






一、监督学习
1、监督学习与非监督学习
(1)、非监督学习:如果数据集中样本点只包含了模型 的输入𝒙,那么就需要采用非监督 学习的算法。
(2)、监督学习:如果这些样本点以〈𝒙,𝒚〉这样的输入-输 出二元组的形式出现(有数据标签), 那么就可以采用监督学习的算法。包含回归和分类,回归问题的输出是连续值,分类问题的输出是离散值。
2、监督学习——回归
3.监督学习——分类
(1)、想要预测(检测)的目标是猫,那么在数据集中猫为正样本 ( Positive ) , 其 他 狗 、 兔 子 、 狮 子 这 些 数 据 为 负 样 本 (Negative )。 将这只猫预测(分类)为狗、兔子、其他预测结果为错(False); 将这只猫预测为猫,预测结果为对(True)。
(2)、将正样本预测正样本 (True Positive, TP) 将负类样本预测为正样 本(False Positive, FP) 将正样本预测为负样本(False Negative, FN) 将负类样本预测为负样 本(True Negative, TN)。
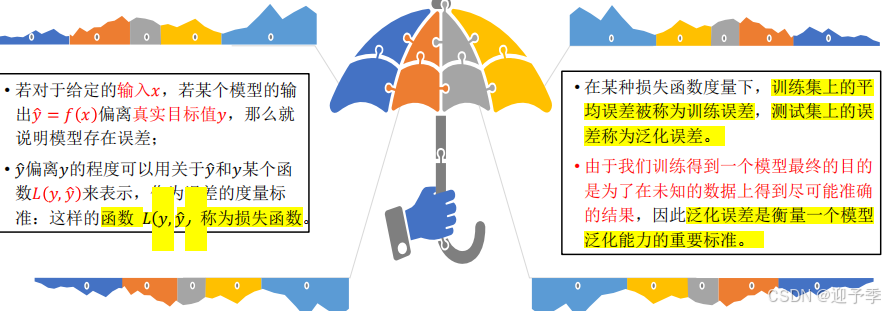
(3)、准确率(Accuracy):对于测试集中D个样本,有k个被正 确分类,D-k个被错误分类,则准确率为: 𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = 分类正确的样本 \样本总数 = 𝑘 \𝐷 = (𝑇𝑃+𝑇𝑁)\ (𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁)
(4)、精确率(查准率)- Precision:所有被预测为正样本中实际为 正样本的概率 ◦ 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 预测为正样本实际也为正样本\ 预测为正样本 = 𝑇𝑃 \(𝑇𝑃 +𝐹𝑃)
(5)、召回率(查全率)- Recall:实际为正样本中被预测为正样 本的概率 ◦ 𝑅𝑒𝑐𝑎𝑙𝑙 = 预测为正样本实际也为正样本 实际为正样本 = 𝑇𝑃\( 𝑇𝑃 +𝐹N)
(6)、把精确率(Precision)和召回率(Recall)之 间的关系用图来表达,就是下PR曲线



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









