






本文介绍了Slurm HPC与Kubernetes融合的负载调度策略,旨在通过优化资源配置与作业调度机制,不仅能提升计算资源的利用率,还增强了系统整体的稳定性和运行效能。此方案确保在满足多种计算场景需求的同时,为您构建一个更为高效且灵活的计算平台。
方案概述
为什么要提出在ACK集群上实现Slurm HPC & Kubernetes负载混合调度呢?
-
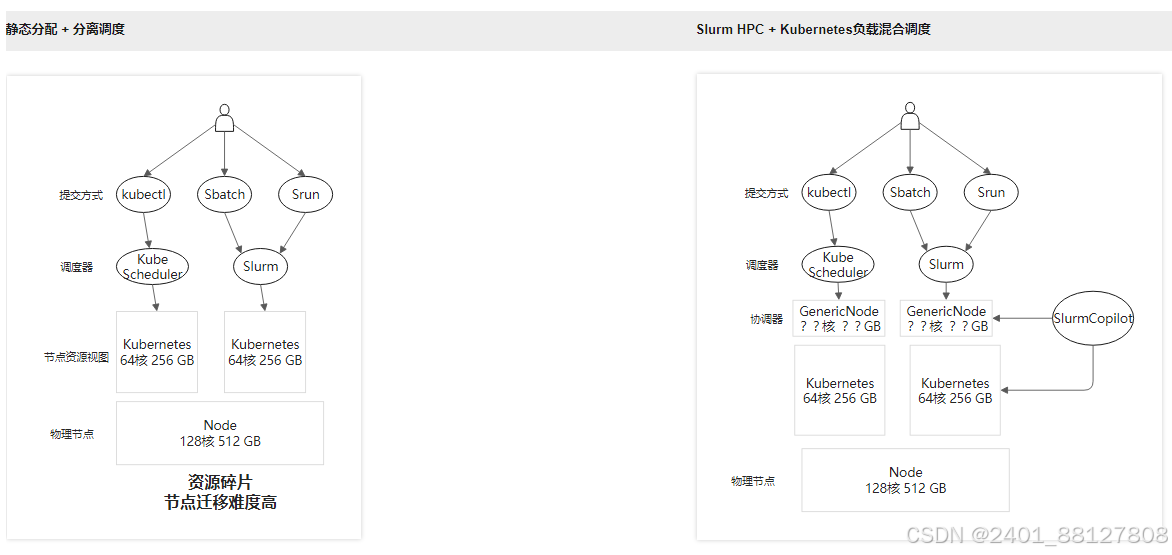
原因分析:目前ACK会提供静态分配+分离调度的方案,但是由于每个Slurm Pod的规格固定,且Slurm Pod属于提前占用集群资源,Slurm集群中资源空闲时Kubernetes无法使用这些已占用的集群资源,从而导致集群资源碎片。此外,修改Slurm Pod的资源规格需要删除Pod重建,因此在Slurm与Kubernetes资源占用变化较大的场景中,节点迁移的难度较大。
-
改进方案:考虑到现有方案的弊端,ACK Slurm Operator提供一种Slurm & Kubernetes混合调度方案,通过配置运行在Kubernetes集群中的协调器以及Slurm集群的扩展资源插件,使得Kubernetes与Slurm可以共享集群资源,并且避免在分配资源时出现重复分配的情况。
目前任务共享资源方案可以分为以下两种。
Slurm HPC + Kubernetes负载混合调度方案的运行原理如下图所示。
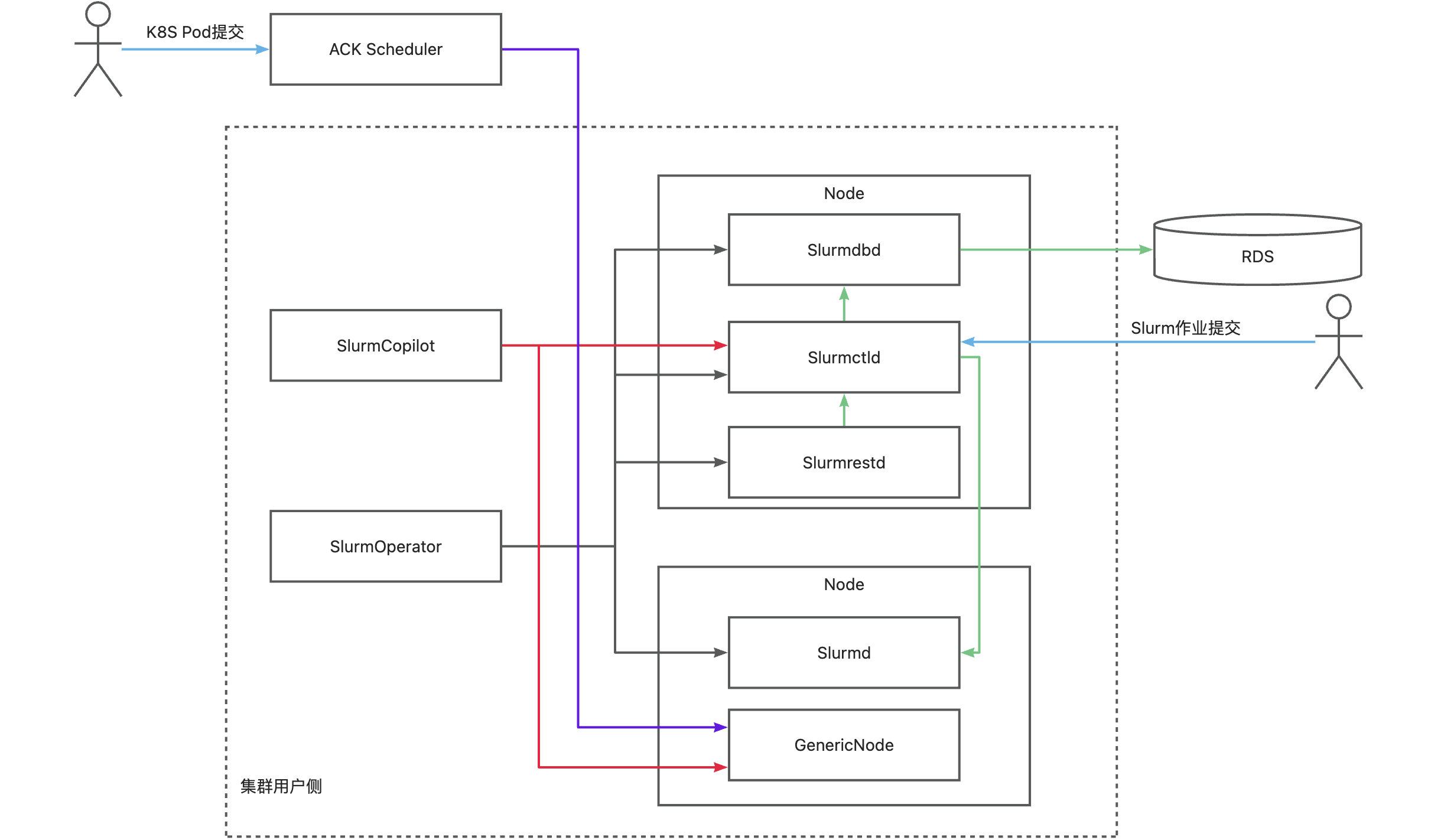
| 核心组件 | 描述 |
| SlurmOperator | 负责在集群中以容器化形式拉起Slurm集群。集群会以容器化的方式运行,运行Slurm的Worker Pod会以互斥的方式运行在不同集群节点上,其他的Slurm系统组件会随机运行在集群节点上。 |
| SlurmCopilot | 使用集群Token(默认启动Slurmctld时会自动生成Token并通过kubectl更新到secret中,可通过自定义启动脚本或取消更新secret权限修改此行为,修改后需要手动更新Toekn至ack-slurm-operator空间下的ack-slurm-jwt-token, Data中以ClusterName为Key,以Token base64 --wrap=0后的结果为value)与Slurmctld进行资源协调通信。负责在AdmissionCheck被添加到GenericNode上后,修改Slurmctld中对应节点的可用资源量,成功修改可用资源量后将状态写回GenericNode,通知ACK Scheduler完成调度。 |
