






目录
本文是对上一篇文章《C++11新特性》的补充,将会介绍过很多的C++11特性。
lambda表达式
定义
C++中可调用对象有三种:函数,仿函数,以及lambda表达式。
函数的类型写起来太繁琐了,所以一般都会使用仿函数来替代函数,但是对于实现简单的函数实现,使用仿函数代码长,比较笨重;因此引出了lambda表达式来解决这一问题。
lambda表达式包含三个部分:1)捕捉列表;2)函数参数;3)函数返回值类型;4)函数体。
struct Add1
{
int operator()(int x, int y)
{
return x + y;
}
};
auto Add2 = [](int x, int y)->int {return x + y ;};
Add1()(1, 1);
Add2(1, 1);以上分别是仿函数和lambda表达式实现加法函数,可以看出lambda表达式的使用更简约。
对于lambda表达式,如果没有参数,参数部分可以省略;返回值类型也可以不写,让编译器自动推导。
auto Add3 = [](int x, int y) {return x + y; };函数指针---在C++中人不用就不用,其类型写起来不太方便;
仿函数---是一个类,重载了operator();
lambda---表达本质上是一个局部匿名函数对象。
lambda表达式的函数体内可以直接调用全局变量,但是不能直接调用局部变量或局部函数。如果需要使用局部对象就要将其添加至捕捉列表中。
void test_02()
{
double rate = 0.5;
auto Add3 = [rate](int x, int y) {return (x + y)*rate; };
}如上图,rate就实现了捕捉,在lambda表达式中可以只用rate。
捕捉的方式
捕捉的方式有四种:
1)[var],对var进行值捕捉;
2)[&var],对var进行引用捕捉,lambda表达式中var的改变会影响其外部的var;
3)[ = ],对局部变量和函数进行全部值捕捉;
4)[ & ],对局部变量和函数进行全部引用捕捉。
当然捕捉列表也可以混合起来使用。
int a = 1, b = 2;
int c = 10;
auto Add4 = [&, c] { a++, b++;
cout << c; };以上就是混合捕捉:对所有局部变量进行引用捕捉,除了c使用值捕捉。
lambda表达式的底层实际上还是仿函数。
lambda表达式在进行值捕捉的时候,默认捕捉后的类型是const修饰的,也就是说进行值捕捉后的参数是不能进行修改的,如果想要修改需要添加mutable关键字。
int a = 1, b = 2;
auto Add4 = [a, b]()mutable { a++, b++;
cout << a << b; };使用mutable后,值捕捉的变量就就可以实现修改了。
可变模板参数
在C语言中就已经有可变参数的概念了,比如printf和scnaf的参数都属于可变参数;C++引入了模板概念,自然也有了可变模板参数概念。
在C++11新增了可变模板参数,使得模板中参数可以不是固定的了,但是可变模板参数使用起来不太方便,此处我们进行简略介绍。
模板的参数是类型,函数的参数是对象,要将这两点分开。
template<class ... Args>
void Show(Args ... args)
{
sizeof...(args);
//....
}模板中的Args指的是模板参数包,函数中的args指的是函数参数包;其中...表示其是可变参数,此处需要注意省略号的位置;通过sizeof...(args)可以打印出参数的个数。
参数包的语法不支持直接使用args[i],所以参数包是不能直接使用的,需要先展开再使用;
递归函数方式展开参数包
通过递归依次减少参数,直到参数为零,其与参数递归类似,只不过递归停止的条件是参数。
template<class T>
void Show(T val)
{
cout << val << endl;
}
template<class T ,class ... Args>
void Show(T val ,Args ... args)
{
cout << val << " ";
Show(args...);
}
void test_03()
{
Show(1);
Show(1,"x");
Show(1, "x", 1.3);
}如图,上面通过两个重载函数来实现参数包的展开,参数大于1会优先匹配void Show(T val ,Args ... args);当参数等于1的时候就去匹配void Show(T val),此时递归结束。
数组展开参数包
template<class T>
int Show(T val)
{
cout << val << " ";
