






因为使用了持久化保存,所以生成浏览器状态的代码和获取浏览器状态的代码可以分离开,进行独立维护。
举例来说,大多数的网站操作都需要登录状态。我们可以先独立编写登录的代码,然后把登录的浏览器状态存储起来, 之后我们每次想进行该网站的操作,可以直接把浏览器 session 取出来,直接操作,节省了每次都要重新登录的流程。
代码的逻辑非常简单,主要分为几个步骤:
·登录
· 存储状态
· 获取状态
· 重复使用
登录
登录的代码,几乎是每个会 selenium 的小伙伴闭着眼睛都能写出来的。需要注意的是最后 3 行,登录动作完成后,获取 selenium 会话的远程服务地址和 session id。
以后测试脚本就靠连接这一次的远程服务地址,通过 session id 得到此次的浏览器对象。 注意,一定不要使用 driver.quit() 退出,否则就不能重复使用了。

持久化存储
得到服务地址 remote_executor 和 session id 之后,我们要通过持久化的方式把这两个数据保存起来。
可以用数据库,可以用 json 文件,可以用 yaml 文件,也可以是其他普通格式的文本,但一定是要可持久化的。
在这里我们使用 yaml 文件保存。
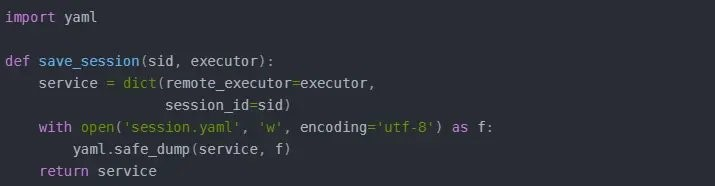
现在,通过 login 函数,我们可以登录,然后通过 save_session 函数保存登录后的浏览器状态。如果代码能正常执行,现在你能在项目中看到一个 session.yaml 的文件。
remote_executor, session_id = login()
save_session(remote_executor, session_id)
获取持久化的 session
接下来,我们要考虑:其他的测试脚本如果想要使用这个 selenium 的 session 对象,首先要从 yaml 文件中读取 session id 和 远程服务地址,然后重新初始化一个 selenium 的浏览器对象,连接地址,并把 session id 设置成读取出来的 id。
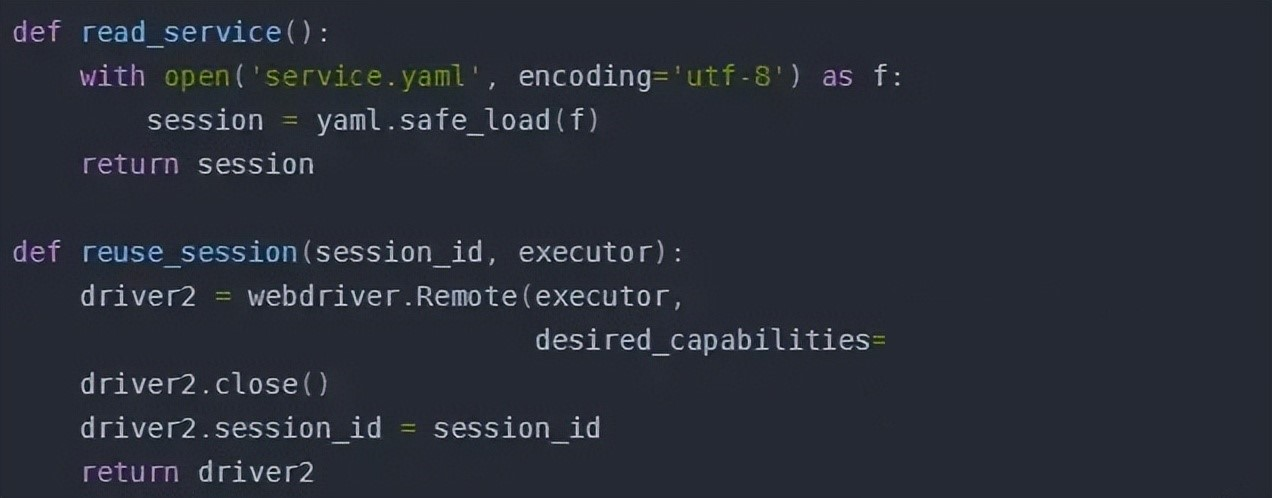
重复使用 session
在具体使用过程中,首先通过 read_service 读取出服务地址和 session id, 再通过 reuse_session 函数重新连接之前的 session。
session_config = read_service()
session_id = session_config[‘session_id’]
executor = session_config[‘remote_executor’]
driver = reuse_session(session_id, executor)
只要 session 没有退出,在任何时候都可以通过上面的代码连接,获取浏览器。后面的操作就和普通的 selenium 没有任何区别了。
# script1
driver.get('
https://petstore.octoperf.com/actions/Catalog.action')
# 不需要登录了
driver.find_element('link text', 'My Account').click()
# script2
driver.get('
https://petstore.octoperf.com/actions/Catalog.action')
# 不需要登录了
driver.find_element('xpath', "//area[@alt='Fish']").click()















 4037
4037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