| Slurmctld | slurm的中心管理器,负责监测集群的资源和作业,以及进行作业的调度和分配。为了提高可用性,还可以配置一个备份的slurmctld。 |
| GenericNodes | 是一种自定义资源,作为Kubernetes和Slurm的中间账本。ACK Scheduler调度一个Pod到节点上之前,会在GenericNode上新增AdmissionCheck,请求Slurm系统确认资源。 |
| Slurmd | slurm的节点守护进程,运行在每个计算节点上,负责执行作业,以及向slurmctld汇报节点和作业的状态。 |
| Slurmdbd | slurm的数据库守护进程,负责存储和管理作业的记账信息,以及提供查询和统计的接口。slurmdbd是可选的,也可以将记账信息存储在文件中。 |
| Slurmrested | slurm的REST API守护进程,提供了一种通过REST API与slurm进行交互的方式,可以实现slurm的所有功能。slurmrestd是可选的,也可以通过命令行工具与slurm进行交互。 |
1. 环境准备
1.1 安装ack-slurm-operator组件
确认已安装的ACK集群版本为v1.26及以上。具体操作,请参见创建GPU集群、升级集群。
安装ack-slurm-operator组件并开启Copilot功能,实现Slurm任务与Kubernetes Pod在同一批物理机器上混合部署。
-
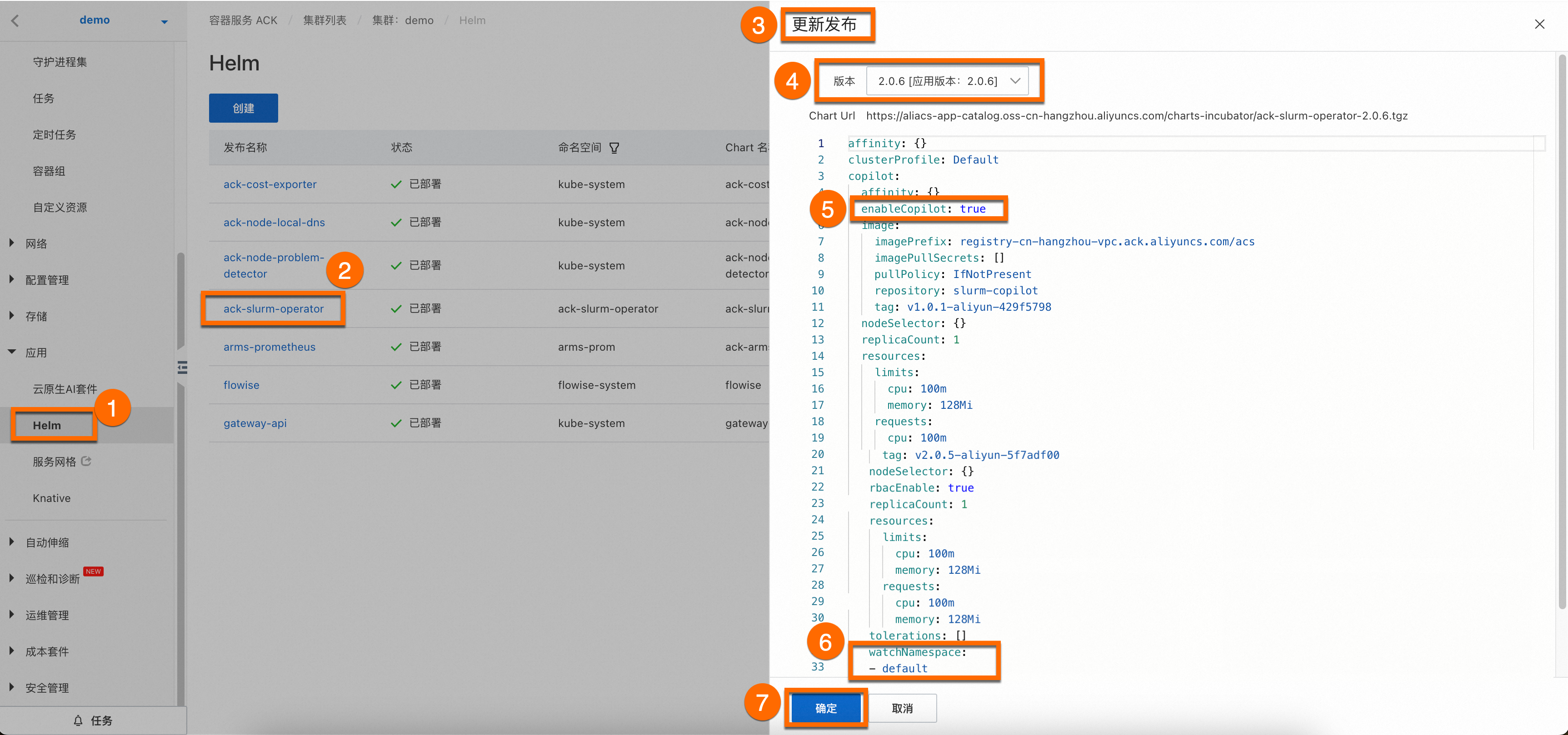
登录容器服务管理控制台。单击目标集群名称,进入集群详情页面,如下图所示,按照序号依次单击,为目标集群安装ack-slurm-operator组件。
您无需为组件配置应用名和命名空间,单击④下一步后会出现一个请确认弹框,单击是,即可使用默认的应用名(ack-slurm-operator)和命名空间(ack-slurm-operator)。
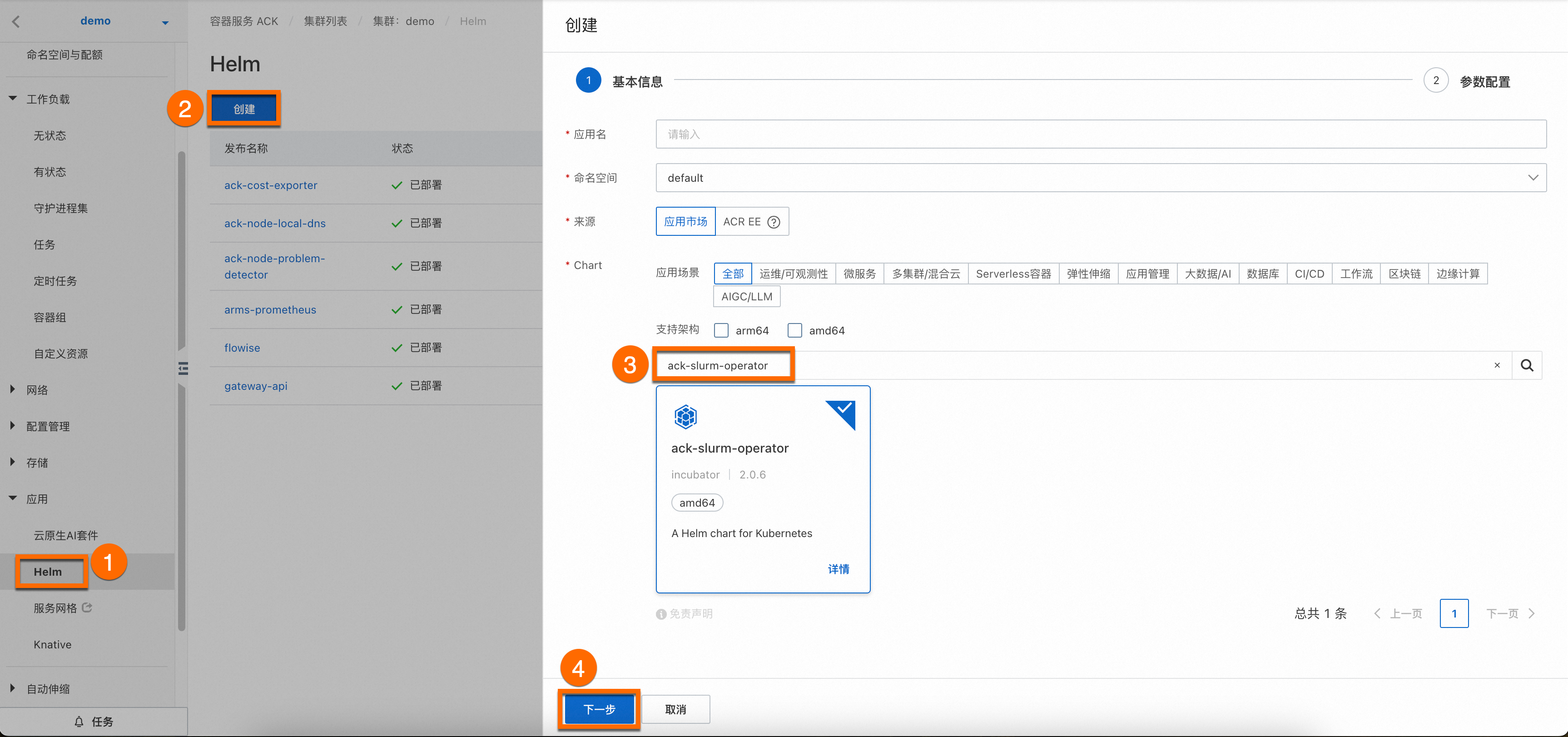
-
然后选择Chart 版本为最新版本,并将②参数
enableCopilot设置为true,并设置③watchNamespace为default(您也可以根据需要自主设置命名空间),单击确定即可完成ack-slurm-operator组件安装。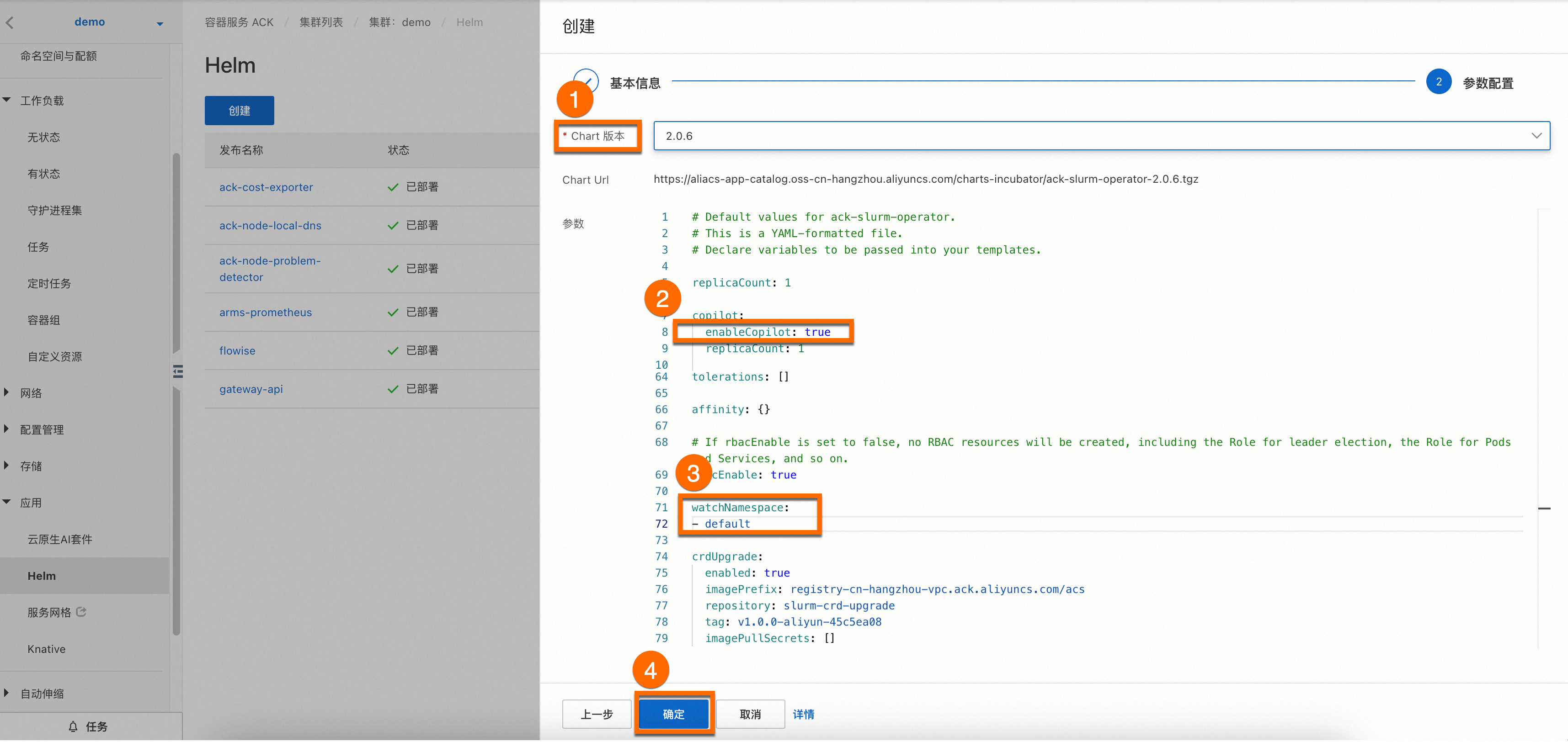
