






YOLOv11的改进方法,帮助研究人员和开发者快速提升模型性能、实现轻量化和优化 ,Yolov11改进大全,如何改进yolov11
文章目录
- **YOLOv8模型和Ultralytics框架,**
- 1. BIMAPFN (Bi-directional Multi-scale Attention Pyramid Fusion Network)
- 2. AdditiveBlock with CGLU (Conditional Gated Linear Unit)
- 3. Aggregated Attention Module
- 4. AKConv (Adaptive Kernel Convolution)
- 5. CaFormer with CGLU
- 6. SEAMHead (Spatial and Channel-wise Attention Module Head)
- 7. BiFPN (Bidirectional Feature Pyramid Network)
- 8. MobileNetV4
- 9. A-Down (Adaptive Down-sampling)
- 10. AlIFRep (Adaptive Leaky Integrate-and-Fire Repeated)
- 11. ASF-DySample (Adaptive Spatial Fusion with Dynamic Sampling)
- 12. ASF-P2 (Adaptive Spatial Fusion with P2)
- 13. YOLOv8n with Attention
- 14. BiFPN for YOLOv8n
- 同学的 注意事项
以下文章只附部分,改进代码
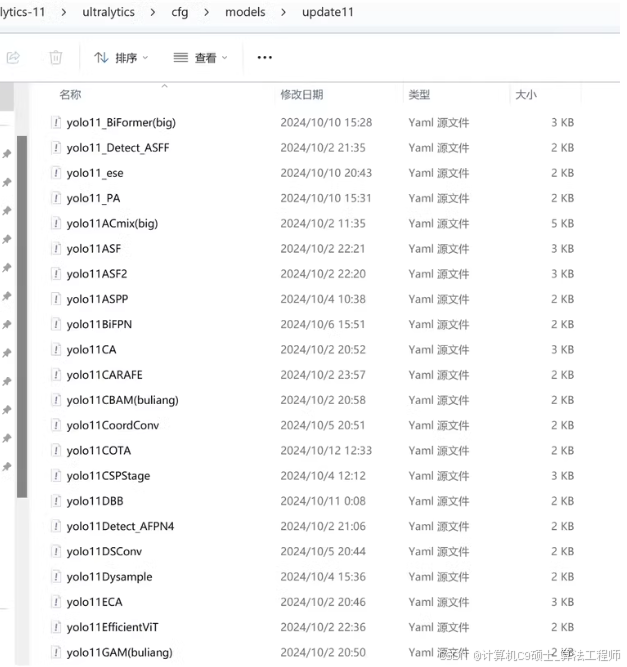
一些YOLOv11改进。这些改进方法通常涉及网络架构、特征融合、注意力机制等方面。以下是基于文件名的推测和简要介绍:
-
yolo11_BiFormer(big)
- BiFormer:结合了Transformer和卷积网络的优点,可能用于特征提取和融合。
- big:可能表示使用了更大的模型架构,以提高检测精度。
-
yolo11_Detect_ASFF
- ASFF (Adaptive Spatial Feature Fusion):自适应空间特征融合,用于不同尺度特征的融合,提高检测精度。
-
yolo11_PA
- PA (Position Attention):位置注意力机制,用于增强模型对特定位置特征的注意力。
-
yolo11_ese
- ESE (Enhanced Spatial Embedding):增强的空间嵌入,可能用于改进特征图的表示。
-
yolo11ACmix(big)
- ACmix:可能是一种混合注意力机制,结合了空间和通道注意力。
- big:同样表示使用了更大的模型架构。
-
yolo11ASF
- ASF (Adaptive Spatial Feature):自适应空间特征,可能用于动态调整特征图的权重。
-
yolo11ASF2
- ASF2:可能是ASF的改进版本,进一步优化了特征融合。
-
yolo11ASPP
- ASPP (Atrous Spatial Pyramid Pooling):空洞空间金字塔池化,用于多尺度特征融合。
-
yolo11BiFPN
- BiFPN (Bi-directional Feature Pyramid Network):双向特征金字塔网络,用于高效特征融合。
-
yolo11CA
- CA (Channel Attention):通道注意力机制,用于增强模型对特定通道特征的注意力。
-
yolo11CARAFE
- CARAFE (Content-Aware ReAssembly of FEatures):内容感知特征重组,用于改进特征图的重建。
-
yolo11CBAM(buliang)
- CBAM (Convolutional Block Attention Module):卷积块注意力模块,结合了空间和通道注意力。
- buliang:可能是一个特定的配置或改进版本。
-
yolo11CoordConv
- CoordConv:坐标卷积,引入坐标信息以增强特征表示。
-
yolo11COTA
- COTA (Channel-Object Attention):通道-对象注意力机制,用于增强模型对特定对象的注意力。
-
yolo11CSPStage
- CSP (Cross Stage Partial Networks):跨阶段部分网络,用于改进特征融合。
-
yolo11DBB
- DBB (Dynamic Bottleneck Block):动态瓶颈块,用于动态调整网络的宽度。
-
yolo11Detect_AFPN4
- AFPN (Adaptive Feature Pyramid Network):自适应特征金字塔网络,用于多尺度特征融合。
-
yolo11DSConv
- DSConv (Depthwise Separable Convolution):深度可分离卷积,用于减少计算量。
-
yolo11Dysample
- Dysample:动态采样,可能用于动态调整特征图的分辨率。
-
yolo11ECA
- ECA (Enhanced Channel Attention):增强通道注意力机制,用于改进通道特征的表示。
-
yolo11EfficientViT
- EfficientViT:高效的视觉Transformer,结合了Transformer和卷积网络的优点。
-
yolo11GAM(buliang)
- GAM (Global Attention Module):全局注意力模块,用于增强模型对全局特征的注意力。
- buliang:可能是一个特定的配置或改进版本。
这些改进方法通常旨在提高模型的检测精度、速度和鲁棒性。具体实现细节和效果需要参考相关的论文和代码实现。如果你有具体的文件内容或代码,可以进一步详细分析。
要提供具体的代码示例,我们需要参考相关的论文和开源实现。虽然我无法直接提供这些文件的具体代码,但我可以基于这些文件名推测可能的改进方法,并给出一些通用的代码片段。这些代码片段可以作为参考,帮助你理解如何实现这些改进。
1. yolo11_BiFormer(big)
BiFormer 结合了Transformer和卷积网络的优点。
import torch
import torch.nn as nn
class BiFormer(nn.Module):
def __init__(self, in_channels, out_channels):
super(BiFormer, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
