






一、安装PyPOTS
一般情况下,可以在cmd上直接输入如下命令行(已经安装python的前提,且配置好环境)
pip install pypots
会自动出现(仅展现部分)
一般情况下没有出现Error就成功了
二、一个操作示例
注:下面的代码是不断地补充过程
1、获得数据
# 导入必要的库
from benchpots.datasets import preprocess_physionet2012 # 导入physionet2012数据集预处理函数
# 加载并预处理physionet2012数据集
# subset="set-a": 使用set-a子集
# pattern="point": 使用点缺失模式
# rate=0.1: 设置缺失率为10%
physionet2012_dataset = preprocess_physionet2012(
subset="set-a",
pattern="point",
rate=0.1,
)
# 打印数据集的键,查看包含哪些数据
print(physionet2012_dataset.keys())PhysioNet 2012 数据集是一个公开可用的医学数据集,包含 12,000 名 ICU 患者的脱敏记录,每条记录由大约 48 小时的多元时间序列数据组成
可能要用终端来运行,用python Edit的话,可能运行不了,会卡顿

运行完之后,会默认把数据集下载到.pypots这个文件夹上的
下载好后,再次运行代码(可在edit上运行),可以看到一些相关数据
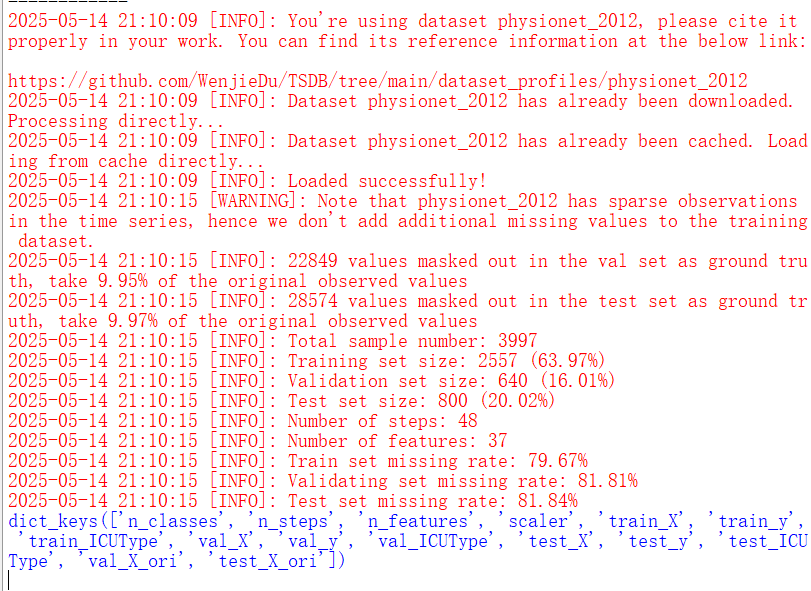
2、对 PhysioNet 2012 数据集进行进一步的处理,以便将其用于深度学习模型的训练、验证和测试
#补充——对上一段代码的概括
from benchpots.datasets import preprocess_physionet2012
physionet2012_dataset = preprocess_physionet2012(
subset="set-a",
pattern="point",
rate=0.1,
)
# 导入numpy库用于数值计算
import numpy as np
# 创建测试集的缺失值指示掩码
# 通过异或运算(^)比较原始数据和缺失数据的NaN位置,得到真实缺失值的位置
physionet2012_dataset["test_X_indicating_mask"] = np.isnan(physionet2012_dataset["test_X"]) ^ np.isnan(physionet2012_dataset["test_X_ori"])
# 将原始测试数据中的NaN值替换为0
physionet2012_dataset["test_X_ori"] = np.nan_to_num(physionet2012_dataset["test_X_ori"])
# 构建训练集字典,只包含输入特征X
train_set = {
"X": physionet2012_dataset["train_X"],
}
# 构建验证集字典,包含输入特征X和原始数据X_ori
val_set = {
"X": physionet2012_dataset["val_X"],
"X_ori": physionet2012_dataset["val_X_ori"],
}
# 构建测试集字典,包含输入特征X和原始数据X_ori
test_set = {
"X": physionet2012_dataset["test_X"],
"X_ori": physionet2012_dataset["test_X_ori"],
}
注:这步不涉及对本地数据集的处理
3、用SAITS 模型来进行时间序列数据的插补
#补充上面的内容。。。
from benchpots.datasets import preprocess_physionet2012
physionet2012_dataset = preprocess_physionet2012(
subset="set-a",
pattern="point",
rate=0.1,
)
import numpy as np
physionet2012_dataset["test_X_indicating_mask"] = np.isnan(physionet2012_dataset["test_X"]) ^ np.isnan(physionet2012_dataset["test_X_ori"])
