






DStream输出操作
1.
2.以saveAsTextFiles算子为例,将词频统计结果保存到文本文件中
首先创建streaming文件(mkdir streaming)

3.将以下代码输入并保存:
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# 初始化SparkContext和StreamingContext
sc = SparkContext('local[2]', 'NetworkWordCountSave')
sc.setLogLevel("WARN")
ssc = StreamingContext(sc, 2) # 批处理间隔2秒
# 从socket数据流创建DStream,并进行词频统计
linesRdd = ssc.socketTextStream('localhost', 9999) \
.filter(lambda x: x.strip() != "") # 添加非空检查
wordCounts = linesRdd \
.flatMap(lambda line: line.split(" ")) \
.filter(lambda word: word != "") \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
wordCounts.pprint()
# 词频统计结果保存到文件系统
wordCounts.saveAsTextFiles("file:///home/spark/streaming/output")
# 启动流计算
ssc.start()
ssc.awaitTermination()
4.保存以上代码并退出编辑器,确保nc服务端在监听9999端口,然后在Linux终端窗体中通过spark-submit命令将NetworkWordCountSave.py程序提交到Spark运行,然后在nc服务端输入文字内容(打开两个终端窗口,在上面窗口中输入)
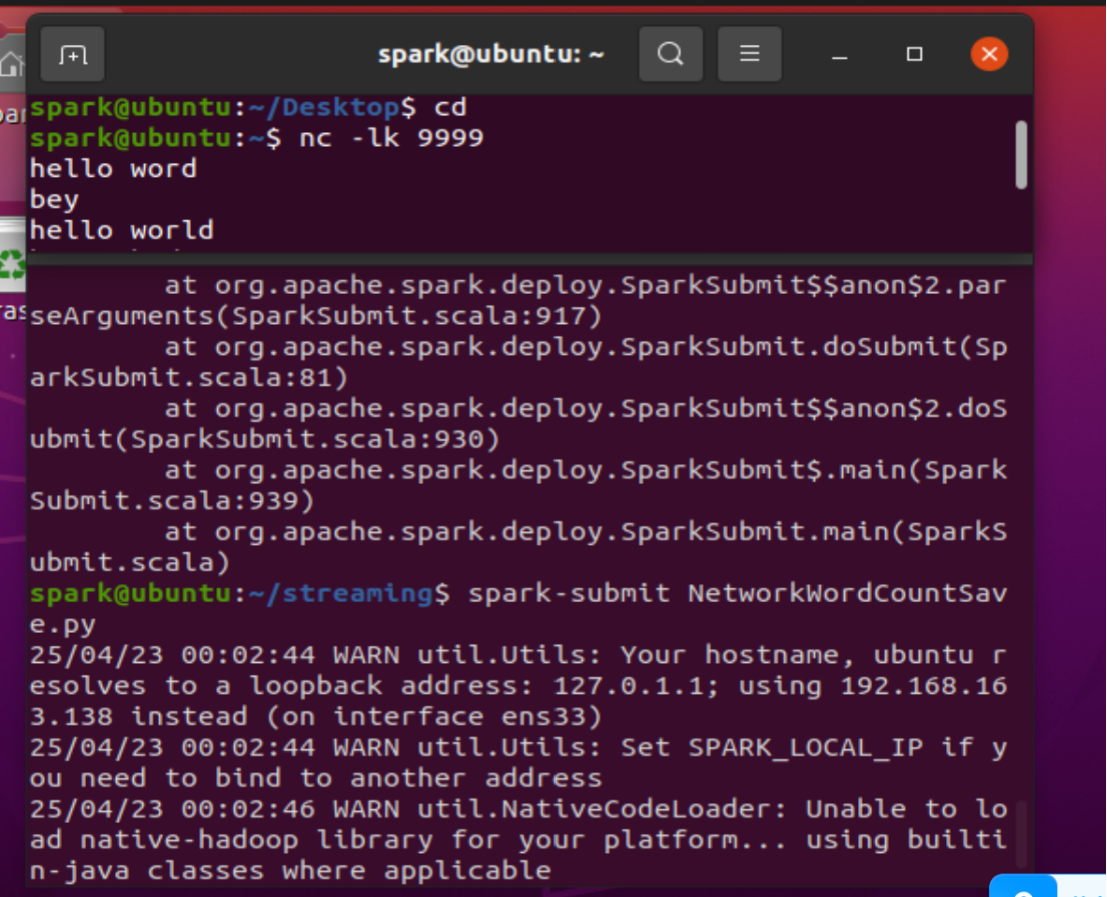
结果如图所示
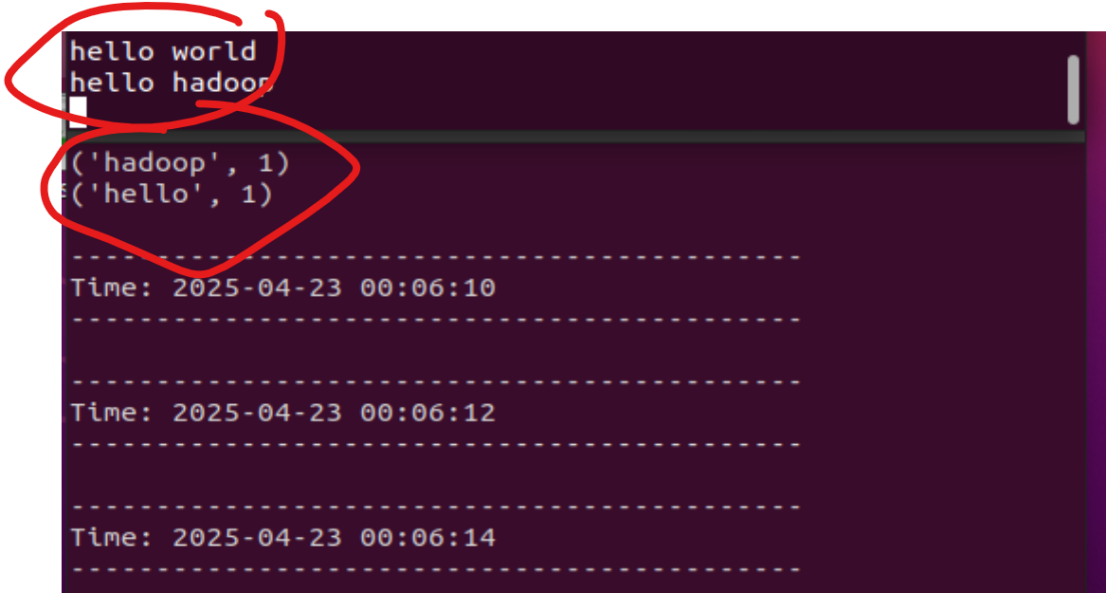
5.Ctrl+C退出进程(对下面的窗口)
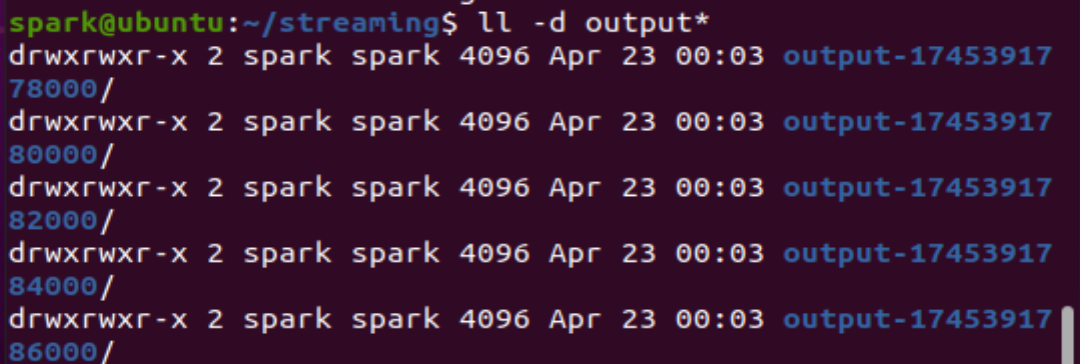
6.查看主目录中的streaming文件夹,里面出现了很多以output-开关的子目录,其中保存的就是不同批次时间点的数据文件


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









