







深度学习目标检测中_如何实现基于YOLOv8的婴儿检测系统,对婴儿肢体动作的攀爬,卧倒,坐立进行识别
文章代码及文字仅供参考。
基于YOLOv8的婴儿检测系统,婴儿行为检测,婴儿肢体检测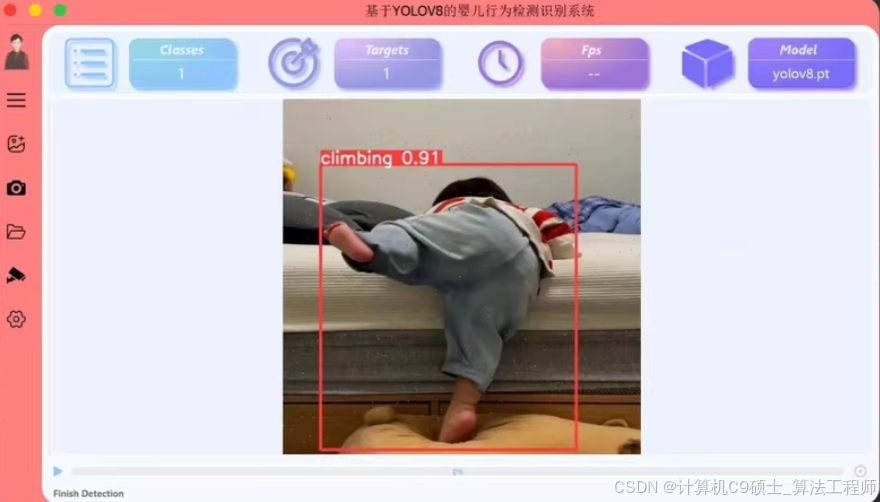
基于Python3.8、PyTorch1.8.0,使用PyQt5框架进行开发。系统的主要功能依赖于用户所提供的图片、视频以及摄像头所获取的实时影像,并结合经大量图像数据所训练得到的神经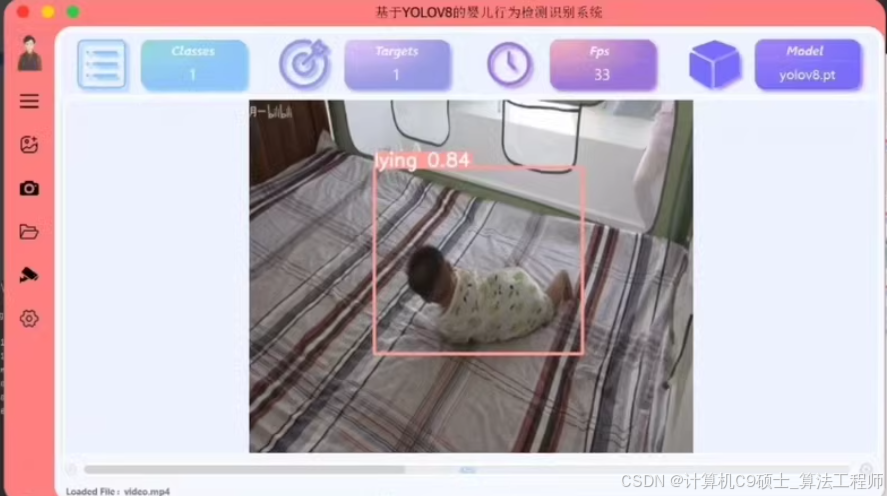
基于YOLOv8的婴儿检测系统,包括婴儿行为和肢体检测,涉及多个步骤:从数据集准备、模型训练到可视化及评估。
数据集准备
- 收集数据:首先需要收集大量的婴儿图片或视频片段,确保覆盖各种可能的行为和姿势。
- 标注数据:使用如LabelImg等工具对图像进行标注,生成YOLO格式的标签文件(即每张图片对应的
.txt文件,包含每个对象的类别ID和边界框坐标)。 - 划分数据集:将数据集划分为训练集、验证集和测试集,通常比例为7:2:1。
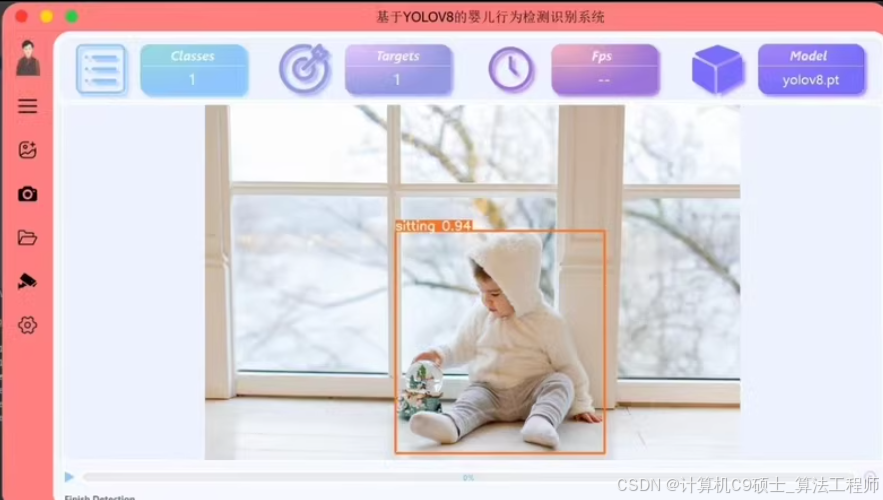
环境配置
确保安装了Python 3.8以及PyTorch 1.8.0。此外,还需要安装其他依赖项:
pip install pyqt5 opencv-python-headless matplotlib
模型训练
假设YOLOv8已经适配并准备好用于婴儿检测任务,下面是一个简化的训练流程示例:
import torch
from yolov8 import YOLOv8 # 假设YOLOv8是已有的模块
# 初始化模型
model = YOLOv8()
# 加载预训练权重(可选)
model.load_weights('path/to/pretrained/weights')
# 定义数据加载器
train_loader = ... # 根据实际情况定义
val_loader = ...
