






引入
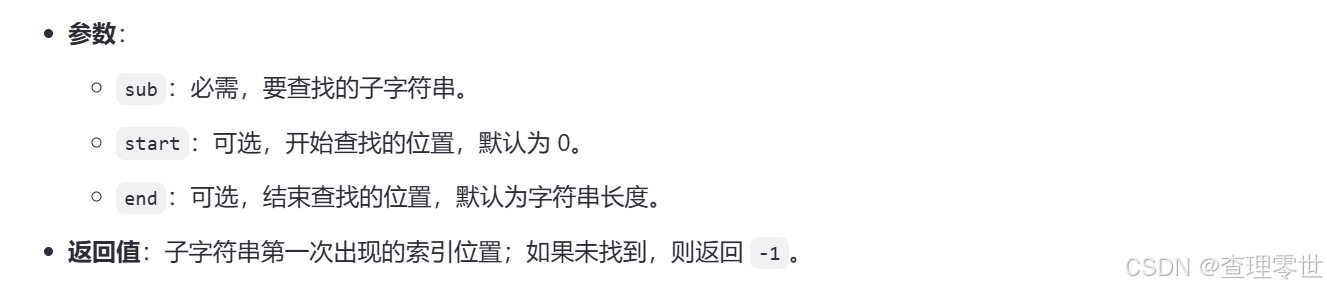
在 Python 中,find() 方法主要用于字符串操作,用于查找子字符串在字符串中的位置。它返回的是子字符串第一次出现的索引位置,如果找不到则返回 -1。
需要注意的是,find() 是字符串的方法,而不是列表或数组的方法。
那数组怎么办?当然是今天要介绍的enumerate()方法了
帮不了解find()方法的小伙伴们学习一下
find( )基本用法
代码如下(示例):
string = "hello world"
index = string.find("o") # 找单个字符
print(index) # 输出: 4
index = string.find("world") # 找一段子串
print(index) # 输出: 6
代码如下(示例):
text = "Python is awesome!"
print(text.find("is")) # 输出: 7
print(text.find("Python")) # 输出: 0
print(text.find("not")) # 输出: -1
print(text.find("a", 5, 12)) # 输出: 8
进入正题
对于列表或数组,没有直接的 find() 方法。
如果你想要查找列表中某个元素的位置,可以使用以下几种方法:
1.使用 index() 方法(只返回第一个匹配项的索引):
list = [1, 2, 3, 2, 4]
index = list.index(2) # 返回第一个 2 的索引,即 1
print(index)
这不行啊 只能找第一个······
别急,大的要来了
2.使用列表推导式(可以找到所有匹配项的索引):
arr = [1, 2, 3, 2, 4]
index_list = [i for i, x in enumerate(arr) if x == 2] # 返回 [1, 3]
print(index_list)
来了,来了,enumerate()
上面代码如果暂时看不懂没关系,听我娓娓道来
enumerate(iterable, start=0)

enumerate() 基本用法
使用 enumerate() 遍历列表并打印索引和值
fruits = ['apple', 'banana', 'cherry']
for index, fruit in enumerate(fruits):
print(f"{index}: {fruit}")
# 0: apple
# 1: banana
# 2: cherry
可以使用自定义起始索引
fruits = ['apple', 'banana', 'cherry']
for index, fruit in enumerate(fruits, start=1):
print(f"{index}: {fruit}")
# 1: apple
# 2: banana
# 3: cherry
enumerate() 是 Python 内置函数,返回一个枚举对象,该对象是一个迭代器,每次迭代产生一个包含索引和对应值的元组 (index, value)。
当然了enumerate()同样可以应用于字符串
# 应用于字符串
s = "Hello World"
for i, c in enumerate(s):
print(f"Character at index {i} is '{c}'")
'''
Character at index 0 is 'H'
Character at index 1 is 'e'
Character at index 2 is 'l'
Character at index 3 is 'l'
Character at index 4 is 'o'
Character at index 5 is ' '
Character at index 6 is 'W'
Character at index 7 is 'o'
Character at index 8 is 'r'
Character at index 9 is 'l'
Character at index 10 is 'd'
'''
好了,实际运用的时候到了
回到引入的问题上来:
结合 enumerate() 和列表推导式,查找列表中某元素的下标
def find_occurrence(list, target):
index_list = [i for i, x in enumerate(list) if x == target]
return index_list
arr = list(map(int, input().split()))
target = int(input())
ans = find_occurrence(arr, target)
print(" ".join(map(str, ans)))
实战演练
统计长度为3的回文子序列的个数
(回文序列是指一个字符串,其正读和反读都一样。如“aba”
对于字符串"aaa",它的子序列有"a1",“a2”,“a3”,“a1a2”,“a1a3”,“a2a3”,“a1a2a3”,“ ” )
input:
第一行包含一个整数n代表字符串的长度(1<=n<=1e5)。
第二场包含一个长度为n的字符串 。
output:
输出该字符串长度为3的回文子序列的个数。
样例输入1
4
AAAA
样例输出:
4
样例输入2
4
ABAA
样例输出:
3
附上题解code:
n = int(input())
s = input().split()
ans = 0
for i in range(2, n):
index_list = [idx for idx, x in enumerate(s[:i]) if x == s[i]]
for index in index_list:
ans += i - index - 1
print(ans)
总结
enumerate() 是一个非常有用的内置函数,能够简化代码逻辑,特别是在需要同时访问元素及其索引的情况下。
它不仅限于列表,还可以应用于任何可迭代对象,并且可以通过设置 start 参数来自定义索引的起始值。
如果有更多问题或需要进一步的帮助,可以在评论区留言讨论哦!
如果喜欢的话,请给博主点个关注 谢谢

















 2371
2371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