return 0;
}
template<class ... Args>
void Show(Args ... args)
{
int arr[] = { Show(args)... };
cout << endl;
}
void test_03()
{
Show(1);
Show(1,"x");
Show(1, "x", 1.3);
}int arr[] = { Show(args)... };数组元素个数是没有给定的所以需要通过对数组元素进行计数,此时就需要将参数包展开;
移动构造和移动赋值
C++11新增了两个默认成员函数:移动构造和移动赋值。
移动构造和移动赋值都属于移动语义,其是为了解决对于返回值的参数无法直接引用问题。
在无析构函数+无拷贝构造+无赋值重载+无移动构造的情况下,编译器会生成默认移动构造:对于内置类型进行浅拷贝,对于内置类型会去调用其自己的拷贝构造。
移动赋值也同理。
一般要写析构函数的内是深拷贝的类,需要写拷贝构造和赋值重载;
包装器
C++11引入了包装器function,通过包装器可以实现将函数,仿函数以及lambda表达式类型统一。
void Print1()
{
cout << "hello world" << endl;
}
struct Print2
{
void operator()()
{
cout << "hello world" << endl;
}
};
void test_04()
{
auto Print3 = [] {cout << "hello world" << endl; };
cout << typeid(Print1).name() << endl;
cout << typeid(Print2()).name() << endl;
cout << typeid(Print3).name() << endl;
}
以上三个可调用对象实现的功能都是一样的,此处可以使用typeid().name打印出其三个可调用对象的类型。
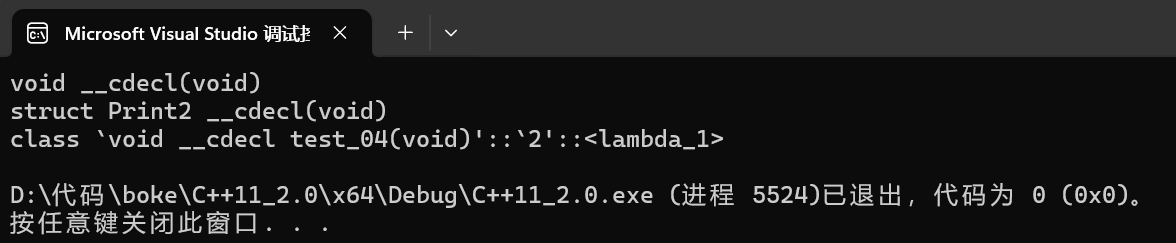
可以看出三者类型是完全不同的,C++11引入了包装器function使得可以通过函数返回值,参数将不同的可调用对象类型统一。
function<void()> arr[] = { Print1,Print2(),Print3 };以上将三个可调用对象都放入到了数组中,其类型都是function<void()>,关于function的使用方法就是:function<函数返回值(函数参数)>,function使用时的头文件是<functional>。
包装器function的本质是一个适配器,可以对函数指针,仿函数以及lambda表达式进行包装。
绑定bind
对于库中的有些接口,参数传递很多并且有些参数是固定的;此时就可以通过bind绑定将接口参数进行绑定。
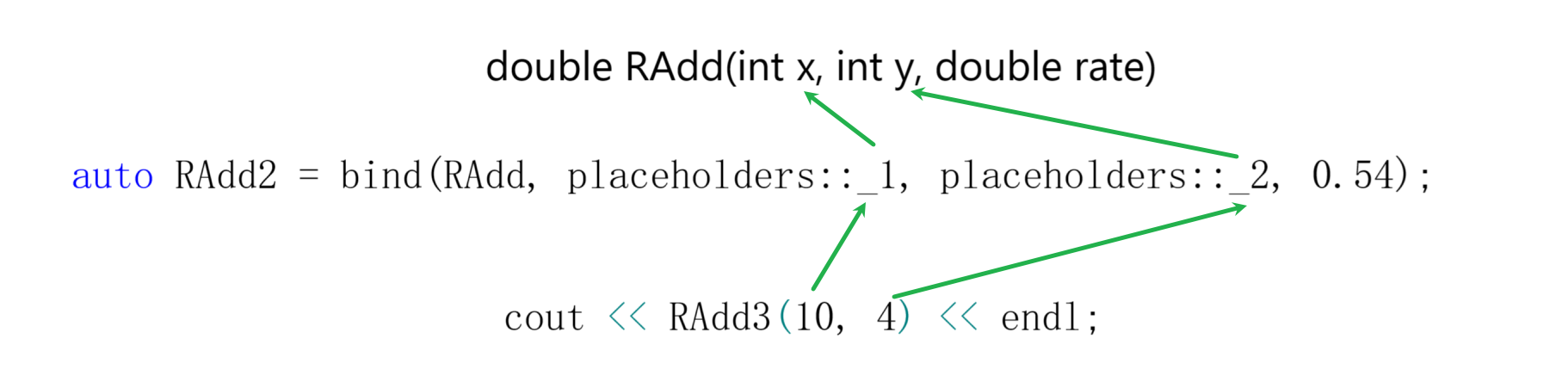
double RAdd(int x, int y, double rate)
{
return (x + y) * rate;
}
void test_05()
{
//如果rate始终是固定的,不需要进行修改次数就可以使用绑定bind
auto RAdd2 = bind(RAdd, placeholders::_1, placeholders::_2, 0.54);
cout << RAdd2(10, 4) << endl;
}bind的参数:可调用对象;参数匹配的位置:10就和_1位置匹配,4就和_2位置匹配,_1和_2有分别和函数参数匹配即x和y;
通过对_1和_2位置的调换,可以出现不同的结果。
如下图所示:通过对_1和_2位置的调换可能会导致函数的调用发生变化。

补充:对于类成员函数的绑定是不同的:对于非静态成员函数要加&,并且要给出对象或对象地址;对于静态成员函数可以不加&,但是建议加上。
class A
{
public:
static int Add1(int x, int y)
{
return x + y;
}
int Add2(int x, int y)
{
return x + y;
}
private:
int _a;
};
void test_05()
{
//非静态成员函数的绑定
auto CAdd1 = bind(&A::Add2, A(), placeholders::_1, placeholders::_2);
A aa;
auto CAdd2 = bind(&A::Add2, &aa, placeholders::_1, placeholders::_2);
//静态成员函数的绑定
auto CAdd3 = bind(&A::Add1, placeholders::_1, placeholders::_2);
}智能指针