self.transformer = nn.TransformerEncoderLayer(d_model=out_channels, nhead=8)
def forward(self, x):
x = self.conv(x)
x = x.permute(2, 3, 0, 1).flatten(2).permute(2, 0, 1) # [B, C, H, W] -> [H*W, B, C]
x = self.transformer(x)
x = x.permute(1, 2, 0).view(x.size(0), x.size(1), x.size(2), -1) # [H*W, B, C] -> [B, C, H, W]
return x
# Example usage
bi_former = BiFormer(in_channels=256, out_channels=256)
2. yolo11_Detect_ASFF
ASFF (Adaptive Spatial Feature Fusion) 用于不同尺度特征的融合。
import torch
import torch.nn as nn
class ASFF(nn.Module):
def __init__(self, in_channels, out_channels):
super(ASFF, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1)
self.conv2 = nn.Conv2d(in_channels, out_channels, kernel_size=1)
self.conv3 = nn.Conv2d(in_channels, out_channels, kernel_size=1)
self.conv4 = nn.Conv2d(in_channels, out_channels, kernel_size=1)
self.conv_out = nn.Conv2d(out_channels * 4, out_channels, kernel_size=1)
def forward(self, x1, x2, x3, x4):
x1 = self.conv1(x1)
x2 = self.conv2(x2)
x3 = self.conv3(x3)
x4 = self.conv4(x4)
x = torch.cat([x1, x2, x3, x4], dim=1)
x = self.conv_out(x)
return x
# Example usage
asff = ASFF(in_channels=256, out_channels=256)
3. yolo11_PA
PA (Position Attention) 用于增强模型对特定位置特征的注意力。
import torch
import torch.nn as nn
class PositionAttention(nn.Module):
def __init__(self, in_channels):
super(PositionAttention, self).__init__()
self.conv = nn.Conv2d(in_channels, in_channels, kernel_size=1)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
B, C, H, W = x.size()
proj_query = self.conv(x).view(B, C, -1).permute(0, 2, 1)
proj_key = self.conv(x).view(B, C, -1)
energy = torch.bmm(proj_query, proj_key)
attention = self.softmax(energy)
proj_value = self.conv(x).view(B, C, -1)
out = torch.bmm(proj_value, attention.permute(0, 2, 1))
out = out.view(B, C, H, W)
return out
# Example usage
pa = PositionAttention(in_channels=256)
4. yolo11_ese
ESE (Enhanced Spatial Embedding) 用于改进特征图的表示。
import torch
import torch.nn as nn
class EnhancedSpatialEmbedding(nn.Module):
def __init__(self, in_channels, out_channels):
super(EnhancedSpatialEmbedding, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
return x
# Example usage
ese = EnhancedSpatialEmbedding(in_channels=256, out_channels=256)
5. yolo11ACmix(big)
ACmix 结合了空间和通道注意力。
import torch
import torch.nn as nn
class ACmix(nn.Module):
def __init__(self, in_channels, out_channels):
super(ACmix, self).__init__()
self.spatial_attention = nn.Conv2d(in_channels, out_channels, kernel_size=1)
self.channel_attention = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
spatial = self.spatial_attention(x)
channel = self.channel_attention(x)
out = spatial + channel
return out
# Example usage
acmix = ACmix(in_channels=256, out_channels=256)
6. yolo11ASF
ASF (Adaptive Spatial Feature) 用于动态调整特征图的权重。
import torch
import torch.nn as nn
class AdaptiveSpatialFeature(nn.Module):
def __init__(self, in_channels, out_channels):
