






集合与映射(字典)的应用
一、核心概念
1、集合(set)
(1)无序、不重复元素的容器。
(2)特性:去重性、支持集合运算(交/并/差)。
(3)语法:{1,2,3} 或 set( )。
(4)元素必须可哈希(不可变类型)。
2、字典(dict)
(1) 键值对(Key-Value)映射结构。
(2)特性:快速查找、键唯一性。
(3)语法:{‘a’:1, ‘b’:2} 或 dict()。
(4)键必须可哈希,值可以是任意类型。
二、应用场景
1、集合常见类型
- 数据去重:快速去除列表中的重复元素
nums = [1, 2, 2, 3, 4, 4]
unique_nums = list(set(nums))
print(unique_nums) # [1, 2, 3, 4]
- 集合运算:分析数据关系
A = {1, 2, 3}
B = {3, 4, 5}
print(A | B) # 并集: {1,2,3,4,5}
print(A & B) # 交集: {3}
print(A - B) # 差集: {1,2}
- 成员快速检测(O(1)时间复杂度)
valid_users = {'alice', 'bob', 'charlie'}
user = input('Username: ')
if user in valid_users:
print("Access granted")

2、字典常见应用
- 数据统计:例如统计词频
text = "apple banana apple orange banana"
words = text.split()
frequency = {}
for word in words:
frequency[word] = frequency.get(word, 0) + 1
# {'apple':2, 'banana':2, 'orange':1}
print('words:', words)
print('次数:',frequency)
运行结果:

- 快速查找表
country_codes = {
'US': 'United States',
'CN': 'China',
'JP': 'Japan'
}
print(country_codes['CN']) # 输出:China
- 配置管理:存储程序配置参数
config = {
'host': 'localhost',
'port': 8080,
'debug': True,
'plugins': ['logger', 'validator']
}
print(config)

- 缓存机制(Memoization)
cache = {}
def fibonacci(n):
if n in cache:
return cache[n]
if n <= 1:
result = n
else:
result = fibonacci(n-1) + fibonacci(n-2)
cache[n] = result
return result
三、进阶应用
1、社交网络共同好友分析
# 使用集合运算分析用户关系
alice_friends = {'Bob', 'Charlie', 'Diana'}
bob_friends = {'Alice', 'Charlie', 'Eve'}
common = alice_friends & bob_friends # 共同好友 {'Charlie'}
alice_only = alice_friends - bob_friends # Alice独有好友 {'Diana'}
all_friends = alice_friends | bob_friends # 所有好友集合
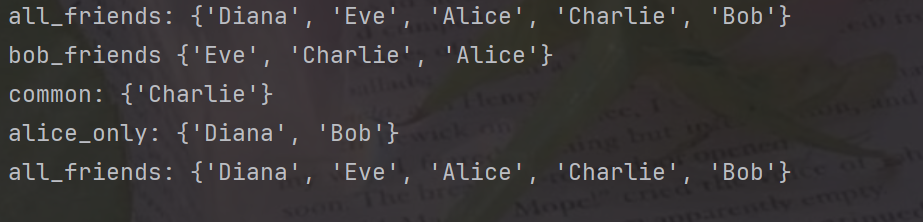
print('all_friends:',all_friends)
print('bob_friends',bob_friends)
print('common:',common)
print('alice_only:',alice_only)
print('all_friends:',all_friends)
- 高效数据分组
```python
# 使用字典进行数据分类
students = [
('Alice', 'A'),
('Bob', 'B'),
('Charlie', 'A'),
('David', 'C')
]
```python
# 使用字典进行数据分类
students = [
('Alice', 'A'),
('Bob', 'B'),
('Charlie', 'A'),
('David', 'C')
]
grade_groups = {}
for name, grade in students:
if grade not in grade_groups:
grade_groups[grade] = []
grade_groups[grade].append(name)
print(students)
print(grade_groups)
# 输出:{'A': ['Alice', 'Charlie'], 'B': ['Bob'], 'C': ['David']}
- 实现LRU缓存
from collections import OrderedDict
class LRUCache:
def __init__(self, capacity):
self.cache = OrderedDict()
self.capacity = capacity
def get(self, key):
if key not in self.cache:
return -1
self.cache.move_to_end(key)
return self.cache[key]
def put(self, key, value):
if key in self.cache:
self.cache.move_to_end(key)
self.cache[key] = value
if len(self.cache) > self.capacity:
self.cache.popitem(last=False)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