C++中对于错误的处理是使用抛异常的方式解决的,抛异常就会导致进程流被修改,当进程流改变后,原本需要释放的内存没有走到delete就会导致内存泄漏。
为了解决这一问题可以采用多次抛异常,在抛异常前进行空间的释放,如果一个函数中有多个位置进行了空间开辟,当抛异常后还需要考虑哪一个需要释放,这就导致了情况多,代码繁琐的问题。
能不能一个空间开辟后,出作用域就销毁呢???此时就可以使用智能指针来实现。
智能指针通过将指针交给对象,让对象进行资源的管理,在对象出作用域时调析构函数进行资源的释放。
template<class T>
class Ptr
{
public:
Ptr(T* ptr)
:_ptr(ptr)
{
}
Ptr(const Ptr& p)
:_ptr(p._ptr)
{
}
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
~Ptr()
{
delete _ptr;
}
private:
T* _ptr;
};以上是对智能指针的简单模拟实现,但是在使用的时候,对指针进行拷贝构造时就会出现对同一块区域的多次释放。在C++中有不同的智能指针,不同的指针处理方式也是不同的。
RAII
资源获取即初始化,利用对象生命周期来控制资源,在构造函数时获取资源,在对象析构时销毁资源。
优势:1)不需要显式释放空间,出作用域自动销毁;
2)对象所需的资源在其生命周期类持续有效;
auto_ptr
auto_ptr是C++98时推出的一个智能指针;auto_ptr对于指针拷贝的方法是:将空间的管理权转移,在完成拷贝构造之后,将被拷贝对象置空。其底层实现如下:
template<class T>
class auto_ptr
{
public:
auto_ptr(T* ptr)
:_ptr(ptr)
{
}
auto_ptr(const auto_ptr& p)
:_ptr(p._ptr)
{
p._ptr = nullptr;
}
auto_ptr operator=(const auto_ptr& p)
{
_ptr = p._ptr;
p._ptr = nullptr;
return *this;
}
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
~auto_ptr()
{
delete _ptr;
}
private:
T* _ptr;
};可以看到,在拷贝完成后,被拷贝对象悬空导致其无法使用,这使得auto_ptr不被广泛使用。
unique_ptr
unique_ptr对于拷贝和赋值的处理方法更加暴力,unique_ptr不支持赋值和拷贝构造。
所以在实现的时候,需要将拷贝和赋值只声明不定义,并且置为私有防止其在外面被定义,为防止编译器自动生成在函数后面加上delete。
template<class T>
class unique_ptr
{
public:
unique_ptr(T* ptr)
:_ptr(ptr)
{
}
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
~unique_ptr()
{
delete _ptr;
}
private:
unique_ptr(const unique_ptr& p) = delete;
unique_ptr operator=(const unique_ptr& p) = delete;
T* _ptr;
};shared_ptr
shared_ptr通过对指向每个空间的指针进行计数来实现对空间的释放,当一个指向一个空间的指针数量为0是对空间进行释放;
所以shared_ptr需要添加一个成员变量来实现计数。
template<class T>
class shared_ptr
{
public:
shared_ptr(T* ptr)
:_ptr(ptr)
,_pcount(new int(1))
{
}
shared_ptr(const shared_ptr& p)
:_ptr(p._ptr)
,_pcount(p._pcount)
{
++(*_pcount);
}
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
shared_ptr operator=(const shared_ptr& p)
{
_ptr = p._ptr;
_pcount = p._pcount;
++(*_pcount);
return *this;
}
~shared_ptr()
{
if (--(*_pcount) == 0)
{
delete _ptr;
}
}
private:
T* _ptr;
int* _pcount;
};shared_ptr确实解决了何时释放的问题,但是又出现了循环引用的问题。
