比CPU虚拟化部分要简单很多,只需记住 “三种地址的含义”与“二级页表的转换关系”就能掌握整套内存虚拟化的运作原理
11.5 I/O虚拟化&中断虚拟化
为什么需要IO虚拟化
回顾:操作系统内核直接管理外部设备
- PIO
- MMIO
- DMA
- Interrupt
如果VM能直接管理物理设备
- 会发生什么?
如果VM直接管理物理网卡
正确性问题:所有VM都直接访问网卡
- 所有VM都有相同的MAC地址、IP地址,无法正常收发网络包
安全性问题:恶意VM可以直接读取其他VM的数据
- 除了直接读取所有网络包,还可能通过DMA访问其他内存
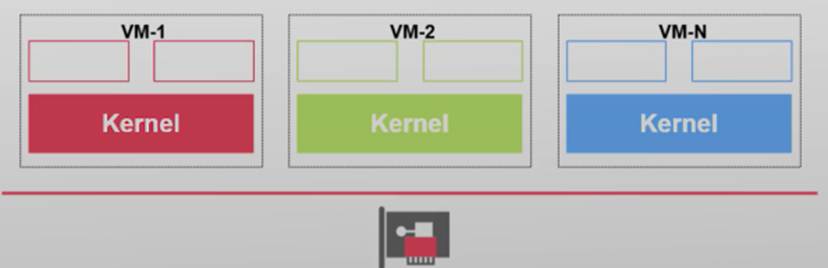
I/O虚拟化的目标
为虚拟机提供虚拟的外部设备
- 虚拟机正常使用设备
隔离不同虚拟机对外部设备的直接访问
- 实现I/O数据流和控制流的隔离
提高物理设备的利用资源
- 多个VM同时使用,可以提高物理设备的资源利用率
实现IO虚拟化主要有三种方式:
1. 设备模拟
OS与设备交互的硬件接口
- 模拟寄存器(中断等)
- 捕捉MMIO操作
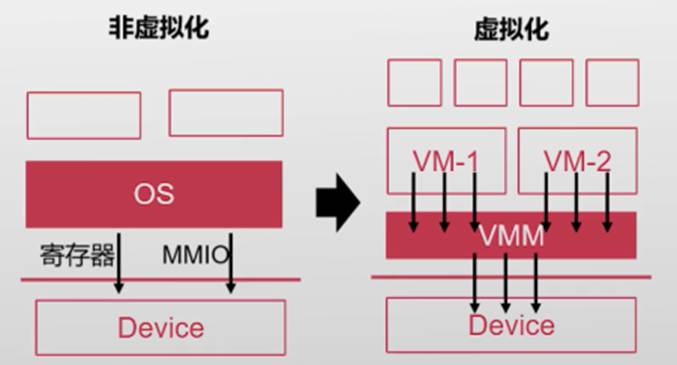
硬件虚拟化的方式
- 硬件虚拟化捕捉PIO指令
- MMIO对应内存在第二阶段页表中设置为invalid
优点
- 可以模拟多种设备
因而可以支持较“久远”的OS
- 允许在中间拦截(lnterposition) :
例如在QEMU层面检查网络内容
- 不需要硬件虚拟化
缺点:性能不佳
2. 半虚拟化方式
协同设计
- 虚拟机“知道”自己运行在虚拟化环境
- 虚拟机内运行前端(front-end)驱动
- VMM内运行后端(back-end)驱动
VMM主动提供Hypercall给VM,通过共享内存传递指令和命令
优点
- 性能优越
多个MMIO/PIO指令可以整合成一次Hypercal
- VMM实现简单,不再需要理解物理设备接口
缺点
- 需要修改虚拟机操作系统内核
3. 设备直通
虚拟机直接接管设备
| 问题1:破坏虚拟机间的隔离性,如:虚拟机可以直接通过设备的DMA来恶意读写内存(可以通过IOMMU来限制这个问题) |
使用IOMMU
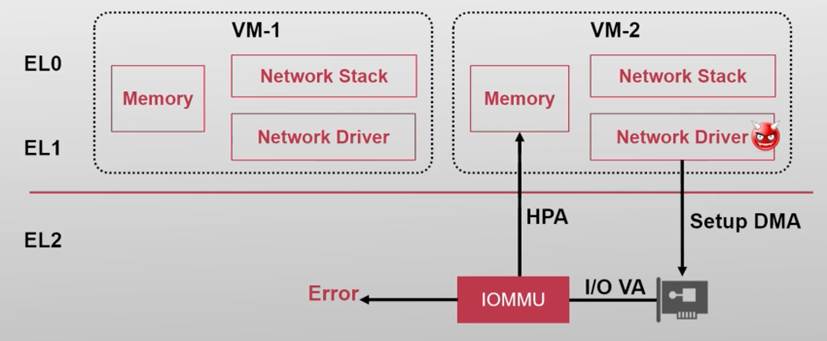
| 问题2:设备独占 Scalability不够
如果一台物理机上运行16个虚拟机
|
Single Root I/O Virtualization (SRlOV)
SR-IOV是PCI-SIG组织确定的标准
满足SRIOV标准的设备,在设备层实现设备复用
- 能够创建多个VirtualFunction(VF),每一个VF分配给一个VM负责进行数据传输,属于数据面(Data-plane)
- 物理设备被称为PhysicalFunction(PF),由Host管理负责进行配置和管理,属于控制面(Control-plane)
优点
- 性能优越
- 简化VMM的设计与实现
缺点
- 需要特定硬件功能的支持(IOMMU、SRIOV等)
