 Linux线程与页表核心解析
Linux线程与页表核心解析






文章目录
前言
在现代计算机系统的繁忙 “工厂” 里,线程如同穿梭于各个工序的工人,承担着执行任务的核心职责。从早期单任务处理的 “孤军奋战”,到如今多核处理器时代的 “协同作战”,线程的演化始终与计算效率的突破紧密相连。
作为操作系统调度的基本单位,线程以轻量性和共享性重塑了程序的执行模式 —— 它既继承了进程对系统资源的封装特性,又通过共享内存空间实现了更高效的通信与协作。
本文将从线程的基本概念出发,逐步揭开其运行机制的神秘面纱,探讨多线程编程的核心技术与实
践经验。
本文将分为5个部分进行介绍:
- 线程的基本概念;
- 页表的映射逻辑;
- 线程与进程对比;
- 进程的相关接口;
- 线程的ID是什么;
一. 线程的基本概念
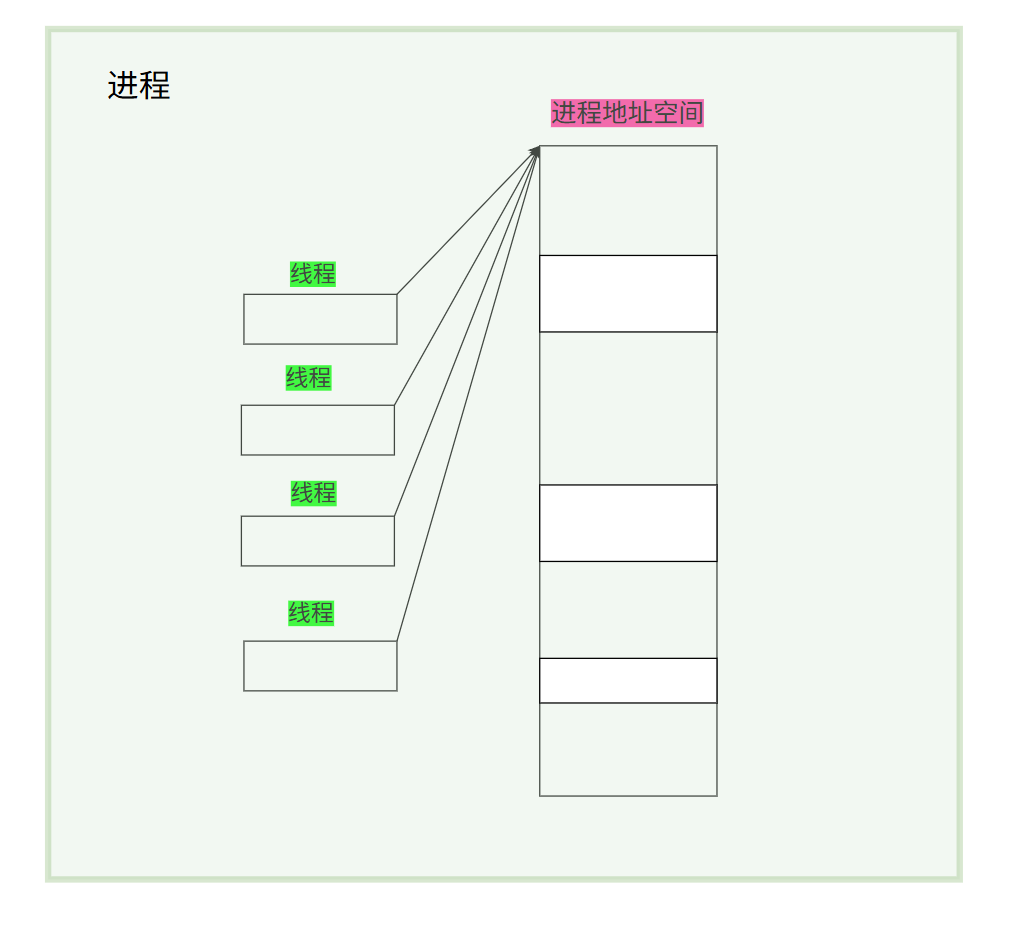
一个进程内部可以有多个执行流,线程是进程的一个执行分支,就是其中的一个执行流。
线程在进程内进行执行,也有分配资源,而一个进程的资源就是该进程的进程地址空间,因此线程在被调度的时进程要为线程分配地址空间,该线程在自己的地址空间中执行代码。
示意图如下:
-
地址空间是进程的资源窗口,在Linux中,线程是在进程"内部"执行的,可以理解为线程在进程的地址空间中运行。
-
因为线程只需要执行进程内的一部分代码,所以说线程的执行力度比进程要更细。
所以根据上面的描述,可以对线程进行一个简单的总结:线程是操作系统调度的基本单位,线程是进程的一个执行分支,线程的执行力度比进程更细。
当有了线程,线程成为进程中的执行流,此后进程就只需要承担分配资源的功能了。
如果一个进程中只有一个执行流,就只有一个task_struct.
