






利用yolov8 Mask R-CNN处理水下侧扫声呐图像数据集 目标检测和实例分割。处理识别水下侧扫声呐图像沉船数据集
文章目录
以下文字及代码仅供参考。
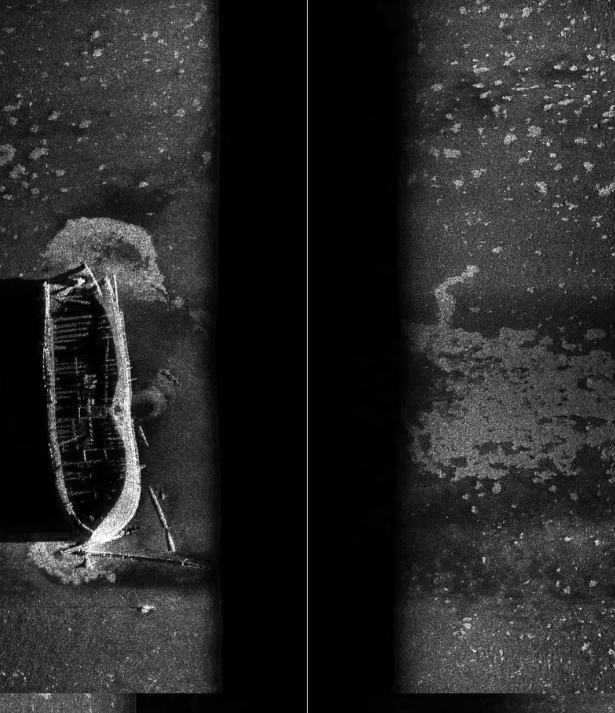
水下侧扫声呐图像数据集,沉船,png标签格式
 1
1

由于这些图像具有独特的特征和挑战(如低对比度、噪声等),需要一个能够有效处理这类数据的模型。
1. 数据预处理
在开始训练之前,确保对数据进行适当的预处理:
- 归一化:将像素值归一化到[0, 1]或[-1, 1]范围内。
- 增强:使用旋转、翻转、缩放等方法增加数据多样性。
- 去噪:应用滤波器减少图像中的噪声。
2. 模型选择
YOLOv8
YOLOv8目标检测模型,适用于实时检测任务。它在速度和准确性之间取得了良好的平衡,并且可以很好地处理各种类型的图像数据。
from ultralytics import YOLO
# 加载YOLOv8模型
model = YOLO('yolov8n.yaml') # 使用YOLOv8 nano架构作为示例
# 开始训练
results = model.train(data='path/to/data.yaml', epochs=100, imgsz=640, batch=16)
Mask R-CNN
需要检测沉船的位置,还需要分割出沉船的具体区域,Mask R-CNN是一个很好的选择。它可以同时进行目标检测和实例分割。
import torch
from torchvision.models.detection import maskrcnn_resnet50_fpn
# 加载Mask R-CNN模型
model = maskrcnn_resnet50_fpn(pretrained=True)
# 将模型设置为训练模式
model.train()
# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 训练循环
for epoch in range(num_epochs):
for images, targets in dataloader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
3. 训练过程
数据集划分
将数据集划分为训练集、验证集和测试集,通常比例为70%、15%和15%。
配置文件
创建一个data.yaml文件来描述你的数据集路径和类别信息:
train: ./dataset/images/train/
val: ./dataset/images/val/
nc: 1 # 类别数量(假设只有沉船一类)
names: ['Shipwreck'] # 类别名称
训练参数调整
根据数据集的特点和硬件资源,调整训练参数,如学习率、批次大小、输入图像尺寸等。
4. 性能评估
在验证集上评估模型性能,并根据结果调整模型和训练策略。
metrics = model.val() # 在验证集上评估模型性能
print(f"Model mAP: {metrics.box.map}") # 输出mAP值
利用训练好的权重建立侧扫声纳图像检测系统,
1. 环境准备
确保你的环境中安装了所有必要的依赖库。对于YOLOv8,可以这样安装:
pip install ultralytics opencv-python-headless
2. 加载训练好的模型权重
首先,你需要加载之前训练好的YOLOv8模型权重。假设你已经保存了训练好的模型文件(如best.pt)。
from ultralytics import YOLO
# 加载训练好的模型权重
model = YOLO('path/to/your/best.pt') # 替换为你的模型权重文件路径
3. 模型推理
单张图片推理
下面是一个对单张图片进行推理的例子:
import cv2
def detect_image(image_path):
results = model.predict(source=image_path, save=True, conf=0.25) # 设置置信度阈值
for result in results:
img = cv2.imread(image_path)
for box in result.boxes:
x1, y1, x2, y2 = [int(x) for x in box.xyxy]
cls = int(box.cls.item())
label = f'{result.names[cls]} {box.conf.item():.2f}'
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(img, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv2.imshow('Detected Image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
detect_image('path/to/test_image.png') # 替换为你的测试图片路径
批量推理
如果你想对整个目录中的图片进行批量处理,可以这样做:
import os
def detect_images_in_dir(directory_path):
"""
对指定目录下的所有图片进行推理。
:param directory_path: 存放待检测图片的目录路径
"""
for filename in os.listdir(directory_path):
if filename.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.gif')): # 支持的图片格式
image_path = os.path.join(directory_path, filename)
results = model.predict(source=image_path, save=True, conf=0.25) # 设置置信度阈值
for result in results:
img = cv2.imread(image_path)
for box in result.boxes:
x1, y1, x2, y2 = [int(x) for x in box.xyxy]
cls = int(box.cls.item())
label = f'{result.names[cls]} {box.conf.item():.2f}'
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(img, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv2.imshow('Detected Image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 调用函数处理特定目录下的所有图片
detect_images_in_dir('path/to/test_dir/') # 替换为你的测试图片目录路径
4. 构建用户界面
为了让系统更加用户友好,可以考虑构建一个简单的图形用户界面(GUI)。这里给出一个简单的Tkinter例子来打开本地图片并显示检测结果:
import tkinter as tk
from tkinter import filedialog
from PIL import Image, ImageTk
def open_image():
file_path = filedialog.askopenfilename()
if not file_path:
return
results = model.predict(source=file_path, save=False)
img = Image.open(file_path)
img = img.resize((600, 600)) # 根据需要调整大小
img_tk = ImageTk.PhotoImage(img)
# 假设你已经将预测结果绘制回原图
panel.configure(image=img_tk)
panel.image = img_tk
root = tk.Tk()
panel = tk.Label(root)
panel.pack(pady=10)
btn = tk.Button(root, text="Open Image", command=open_image)
btn.pack(side="bottom")
root.mainloop()
5. 部署
-
导出模型:为了方便部署,可以将模型导出为ONNX或其他适合部署的格式。
success = model.export(format="onnx") -
Web服务:利用Flask或FastAPI创建一个RESTful API服务,接收上传的图片并返回检测结果。
-
移动应用:通过TensorFlow Lite或者ONNX Runtime将模型部署到移动端。
基于训练好的YOLOv8权重建立一个侧扫声纳图像检测系统。这个系统不仅能对单一图像做出准确的分类,还能扩展为支持批量处理、GUI交互以及多种部署方式



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









