






一、Transformer
引言
在transformer模型提出之前,大部分序列转换模型都采用编码器-解码器的架构,其中性能较好的模型会用到注意力机制。而transformer仅仅用到注意力机制没有用到循环(RNN)和卷积(CNN)神经网络。
创新机制
RNN的特点:RNN会从左到右依次去编译序列,并对第t个词输出隐藏状态(ht),ht由当前词t及前一个词t-1决定。RNN通过ht将之前信息放在当下进行比较并输出。因此RNN有无法并行和当序列很长时ht丢失信息或占用很大内存的问题。
CNN的特点:对于很长的序列难以建模,但是有多通道输出的机制,transformer也想通过注意力实现多通道输出,于是开发出了muilt-headed self-attention(多头的注意力机制)
所以Transformer只使用注意力机制,将所有的循环程都替换成了muilt-headed self-attention
模型架构
编码器-解码器架构:编码器是将序列转换成机器学习能够理解的的向量,解码器会根据编码器的输出生成一个新的序列。它会将过去时刻的输出作为当前时刻的输入,该方法称作自回归。
编码器:用6个完全一样的层堆叠而成,每个层里有两个子层:多头的注意力机制(muilt-headed self-attention)和前馈神经网络(MLP),每个子层之间通过残差连接,最后对残差连接进行归一化。
解码器:用6个完全一样的层堆叠而成,每个层里有三个子层:多头注意力机制,前馈神经网络和带掩码的多头注意力机制,每个子层之间通过残差连接。带掩码的多头注意力机制用来防止解码器在训练时偷看未来信息,保证训练和预测时的行为是一致的。
关键技术
自注意力机制:通过计算查询(Query)、键(Key)和值(Value)的加权和,模型能够动态捕捉序列中任意位置的关系。
权重计算公式: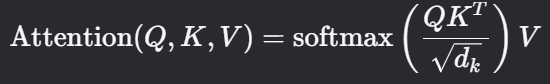
多头注意力:将注意力机制并行化,允许模型在不同子空间中学习多样化的依赖关系。
位置编码:通过正弦函数引入序列位置信息,弥补了自注意力机制对顺序不敏感的缺陷。
二、BERT:
引言
BERT是一个深的双向的Transformer是用来做预训练的。NLP在NERT之前一直没有一个固定的神经网络使得训练好之后能够帮助更多的NLP任务,因此每个人都需要构建自己的神经网络并训练。BERT提供了一个更深的神经网络,能够适用于更多的NLP任务,简化了NLP任务并提高了性能。
核心训练
BERT用来减轻语言模型是单向的这个限制,它用到的是带掩码的语言模型(masked language model)。
- 掩码语言模型(MLM):随机选一些字元将输入词盖住,让目标函数根据左右内容去预测内容。
- 下一个句子预测(NSP):判断两个句子是否连续,以学习句子间关系。
贡献
- 展示了双向信息的重要性,不是简单的将从左到右的语言模型与从右到左的语言模型进行合并,BERT在双向信息的应用上要更好一点。
- BERT是第一个基于微调的模型,在一系列的NLP任务上(包括句子层面和字元层面的任务上都取得了最好的成绩)
三、BioBERT
引言
随着生物医学文献数量的快速增长,生物医学文本挖掘的重要性日益凸显。然而,直接将自然语言处理(NLP)的最新进展应用于生物医学领域往往效果不佳,主要原因是通用领域语料库与生物医学语料库之间存在词汇分布差异。为此,提出了BioBERT(Bidirectional Encoder Representations from Transformers for Biomedical Text Mining),这是一种针对生物医学领域预训练的语言表示模型。
模型架构
BioBERT基于BERT架构,采用双向Transformer编码器。采用BERT的训练任务:(1)掩码语言模型(MLM):随机遮盖输入文本中的部分单词(如 15%),让模型预测被遮盖的词。(2)下一个句子预测(NSP):判断两个句子是否连续,增强模型对篇章级语义的理解。(3) 领域适应预训练:使用通用 BERT(基于 Wikipedia + BooksCorpus)的权重。在 PubMed 摘要(4.5B 词)和 PMC 全文(13.5B 词)上继续训练,使模型适应生物医学语言模式。
微调任务
BioBERT 的微调任务主要包括生物医学命名实体识别(NER)、关系抽取(RE)和问答(QA)三大核心任务,通过简单的架构调整即可实现高效迁移:在 NER 任务中,模型通过附加的 CRF 或线性层直接预测文本中的基因、疾病等实体边界,实体级 F1 值平均提升 0.62%;在 RE 任务中,采用 [CLS] 标记分类和实体匿名化策略,精准识别基因-疾病等关联关系,F1 值提升 2.80%;而在 QA 任务中,基于 SQuAD 的指针网络结构从生物医学文献中定位答案,MRR 指标显著提高 12.24%。这种"预训练-微调"范式仅需单任务输出层适配,即能在多项生物医学文本挖掘任务中实现最先进性能。
结论
BioBERT是首个针对生物医学文本挖掘的预训练语言表示模型,通过领域适应预训练显著提升了性能。
四、总结
BERT和BioBERT分别在通用NLP任务和生物医学文本挖掘领域取得了显著成果。BERT证明了双向预训练和大规模预训练数据的有效性,BioBERT则展示了领域特定预训练模型在专业文本处理中的优势。未来,基于Transformer的模型有望在更多领域得到应用和扩展,通过改进预训练任务、优化模型架构和利用更多数据,进一步提升性能和泛化能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