physionet2012_dataset["test_X_ori"] = np.nan_to_num(physionet2012_dataset["test_X_ori"])
train_set = {
"X": physionet2012_dataset["train_X"],
}
val_set = {
"X": physionet2012_dataset["val_X"],
"X_ori": physionet2012_dataset["val_X_ori"],
}
test_set = {
"X": physionet2012_dataset["test_X"],
"X_ori": physionet2012_dataset["test_X_ori"],
}
# 导入SAITS模型,这是一个用于时间序列数据插补的深度学习模型
from pypots.imputation import SAITS
#补充内容
from pypots.optim import Adam
DEVICE = 'cpu'
# 初始化SAITS模型,设置模型参数
saits = SAITS(
n_steps=physionet2012_dataset['n_steps'], # 时间步长,从数据集中获取
n_features=physionet2012_dataset['n_features'], # 特征数量,从数据集中获取
n_layers=3, # Transformer编码器层数
d_model=64, # 模型维度
n_heads=4, # 注意力头数
d_k=16, # 每个注意力头的键维度
d_v=16, # 每个注意力头的值维度
d_ffn=128, # 前馈神经网络隐藏层维度
dropout=0.1, # Dropout比率,用于防止过拟合
# 你可以调整参数ORT_weight和MIT_weight的权重值,以使SAITS模型更多地关注于一个任务。通常你可以让它们保持默认值,比如1
ORT_weight=1,
MIT_weight=1,
batch_size=32,
# 这里为了快速演示我们将epochs设置为10,你可以将其设置为100或更多以获得更好的结果
epochs=10,
# 这里我们设置patience=3,如果连续3个epoch的评估loss没有减少,则提前停止训练。你可以不设置它,则默认为None,禁用早停机制
patience=3,
# 设置优化器。不同于torch.optim。在初始化pypots.optimizer时,你不必指定模型的参数。您也可以不设置它, 它将默认初始化一个lr=0.001的Adam优化器。
optimizer=Adam(lr=1e-3),
# 这个num_workers参数用于torch.utils.data.Dataloader。它是用于数据加载的子进程的数量。让它默认为0意味着数据加载将在主进程中,即不会有子进程。如果你认为数据加载是模型训练速度的瓶颈,则可以将其增加
num_workers=0,
# 如果不设置device, PyPOTS将自动为你分配最佳设备。这里我们将其设置为“cpu”。你也可以设置为'cuda', ‘cuda:0’或‘cuda:1’,如果你有多个cuda设备,甚至并行['cuda:0', 'cuda:1']
device=DEVICE,
# 设置保存tensorboard和训练模型文件的路径
saving_path="../task2_数据集/result_saving/imputation/saits",
# 训练完成后只保存最好的模型。你还可以将其设置为“better”,以保存在训练期间每一次在val set上表现得比之前更好的模型
model_saving_strategy="best",
)
这次会对优化后的数据集进行保存(注:我对路径进行了修改,和原始的不一样)
看参数:
# 设置保存tensorboard和训练模型文件的路径
saving_path="../task2_数据集/result_saving/imputation/saits",补充了两条内容:
from pypots.optim import Adam #和PyTorch库的Adam优化器有所不同喔
DEVICE = 'cpu'
4、进行训练和预测
#补充上面的内容。。。
#1.
