






一、自定义函数
1、自定义函数有固定的格式,它是通过关键字de来声明的,其结构如下。
def 函数名(参数):
“”“
说明文档内容
”“”
函数体
return返回值【例】
defy):
“”“
本函数主要是计算z= x**2y**2的值函数需要接收两个参数:x和y
"""
z = X**2 + y**2
return z
2、 函数的参数分为形参和实参。形参即形式参数,在使用def定义函数时,函数名后面的括号里的变量称作形式参数。在调用函数时提供的值或者变量称作实际参数,实际参数简称为实参。
#这里的a和b就是形参
def add(a b):
return a+b
#这里的1和2是实参
add(1,2)
#这里的x和y是实参
x-2
y=3
add (x,y)【例】
def f(x, y):
z = x**2 + y**2
return z
res = f(2,3)
print (res)运行结果:
![]()
help(f)运行结果:

3、函数中带有默认参数模式
def f(x=0,y=0):
"""
本函数主要是计算z=x**2+ y**2的值
函数需要接收两个参数:x和y
当参数不赋值时,就以默认参数赋值计算
"""
Z = x**2 + y**2
return Z
result = f(2, 3)
print(result)4、func(*args),这种传入参数方式是可以传入任意个参数,这些参数都被放到了tuple元组,中赋值给形参args,之后要在函数中使用这些形参,直接操作args这个tuple元组就可以了这样的好处是在参数的数量上没有了限制,但因为是tuple,其本身还是有次序的,这就仍然存在一定的束缚,在对参数操作上也会有一些不便
def func(name,*args):
print(name+"有以下雅称:")
for i in args:
print(i)
func('孙赵钱','孙猴子','二毛','孙学霸')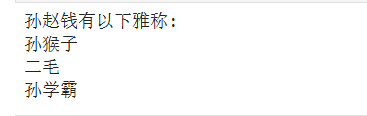
4、func(**kargs),最为灵活,是以键值对字典的形式向函数传入参数,既有第二种位置上的灵活,同时还具有第三种方式在数量上的无限制。此外第三第四种以函数声明的方式在前面加有'*做声明标识。
以上四种方式大多数情况是四种传递方式混合使用,如fun0(a,b,*c,**d)。
def test(x,y=5,*a,**b):
print(x, y, a, b)
test(1)
test(1,2)
二、函数的递归与嵌套
1、递归
函数的递归是指函数在函数体中直接或间接的调用自身的现象。递归要有停止条件,否则函数将永远无法跳出递归,造成了死循环。下面我们将用递归写一个经典的斐波那契数列,斐波那契数列的每一项等于它前面两项的和。
f(n)=f(n-1)+f(n-2) n>2
f(n)=1 n ≤ 2
定义菲波那切数列如下。
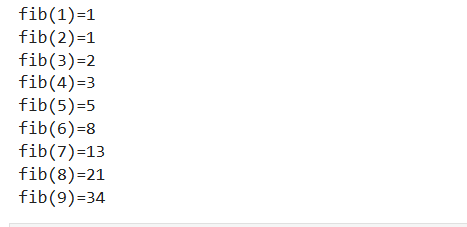
def fib(n):
if n <= 2:
return 1
else:
return fib(n-1)+fib(n-2)
for i in range(1,10):
#格式化输出
print("fib(%s)=%s" %(i,fib(i)))
运行结果:
注:递归结构往往消耗内存较大,能用迭代解决的就尽量不用递归。
2、嵌套
函数的嵌套是指在函数中调用另外的函数,这是函数式编程的重要结构,也是我们在程序中最常用的一种程序结构。我们将利用函数的嵌套重写二次方程解的程序。
【例】
#定义输入函数
def args_input():
try:
A = float(input("输入A:"))
B = float(input("输入B:"))
C = float(input("输入C:"))
return A,B,C
#输入出错则重新输入
except:
print("请输入正确的数值类型!")
#为了出错时能够重新输入
return args_input()
# 计算delta
def get_delta(A,B,C):
return B**2-4*A*C
#求解方程的根
def solve():
A,B,C= args_input()
delta = get_delta(A,B,C)
if delta < 0:
print("该方程无解!")
elif delta == 0:
X = B / (-2 * A)
print("x=", x)
else:
#计算x1、x2
X1=(B + delta**0.5) / (-2* A)
x2=(B - delta**0.5 )/ (-2* A)
print("x1=",x1)
print("x2=",x2)
#在当前程序下直接执行本程序
def main():
solve()
if __name__ == '__main__':
mian()运行结果:

代码说明:
if_name_ =='_main_'的意思是:该代码.py文件被直接运行时,if_name_=='_main之下的代码块将被运行;当该代码.py文件以模块形式被其它代码调用或者导入时,if_name=='main'之下的代码块则不被运行。
三、匿名函数
lambda函数又称为匿名函数,或者行内函数。名函数多用于调用一次就不再被调用的函数,属于“一次性”函数。
其表达式的语法格式为:lambda para:expr
para为参数,多个参数可以使用逗号隔开,冒号后的expr为一个表达式
#定义函数f(x,y)=x+Xy
f=lambda x,y:x+x*y
print(f(2,3))运行结果:

四、关键字yield函数
Yield函数可以将函数执行的中间结果返回但又不结束程序,听起来比较抽象但是用起来很简单,下面的例子将模仿range()函数写一个自己的range。
def func(n):
i = 0
while i < n:#为什么不是print(i)?
yield i
i += 1
for i in func(10):
print(i)运行结果:

yield函数的作用就是把一个函数变成一个generator(生成器),带有yield的函数不再是一个普通函数,Python解释器会将其视为一个generator。上面代码若把yield i改为print(i),就获取不到iterable 的效果。再如下斐波那契(Fibonacci)数列的例子。
斐波那契数列是一个非常简单的递归数列,除第一个和第二个数外,其任意一个数都可由前两个数相加得到。用计算机程序输出斐波那契数列的前N个数是一个非常简单的问题,许多初学者都可以轻易写出如下函数。
(1)输出斐波那契数列前 N 个数。
def fab(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
# 使用生成器
for num in fab(10):
print(num)运行结果:

(2)可以使用如下方式打印出fab()函数返回的List .
def fab(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
# 使用生成器
for num in fab(10):
print(num)
改写后的 fab() 函数通过返回 List 能满足复用性的要求,但是更有经验的开发者会指出,该函数在运行中占用的内存会随着参数max的增大而增大,如果要控制内存占用,最好不要用 List来保存中间结果,而是通过 iterable 对象来迭代。
五、map函数
遍历序列,对序列中每个元素进行同样的操作,最终获取新的序列。
map(f, S)
将函数 f 作用在序列S上。
li=[11,22,33]
new_list=map(lambda a:a+100,li)
list(new_list)运行结果:

六、filter函数
对序列中的元素进行筛选,最终获取符合条件的序列。
filter(f, S)
将条件函数f作用在序列S上,符合条件函数的则输出。
七、reduce函数
对于序列内所有元素进行累计操作。
reduce(f(x,y), S)
将序列S中的第一、第二个数用二元函数f(x,y)作用后的结果与第三个数继续用f(x,y)作用,再将这个结果与第四个数继续用f(x,y)作用,直到最后。
Reduce0)有三个参数:
第一个参数是含有两个参数的函数,即第一个参数是函数且必须含有两个参数:f(x,y)
第二个参数是作用域,表示要循环的序列:S
第三个参数是初始值
from functools import reduce
def add(x, y):
return x + y
result = reduce(add, range(1, 10))
print(result) # 输出结果运行结果:

八、eval函数
eval0函数将字符串str当成有效的表达式来求值并返回计算结果,也就是实现list、dict、tuple与str之间的转化。
#字符串转换成列表
a="[[1,2],[3,4],[5,6],[7,8],[9,0]]"
print(type(a))
b = eval(a)
print(b)运行结果:
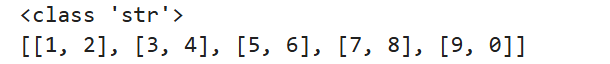
九、面向对象class
在 Python 中,所有数据类型都可以视为对象,当然也可以自定义对象。自定义的对象数据类型就是面向对象中的类(Class)的概念。
面向对象最重要的概念就是类(class)和实例(Instance),必须牢记类是抽象的板比如Employee类,而实例是根据类创建出来的一个个具体的“对象”,每个对象都拥有相同的方法,但各自的数据可能不同。在Python中,定义类是通过class关键字,以Emplovee类为例:
class Employee(object).
passclass后面紧接着是类名,即Employee,类名通常是大写开头的单词,"紧接着是(object)表示该类是从哪个类继承下来的,关于继承的概念这里不做过多说明,读者可以自行查询资料。通常,如果没有合适的继承类,就使用object类,这是所有类最终都会继承的类。
定义好了Employee类,就可以根据Employee类创建出Employee的实例,创建实例是通过类名 ()”实现的。
由于类可以起到模板的作用,因此,可以在创建实例的时候,把一些我们认为必须绑定的属性强制填写进去。通过定义一个特殊的init方法,在创建实例的时候,就把name、salary等属性绑上去。
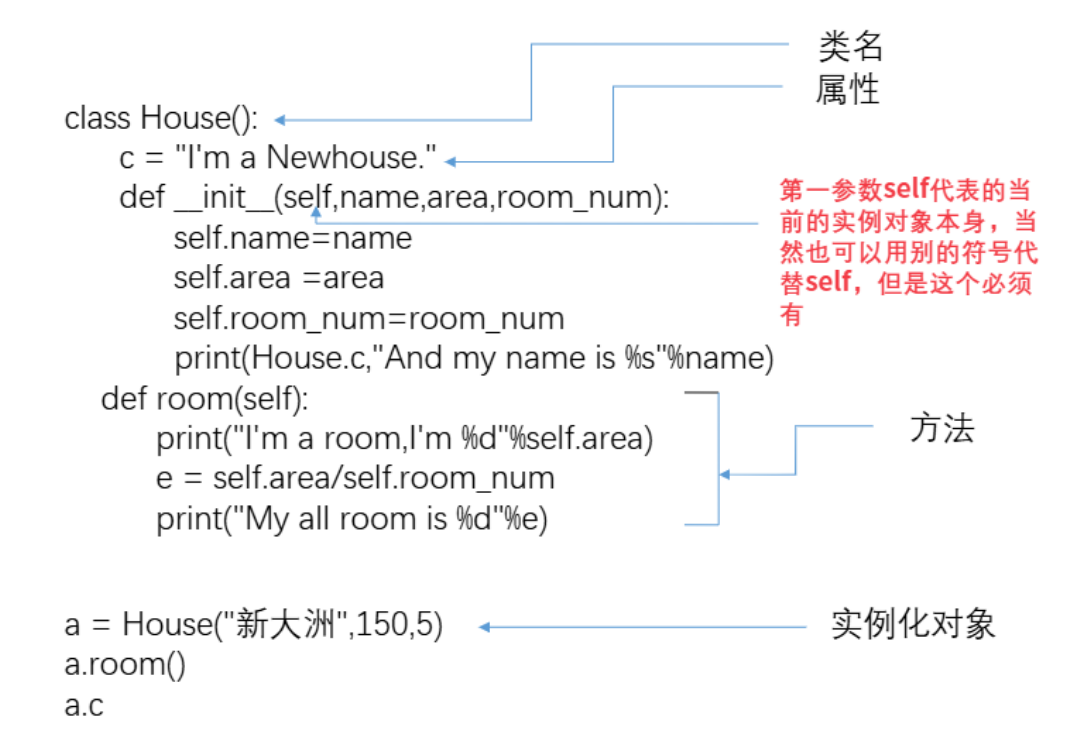
class Employee(obiect):
definit (self,name,salary):
self.name =name
self.salary=salary注意:特殊方法“init "前后分别有两个下划线!!!
注意到 init 方法的第一个参数永远是self,表示创建的实例本身,因此在_init-方法内部可以把各种属性绑定到self,因为self就指向创建的实例本身。有了init 方法,在创建实例时,就不能传入空参数了,必须传入与 init 方法匹配的参数,但self不需要传,Pvthon解释器自己会把实例变量
传进去。
类模板说明
面向对象编程有一个重要特点就是数据封装。在上面的Employee类中,每个实例就拥有各自的name和salary这些数据。我们可以通过函数来访问这些数据,比如打印一个员工的工资。
:def print salary(std):
print('号s:号s'号std.name,std.salary))
print salary(amy)既然Emplovee实例本身就拥有这些数据,访问这些数据就没有必要从外部的函数去访问,可以直接在Employee类的内部定义访问数据的函数,这样就把“数据"给封装起来了。这些封装数据的函数是和Employee类本身是关联起来的,我们称之为类的方法。
class Employee(object):
definit (self,name,salary):self.name =nameself.salary=salary
def print salary(self):
print('号s:号s'号(self.name,self.salary))要定义一个方法,除了第一个参数是self外,其他和普通函数一样。要调用一个方法,只需要在实例变量上直接调用,除了self不用传递,其他参数正常传入。
amy.print salary()通过上面的操作,我们从外部看Employee类,创建实例只需要给出name和salary,而如何打印都是在Employee类的内部定义的,这些数据和逻辑被“封装”起来了,很容易调用,但却不用知道内部实现的细节。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









