







GLake:突破GPU内存和IO瓶颈的利器
在人工智能快速发展的今天,大模型训练和推理正面临着严峻的挑战。随着模型规模的不断扩大,GPU内存容量和IO带宽的增长速度已经远远跟不上AI模型规模的增长速度,形成了所谓的"内存墙"和"IO传输墙"。为了应对这些挑战,一个名为GLake的开源项目应运而生,旨在通过底层优化来突破GPU内存和IO传输的瓶颈。
GLake简介
GLake是一个专注于优化GPU内存管理和IO传输的加速库及相关工具集。它主要在两个层面上进行工作:
- 底层:优化GPU虚拟和物理内存管理
- 系统层:优化多GPU、多路径和多任务场景
通过这些优化,GLake能够显著提升AI训练、推理以及开发运维(如Notebook)等场景下的硬件资源利用率。根据项目介绍,GLake可以:
- 将训练吞吐量提高至原来的4倍
- 节省推理内存高达3倍
- 加速IO传输3~12倍
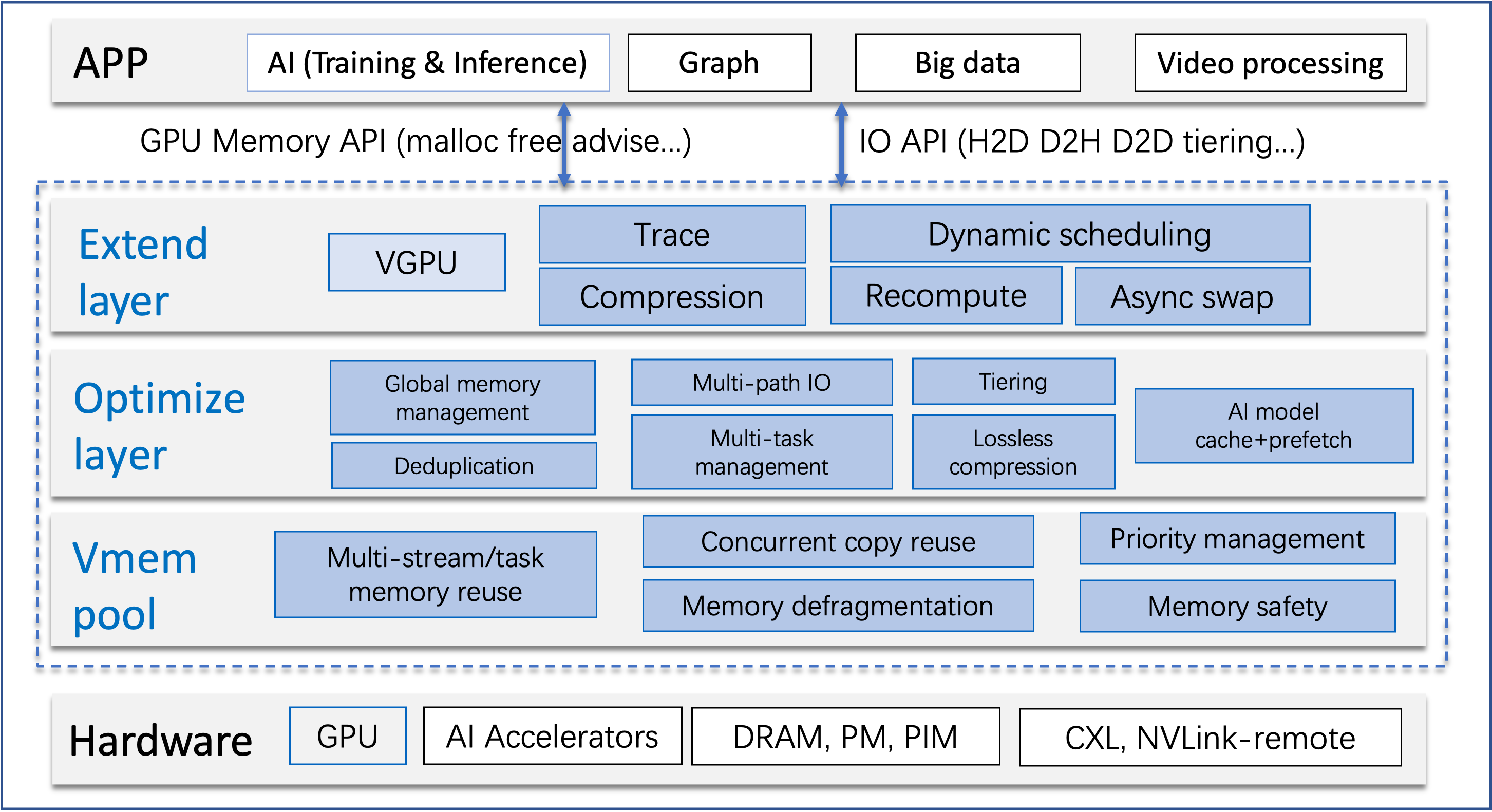
GLake的核心特性
-
高效性:GLake采用内部两层GPU内存管理和全局(多GPU、多任务)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









