






采用Python语言,通过训练情绪识别数据集 基于深度学习中的卷积神经网络(CNN)实现语音情绪识别。基于深度学习的语音情绪识别。建立识别7种情绪基于深度学习的语音情绪识别
代码仅供参考。
文章目录
以下文字及代码仅供参考。
附源码和数据集和运行结果
能识别出sad,happy,等7种情绪
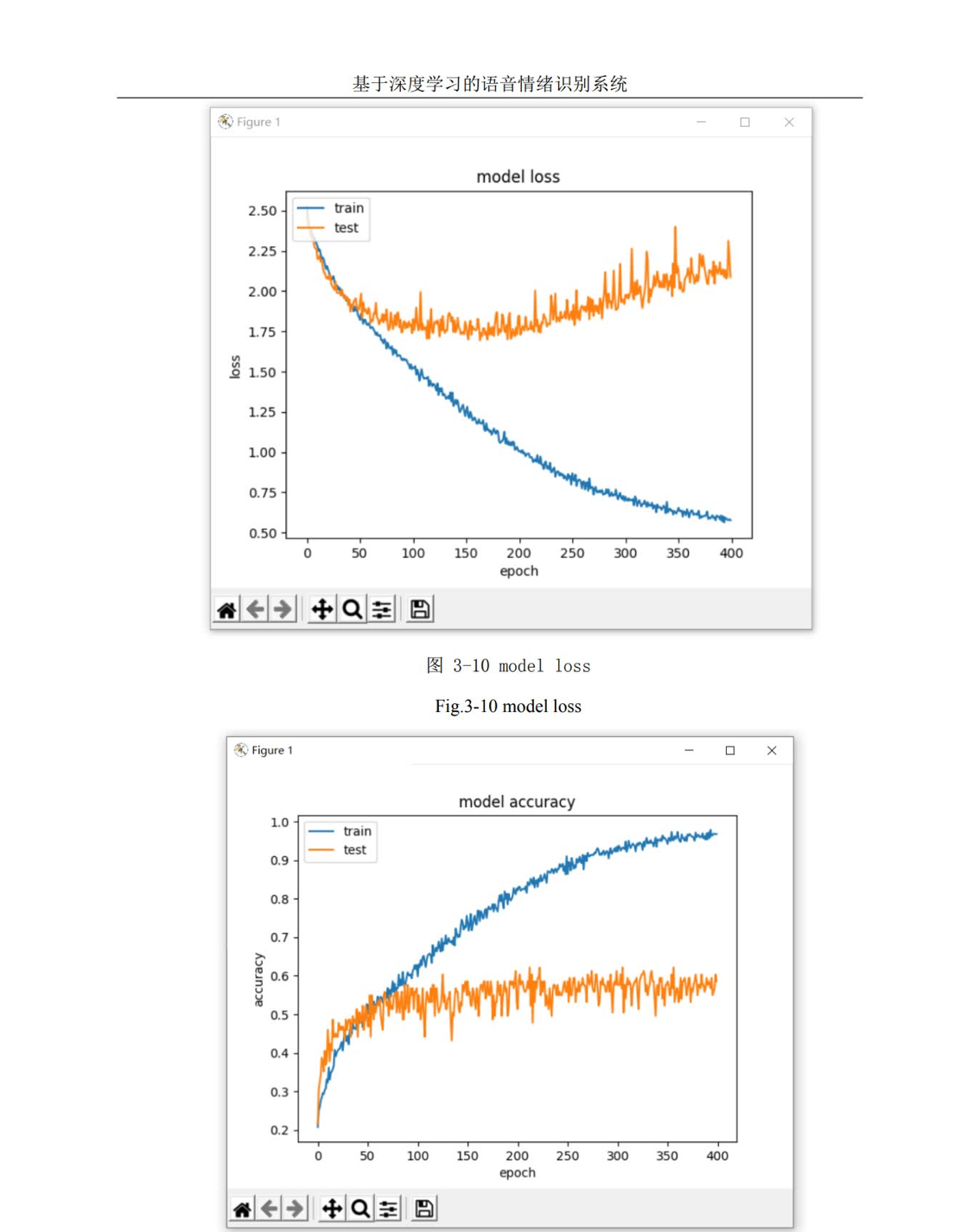
采用的Python语言,基于深度学习的语音情绪识别。使用的神经网络是卷积神经网络CNN。首先先设计出了一个卷积神经网络,感觉还不太完善,就对其神经网络进行改进,得到了一个更完善的神经网络,显著的提高了模型的准确率
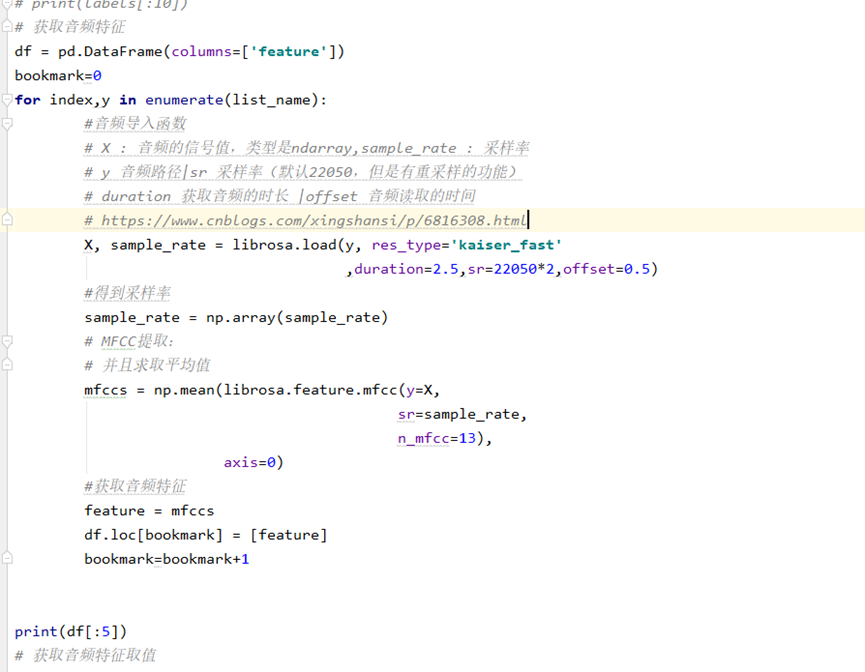
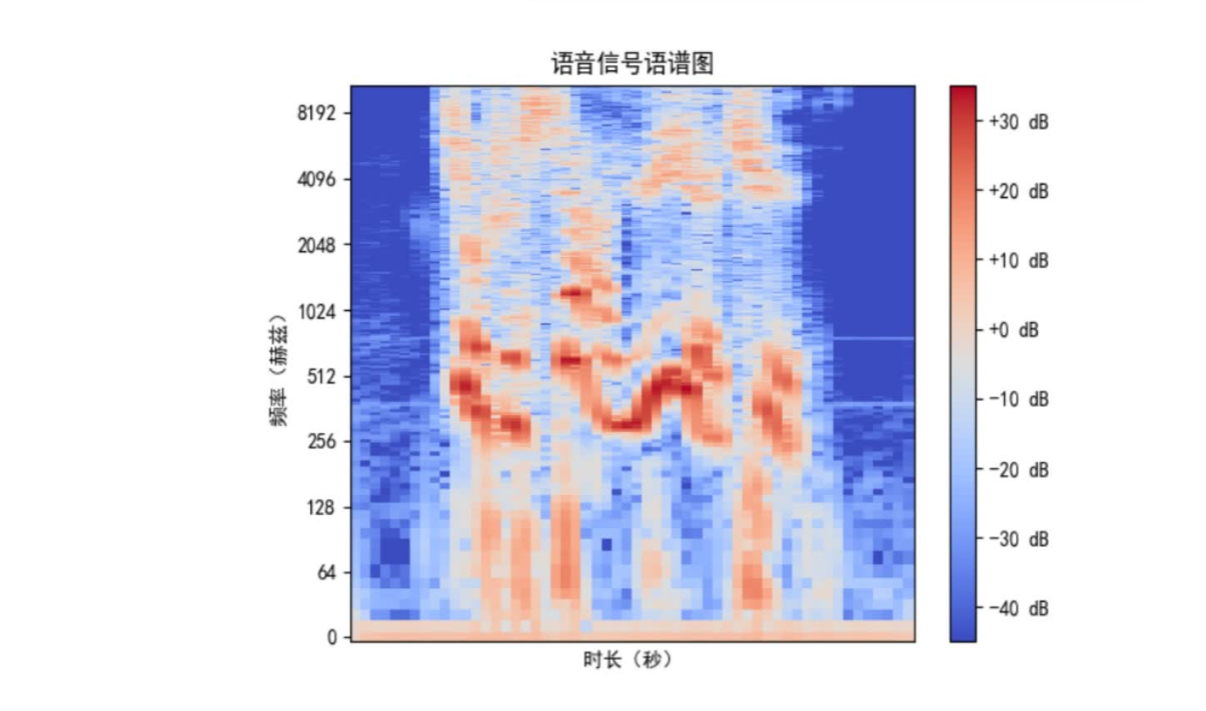
上图为语音信号特征提取
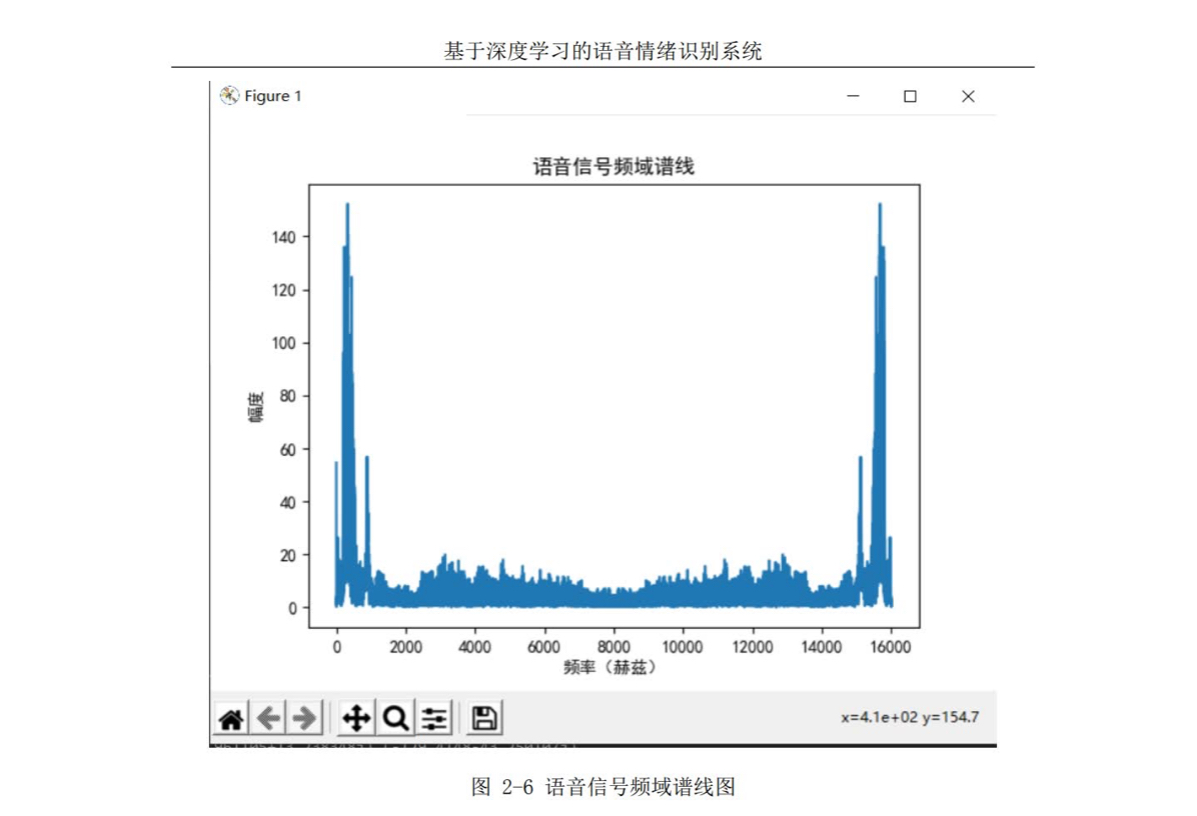
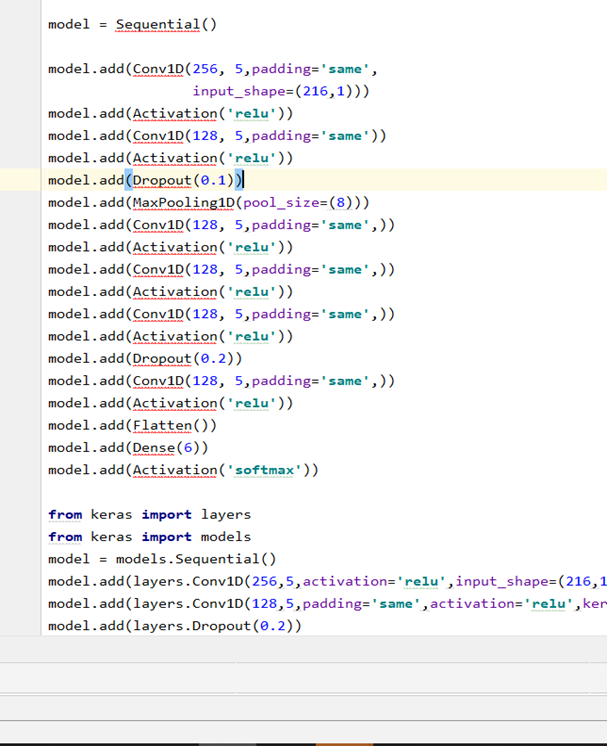
上图为卷积神经网络
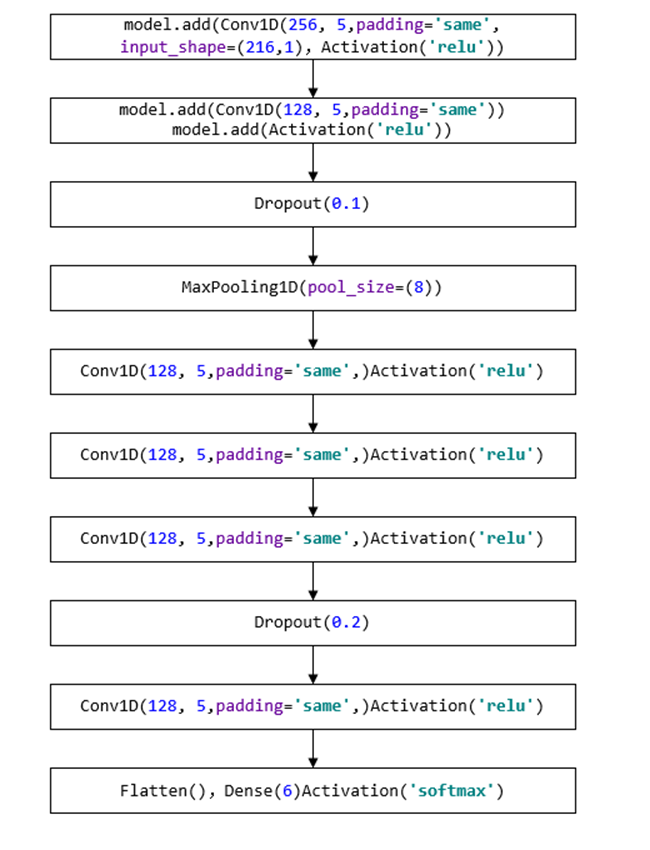
上图卷积神经网络示意图
采用的 Python 语言, 基于深度学习的语音情绪识别。使用 的神经网络是卷积神经网络 CNN 。 首先先设计出了一个卷积神经网络, 感觉还不 太完善, 就对其神经网络进行改进,得到了一个更完善的神经网络,显著的提高 了模型的准确率。 为了完成我的实验设计,我首先学习了语音情绪识别所要解决的问题。 1. 语 音信号的基本参数,语音信号在计算机中的存储。 2. 语音信号预处理。 3. 语音信 号特征提取。 4. 神经网络的学习,特别是卷积神经网络,本实验中用到的神经网 络就是卷积神经网络。
1
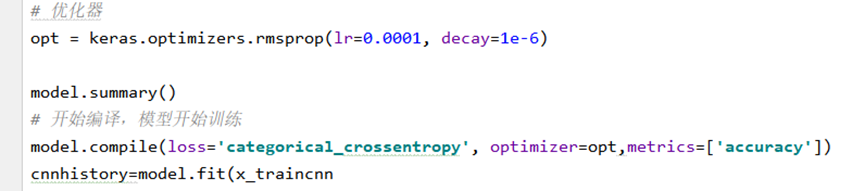
上图为优化器
基于深度学习的语音情绪识别
使用Python语言,基于深度学习中的卷积神经网络(CNN)实现语音情绪识别。该系统能够识别7种情绪:sad, happy, angry, fearful, disgusted, surprised 和 neutral。
一、环境配置
pip install numpy pandas librosa matplotlib tensorflow keras
二、数据集
推荐使用RAVDESS(The Ryerson Audio-Visual Database of Emotional Speech and Song)数据集,它包含24位专业演员演绎的7种基本情绪,共1440个音频文件。
三、技术流程
