






机器学习(Machine Learning)
简要声明
基于吴恩达教授(Andrew Ng)课程视频
BiliBili课程资源
正则化的应用
一、带正则化的代价函数
在带正则化的代价函数中,我们在原始代价函数的基础上添加了一个正则化项。对于线性回归模型,其带正则化的代价函数形式如下:
J ( w , b ) = 1 2 m ∑ i = 1 m ( f w , b ( x ( i ) ) − y ( i ) ) 2 + λ 2 m ∑ j = 1 n w j 2 J(\mathbf{w}, b) = \frac{1}{2m} \sum_{i=1}^{m} \left( f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)} \right)^2 + \frac{\lambda}{2m} \sum_{j=1}^{n} w_j^2 J(w,b)=2m1i=1∑m(fw,b(x(i))−y(i))2+2mλj=1∑nwj2
其中:
- m m m是训练样本的数量
- n n n 是特征的数量
- λ \lambda λ 是正则化参数,用于控制正则化的强度
正则化项 λ 2 m ∑ j = 1 n w j 2 \frac{\lambda}{2m} \sum_{j=1}^{n} w_j^2 2mλ∑j=1nwj2 会惩罚过大的参数值,使模型更倾向于学习较小的参数,从而降低模型的复杂度。
二、正则化线性回归
在正则化线性回归中,我们通过梯度下降算法来最小化带正则化的代价函数。其梯度下降的更新规则如下:
w j = w j − α [ 1 m ∑ i = 1 m ( f w , b ( x ( i ) ) − y ( i ) ) x j ( i ) + λ m w j ] w_j = w_j - \alpha \left[ \frac{1}{m} \sum_{i=1}^{m} \left( f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)} \right) x_j^{(i)} + \frac{\lambda}{m} w_j \right] wj=wj−α[m1i=1∑m(fw,b(x(i))−y(i))xj(i)+mλwj]
b = b − α 1 m ∑ i = 1 m ( f w , b ( x ( i ) ) − y ( i ) ) b = b - \alpha \frac{1}{m} \sum_{i=1}^{m} \left( f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)} \right) b=b−αm1i=1∑m(fw,b(x(i))−y(i))
其中:
- α \alpha α是学习率
- w j w_j wj 是特征 ( j ) 的参数
- b b b是偏置项
在梯度下降过程中,正则化项会使得参数 w j w_j wj在每次更新时都乘以一个因子 ( 1 − α λ m ) (1 - \alpha \frac{\lambda}{m}) (1−αmλ),从而实现参数的“收缩”。
