






print(soup) # 查看

prettify() 方法 格式化输出:
print(soup.prettify()) # 代码的格式化

获取指定标签(只获取第一个匹配的)
print(soup.title)
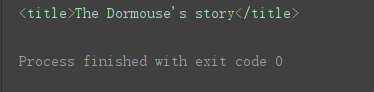
获取指定标签的标签名
print(soup.title.name)
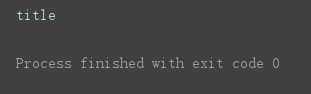
获取指定标签的文本字符串
print(soup.title.string)
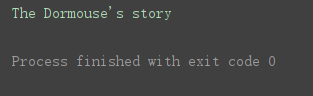
使用**find()**方法,获取指定标签(只获取第一个与之匹配的)
print(soup.find(‘p’))

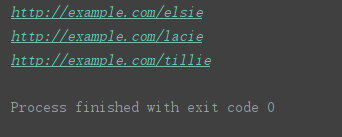
使用 find_all() 方法,获取全部与之匹配的标签,结果放在一个列表中
print(soup.find_all(‘a’))

找多个标签,给find_all()传入一个标签列表
print(soup.find_all([‘a’, ‘p’]))

get() 方法 获取标签的属性
links = soup.find_all(‘a’) # 'a’通过字符串传递字符串过滤器
for link in links:
print(link.get(‘href’))
attrs 属性 获取标签的全部属性
links = soup.find_all(‘a’)
a = links[0]
print(a.attrs)

============================================================================
soup = BeautifulSoup(html_doc, ‘lxml’)
print(type(soup.title))
print(type(soup.p))
print(type(soup.a))
print(type(soup.find(‘a’)))
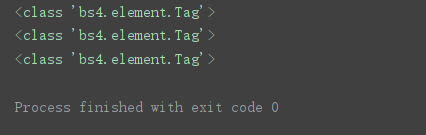
得到的都是Tag标签类型,不是字符串。
title_head = soup.head
print(type(title_head.string))
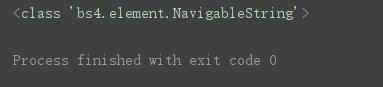
可导航的字符串(可操纵的字符串)
print(type(soup)) # bs对象
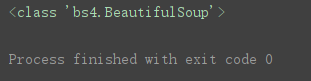
bs对象。
此外,还有注释类型,指的是html文件的注释标签部分,形如
<!–xxxxxxxxx–>
这里不再具体展示,了解即可。
=============================================================================
● string获取标签里面的内容
● strings 返回是一个生成器对象用过来获取多个标签内容
● stripped_strings 和strings基本一致 但是它可以把多余的空格去掉
title_tag = soup.title
print(title_tag.string)
head_tag = soup.head
print(title_tag.string)
html_tag = soup.html
print(html_tag.string)
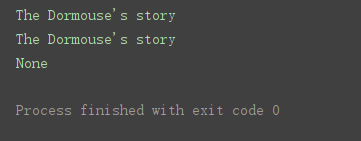
如图,使用同级标签,可以找到同级数据,使用上级标签也可以,使用再上一级标签,因为这里边可以匹配的字符串有多个,所以不能再匹配到数据。
这个时候可以将string属性换为strings属性再尝试:
texts = soup.html.strings
print(texts)

如图输出结果是一个生成器。可遍历。
for i in texts:
print(i)

但是如图,其中空行较多,不美观。于是可以切换使用stripped_strings属性,stripped_strings 和strings基本一致 但是它可以把多余的空格去掉。















 653
653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