-
(可选)更新ack-slurm-operator组件操作步骤。
登录容器服务管理控制台。在集群信息页面,单击应用 > Helm页签,在应用页面找到ack-slurm-operator组件,然后点击更新。
1.2 安装配置ack-slurm-cluster组件
如需快速安装、管理SlurmCluster,以及灵活调整集群配置,您可以使用Helm软件包管理器来部署阿里云提供的SlurmClusterart。从charts-incubator中下载由阿里云包装好的SlurmCluster的Helm,设置好相应的参数后,Helm会帮助您创建出RBAC、Configmap、Secret以及SlurmCuster等资源。
展开查看Helm Chart资源及参数说明
具体操作如下所示:
-
执行以下命令,将阿里云Helm仓库添加到您的Helm客户端。该操作将允许您访问阿里云提供的各种Charts,包括ack-slurm-cluster组件。
helm repo add aliyun https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/charts-incubator/ -
执行以下命令,拉取并解压ack-slurm-cluster组件。该操作将会在当前目录下创建一个名为
ack-slurm-cluster的目录,其中包含了Chart的所有文件和模板。helm pull aliyun/ack-slurm-cluster --untar=true -
执行以下命令,在名为values.yaml的文件中修改Chart参数。
values.yaml文件包含了Chart的默认配置。您可以根据您的实际需求通过编辑这个文件来修改参数。例如Slurm的配置、资源请求与限制、存储等。
cd ack-slurm-cluster vi values.yaml展开查看如何生成JWT并提交到集群中
展开查看如何声明数据库地址和配置gres
展开查看如何设置Slurmrestd Pod和Slurmdbd Pod相关配置
-
使用Helm安装Chart,执行以下命令将会部署ack-slurm-cluster组件。(如果已经安装了ack-slurm-cluster,可以使用helm upgrade命令更新helm chart。更新后需要手动清理已有Pod以及Slurmctld的StatefulSet完成配置更新。)
cd .. helm install my-slurm-cluster ack-slurm-cluster # my-slurm-cluster可以根据实际情况进行更改。 -