| 正则化线性回归与普通线性回归对比 | 正则化线性回归 | 普通线性回归 |
|---|---|---|
| 更新规则 | 包含正则化项 | 不包含正则化项 |
| 参数变化 | 参数逐渐收缩 | 参数无收缩 |
| 泛化能力 | 更强 | 较弱 |
三、正则化逻辑回归
正则化逻辑回归与正则化线性回归类似,其代价函数也包含一个正则化项。对于逻辑回归模型,其带正则化的代价函数形式如下:
J ( w , b ) = − 1 m ∑ i = 1 m [ y ( i ) log ( f w , b ( x ( i ) ) ) + ( 1 − y ( i ) ) log ( 1 − f w , b ( x ( i ) ) ) ] + λ 2 m ∑ j = 1 n w j 2 J(\mathbf{w}, b) = -\frac{1}{m} \sum_{i=1}^{m} \left[ y^{(i)} \log(f_{\mathbf{w},b}(\mathbf{x}^{(i)})) + (1 - y^{(i)}) \log(1 - f_{\mathbf{w},b}(\mathbf{x}^{(i)})) \right] + \frac{\lambda}{2m} \sum_{j=1}^{n} w_j^2 J(w,b)=−m1i=1∑m[y(i)log(fw,b(x(i)))+(1−y(i))log(1−fw,b(x(i)))]+2mλj=1∑nwj2
其中:
- ( f w , b ( x ( i ) ) ) ( f_{\mathbf{w},b}(\mathbf{x}^{(i)}) ) (fw,b(x(i))) 是逻辑回归模型的预测输出,使用Sigmoid函数计算得到
正则化逻辑回归的梯度下降更新规则与正则化线性回归类似,也是在原始梯度的基础上添加了正则化项。
四、正则化参数的选择
正则化参数 λ \lambda λ 的选择对模型的性能有重要影响:
- λ \lambda λ 过小:正则化效果不明显,模型可能仍然过拟合
- λ \lambda λ 过大:过度正则化,模型可能欠拟合
可以通过交叉验证的方法来选择合适的 λ \lambda λ 值。
五、正则化方法对比
| 正则化方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| L1正则化 | 特征稀疏 | 可进行特征选择 | 收敛速度较慢 |
| L2正则化 | 参数平滑 | 收敛速度快 | 无法进行特征选择 |
通过合理应用正则化技术,可以有效防止模型过拟合,提高模型的泛化能力和实际应用效果。
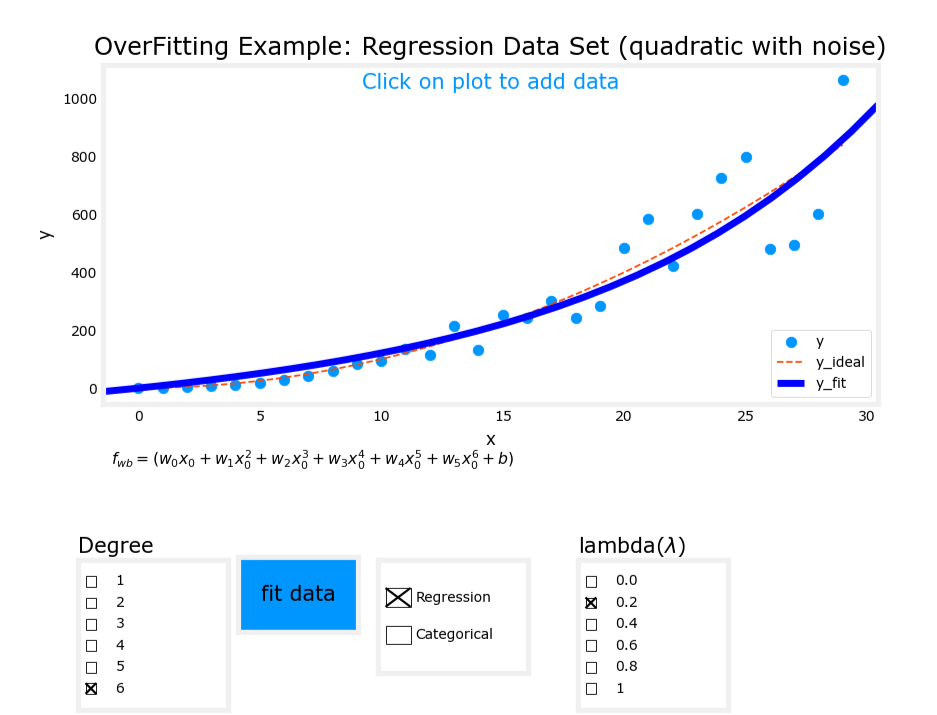
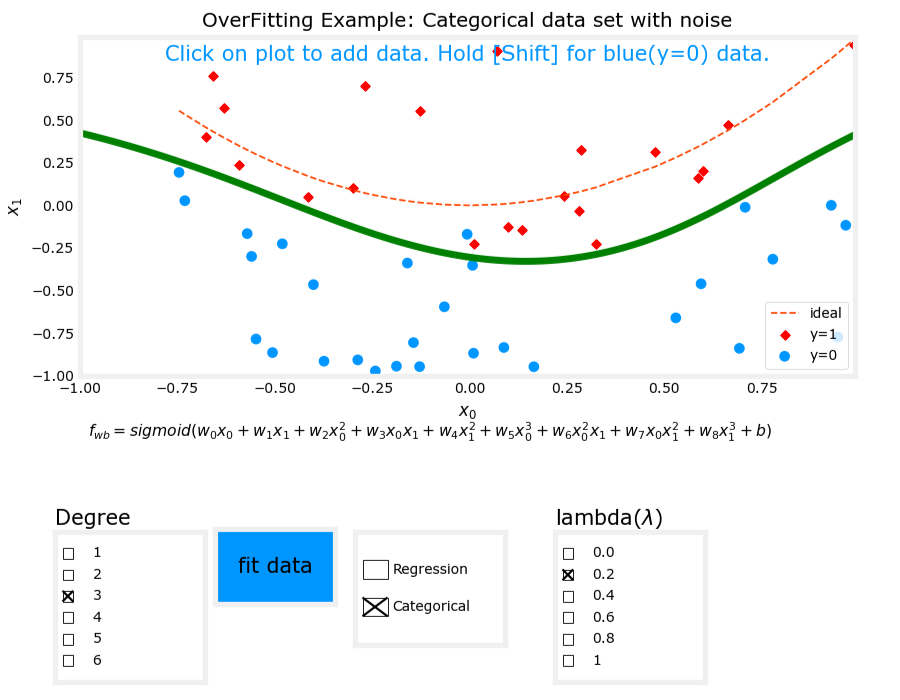
正则化后图像
线性回归
分类
end


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