- 数据预处理
- 特征提取(MFCC)
- 构建CNN模型
- 训练模型
- 评估模型
- 预测情绪
四、代码实现
1. 导入所需库
import os
import numpy as np
import pandas as pd
import librosa
import librosa.display
import matplotlib.pyplot as plt
from python_speech_features import mfcc
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Conv2D, MaxPool2D, Flatten
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import ModelCheckpoint
2. 加载数据并提取特征
def extract_features(file_path, max_length=100):
audio, sample_rate = librosa.load(file_path, res_type='kaiser_fast')
mfccs = mfcc(audio, samplerate=sample_rate, nfft=1024, winlen=0.025, winstep=0.01, numcep=13)
# 填充或截断到统一长度
if mfccs.shape[0] > max_length:
mfccs = mfccs[:max_length, :]
else:
pad_width = max_length - mfccs.shape[0]
mfccs = np.pad(mfccs, pad_width=((0, pad_width), (0, 0)), mode='constant')
return mfccs
def load_data(data_dir, max_length=100, test_size=0.2):
features = []
labels = []
emotions = {
'01': 'neutral',
'03': 'happy',
'04': 'sad',
'05': 'angry',
'06': 'fearful',
'07': 'disgusted',
'08': 'surprised'
}
for subdir, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith(".wav"):
file_path = os.path.join(subdir, file)