通过ps -aL可以查看一个进程中的线程的个数,其中PID指的是进程得PID ,LWP指的是线程得PID,属于同一个进程的线程其,线程的PID相同:
单线程:

多线程:

一个进程至少有一个执行流,也就是说:一个进程至少有一个线程。
在一个进程中可能存在着多个线程,因此线程也要被管理起来,也要向描述在组织,线程是不是也有自己的结构体呢?是的,在Windows操作系统中,就专门为了管理线程,使用了struct tcb结构体来进行描述和组织。
线程属于进程的一部分,进程有的线程也有,像ID,状态,优先级,内存资源,文件描述符表,信号处理、调度信息等。也就是说进程结构体中的各个字段,线程也应该有,只不过可能内部资源的多少不同。
根据上面的描述,我们知道实际上并不需要一个新的结构体来描述线程,使用进程的结构体来描述线程就足够了,因此在Linux中并没有真正的线程tcb结构体,而是使用"进程"内核数据结构来模拟线程的,毕竟线程就是轻量化的进程,而进程分配资源实际上就是在分配该进程地址空间。
在CPU调度的时候,在它眼中,线程和进程都是一样的,都属于执行流;
对于执行流,线程,进程可以根据大小进行排序:线程 <= 执行流 <= 进程;
二. 页表的映射逻辑
在上面我们谈到分配资源都是对虚拟地址进行分配的,虚拟地址通过页表映射到内存地址上。
以下将对这一过程进行详细介绍:
2.1 页和页框
在物理内存上数据的存放是随机存放的,对于一个进程中的数据也并不是整块存储的,使用随机存储,否则如果内存中有多个进程,并且这些进程的数据都是连续存储的,就会导致物理内存将会被分割成各种离散的、大小不同的块,导致物理内存被大量浪费。
我们希望操作系统提供给用户的空间必须是连续的,但是物理内存最好不要连续。 此时就需要将虚拟地址与物理地址建立映射,就是通过也也标记进行映射的。
把物理内存按照一个固定的长度的页框进行分割,有时叫做物理页。每个页框包含一个物理页
(page)。一个页的大小等于页框的大小。大多数32位体系结构支持4KB的页,而64位体系结
构一般会支持8KB的页。区分一页和一个页框是很重要的:
- 页框是一个存储区域;
- 而页是一个数据块,可以存放在任何页框或磁盘中。
假设一个可用的物理内存有4GB的空间。按照一个页框的大小4KB进行划分,4GB
的空间就是4GB/4KB=1048576个页框。有这么多的物理页,操作系统肯定是要将其管理起来的,操作系统需要知道哪些页正在被使用,哪些页空闲等等。内核用struct page结构表示系统中的每个物理页,出于节省内存的考虑,struct page结构体很小:
struct page {
page_flags_t flags; /* Atomic flags, some possibly
* updated asynchronously */
atomic_t _count; /* Usage count, see below. */
atomic_t _mapcount; /* Count of ptes mapped in mms,
* to show when page is mapped
* & limit reverse map searches.
*/
unsigned long private; /* Mapping-private opaque data:
* usually used for buffer_heads
* if PagePrivate set; used for
* swp_entry_t if PageSwapCache
* When page is free, this indicates
* order in the buddy system.
*/
struct address_space *mapping; /* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
*/
pgoff_t index; /* Our offset within mapping. */
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone->lru_lock !
*/
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
};
- flags:用来存放页的状态。这些状态包括页是不是脏的,是不是被锁定在内存中等。
- mapcount:表示在页表中有多少项指向该页,也就是这一页被引用了多少次。当计数值变
为-1时,就说明当前内核并没有引用这一页,于是在新的分配中就可以使用它。 - virtual:是页的虚拟地址。通常情况下,它就是页在虚拟内存中的地址。有些内存(即所谓
的高端内存)并不永久地映射到内核地址空间上。在这种情况下,这个域的值为NULL,需要的
时候,必须动态地映射这些页。
2.2 虚拟地址转内存地址
那么内存地址是如何与虚拟地址建立关系的呢???