# 设置优化器和损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
loss_fn = ... # 根据实际情况定义
# 开始训练
for epoch in range(num_epochs):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
# 验证阶段
model.eval()
with torch.no_grad():
for data, target in val_loader:
output = model(data)
# 计算验证损失或其他指标
可视化与评估
为了在PyQt5中集成YOLOv8模型的预测结果,你可以创建一个简单的GUI应用来展示检测结果。以下是一个基本框架:
from PyQt5.QtWidgets import QApplication, QLabel, QVBoxLayout, QWidget
from PyQt5.QtGui import QImage, QPixmap
import sys
import cv2
import numpy as np
class InfantDetectionApp(QWidget):
def __init__(self):
super().__init__()
self.initUI()
def initUI(self):
self.layout = QVBoxLayout()
self.label = QLabel(self)
self.layout.addWidget(self.label)
self.setLayout(self.layout)
def update_image(self, img):
height, width, channel = img.shape
bytesPerLine = 3 * width
qImg = QImage(img.data, width, height, bytesPerLine, QImage.Format_RGB888).rgbSwapped()
self.label.setPixmap(QPixmap.fromImage(qImg))
def detect_infant(self, image_path):
img = cv2.imread(image_path)
# 调用YOLOv8模型进行预测,并绘制边界框
# predictions = model.predict(img)
# 绘制代码...
self.update_image(img)
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = InfantDetectionApp()
ex.show()
# 示例调用
ex.detect_infant('path/to/image.jpg')
sys.exit(app.exec_())
构建一个基于YOLOv8的婴儿检测系统,包括从环境配置到运行整个系统的详细步骤。考虑到YOLOv8并不是一个官方发布的版本(截至2025年初),以下指南将基于假设YOLOv8是YOLO系列的一个新版本,并且其API与之前的版本相似。我们将使用Python 3.8、PyTorch 1.8.0以及PyQt5框架进行开发。
环境配置
首先,确保你的环境中已安装必要的库:
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio===0.8.0 -f https://download.pytorch.org/whl/torch_stable.html
pip install opencv-python-headless PyQt5 matplotlib
注意:请根据自己的GPU/CPU情况选择合适的PyTorch版本。
数据集准备
对于婴儿行为和肢体检测的数据集,你可以从公开数据集中收集相关数据或自己创建一个。确保每张图片都有对应的标签文件,格式为YOLO所需的<class> <x_center> <y_center> <width> <height>。
模型训练
假设你已经有了YOLOv8的实现代码,以下是简化版的模型训练脚本:
import torch
from yolov8 import YOLOv8 # 假设这是一个自定义模块
# 初始化模型
model = YOLOv8()
# 加载预训练权重(可选)
if pretrained_weights_path:
model.load_state_dict(torch.load(pretrained_weights_path))
# 定义数据加载器
from dataset_loader import load_data # 自定义的数据加载函数
train_loader, val_loader = load_data(train_images_path, train_labels_path, val_images_path, val_labels_path)
# 设置优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 开始训练循环
num_epochs = 50
for epoch in range(num_epochs):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = compute_loss(output, target) # 需要实现compute_loss函数
loss.backward()
optimizer.step()
# 验证阶段略...
# 保存模型
torch.save(model.state_dict(), 'yolov8_infant_detection.pth')
可视化及评估
接下来,我们将集成YOLOv8到PyQt5应用中,用于实时视频流中的婴儿检测:
from PyQt5.QtWidgets import QApplication, QLabel, QVBoxLayout, QWidget
from PyQt5.QtGui import QImage, QPixmap
import sys
import cv2
import numpy as np
import torch
class InfantDetectionApp(QWidget):
def __init__(self, model):
super().__init__()
self.model = model
self.initUI()
def initUI(self):
self.layout = QVBoxLayout()
self.label = QLabel(self)
self.layout.addWidget(self.label)
self.setLayout(self.layout)
def update_image(self, img):
height, width, channel = img.shape
bytesPerLine = 3 * width
qImg = QImage(img.data, width, height, bytesPerLine, QImage.Format_RGB888).rgbSwapped()
self.label.setPixmap(QPixmap.fromImage(qImg))
def detect_and_update(self, frame):
# 使用YOLOv8模型预测
predictions = self.model.predict(frame)
# 根据predictions在frame上绘制边界框
# 绘制逻辑略...
self.update_image(frame)
if __name__ == '__main__':
app = QApplication(sys.argv)
# 加载训练好的模型
model = YOLOv8() # 初始化模型
model.load_state_dict(torch.load('yolov8_infant_detection.pth'))
ex = InfantDetectionApp(model)
ex.show()
# 实时视频流处理
cap = cv2.VideoCapture(0) # 打开摄像头
while True:
ret, frame = cap.read()
if not ret:
break
ex.detect_and_update(frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
sys.exit(app.exec_())



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









