






前言
在上篇文章中已介绍了启发式优化算法的相关内容及其在模式识别领域中的应用。本文以使用优化算法优化多机器学习分类器在某二分类模式识别任务时决策级融合(加权投票)的权重为例,介绍遗传算法的原理及实现过程。
1.1 算法原理
遗传算法(Genetic Algorithms, GA)最开始是在20世纪60年代提出来的,美国Michigan大学的Holland教授根据自然界繁殖、杂交和突变现象提出的一种搜索算法。在构建遗传算法时,根据染色体的构成模式,需要将问题转换成类似DNA编码的方式,就需要将问题可能出现的所有解进行编码,编码的方式多种多样包括二进制编码、实数编码等等,需要根据具体问题具体决定。在编码完成之后,会首先确定适应度的计算方式,规定什么样的个体属于优质个体,通过模拟自然界物竞天择适者生存的规律,选取优质个体,淘汰劣质个体,在选取的优质个体之间进行杂交和变异,从中挑选可能产生的更加优质的个体,不断循环迭代,使种群越来越优,直到满足期望的条件为止。(实际应用中演变截至条件可通过设置最大迭代次数或者最佳适应度实现)
遗传算法搜寻最优解的大致流程如图1所示。该过程主要包含三大步骤:选择操作、交叉操作和变异操作。
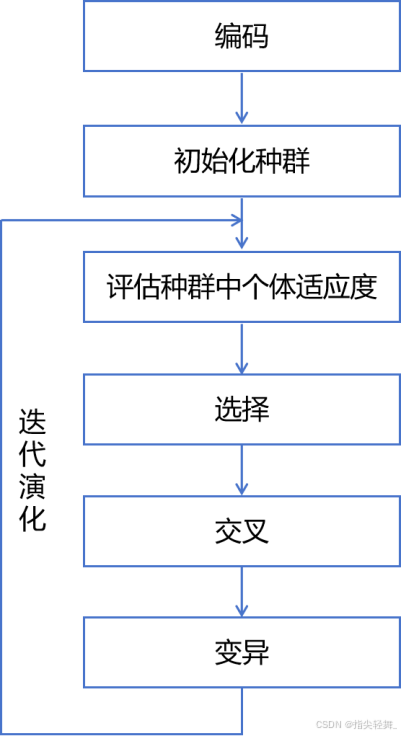
图1 遗传算法过程图解
(1)选择操作
选择操作实际上是自然界物竞天择适者生存的过程,通过自然界的选择,适应环境的个体保留,适应不了的个体则被淘汰,选择操作的目的就是模仿自然界选择的过程,尽可能的选出适应度高的个体,为后续交叉变异算子提供基础。在这一步骤中通常需根据实际优化任务设置适应度函数(Fitness function),在每轮迭代中选择适应度最高的两个个体保留进行后续操作。
(2)交叉操作
交叉操作实际上是模仿自然界杂交的方式,通过交换染色体的特定区域,来保证种群内的个体不是一成不变的,使种群存在着向更优的方向进行的可能性,该过程是遗传算法获得更加优良个体的重要手段。图2为交叉操作的示意图,该图以二进制编码方式具体,实际过程中需根据优化的对象而定,本文以二进制数值为例,取值范围是0和1。

图2 交叉操作示意图
(3)变异操作
变异操作实际上是自然选择中的基因突变,即染色体中的DNA在遗传的过程中发生了变异,这种变异可能是良性的,也可能是恶性的,但一定是随机的,在遗传算法中,变异操作提升了种群的多样性,防止种群在还为达到最优效果时就已经收敛了。相比交叉操作,变异操作发生的概率要小的多,变异位置也是完全随机的变异操作如图 3所示,图示变异操作方便理解以二进制编码方式举例。

图3 变异操作示意图
1.2 分类任务示例
针对某二分类模式识别任务,本文共采用十种典型的机器学习分类算法。它们分别是:线性判别分析(LDA)、高斯贝叶斯分类器(GNB)、k近邻分类器(KNN)、逻辑回归分类器(LR)、决策树分类器(DT)、随机森林分类器(RF)、支持向量机分类器(SVM)、多层感知机分类器(MLP)、自适应提升分类器(Adaboosting)、梯度提升分类器(GradientBoosting)。以下是分类器的导入方法。
| 机器学习分类器 | 导入方法 |
| LDA | from sklearn.discriminant_analysis import LinearDiscriminantAnalysis |
| GNB | from sklearn.naive_bayes import GaussianNB |
| KNN | from sklearn.neighbors import KNeighborsClassifier |
| LR | from sklearn.linear_model import LogisticRegression |
| DT | from sklearn import tree |
| RF | from sklearn.ensemble import RandomForestClassifier |
| SVM | from sklearn.svm import SVC |
| MLP | from sklearn.neural_network import MLPClassifier |
| Adaboosting | from sklearn.ensemble import AdaBoostClassifier |
| GradientBoosting | from sklearn.ensemble import GradientBoostingClassifier |
注:以上十种机器学习分类器的均使用默认参数进行分类任务。
以上分类器均先使用训练集进行训练,训练完毕后使用测试集进行测试,各个分类器在测试集上的准确率如图4所示,其中GBDT分类器的精度最高为93.23%。
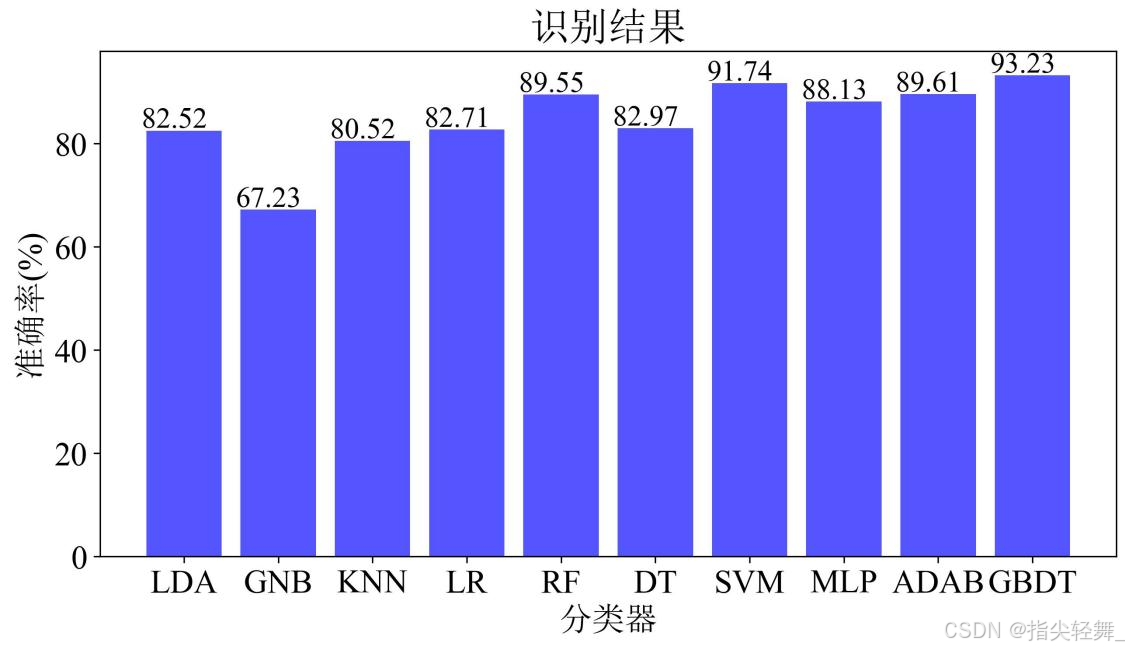
图4 十种机器学习分类器准确率
1.3 算法应用