- 不能实现lnterposition:难以支持虚拟机热迁移
VMM在完成I/O操作后通知VM
- 例如在DMA操作之后
VMM在VM Entry时插入虚拟中断
- VM的中断处理函数会被停用
虚拟中断类型
- 时钟中断,核间中断,外部中断
ARM中断虚拟化的实现方法
打断虚拟机执行(性能差一些)
- 通过List Register插入
不打断虚拟机执行(物理机直接向虚拟机发送虚拟中断;免去了VMM的介入处理,上下文切换的开销)
- 通过GIC ITS插入
11.6 案例:QEMU/KVM
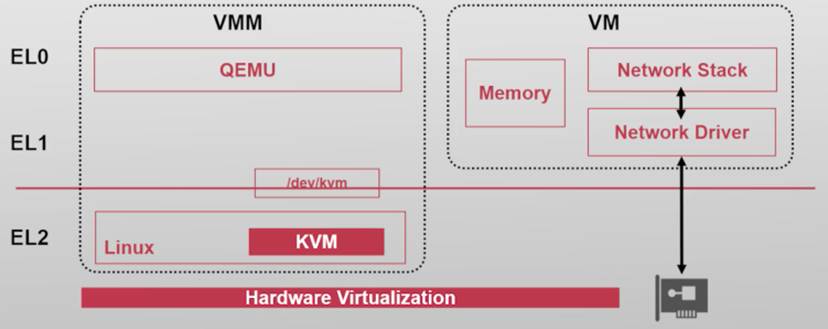
当前工业界用的最多的系统虚拟化方案就是QEMU/KVM
- KVM是linux内核中的一个模块
- Qemu是在用户态与它配合执行的一个项目
QEMU发展历史
2003年,法国程序员FabriceBellard发布了QEMU0.1版本
- 目标是在非x86机器上使用动态二进制翻译技术模拟x86机器
2003-2006年
- 能模拟出多种不同架构的虚拟机,包括S390、ARM、MIPS、SPARC等
- 在这阶段,QEMU一直使用软件方法进行模拟
如二进制翻译技术
KVM发展历史
2007年,KVM被整合进Linux 2.6.20
2008年9月,Redhat出资1亿多美元收购Qumranet
2009年,QEMU0.10.1开始使用KVM,以替代其软件模拟的方案
QEMU/KVM架构
QEMU运行在用户态,负责实现策略
- 也提供虚拟设备的支持
KVM以Linux内核模块运行,负责实现机制
- 可以直接使用Linux的功能
- 例如内存管理、进程调度
- 使用硬件虚拟化功能
两部分合作
- KVM捕捉所有敏感指令和事件,传递给QEMU
- KVM不提供设备的虚拟化,需要使用QEMU的虚拟设备
- 1个虚拟机对应1个QEMU进程
- 虚拟机的VCPU对应QEMU的线程
QEMU使用KVM的用户态接口
QEMU使用/dev/kvm与内核态的KVM通信
- 使用ioctl向KVM传递命令:
CREATE_VM,CREATE_VCPU,KVM_RUN等
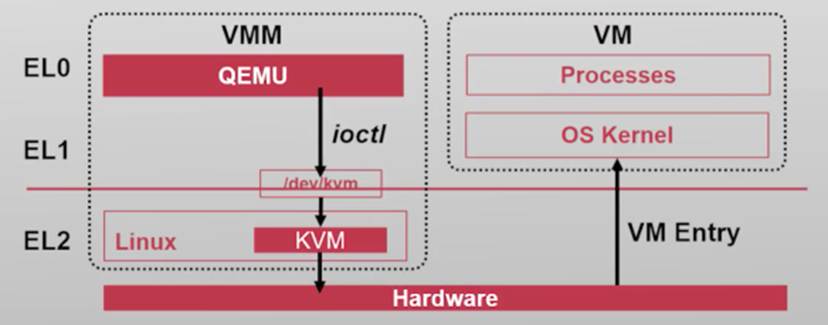
例:I/O指令VMExit的处理流程
QEMU使用/dev/kvm与内核态的KVM通信
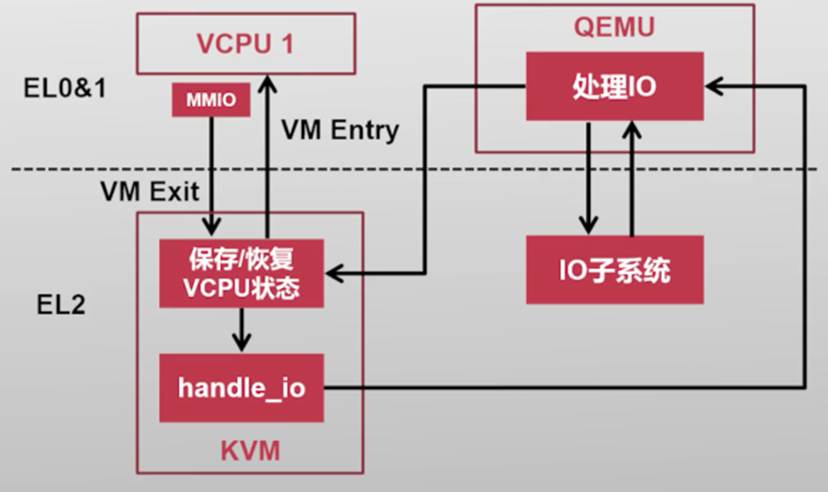
| 首先当一个虚拟运行时,想要执行一条MMIO相关的指令,那么就会产生trap被kpm捕捉到,kvm先保存这个虚拟机的所有状态,然后判断出这个trap是和MMIO相关,应该交给KVM处理,于是就返回用户态交给QEMU进行IO设备的模拟处理,当QEMU完成后,会再次调用KVM进入内核,KVM恢复虚拟机的所有状态后,会重新使用VM Entry进入虚拟机,再继续执行 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