循环引用
当一个对象有前后指针的时候就会出现问题,比如一下代码。
template<class T>
struct Node
{
Node()
:_a(T())
,_next(nullptr)
,_prev(nullptr)
{ }
T _a;
shared_ptr<Node> _next;
shared_ptr<Node> _prev;
};
void test_06()
{
shared_ptr<Node<int>> aa(new Node<int>);
shared_ptr<Node<int>> bb(new Node<int>);
aa->_next = bb;
bb->_prev = aa;
}当aa的后继指针指向bb的时候,bb的引用计数就变成了2,同理aa的引用计数也编程了2。当对aa进行销毁的时候,其引用计数是2无法调用Node的析构,也就不能进行_next和_prev的析构了,此时就出现了空间泄露。
为了解决这一问题添加了weak_ptr。
weak_ptr
weak_ptr与shared_ptr的使用是一样的,只是在对shared_ptr拷贝的时候不会对引用计数进行改变。weak_ptr不遵循RAII,其是专门为解决循环引用而出现的。
template<class T>
class weak_ptr
{
public:
weak_ptr(T* ptr)
:_ptr(ptr)
{
}
weak_ptr(const shared_ptr<T>& p)
:_ptr(p._ptr)
{
}
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
weak_ptr operator=(const shared_ptr<T>& p)
{
_ptr = p._ptr;
return *this;
}
private:
T* _ptr;
};上面Node类定义变为:
template<class T>
struct Node
{
Node()
:_a(T())
,_next(nullptr)
,_prev(nullptr)
{ }
T _a;
weak_ptr<Node> _next;
weak_ptr<Node> _prev;
};补充
shared_ptr<int> aa(new int[10]);当我们开辟一个数组的空间时,释放时再使用delete就不能进行空间释放了,所以对于shared_ptr和unique_ptr的参数增加了一个:释放对象。

结合lambda表达式使用起来更加简单。Del的类型可以使用function表示。
template<class T, class Del=function<void(T*)>>
class shared_ptr
{
public:
shared_ptr(T* ptr, Del del = [](T* ptr) {delete ptr; })
:_ptr(ptr)
,_pcount(new int(1))
,_del(del)
{
}
shared_ptr(const shared_ptr<T>& p)
:_ptr(p._ptr)
,_pcount(p._pcount)
{
++(*_pcount);
}
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
shared_ptr operator=(const shared_ptr<T>& p)
{
_ptr = p._ptr;
_pcount = p._pcount;
++(*_pcount);
return *this;
}
~shared_ptr()
{
if (--(*_pcount) == 0)
{
_del(_ptr);
}
}
private:
T* _ptr;
int* _pcount;
Del _del;
};shared_ptr<int> a(new int[10], [](int* ptr) {delete[] ptr; });
shared_ptr<FILE> b(fopen("test.txt", "w"), [](FILE* ptr) {fclose(ptr); });总结
auto_ptr:管理权转移,被拷贝的对象会悬空;
unique_ptr:不支持赋值和拷贝构造;
shared_ptr:通过引用计数控制内存的释放;
weak_ptr:解决shared_ptr的循环引用问题,拷贝和赋值的时候不增加引用计数。
特殊类的设计
不能被拷贝的类
C++11增加了delete的功能,不仅能对new的空间进行释放,放在默认成员函数后面还能表示:不让编译器生成该函数。
实现:将拷贝和赋值置为私有,且使用delete不让编译器生成即可。
template<class T>
class NoCopy
{
public:
//...