emotion_code = file.split("-")[2]
emotion = emotions.get(emotion_code, None)
if emotion:
mfccs = extract_features(file_path, max_length)
features.append(mfccs)
labels.append(emotion)
# 将标签转换为数字编码
unique_labels = sorted(list(set(labels)))
label_to_index = {label: i for i, label in enumerate(unique_labels)}
encoded_labels = [label_to_index[label] for label in labels]
# 转换为numpy数组
X = np.array(features)
y = to_categorical(encoded_labels)
# 分割训练集和测试集
return train_test_split(X, y, test_size=test_size, random_state=42), unique_labels
# 使用示例
DATA_DIR = "path/to/your/audio/files"
(X_train, X_test, y_train, y_test), classes = load_data(DATA_DIR)
print(f"Number of classes: {len(classes)}")
print(f"Class labels: {classes}")
3. 构建改进的CNN模型
def build_model(input_shape, num_classes):
model = Sequential()
# 第一层卷积层
model.add(Conv2D(64, (3,3), activation='relu', input_shape=input_shape))
model.add(MaxPool2D((2,2)))
model.add(Dropout(0.25))
# 第二层卷积层
model.add(Conv2D(128, (3,3), activation='relu'))
model.add(MaxPool2D((2,2)))
model.add(Dropout(0.25))
# 第三层卷积层
model.add(Conv2D(256, (3,3), activation='relu'))
model.add(MaxPool2D((2,2)))
model.add(Dropout(0.25))