以32位机器为例:
32位机器下,一个地址有32个比特位,也就是说每个地址的存储需要4个字节,那么如果要存储所有的虚拟地址就需要 2 32 − 1 ∗ 4 2^{32-1}*4 232−1∗4 也就是大约4GB的空间,虚拟地址要存4GB,对应的内存地址也要存4GB,因此内存上要用8GB的空间完成映射。
毫无疑问,这种直接将虚拟地址和内存地址一一对应的方法肯定是不行的,因为这太浪费空间了。
==所以页表将32个地址进行拆分:前10个一组,中间10个一组,最后12个一组:==将虚拟地址通过三次映射找到物理地址,示意图如下:
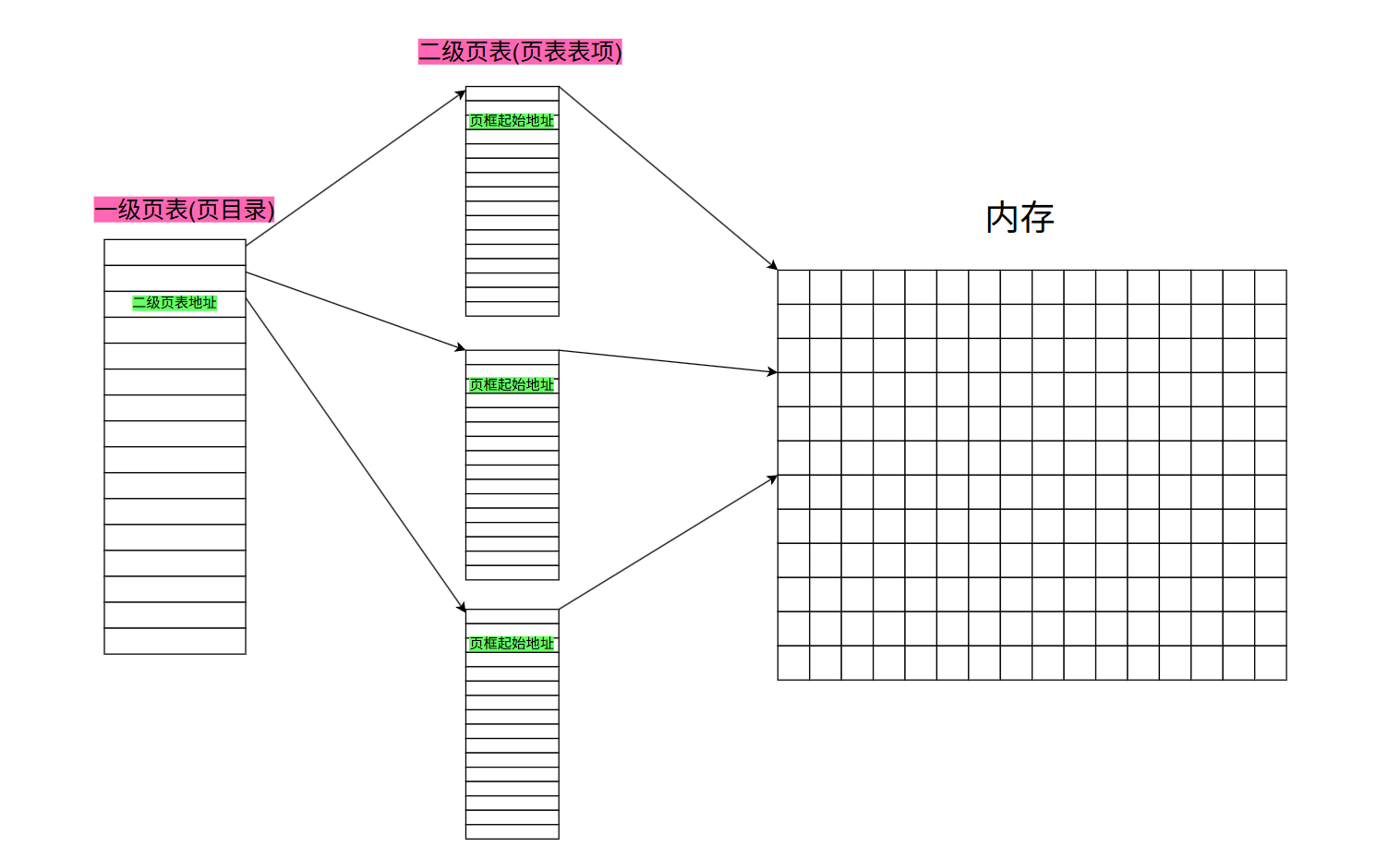
- 先将地址划分出前10位,使用一个 2 10 2^{10} 210的数组来存储二级页表的地址,而一级页表的下标就代表地址的前10位;
- 同理二级页表大小也是 2 10 2^{10} 210,下标表示中间10位地址的大小,其中存储的是内存中每个页的起始位置,通过中间10位就可以找到数据在内存中的哪一个页框中;
- 还剩最后12位,而 2 12 2^{12} 212恰好是4KB,一个页框的大小,所以根据随后12位就可以知道在页框中的哪一个位置。
通过上面三次映射来在目标位置,需要多少空间:一级页表 1024 ∗ 4 = 4 K B 1024*4 = 4KB 1024∗4=4KB ,二级页表有1024个,所以二级页表总大小是 1024 ∗ 1024 ∗ 4 = 4 M B 1024*1024*4 = 4MB 1024∗1024∗4=4MB ,也就是说存这两个表只需要大约4MB空间。
