








1688是中国的一个大型B2B电子商务平台,主要用于批发和采购各种商品。对于需要从1688上获取商品详情数据、工程数据或店铺数据的用户来说,可以采用以下几种常见的方法:
- 官方API接口:如果1688提供了官方的API接口,那么可以通过编写代码来调用这些接口,从而获取所需的数据。使用API的好处是数据格式通常比较规范,且获取速度较快。
- 网页爬虫:如果1688没有提供官方API,或者API不能满足所有需求,那么可以考虑使用网页爬虫来抓取数据。爬虫可以根据设定的规则自动访问网页、解析网页内容,并提取出所需的数据。但需要注意的是,爬虫可能会受到网站反爬虫机制的限制,且抓取速度可能较慢。
- 第三方数据服务商:市面上有一些第三方数据服务商提供了1688等电商平台的数据采集服务。这些服务商通常会使用自己的技术手段来获取数据,并将数据整理成易于使用的格式。使用第三方数据服务商的好处是无需自己编写代码或设置爬虫,但可能需要支付一定的费用。
最后,无论是使用API、爬虫还是第三方数据服务商,都需要对采集到的数据进行适当的处理和清洗,以确保数据的质量和可用性。
请求示例,API接口接入Anzexi58
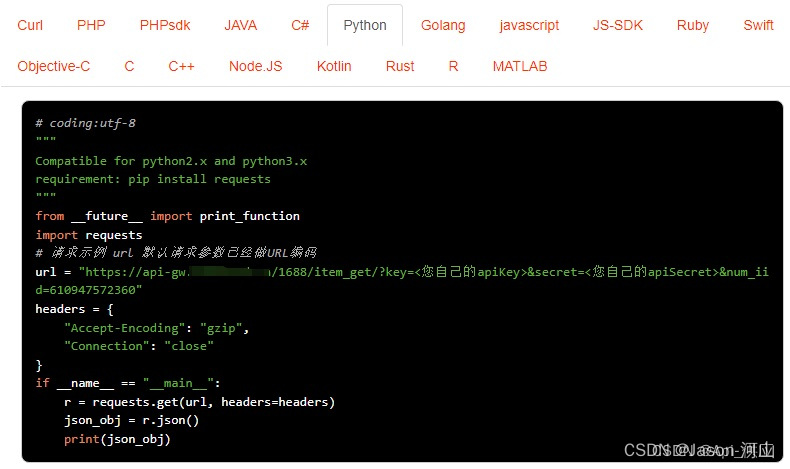
请求参数
请求参数:num_iid=610947572360
参数说明:num_iid:1688商品ID
sales_data:&sales_data=1 获取近30天成交数据
agent:&agent=1 获取1688分销代发价格数据
响应示例



















 392
392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