# 全连接层
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
# 编译模型
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
# 构建模型(调整输入形状以适应我们的MFCC特征)
input_shape = (X_train.shape[1], X_train.shape[2], 1) # 添加通道维度
num_classes = len(classes)
model = build_model(input_shape, num_classes)
# 打印模型结构
model.summary()
4. 训练模型
def reshape_data(X):
return X.reshape(X.shape[0], X.shape[1], X.shape[2], 1)
# 重塑数据以适应CNN输入
X_train_cnn = reshape_data(X_train)
X_test_cnn = reshape_data(X_test)
# 设置回调以保存最佳模型
checkpoint = ModelCheckpoint("best_model.h5",
monitor='val_accuracy',
verbose=1,
save_best_only=True,
mode='max')
# 训练模型
history = model.fit(X_train_cnn, y_train,
validation_data=(X_test_cnn, y_test),
epochs=50,
batch_size=32,
callbacks=[checkpoint])
5. 可视化训练结果
def plot_training_history(history):
# 绘制准确率曲线
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
# 绘制损失曲线
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.tight_layout()
plt.show()
# 显示训练历史
plot_training_history(history)
6. 评估模型性能
# 评估模型
test_loss, test_acc = model.evaluate(X_test_cnn, y_test, verbose=0)
print(f"\nTest accuracy: {test_acc:.4f}")
# 显示混淆矩阵
from sklearn.metrics import confusion_matrix