private:
NoCopy(const NoCopy&) = delete;
NoCopy operator=(const NoCopy&) = delete;
T _val;
};只能在堆上创建类
也就是不能再栈上创建对象,栈上创建对象必须能够调用构造函数和析构函数,所以对于类的实现有两种方法:1)将构造函数私有;2)将析构函数私有;还需要将拷贝构造和赋值删除。
将构造函数私有
将构造函数私有之后,new也不能调用构造函数了,所以需要增加接口专门返回在对上创建的对象。
template<class T>
class HeapOnly
{
static HeapOnly* Get()
{
return new HeapOnly;
}
private:
HeapOnly(const HeapOnly&) = delete;
HeapOnly operator=(const HeapOnly&) = delete;
HeapOnly()
{
//...
}
T _val;
};将析构函数私有
将析构函数私有之后,还需要提供接口进行空间的释放。
template<class T>
class HeapOnly
{
HeapOnly()
{
//...
}
private:
~HeapOnly()
{
//...
}
HeapOnly(const HeapOnly&) = delete;
HeapOnly operator=(const HeapOnly&) = delete;
T _val;
};只能在栈上创建对象
对于只能在栈上创建对象,就需要不能让new正常使用,new分为两步:1)调用operator new;2)调用构造函数;
实现:重载operator new,将其删除并将构造函数私有;向外提供构造接口。
template<class T>
class StackOnly
{
static StackOnly Creat()
{
StackOnly st;
return st;
}
~StackOnly()
{
//...
}
private:
void* operator new(size_t size) = delete;
StackOnly()
{
//...
}
T _val;
};只能创建一个对象(单例模式)
创建一个类只能创建一个对象,这中类称为单例模式。
实现方法:1)只创建一个对象,将这个对象设为类的及静态成员,在每次获取的时候都将这一静态成员返回;2)将构造函数设为私有,防构造;3)防拷贝,将拷贝和赋值删除。
该类分为两种:饿汉模式和懒汉模式。
饿汉模式
饿汉模式指的是在main函数之前就创建出对象。
class Hungry_class
{
public:
Hungry_class& Get()
{
return _date;
}
private:
Hungry_class(const Hungry_class&) = delete;
Hungry_class operator=(Hungry_class) = delete;
Hungry_class()
{
//...
}
static Hungry_class _date;
};
Hungry_class Hungry_class::_date;
函数自始至终都只有一个对象_date。
饿汉模式的劣势:
1)在main函数之前就进行对象的创建,当有多个单例模式需要被创建时就会影响程序的启动效率。
2)如果两个单例类A和B之间相互联系,B的创建需要A,如果还是使用饿汉模式就会导致无法控制哪一个单例对象先创建。
懒汉模式
懒汉模式与饿汉不同的是:懒汉模式是在需要单例对象时才去创建。
实现方法:与饿汉模式一样,但是懒汉的成员变量是指针而不是对象。
class Lazy_class
{
public:
Lazy_class& Get()
{
if (_date == nullptr)
{
Lazy_class* _date = new Lazy_class;
}
return *_date;
}
private:
Lazy_class(const Lazy_class&) = delete;
Lazy_class operator=(Lazy_class) = delete;
Lazy_class()
{
//...
}
T _val;
static Lazy_class* _date;
};
Lazy_class* Lazy_class::_date;
单例对象的释放
一般单例对象是不需要进行释放的,但是如果中途需要进行显示释放或程序需要进行一些特殊动作(如持久化)等;
单例对象通常是在多个进程中使用的,所以单例对象的释放不能简单的根据作用域让其自己释放,需要提供专门的接口释放。
单例模式析构可以手动调用,也可以像智能指针一样自动调用。
可以通过设计一个内部类实现自动调用析构函数。
class Lazy_class
{
public:
static Lazy_class& Get()
{
if (_date == nullptr)
{
Lazy_class* _date = new Lazy_class;
}
return *_date;
}
static void Destory()
{
//...
}
struct GC
{
~GC()
{
Lazy_class::Destory();
}
};
private:
Lazy_class(const Lazy_class&) = delete;
Lazy_class operator=(Lazy_class) = delete;
Lazy_class()
{
//...
}
static Lazy_class* _date;
static GC _gc;
};
Lazy_class* Lazy_class::_date;
Lazy_class::GC Lazy_class::_gc;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









