






如何使用GA-SVM(遗传算法优化的支持向量机)处理小样本_DGA变压器故障诊断相关 变压器油中溶解气体,7种特征量的小样本数据集,5种特征量的数据集
文章目录
以下文字及代码仅供参考。
DGA变压器故障诊断相关
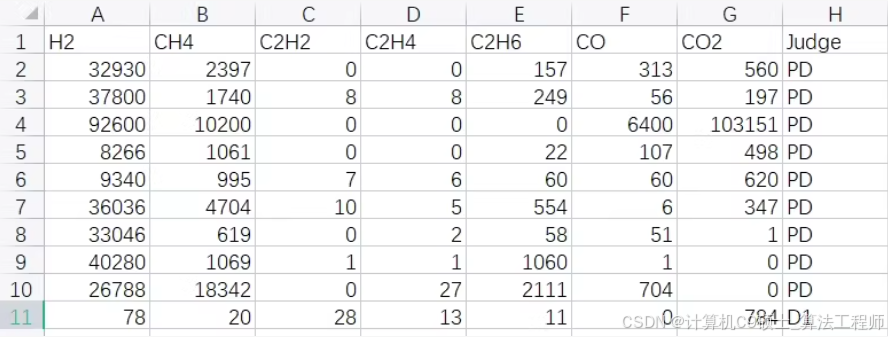
变压器油中溶解气体,7种特征量的小样本数据集(含五种故障类型,样本数117),5种特征量的数据集(含五种故障类型,样本数670左右)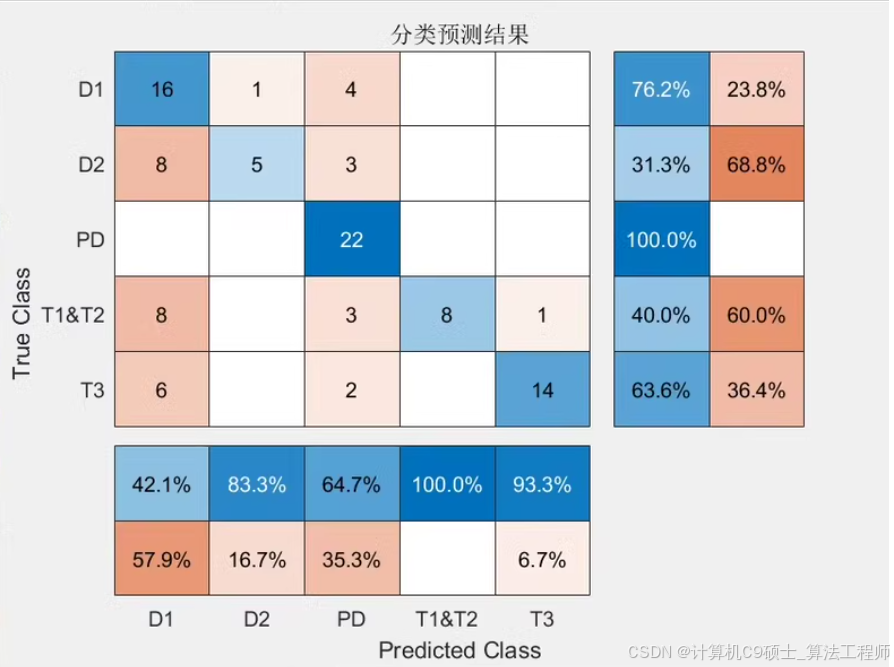
1
基于遗传算法优化的支持向量机(GA-SVM)在变压器故障诊断中的应用
如何使用遗传算法优化支持向量机的参数,并将其应用于变压器故障诊断任务中。该代码包括数据准备、适应度函数定义、遗传算法优化过程以及最终模型的训练和评估。
1. 数据准备
首先,假设你已经将数据导入到MATLAB环境中。这里我们创建一个简单的示例来加载或生成数据。
% 示例:生成或加载你的数据集
% 对于实际应用,请替换为从文件加载的数据
X = rand(117, 7); % 示例特征数据,117个样本,每样本7个特征
Y = randi([1,5], 117, 1); % 示例标签数据,5种故障类型
% 划分训练集和测试集
cv = cvpartition(Y, 'HoldOut', 0.2);
X_train = X(training(cv), :);
Y_train = Y(training(cv), :);
X_test = X(test(cv), :);
Y_test = Y(test(cv), :);
% 进一步划分训练集为训练集和验证集
cv_train = cvpartition(Y_train, 'HoldOut', 0.2);
X_train_final = X_train(training(cv_train), :);
Y_train_final = Y_train(training(cv_train), :);
X_val = X_train(test(cv_train), :);
Y_val = Y_train(test(cv_train), :);
2. 定义适应度函数
此函数用于遗传算法中评估个体的表现,即SVM模型在验证集上的性能。
function fitness = fitnessFcn(params, X_train, Y_train, X_val, Y_val)
sigma = params(1);
C = params(2);
% 训练SVM模型
model = fitcsvm(X_train, Y_train, 'KernelFunction', 'rbf', ...