并且因为一个进程并不会使用所有内存,因此一级页表中有些位置为空,也就是说二级页表数量少于1024个,空间会更小。所以按照这种方式进行映射能有效节约空间。
CPU中与内存相关的寄存器:
- 在CPU中有CR3寄存器存储当前进程的一级页表地址;
- CPU还有一个CR2寄存器,专门用来存放发生缺页中断的地址,来保证当数据加载到内存中能从原位置继续执行。
**MMU(Memory Manage Unit)**是一种硬件电路,其速度很快,是它来进行内存管理的,地址转换,用虚拟地址找物理地址的。
在操作系统中为了让查找效率更快,还会使用TLB,就是缓存,将经常使用的地址放到缓存中,在缓存中地址是直接映射的,查找更快,但缓存只能存放一部分映射关系。
当要访问物理内存时,先去TLB中查看是否已经缓存了,如果没有才通过MMU来查找物理内存。
三. 线程与进程对比
线程比进程更轻量化:
- 创建和释放更轻量化,线程占据的资源更少;
- 切换更轻量化,CPU中切换调度的进程需要更换寄存器,页表,虚拟地址等,而线程的切换调度只需要更换物理内存即可。
关于上面的切换轻量化还有一个重要的原因:
CPU中不仅仅有寄存器,还有一块CPU级别的缓存cache,被称为热缓存,通过cat \proc\cpuinfo也可以进行查看:

该缓存中存放着进程中经常使用的一些数据,因此放切换进程后,要重新进行缓存,而切换线程就无需重新缓存,还有上面页表的TLB缓存也要从0开始。
线程是进程的一个分支,所以线程执行就代表这进程执行,所以当一个线程挂了会直接导致进程挂掉。
线程也是有身份的:主线程,新线程;如果一个线程的LWP和进程的PID一样,则该线程就是主线程;线程替换是根据每个线程中时间片的使用情况进行切换的,在主线程中不仅仅有自己线程的时间片,还有整个进程的时间片,决定了当前线程什么时候切换。