通过Helm安装之后可以通过Helm list查看当前的ack-slurm-cluster是否完成安装。
Helm list预期输出结果如下。
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION ack-slurm-cluster default 1 2024-07-19 14:47:58.126357 +0800 CST deployed ack-slurm-cluster-2.0.0 2.0.0 -
验证Slurmrestd & Slurmdbd正常启动
-
通过kubectl连接集群查看slurmdbd Pod是否正常启动。
kubectl get pod预期输出结果如下,可以看到此时集群中有1个Worker节点和3个控制面组件的Pod。
NAME READY STATUS RESTARTS AGE slurm-test-slurmctld-dlncz 1/1 Running 0 3h49m slurm-test-slurmdbd-8f75r 1/1 Running 0 3h49m slurm-test-slurmrestd-mjdzt 1/1 Running 0 3h49m slurm-test-worker-cpu-0 1/1 Running 0 166m -
执行以下命令查看日志信息,了解Slurmdbd是否已经正常启动。
kubectl exec slurm-test-slurmdbd-8f75r cat /var/log/slurmdbd.log | head预期输出结果如下。
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead. [2024-07-22T19:52:55.727] accounting_storage/as_mysql: _check_mysql_concat_is_sane: MySQL server version is: 8.0.34 [2024-07-22T19:52:55.737] error: Database settings not recommended values: innodb_lock_wait_timeout [2024-07-22T19:52:56.089] slurmdbd version 23.02.7 started
-
如果您需要在Slurm中扩展安装其他依赖软件,您可以展开查看下述内容。