在使用遗传算法对上述十种分类器的投票权重进行优化时,需先初始化种群数量n,在本案例中我们设置种群数量n=50,每个个体包含10个基因(因为有10个分类器),基因的取值范围是[0, 1](每个分类器的权重),即下边界为0,上边界为1,该过程是个随机化的过程,随机在[0, 1]范围内取值。演变截至条件通过最大迭代次数实现,设置generations=50;接着设置本案例的适应度函数,在本文中将加权投票识别结果的准确率作为适应度函数,如下式所示。
![]()
初始条件设置完成后,首先执行算法的选择过程,计算种群内每个个体的适应度,选择具有最优适应度的个体作为下一代的父辈和母辈
。在选择了父母之后,可以应用交叉来创建后代,交叉过程中需预先设定一个交叉率,本案例设为0.5,生成[0, 1]之间的随机数与交叉率比较,当小于交叉率时执行交叉操作,交叉点也是随机生成的。
在执行完交叉后进入突变阶段,该过程也是设置突变率(本案例设为0.5)和生成随机数来判断基因是否产生突变,通过遍历每个基因,生成新一代的种群,最后通过计算适应度,确定最优个体。
到此,遗传算法完成一次迭代演化。遗传算法每一次迭代都可确定一个最优个体。该过程循环50次,可得到50个最优个体,通过对比确定最终的最优解。在本案例中最优解为:
| 0.0085 | 0.0018 | 0.0 | 0.0287 | 0.3325 | 0.3439 | 0.7264 | 0.1434 | 0.9819 | 0.9013 |
图5展示了使用遗传算法优化后与未优化之前各个基分类器准确率的对比,从图中不难看出GA优化后的分类结果为94.32%,比基分类器中最好的GBDT模型提升1.09%。
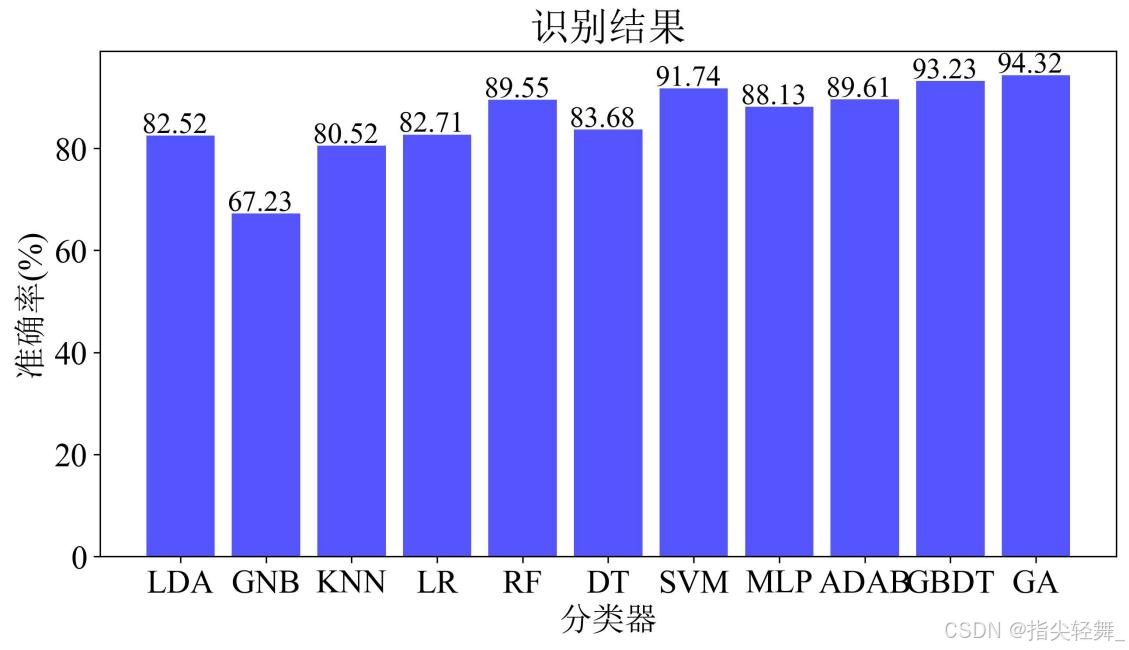
图5 十种机器学习分类器与遗传算法优化对比
1.4 代码演示
导入所需功能包
import numpy as np
from sklearn.metrics import confusion_matrix
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn import tree
from sklearn.svm import SVC
from sklearn.neural_network import MLPClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from deap import base, creator, tools, algorithms
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.family'] = 'Times New Roman, SimSun'定义十种机器学习分类器
#线性判别分析
def lda_classifier(train_x, train_y):
model = LinearDiscriminantAnalysis()
model.fit(train_x, train_y)
return model
# 线性回归分类器(贝叶斯分类)
def gaussian_classifier(train_x, train_y):
model = GaussianNB()
model.fit(train_x, train_y)
return model
# K近邻分类器
def knn_classifier(train_x, train_y):
model = KNeighborsClassifier()
model.fit(train_x, train_y)
return model
# 逻辑回归分类器
def logistic_regression_classifier(train_x, train_y):
model = LogisticRegression(penalty='l2',solver='lbfgs', max_iter=100)
model.fit(train_x, train_y)
return model
# 随机森林分类器
def random_forest_classifier(train_x, train_y):
model = RandomForestClassifier(n_estimators=8,random_state=66)
model.fit(train_x, train_y)
return model
# 决策树分类器
def decision_tree_classifier(train_x, train_y):
model = tree.DecisionTreeClassifier()
model.fit(train_x, train_y)
return model
# 支持向量机
def svm_classifier(train_x, train_y):
model = SVC(kernel='rbf', probability=True)
model.fit(train_x, train_y)
