






程序名称:基于线性-非线性分解的弹性网络回归(ElasticNet)和随机森林时间序列预测
实现平台:python—Jupyter Notebook
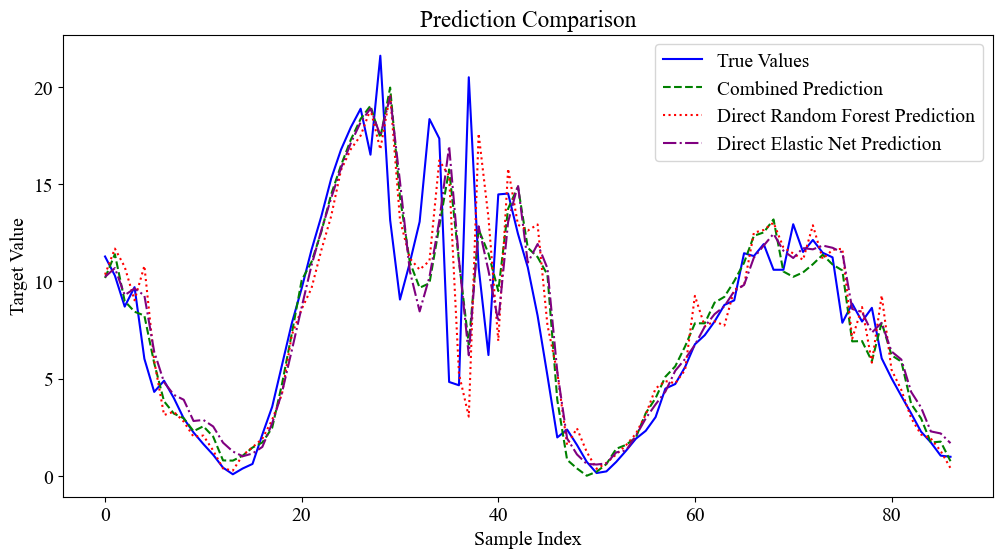
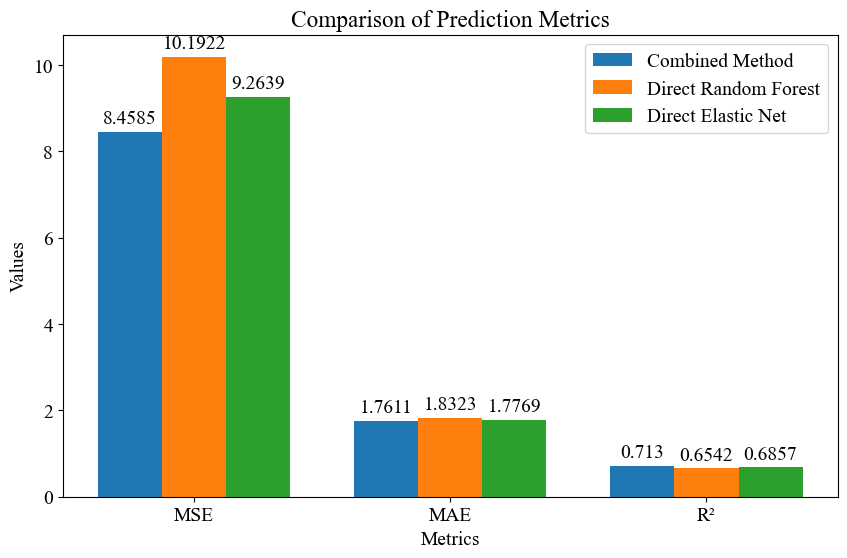
代码简介:构建了基于基于线性-非线性分解的弹性网络回归(ElasticNet)和随机森林时间序列预测模型。该模型为线性-非线性时间序列分解模型(LN-TSDM)。通过将时间序列数据分解为线性部分和非线性部分,分别采用弹性网络回归(ElasticNet)和随机森林算法进行建模与预测。线性部分利用弹性网络回归捕捉数据中的线性趋势,而非线性部分则通过随机森林强大的非线性拟合能力处理复杂的非线性关系,使用网格搜索与交叉验证优化随机森林的参数。两种预测结果相加得到最终的组合预测值。此外,模型还与直接使用随机森林和弹性网络回归的方法进行了对比验证。实验结果表明,LN-TSDM在预测精度上具有显著优势,能够有效提升时间序列预测的准确性和稳定性,为相关领域的时间序列预测问题提供了一种高效可靠的解决方案。可用于风光负荷、天气、交通等一切符合模型输入的时间序列预测。
随机森林在时间序列预测中展现了独特的优势。首先,作为一种集成学习方法,它通过构建多个决策树并汇总其结果来提高预测的准确性和稳定性,有效避免了单个模型可能出现的过拟合问题。其次,随机森林能够处理大量特征,并且对数据中的噪声具有较高的鲁棒性,这使得它在面对复杂的时间序列数据时表现尤为出色。此外,由于其非线性的模型结构,随机森林可以捕捉到数据中的复杂模式和非线性关系,非常适合用于含有不规则波动的时间序列分析。最后,随机森林不需要对数据进行严格的假设(如线性关系等),这为其应用于不同类型的时间序列提供了更大的灵活性和适应性。
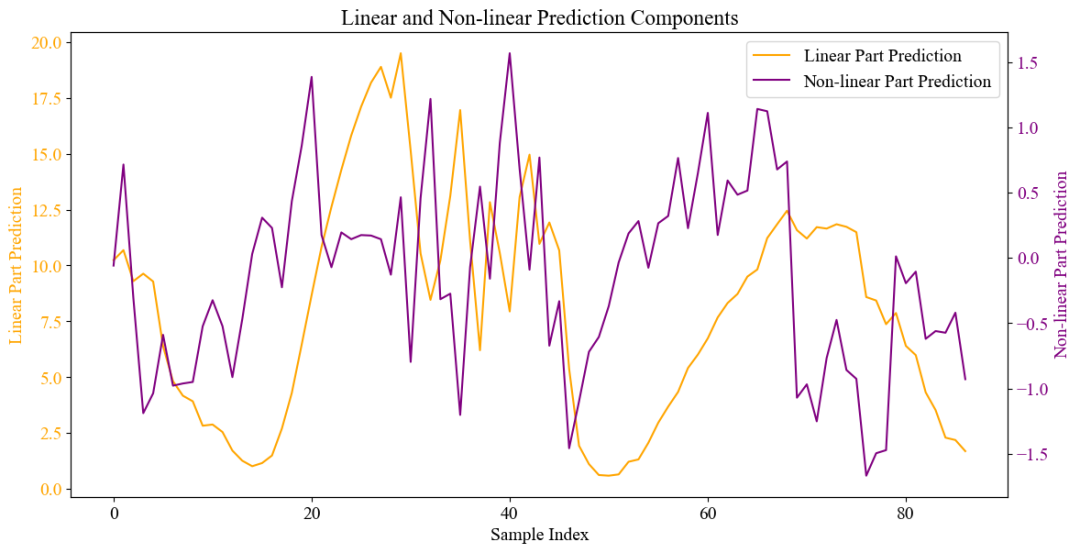
采用将时间序列数据分割成线性与非线性组件分别进行预测的方法,然后合并这两个预测结果以获得最终预测值。这样做可以最大化利用线性和非线性模型的长处。具体来说,线性模型擅长识别数据中的趋势和模式,而非线性模型则在应对复杂关系及波动方面表现出色。通过这种分解和综合的策略,不仅能提升预测准确性,还能提高模型的灵活性和稳定性。这种方法规避了单独使用一种模型时可能遇到的挑战,并且整合了两者的优点,特别适合用于含有显著趋势以及复杂变化的时间序列数据分析,从而达到更加精确和可信的预测效果。
代码获取方式:【原创代码分享】基于线性-非线性分解的弹性网络回归(ElasticNet)和随机森林时间序列预测 (qq.com)
部分代码
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.linear_model import ElasticNet
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import matplotlib.pyplot as plt