展开查看制作Slurm通用镜像步骤
2. 验证拓展负载混合调度功能
2.1 验证负载混合调度功能
-
查看genericnode状态,可以看到Slurm与Kubernetes的负载状态。
kubectl get genericnode预期输出结果如下。
NAME CLUSTERNAME ALIAS TYPE ALLOCATEDRESOURCES cn-hongkong.10.1.0.19 slurm-test-worker-cpu-0 Slurm [{"allocated":{"cpu":"0","memory":"0"},"type":"Slurm"},{"allocated":{"cpu":"1735m","memory":"2393Mi"},"type":"Kubernetes"}] -
提交一个任务到Slurm集群中,相关命令和预期输出结果如下,可以看到Kubernetes的任务和Slurm的任务资源使用量都反映在了GenericNode上。
root@iZj6c1wf3c25dbynbna3qgZ ~]# kubectl exec slurm-test-slurmctld-dlncz -- nohup srun --cpus-per-task=3 --mem=4000 --gres=k8scpu:3,k8smemory:4000 sleep inf & [1] 4132674 [root@iZj6c1wf3c25dbynbna3qgZ ~]# kubectl scale deployment nginx-deployment-basic --replicas 2 deployment.apps/nginx-deployment-basic scaled [root@iZj6c1wf3c25dbynbna3qgZ ~]# kubectl get genericnode NAME CLUSTERNAME ALIAS TYPE ALLOCATEDRESOURCES cn-hongkong.10.1.0.19 slurm-test-worker-cpu-0 Slurm [{"allocated":{"cpu":"3","memory":"4000Mi"},"type":"Slurm"},{"allocated":{"cpu":"2735m","memory":"3417Mi"},"type":"Kubernetes"}] -
此时再提交一个任务到Slurm集群中,可以看到第2个提交的任务进入了PD(Pending)状态。
