






第一章 绪论
1.1机器学习的概念
机器学习(machine learning)致力于通过计算的手段,利用经验来改善自身的性能。在计算机中,“经验”以“数据”的方式存在,因此,机器学习研究的主要内容就是如何让机器从经验(数据)中总结出模型(model),实现这一过程的算法被称作学习算法(learning algorithm)。产生模型之后,在面对新的情形时,就能基于模型得出更准确的判断。
1.2 基本术语
由上文我们可以知道,数据是机器学习最基本的养料,深蓝的夜空中挂着一轮金黄的圆月...想象一大波西瓜正在袭来,有强迫症的你决定从三个重要方面标记好它们各自的特征,以便后续做出区分。于是你得到了很多信息,例如你左手边的几个瓜分别是:(色=绿;瓜蒂=蜷缩;声=浊),(色=黑;瓜蒂=稍蜷;声=闷)...(色=白,瓜蒂=直挺挺;声=脆)
每对括号内是一条记录,“=”表示取值于
| (色=绿;瓜蒂=蜷缩;声=浊), (色=黑;瓜蒂=稍蜷;声=闷)... (色=白,瓜蒂=直挺挺;声=脆) | 所有记录的集合 | 数据集 (data set) |
| (色=绿;瓜蒂=蜷缩;声=浊) | 关于一个事件或对象 (此处为西瓜)的描述 | 示例 / 样本 (instance/ sample) |
| 色、瓜蒂、声 | 反映事件或对象在某 方面的表现或性质的事项 | 属性 / 特征 (attribute/ feature) |
| 绿、黑、白 | 属性的取值 | 属性值 (value) |
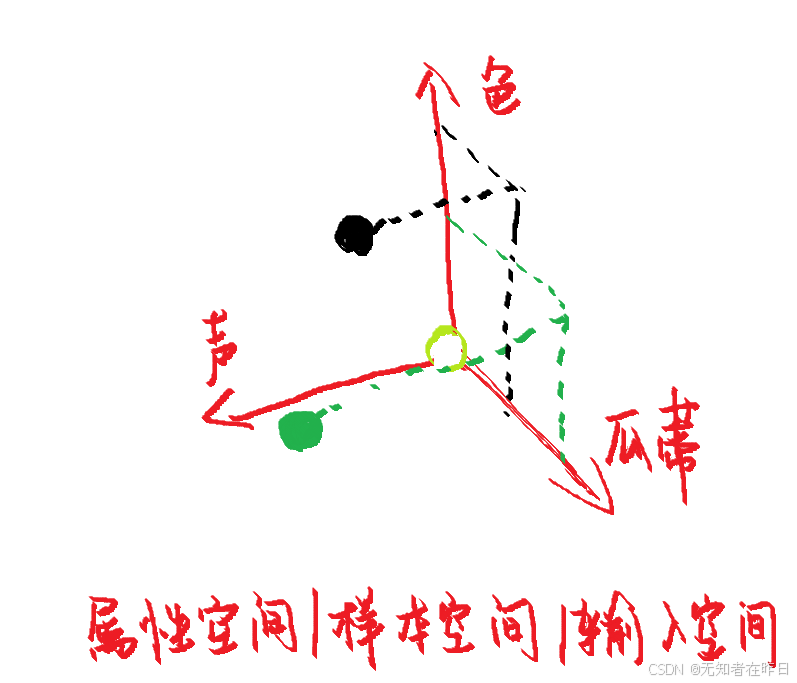
属性张成的空间称为:属性空间(attribute space)/样本空间(sample space)/输入空间(最重要的是,每个西瓜都有了一个家)
空间中的每个点对应一个坐标向量,因此我们也可以把每个示例也就是每个样本称为一个
“特征向量”(feature vector)

d为样本空间的维数(dimensionality)
得到数据还不够,你可不想抱着坏瓜回家,下一步,模型!
| 学习(learning)/训练(training) | 从数据中获得模型的过程 |
| 训练数据(training data) | 训练过程中使用的数据 |
| 训练样本(training sample) | 使用的训练数据中的每一个样本 |
| 训练集(training set) | 训练样本的集合 |
| 假设(hypothesis) | 学得的模型对应的关于数据的某种潜在规律 |
| 真相/真实(ground-truth) | ↑那种潜在规律本身,学习过程就是为了找出更为贴近真相的假设 |
| 学习器(learner) | 模型的别称,可看作学习算法在给定空间和参数条件下的实例化 |
为了得到模型,我们必须得到一些已知的判断好坏瓜的信息,你浅尝了几个西瓜,得到了代表瓜好坏的“结果”信息,并给这些瓜添加了新的标记(label),例如:
(色=绿;瓜蒂=蜷缩;声=浊)→((色=绿;瓜蒂=蜷缩;声=浊),好瓜)
示例→样例
这里的“好瓜”这种关于示例结果的信息就是标记,添加了标记的示例称作样例(example)
(xi,yi)表示第i个样例,所有标记的集合称作标记空间(label space)或输出空间
机器通过学习能得到的关于“预测(prediction)”的模型似乎很厉害,也许你能得到更多的模型,不止于预测西瓜的好坏。这些你想要预测的值决定机器要进行怎样的学习任务:
| 分类(classification) | 预测的是离散值,例如“好瓜”、“坏瓜” |
| 回归(regression) | 预测的是连续值,例如西瓜的成熟度为0.95、0.83 |
| 二分类任务(binary classification) | 只涉及两个类别的任务,称其中一个为正类(positive class),剩下一个为反类(negative class)或负类( |
| 多分类任务(multi-class classification) | 涉及多个类别的任务 |
一般地,学习任务是希望通过对训练集{(x1,y1),(x2,y2)...(xn,yn)}进行训练,得出一个从输入空间X到输出空间Y的映射f:x→y;对于二分类任务,通常令Y={+1,-1}或{0,1};多分类任务则是|Y|>2;对于回归类任务,Y=R(实数集)
使用产生的模型进行预测的过程称为“测试”(testing),被测试的样本称为测试样本(testing sample)(也称测试示例/测试例),对于测试样本x,通过预测可得到它的预测标记y=f(x)
此外,我们还可以把西瓜分成若干个小组——即对西瓜进行“聚类”(clustering),每一个小组称为“簇”(cluster),这些簇是自动形成的,背后可能会对应一些如“本地瓜”、“外地瓜”的潜在概念。注意:1.这些概念事先不为我们所知 2.聚类学习的学习过程中通常不拥有标记信息
根据训练数据是否含有标记信息,学习任务可分为以下两大类:
监督学习(supervised learning) 代表为分类和回归
无监督学习(unsupervised learning) 代表为聚类
机器学习最终目标是让预测模型能够很好地适应新样本,这种能力称作泛化(generalization),不止于此,为了真正使在训练集上得到的模型对整个样本空间中的新样本都工作的很好,机器学习还需要——四两拨千斤,最好是投入采样于样本空间少量数据的训练集就能达到很好地反映整个样本空间的特性的效果,能做到这点的称为具有强泛化能力的模型。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