return model
# 多层感知机
def mlp_classifier(train_x, train_y):
model = MLPClassifier(hidden_layer_sizes=(10, 10), max_iter=1000, alpha=0.001, random_state=42)
model.fit(train_x, train_y)
return model
# 自适应提升分类器
def ada_boosting_classifier(train_x, train_y):
model = AdaBoostClassifier(n_estimators=200)
model.fit(train_x, train_y)
return model
# 梯度提升分类器
def gradient_boosting_classifier(train_x, train_y):
model = GradientBoostingClassifier(n_estimators=200)
model.fit(train_x, train_y)
return model
# 绘制准确度统计图
def plot_acc(acc_list, ga_acc):
ary = acc_list
ary.append(ga_acc)
lab = ['LDA','GNB','KNN', 'LR', 'RF', 'DT', 'SVM', 'MLP','ADAB','GBDT', 'GA']
plt.rcParams.update({'font.size': 18})
plt.figure(figsize=(10, 5))
plt.bar(range(len(ary)), ary, color='#5555FF')
plt.xticks(range(len(ary)), lab)
for j in range(11):
plt.text(x=j-0.45, y=ary[j] + 0.6, s='%.2f' % ary[j], fontsize=16)
plt.ylabel('准确率(%)', fontsize=18)
plt.xlabel('分类器', fontsize=18)
plt.title('识别结果')
# plt.show()
# plt.savefig('acc.jpg',dpi=300, bbox_inches='tight', pad_inches=0.1)加载分类任务的训练集和测试集完成训练,并输出单分类器的分类指标
data_train = pd.read_csv(r"xxx.csv", header = None)
data_test = pd.read_csv(r"xxx.csv", header = None)
data_train = np.array(data_train)
data_test = np.array(data_test)
test_classifiers = ['LDA','GNB','KNN', 'LR', 'RF', 'DT', 'SVM', 'MLP','ADAB','GBDT']
classifiers = {'LDA':lda_classifier,
'GNB':gaussian_classifier,
'KNN':knn_classifier,
'LR':logistic_regression_classifier,
'RF':random_forest_classifier,
'DT':decision_tree_classifier,
'SVM':svm_classifier,
'MLP':mlp_classifier,
'ADAB':ada_boosting_classifier,
'GBDT':gradient_boosting_classifier,
}
train_x = data_train[:, :xx]
train_y = data_train[:, -1]
test_x = data_test[:, :xx]
test_y = data_test[:, -1]
acc_list = []
for classifier in test_classifiers:
model = classifiers[classifier](train_x, train_y)
predict = model.predict(test_x)
c = confusion_matrix(test_y, predict)
acc = (c[0][0] + c[1][1]) / (np.sum(c)) * 100
sens = c[0][0] / np.sum(c[:, 0]) * 100
spec = c[0][0] / np.sum(c[0]) * 100
f1_score = 2*sens*spec/(sens+spec)
acc_list.append(acc)