[root@iZj6c1wf3c25dbynbna3qgZ ~]# kubectl exec slurm-test-slurmctld-dlncz -- nohup srun --cpus-per-task=3 --mem=4000 sleep inf & [2] 4133454 [root@iZj6c1wf3c25dbynbna3qgZ ~]# srun: job 2 queued and waiting for resources [root@iZj6c1wf3c25dbynbna3qgZ ~]# kubectl exec slurm-test-slurmctld-dlncz -- squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 2 debug sleep root PD 0:00 1 (Resources) 1 debug sleep root R 2:34 1 slurm-test-worker-cpu-0
在上述的srun的示例中,我们并没有指定gres扩展资源,是由于在slurm集群启动时已经加载了job_resource_completion插件,该插件会自动根据cpu和mem的请求量生成对应的gres资源量。如果没有开启该插件,您需要手动指定,本例中需要指定的额外参数为--gres=k8scpu:3,k8smemory:4000。如果您需要了解关于Slurm任务脚本参数是如何设置的,您可以展开查看下述内容。
展开查看Slurm任务脚本示例解析
(可选)2.2 拓展混合调度功能-非容器化Slurm集群
由于SlurmCopilot通过Slurm的OpenAPI与Slurm进行交互,所以在非容器化场景中,SlurmCopilot同样可以使用。
针对非容器化场景,Kubernetes中的部分资源需要手动进行创建,除上文中可能需要手动创建的Token之外,需要手动创建的资源如下。
-
为每个SlurmCluster创建SVC。
SlurmCopilot会从集群中获取Service信息,并向
${.metadata.name}.${.metadata.namespace}.svc.cluster.local:${.spec.ports[0].port}发出OpenAPI请求,在非容器化场景中,需要为每个SlurmCluster创建对应的SVC,示例如下,必须要注意的是SVC的Name必须是${slurmCluster}-slurmrestd,该${slurmCluster}需要能够与GenericNode中相对应。apiVersion: v1 kind: Service metadata: name: slurm-slurmrestd namespace: default spec: ports: - name: slurmrestd port: 8080 protocol: TCP targetPort: 8080 -