from benchpots.datasets import preprocess_physionet2012
physionet2012_dataset = preprocess_physionet2012(
subset="set-a",
pattern="point",
rate=0.1,
)
#2
import numpy as np
physionet2012_dataset["test_X_indicating_mask"] = np.isnan(physionet2012_dataset["test_X"]) ^ np.isnan(physionet2012_dataset["test_X_ori"])
physionet2012_dataset["test_X_ori"] = np.nan_to_num(physionet2012_dataset["test_X_ori"])
train_set = {
"X": physionet2012_dataset["train_X"],
}
val_set = {
"X": physionet2012_dataset["val_X"],
"X_ori": physionet2012_dataset["val_X_ori"],
}
test_set = {
"X": physionet2012_dataset["test_X"],
"X_ori": physionet2012_dataset["test_X_ori"],
}
#3
from pypots.imputation import SAITS
from pypots.optim import Adam
DEVICE = 'cpu'
saits = SAITS(
n_steps=physionet2012_dataset['n_steps'],
n_features=physionet2012_dataset['n_features'],
n_layers=3,
d_model=64,
n_heads=4,
d_k=16,
d_v=16,
d_ffn=128,
dropout=0.1,
ORT_weight=1,
MIT_weight=1,
batch_size=32,
epochs=10,
patience=3,
optimizer=Adam(lr=1e-3),
num_workers=0,
device=DEVICE,
saving_path="../task2_数据集/result_saving/imputation/saits",
model_saving_strategy="best",
)
# 使用训练集和验证集对SAITS模型进行训练
# train_set: 包含训练数据的字典,其中"X"键对应的值包含输入特征
# val_set: 包含验证数据的字典,其中"X"键对应的值包含输入特征,"X_ori"键对应的值包含原始数据
# 训练过程中会自动使用之前设置的参数,包括epochs=10等超参数
saits.fit(train_set, val_set)
# 使用训练好的SAITS模型对测试集进行预测,生成缺失值填充结果
# test_set: 包含测试数据的字典,其中"X"键对应的值包含输入特征
# 返回的test_set_imputation_results是一个字典,其中重要的键值对为:
# - "imputation": 填充后的完整时间序列数据,形状为(n_samples, n_steps, n_features)
test_set_imputation_results = saits.predict(test_set)
会保存在上一步那里的路径的相关文件夹下,可以自己去看看

5、计算测试集上的均方误差
#补充上面的内容。。。
#1.
from benchpots.datasets import preprocess_physionet2012
physionet2012_dataset = preprocess_physionet2012(
subset="set-a",
pattern="point",
rate=0.1,
)
#2
import numpy as np
physionet2012_dataset["test_X_indicating_mask"] = np.isnan(physionet2012_dataset["test_X"]) ^ np.isnan(physionet2012_dataset["test_X_ori"])
physionet2012_dataset["test_X_ori"] = np.nan_to_num(physionet2012_dataset["test_X_ori"])
train_set = {
"X": physionet2012_dataset["train_X"],
}
val_set = {
"X": physionet2012_dataset["val_X"],
"X_ori": physionet2012_dataset["val_X_ori"],
}
test_set = {
"X": physionet2012_dataset["test_X"],
"X_ori": physionet2012_dataset["test_X_ori"],
}
#3
from pypots.imputation import SAITS
from pypots.optim import Adam
DEVICE = 'cpu'
saits = SAITS(
n_steps=physionet2012_dataset['n_steps'],
n_features=physionet2012_dataset['n_features'],
n_layers=3,
d_model=64,
n_heads=4,
d_k=16,
d_v=16,
d_ffn=128,
dropout=0.1,
ORT_weight=1,
MIT_weight=1,
batch_size=32,
epochs=10,
patience=3,
optimizer=Adam(lr=1e-3),
num_workers=0,
device=DEVICE,
saving_path="../task2_数据集/result_saving/imputation/saits",
model_saving_strategy="best",
)
#4
saits.fit(train_set, val_set)