print('{}分类器的准确率为:{:.2f}%, 精确率为:{:.2f}%, 召回率为:{:.2f}%, F1分数为:{:.2f}%'.format(classifier, acc, sens, spec, f1_score))list_model = []
for classifier in test_classifiers:
model = classifiers[classifier](train_x, train_y)
list_model.append(model)
# print(list_model)
predict = [list_model[i].predict_proba(test_x) for i in range(10)]定义适应度函数
# 定义适应度函数
def evaluate(individual):
# 获取个体的分类器权重
weights = np.array(individual)
# 根据权重对预测结果进行加权融合
combined_pred = sum(w * p for w, p in zip(weights, predict))
final_pred = np.argmax(combined_pred, axis=1)
accuracy = np.mean(final_pred == test_y)
return (accuracy,)由于遗传算法在python中已被封装成高级API,可以通过直接调用deap包来实现相关优化功能。
# 遗传算法设置
creator.create("FitnessMax", base.Fitness, weights=(1.0,))
creator.create("Individual", list, fitness=creator.FitnessMax)
toolbox = base.Toolbox()
toolbox.register("attr_float", np.random.uniform, 0, 1)
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attr_float, n=10) # 10个分类器
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
# 交叉
def cxBlend_with_bounds(ind1, ind2, alpha=0.5, low=0.0, high=1.0):
tools.cxBlend(ind1, ind2, alpha)
# 确保交叉后的基因值在 [low, high] 范围内
for i in range(len(ind1)):
ind1[i] = max(low, min(high, ind1[i]))
ind2[i] = max(low, min(high, ind2[i]))
return ind1, ind2
toolbox.register("mate", cxBlend_with_bounds)
# 变异
def mutate_with_bounds(individual, mu=0, sigma=0.1, indpb=0.2, low=0.0, high=1.0):
for i in range(len(individual)):
if np.random.random() < indpb:
individual[i] += np.random.normal(mu, sigma)
individual[i] = max(low, min(high, individual[i]))
return individual,
toolbox.register("mutate", mutate_with_bounds)
# 选择
toolbox.register("select", tools.selTournament, tournsize=3)
toolbox.register("evaluate", evaluate)
# 初始化种群
population = toolbox.population(n=50)
# 遗传算法的运行
algorithms.eaSimple(population, toolbox, cxpb=0.7, mutpb=0.2, ngen=50, verbose=False)
# 输出最优解
best_individual = tools.selBest(population, 1)[0]
print("Best individual is: ", best_individual)
print("Best fitness is: ", best_individual.fitness.values[0])绘制准确率对比图
plot_acc(acc_list, best_individual.fitness.values[0])

















 2284
2284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