为每个SlurmCluster创建DNS解析。
为了能访问到对应的Slurmrestd进程,需要在SlurmCopilot中创建对
${.metadata.name}.${.metadata.namespace}.svc.cluster.local:${.spec.ports[0].port}的地址解析,解析结果为Slurmrestd的进程地址。 -
Slurm节点对应的GenericNode资源。
GenericNode用于给SlurmCopilot提供节点在Slurm集群内的别名,否则SlurmCopilot将无法获取到Slurm中该节点的具体信息。其中GenericNode的Name必须与Kubernetes的节点名对应,
.spec.alias必须与Slurm中该节点的命名对应,而标签中的kai.alibabacloud.com/cluster-name以及kai.alibabacloud.com/cluster-namespace需要与SVC的信息对应。apiVersion: kai.alibabacloud.com/v1alpha1 kind: GenericNode metadata: labels: kai.alibabacloud.com/cluster-name: slurm-test kai.alibabacloud.com/cluster-namespace: default name: cn-hongkong.10.1.0.19 spec: alias: slurm-test-worker-cpu-0 type: Slurm
总结
在Slurm HPC和容器化工作负载的混合调度环境中,使用Slurm作为HPC调度程序和Kubernetes作为容器编排工具,您可以利用Kubernetes的大量生态系统和服务,例如Helm Charts、CI/CD流水线、监控工具,以及相同的作业调度和管理界面提交HPC作业和容器化工作负载。实现将HPC作业和Kubernetes容器工作负载整合到同一个集群中,更有效地利用硬件资源。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