test_set_imputation_results = saits.predict(test_set)
# 从pypots库中导入计算均方误差(MSE)的函数
from pypots.nn.functional import calc_mse
# 计算测试集上的均方误差(MSE)
# test_set_imputation_results["imputation"]: SAITS模型对测试集的插补结果
# physionet2012_dataset["test_X_ori"]: 测试集的原始完整数据
# physionet2012_dataset["test_X_indicating_mask"]: 测试集的缺失值指示掩码
test_MSE = calc_mse(
test_set_imputation_results["imputation"],
physionet2012_dataset["test_X_ori"],
physionet2012_dataset["test_X_indicating_mask"],
)
# 打印SAITS模型在测试集上的MSE评估结果
print(f"SAITS test_MSE: {test_MSE}")
注:在机器学习和深度学习中,即使使用相同的代码,每次运行的结果也可能不同。
6、保存
使用 pypots 库中的 pickle_dump 函数将插补后的数据集保存为一个 .pkl 文件
#补充上面的内容。。。
#1.
from benchpots.datasets import preprocess_physionet2012
physionet2012_dataset = preprocess_physionet2012(
subset="set-a",
pattern="point",
rate=0.1,
)
#2
import numpy as np
physionet2012_dataset["test_X_indicating_mask"] = np.isnan(physionet2012_dataset["test_X"]) ^ np.isnan(physionet2012_dataset["test_X_ori"])
physionet2012_dataset["test_X_ori"] = np.nan_to_num(physionet2012_dataset["test_X_ori"])
train_set = {
"X": physionet2012_dataset["train_X"],
}
val_set = {
"X": physionet2012_dataset["val_X"],
"X_ori": physionet2012_dataset["val_X_ori"],
}
test_set = {
"X": physionet2012_dataset["test_X"],
"X_ori": physionet2012_dataset["test_X_ori"],
}
#3
from pypots.imputation import SAITS
from pypots.optim import Adam
DEVICE = 'cpu'
saits = SAITS(
n_steps=physionet2012_dataset['n_steps'],
n_features=physionet2012_dataset['n_features'],
n_layers=3,
d_model=64,
n_heads=4,
d_k=16,
d_v=16,
d_ffn=128,
dropout=0.1,
ORT_weight=1,
MIT_weight=1,
batch_size=32,
epochs=10,
patience=3,
optimizer=Adam(lr=1e-3),
num_workers=0,
device=DEVICE,
saving_path="../task2_数据集/result_saving/imputation/saits",
model_saving_strategy="best",
)
#4
saits.fit(train_set, val_set)
test_set_imputation_results = saits.predict(test_set)
#5
from pypots.nn.functional import calc_mse
test_MSE = calc_mse(
test_set_imputation_results["imputation"],
physionet2012_dataset["test_X_ori"],
physionet2012_dataset["test_X_indicating_mask"],
)
print(f"SAITS test_MSE: {test_MSE}")
from pypots.data.saving import pickle_dump
train_set_imputation = saits.impute(train_set)
val_set_imputation = saits.impute(val_set)
test_set_imputation = test_set_imputation_results["imputation"]
dict_to_save={
'train_set_imputation': train_set_imputation,
'train_set_labels': physionet2012_dataset['train_y'],
'val_set_imputation': val_set_imputation,
'val_set_labels': physionet2012_dataset['val_y'],
'test_set_imputation': test_set_imputation,
'test_set_labels': physionet2012_dataset['test_y'],
}
pickle_dump(dict_to_save, "../task2_数据集/result_saving2/imputed_physionet2012.pkl")
注:这段代码的最后,我改了保存路径
.pkl文件是一种用于序列化和反序列化 Python 对象结构的文件格式。(记住,永远不要反序列化来自不可信来源的数据)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