# 添加图例
fig.tight_layout()
fig.legend(loc='upper right', bbox_to_anchor=(1, 1), bbox_transform=ax1.transAxes)
plt.title('Linear and Non-linear Prediction Components')
plt.show()
# 可视化预测指标
metrics = ['MSE', 'MAE', 'R²']
combined_metrics = [mse_combined, mae_combined, r2_combined]
direct_rf_metrics = [mse_direct_rf, mae_direct_rf, r2_direct_rf]
direct_elastic_net_metrics = [mse_direct_elastic_net, mae_direct_elastic_net, r2_direct_elastic_net]
x = np.arange(len(metrics)) # 标签位置
width = 0.25 # 条形的宽度
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width, combined_metrics, width, label='Combined Method')
rects2 = ax.bar(x, direct_rf_metrics, width, label='Direct Random Forest')
rects3 = ax.bar(x + width, direct_elastic_net_metrics, width, label='Direct Elastic Net')
# 添加一些文本标签
ax.set_xlabel('Metrics')
ax.set_ylabel('Values')
ax.set_title('Comparison of Prediction Metrics')
ax.set_xticks(x)
ax.set_xticklabels(metrics)
ax.legend()
# 在每个条形上添加数值标签
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate('{}'.format(round(height, 4)),
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom')
autolabel(rects1)
autolabel(rects2)
autolabel(rects3)
plt.show()运行结果
Optimized Random Forest parameters: {'max_depth': 20, 'min_samples_split': 10, 'n_estimators': 100}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