'BoxConstraint', C, 'KernelScale', sigma, 'Standardize', true, 'ClassNames', unique(Y_train));
% 预测验证集
[~, score] = predict(model, X_val);
[~, predictedLabels] = max(score,[],2);
% 计算准确率作为适应度值
accuracy = sum(predictedLabels == Y_val) / length(Y_val);
fitness = -accuracy; % 注意:GA最小化目标函数,所以我们取负准确率
end
3. 使用遗传算法优化SVM参数
% 设置遗传算法选项
options = optimoptions('ga', 'PopulationSize', 50, 'MaxGenerations', 20, ...
'PlotFcn', {@gaplotbestf, @gaplotstopping});
% 定义参数范围
lb = [0.1, 0.1]; % 下界
ub = [10, 100]; % 上界
% 运行遗传算法
[x, fval] = ga(@(params) fitnessFcn(params, X_train_final, Y_train_final, X_val, Y_val), ...
2, [], [], [], [], lb, ub, [], options);
% 获取最优参数
best_sigma = x(1);
best_C = x(2);
fprintf('Best Sigma: %.4f, Best C: %.4f\n', best_sigma, best_C);
4. 使用优化后的参数训练最终模型
% 使用最佳参数重新训练SVM模型
finalModel = fitcsvm(X_train, Y_train, 'KernelFunction', 'rbf', ...
'BoxConstraint', best_C, 'KernelScale', best_sigma, 'Standardize', true, 'ClassNames', unique(Y_train));
% 在测试集上进行预测
[~, score] = predict(finalModel, X_test);
[~, predictedLabels] = max(score,[],2);
% 计算并显示测试集上的准确率
testAccuracy = sum(predictedLabels == Y_test) / length(Y_test);
disp(['Test Accuracy: ', num2str(testAccuracy)]);
这个MATLAB脚本提供了一个完整的流程,从数据准备到使用遗传算法优化支持向量机的参数,再到最终模型的训练和评估。请根据实际情况调整代码,特别是数据加载部分,确保正确加载您的数据集
评估支持向量机(SVM)模型的性能是确保其有效性和可靠性的重要步骤。以下是一些常用的评估指标和方法,以及如何在MATLAB中实现这些评估:
常用评估指标
- 准确率(Accuracy):正确分类的样本数占总样本数的比例。
- 精确率(Precision):预测为正类的样本中实际为正类的比例。
- 召回率(Recall):实际为正类的样本中被正确预测为正类的比例。
- F1分数(F1 Score):精确率和召回率的调和平均数,提供了一个平衡两者的方法。
- ROC曲线与AUC值(Receiver Operating Characteristic Curve & Area Under the Curve):用于展示不同阈值下的模型性能,AUC值越大,模型区分能力越强。
在MATLAB中实现评估
假设你已经有了训练好的SVM模型,并且有测试集的数据X_test和标签Y_test,下面是如何在MATLAB中计算上述指标的示例代码。
1. 准备工作
首先,使用你的SVM模型对测试集进行预测。
% 假设finalModel是你已经训练好的SVM模型
[~, score] = predict(finalModel, X_test);
[~, predictedLabels] = max(score,[],2); % 对于多类别问题,选择得分最高的类别作为预测结果
2. 计算基本评估指标
% 导入必要的工具箱
import matlab.unittest.constraints.IsEqualTo;
import matlab.unittest.diagnostics.Diagnostic;
% 计算混淆矩阵
confMat = confusionmat(Y_test, predictedLabels);
% 计算准确率
accuracy = sum(diag(confMat)) / sum(confMat(:));
fprintf('Accuracy: %.2f%%\n', accuracy * 100);
% 计算精确率、召回率和F1分数
precision = diag(confMat) ./ sum(confMat);
recall = diag(confMat) ./ sum(confMat, 2);
f1Score = 2 .* precision .* recall ./ (precision + recall);
% 显示每个类别的精确率、召回率和F1分数
for i = 1:length(unique(Y_test))
fprintf('Class %d - Precision: %.2f, Recall: %.2f, F1 Score: %.2f\n', ...
unique(Y_test)(i), precision(i), recall(i), f1Score(i));
end
3. 绘制ROC曲线并计算AUC值
对于二分类问题,可以直接使用perfcurve函数来绘制ROC曲线并计算AUC值。对于多分类问题,则需要分别对每一类进行处理。
% 仅适用于二分类问题
if length(unique(Y_test)) == 2
[X,Y,T,AUC] = perfcurve(Y_test, score(:,2), 1); % 假设第二列为正类的概率
figure;
plot(X,Y);
xlabel('False positive rate');
ylabel('True positive rate');
title(['ROC Curve, AUC = ', num2str(AUC)]);
else
% 对于多分类问题,可以循环遍历每个类别
for i = 1:length(unique(Y_test))
[~,~,~,AUC(i)] = perfcurve(Y_test, score(:,i), unique(Y_test)(i));
fprintf('Class %d - AUC: %.2f\n', unique(Y_test)(i), AUC(i));
end
end
评估SVM模型在特定数据集上的性能。这不仅包括了基本的准确性度量,还包括了更详细的分类效果分析(如精确率、召回率、F1分数)以及模型区分能力的评估(如AUC)。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