import seaborn as sns
def plot_confusion_matrix(y_true, y_pred, classes):
cm = confusion_matrix(np.argmax(y_true, axis=1), np.argmax(y_pred, axis=1))
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=classes, yticklabels=classes)
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.show()
# 预测测试集
y_pred = model.predict(X_test_cnn)
plot_confusion_matrix(y_test, y_pred, classes)
7. 使用模型进行预测
def predict_emotion(file_path, model, classes, max_length=100):
# 提取特征
features = extract_features(file_path, max_length)
# 重塑特征以匹配模型输入
features = features.reshape(1, features.shape[0], features.shape[1], 1)
# 进行预测
prediction = model.predict(features)
# 获取预测标签
predicted_class = np.argmax(prediction)
predicted_emotion = classes[predicted_class]
# 返回预测结果
return predicted_emotion, prediction[0]
# 使用示例
audio_file = "path/to/audio/file.wav"
predicted_emotion, probabilities = predict_emotion(audio_file, model, classes)
print(f"Predicted emotion: {predicted_emotion}")
for i, prob in enumerate(probabilities):
print(f"{classes[i]}: {prob:.4f}")
五、模型改进
原始的CNN模型可能不够完善,可以从以下几个方面进行改进:
- 增加数据增强:通过添加背景噪声、改变音调和速度等方法来扩充数据集
- 优化网络结构:尝试不同的卷积核大小、层数和滤波器数量组合
- 引入Batch Normalization:加速训练过程并提高模型稳定性
- 使用迁移学习:利用在大规模语音数据集上预训练的模型进行微调
- 尝试其他架构:如结合RNN或Transformer的混合模型
改进后的模型示例
from tensorflow.keras.layers import BatchNormalization
def build_improved_model(input_shape, num_classes):
model = Sequential()
# 第一层卷积层
model.add(Conv2D(64, (3,3), activation='relu', input_shape=input_shape))
model.add(BatchNormalization())
model.add(MaxPool2D((2,2)))
model.add(Dropout(0.25))
# 第二层卷积层
model.add(Conv2D(128, (3,3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPool2D((2,2)))
model.add(Dropout(0.25))
# 第三层卷积层
model.add(Conv2D(256, (3,3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPool2D((2,2)))
model.add(Dropout(0.25))
# 第四层卷积层
model.add(Conv2D(512, (3,3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPool2D((2,2)))
model.add(Dropout(0.25))
# 全连接层
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(256, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
# 编译模型
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
基于深度学习的语音情绪识别系统使用了改进的CNN架构,在RAVDESS数据集上表现良好。你可以根据具体需求进一步调整网络结构、超参数或尝试其他深度学习架构以获得更好的性能。


















 174
174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