线程的缺点:
- 健壮性比高,当一个线程出现问题的时候,会直接影响到其他线程,线程就代表整个进程;
- 编程难度更高,需要考虑不同线程间的同步互斥问题。
两个概念:
- 计算密集型:任务的速度取决于CPU的运算能力;
- IO密集型:任务的执行速度,主要受输入输出操作速度限制。
对于计算密集型的程序,只用单线程更好;而对于IOO密集型的任务,使用多线程效率更高。线程的用途,与多进程一样,都是为了提高并发度。
线程与进程的概念:
- 进程是资源分配的基本单位;
- 线程是CPU调度的基本单位;
- 线程间共享进程资源,进程之间相互独立。
线程有些资源可以共享使用,但是有些资源只能自己进行使用:
线程独立的资源:
- 栈空间;
- 一组寄存器,用来存储线程的上下文;
- 线程ID;
errno存储错误号;- 信号屏蔽字。
线程间共享的资源:
- 文件描述符表;
- 地址空间,代码段,数据区;
- 全局变量,函数;
- 信号的处理方式。
四. 线程调用接口
上面我们谈到Linux中没有线程的概念,所以没有提供线程的系统接口,只提供了轻量级进程的系统调用;Linux程序员对这些接口进行封装,在应用层,提供pthread库,属于Linux的原生线程库,Linux系统中自带的有,只不过在使用一些接口的时候需要主动连接相应的库。
以下介绍的都是pthread原生线程库中的接口。
4.1 创建线程
int pthread_create(pthread_t* thread , const pthread_attr_t *attr , void* (*start_routinue)(void*) , void* arg:
- 参数一:一个输出型参数,用来输出线程的ID;
- 参数二:设置线程的属性,像优先级,栈属性,以及回收方式等,一般不进行设置,使用NULL;
- 参数三:是一个函数指针,该函数返回值和参数都是
void*,当线程创建成功之后,会去执行该函数中的代码; - 第四个参数,一个
void*的指针,用来作为函数的参数。 - 返回值,成功返回0,失败返回错误码。
因为给线程调用函数传参的时候,传的是指针并且是void*类型的,所以我们不仅可以传内置类型,还可以传结构体/类指针等。
下面写一个demo代码进行演示:
void *thread_func(void *arg)
{
while (1)
{
std::cout << "the new thread is running" << std::endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t thread;
pthread_create(&thread, nullptr, thread_func, nullptr);
while (1)
{
std::cout << "the main thread is running" << std::endl;
sleep(1);
}
return 0;
}
注意:在进行编译的时候,要连接pthread库:g++ -o test test.cc -std=c++11 -lpthread
现象:
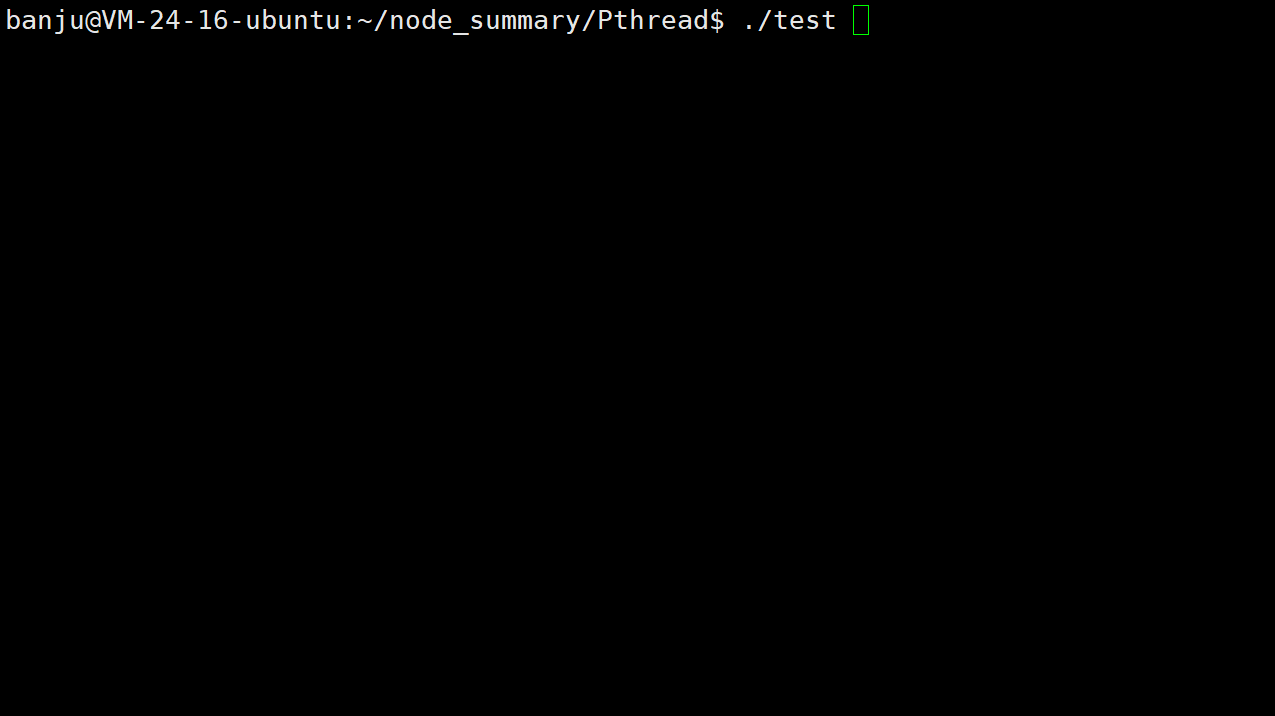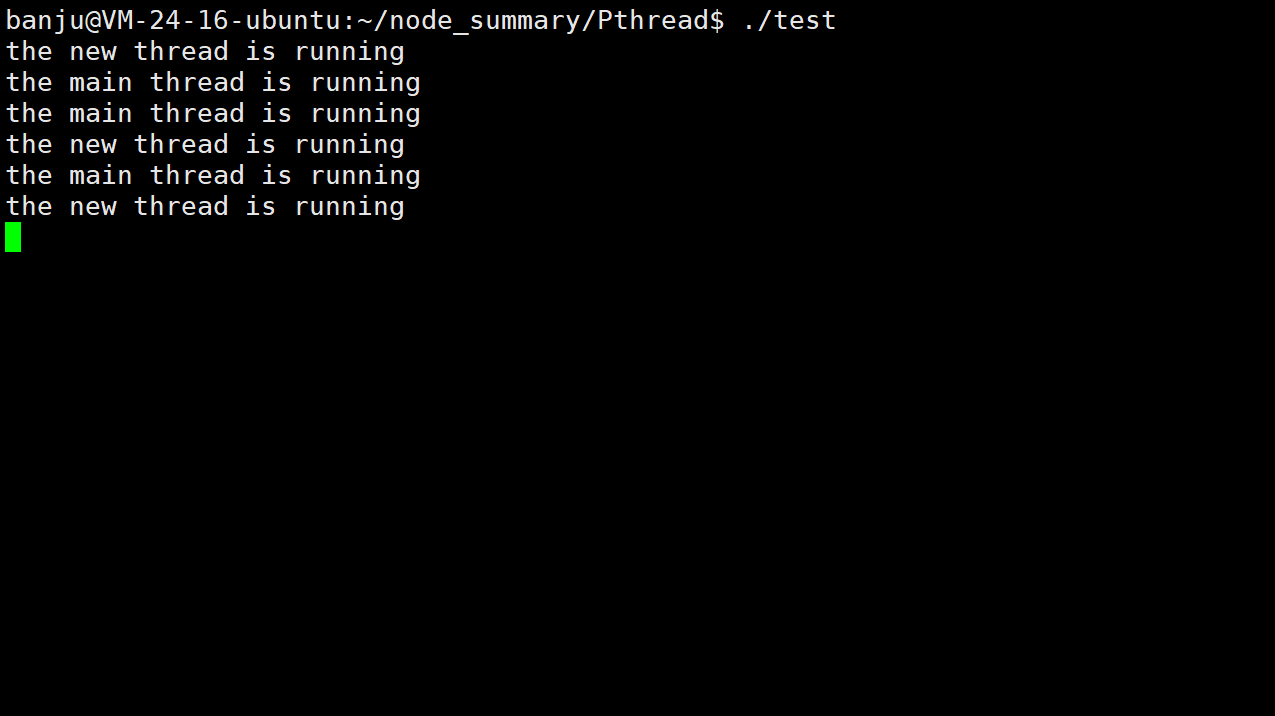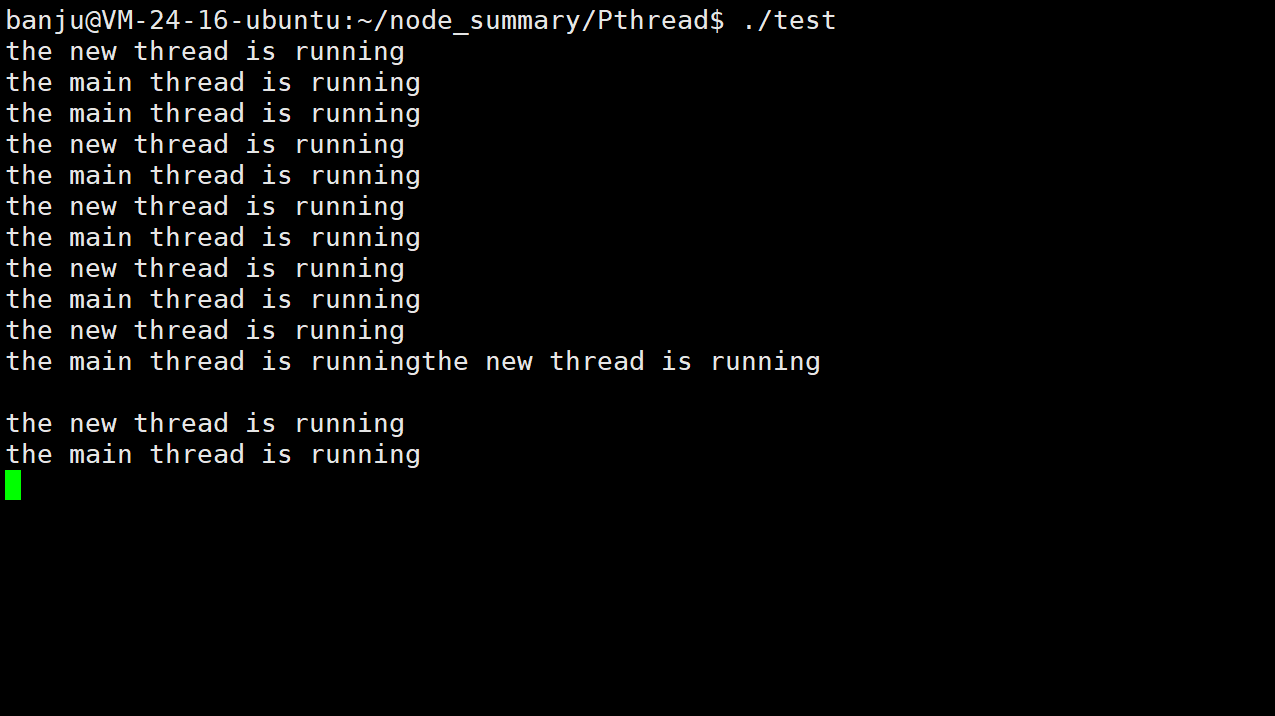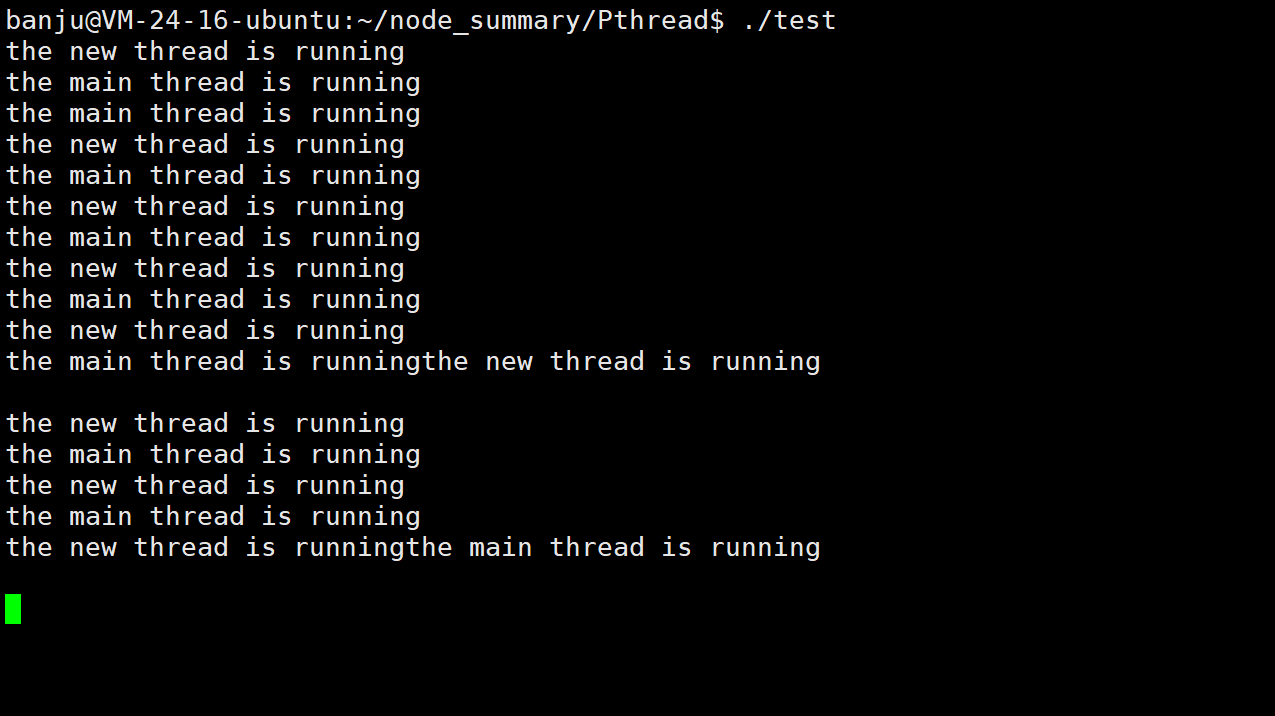
可以看到两个线程在同时打印数据。
4.2 线程等待
与进程等待类似,线程也需要进行等待,否则也会出现类似于僵尸进程的现象,有时主线程也希望知道新线程的运行情况。
在线程库中也提供了对应的接口,让主进程来回收新进程:
int pthread_join(pthread_t thread , void** reval)
- 参数一:线程ID;
- 参数二:是一个输出型参数,接收线程的返回信息;
- 返回值:成功返回0,失败返回错误码。
在一个新线程中也允许主动终止当前线程的执行,并可选地向其他等待该线程的线程传递退出状态:
void pthread_exit(void* retval):与exit()类似,只不过该结构终止的是线程。
在操作系统中好提供了一个特殊的接口:int pthread_cancel(pthread_t thread),其核心作用是向指定线程发送取消请求,请求终止该线程的执行。它允许一个线程主动请求终止另一个线程,但这种终止并非强制即时生效,而是取决于目标线程的 “取消状态” 和 “取消类型” 设置。
五. 线程的ID
我们可以使用pthread_self()接口来获取线程的ID,对上面的程序代码进行修改,分别获取主线程和新线程的ID,用16进制打印出来:
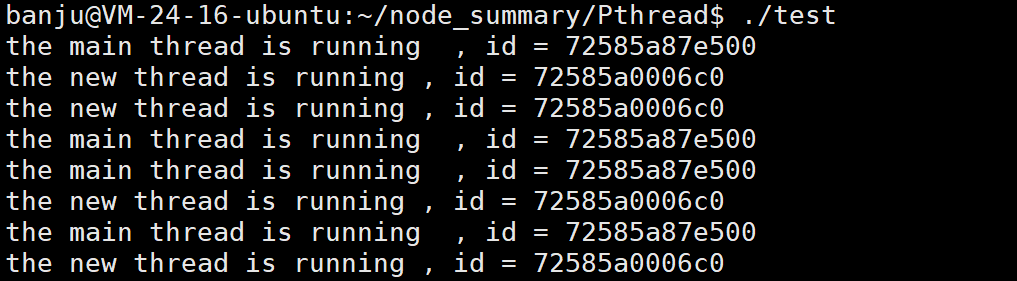
可以看到这些数字都很大,不想进程ID一样。这些数都是什么意思,为什么和我们使用
ps -aL查看的数不一样???
实际上使用ps -aL命令查看的轻量化进程的ID,也就是线程的ID。
而此处使用pthread_self()得到的ID并不是线程的ID,而是一个地址,下面进行详细解释:
pthread线程库是一个动态库,也要加载到内存中,映射到进程的共享区中。因为操作系统没有线程的概念,因此所有关于线程的概念及接口都由这一个动态库进行维护,当一个进程中有多个线程的时候,动态库也要负责将他们组织起来,库中使用一个struct pthread结构体来进行组织。
那么该库如何标定每一个线程,以及记录每一个线程结构体的位置呢???,既要让外界能拿到进程的唯一标识符,又要能找到进程结构体的位置
因此,直接向用户返回一个对应线程结构体的起始地址即可,既保证了唯一性,又让外界能够通过这一个地址获取线程属性。
示意图如下:
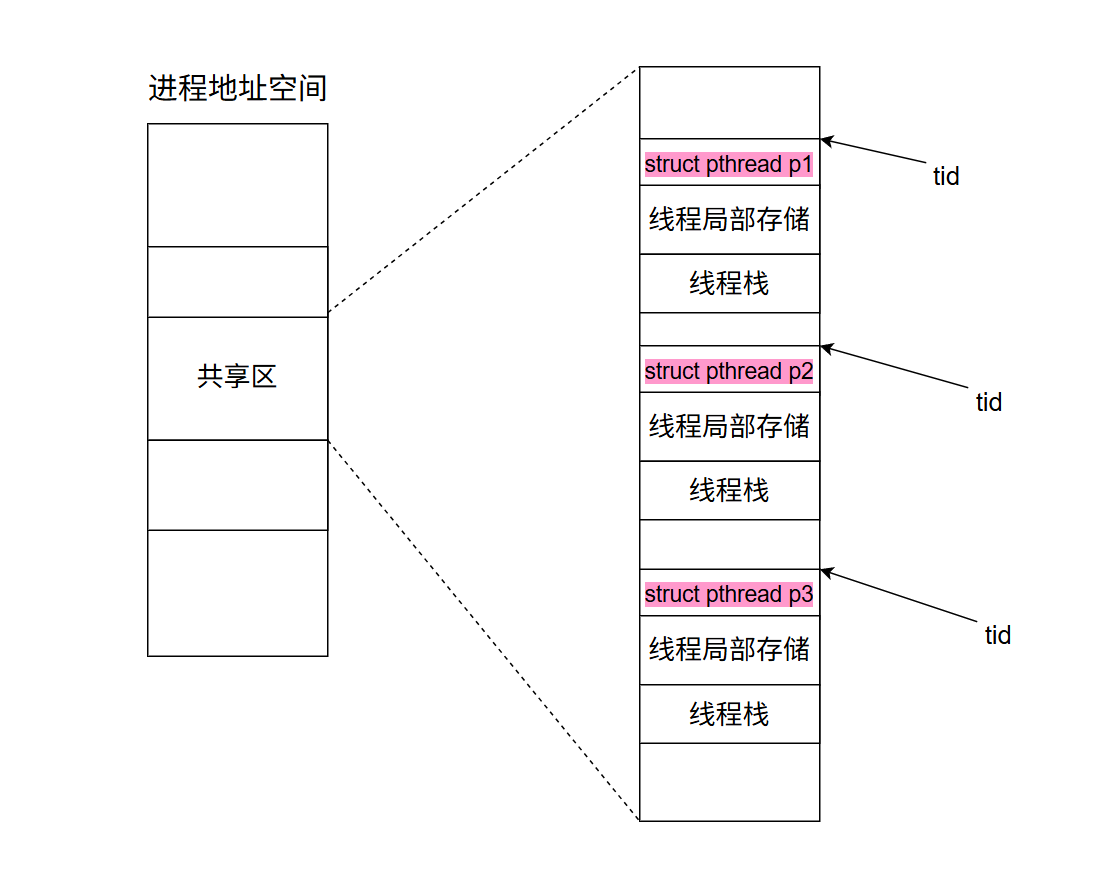
每个线程都有自己的调用链,所以每个线程都有独立的栈结构:
- 主线程直接使用进程地址空间的栈;
- 新线程的栈在共享区,具体来说在线程库中如上图,在其自己的结构体中。
栈实际上是完成整个执行链而临时使用的空间,线程之间堆空间是共享的,可以相互访问,但是栈空间都是各自使用自己的。
但是注意:线程之间没有秘密,虽然各自使用自己的栈空间,但是这些数据都还是在进程地址空间中的,所有进程都可以看到,只要拿到对应的地址就可以进行访问。
六. 线程局部存储
如果一个线程希望使用一个变量,来让它要调用的函数都可以看到,应该用什么方式比较好???
使用一个全局变量可以吗,当然对于一个线程来说,使用一个全局变量是足够的,但是如果又很多线程都希望这样做,那是不是要定义很多全局变量,还要区分这些全局变量。
为了解决这一问题,编译器提供了一个关键字__thread,通过在一个变量定义前面加上__thread让该变量放在线程局部存储的位置(见上图),使得对应的线程在任意位置都可以看到,并且每个线程都有一份自己的。
注意:局部存储只允许定义内置类型。
七. 线程分离
如果我们不需要从新线程中获取线程的退出信息,有没有什么方法可以不然主线程进行等待???
- 默认情况下,创建的进程都是joinable需要被等待的,线程退出后,需要主线程
pthread_jion()等待; - 当然如果不希望等待新线程,可以使用
int pthread_detach(pthread_t thread)表示让主进程不再等待thread新线程,新线程执行完,直接退出即可。
进行线程分离后,必须保证主线程是最后一个退出的线程。
线程分离可以主线程调用,也可以新线程自己调用。


















 1074
1074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