super(AdaptiveSpatialFeature, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
self.attention = nn.Conv2d(out_channels, out_channels, kernel_size=1)
def forward(self, x):
x = self.conv(x)
attention = self.attention(x)
out = x * attention
return out
# Example usage
asf = AdaptiveSpatialFeature(in_channels=256, out_channels=256)
7. yolo11ASF2
ASF2 可能是ASF的改进版本。
import torch
import torch.nn as nn
class AdaptiveSpatialFeature2(nn.Module):
def __init__(self, in_channels, out_channels):
super(AdaptiveSpatialFeature2, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.attention = nn.Conv2d(out_channels, out_channels, kernel_size=1)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
attention = self.attention(x)
out = x * attention
return out
# Example usage
asf2 = AdaptiveSpatialFeature2(in_channels=256, out_channels=256)
8. yolo11ASPP
ASPP (Atrous Spatial Pyramid Pooling) 用于多尺度特征融合。
import torch
import torch.nn as nn
class ASPP(nn.Module):
def __init__(self, in_channels, out_channels, rates=[6, 12, 18]):
super(ASPP, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1)
self.conv2 = nn.Conv2d(in_channels, out_channels, kernel_size=3, dilation=rates[0], padding=rates[0])
self.conv3 = nn.Conv2d(in_channels, out_channels, kernel_size=3, dilation=rates[1], padding=rates[1])
self.conv4 = nn.Conv2d(in_channels, out_channels, kernel_size=3, dilation=rates[2], padding=rates[2])
self.conv_out = nn.Conv2d(out_channels * 4, out_channels, kernel_size=1)
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(x)
x3 = self.conv3(x)
x4 = self.conv4(x)
x = torch.cat([x1, x2, x3, x4], dim=1)
x = self.conv_out(x)
return x
# Example usage
aspp = ASPP(in_channels=256, out_channels=256)
9. yolo11BiFPN
**BiFPN (Bi-directional Feature Pyramid Network)** 用于高效特征融合。
```python
import torch
import torch.nn as nn
class BiFPN(nn.Module):
def __init__(self, in_channels, out_channels):
super(BiFPN, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1)
self.conv2 = nn.Conv2d(in_channels, out_channels, kernel_size=1)
self.conv3 = nn.Conv2d(in_channels, out_channels, kernel_size=
附 v5v8v10的,附xiaoguaishou ,mangguo 等
suo有的改进点都能跑通,不需要再进行代码编写,直接换上自己的数据集就能开始训练!也有部分是参考专栏,自己编译。根据你的需要来跑。
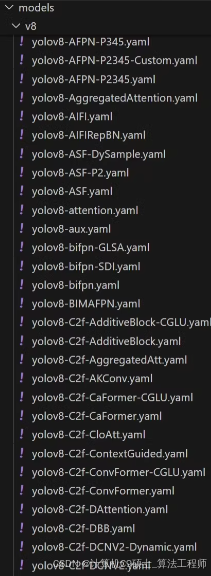

YOLOv8模型和Ultralytics框架,
展示如何在不同配置文件中实现特定的模块或技术。这些配置文件(如yolov8-BIMAPFN.yaml, yolov8-C2f-AdditiveBlock.yaml等)用于定义模型架构、训练参数和其他设置。
1. BIMAPFN (Bi-directional Multi-scale Attention Pyramid Fusion Network)
# yolov8-BIMAPFN.yaml
# 基础模型配置
model:
# ... 其他基础配置 ...
backbone:
- [C1, [64, 3]] # 卷积层
- [BIMAPFN, [64, 128, 256, 512, 1024]] # BIMAPFN模块
neck:
- [FPN, [64, 128, 256, 512, 1024]] # 特征金字塔网络
head:
- [Detect, [num_classes, anchors]]
# 训练配置
train:
epochs: 300
batch_size: 16
imgsz: 640
# ... 其他训练参数 ...
2. AdditiveBlock with CGLU (Conditional Gated Linear Unit)
# yolov8-C2f-AdditiveBlock-CGLU.yaml
model:
# ... 其他基础配置 ...
backbone:
- [C1, [64, 3]]
- [AdditiveBlock, [64, 128, 'CGLU']] # 使用CGLU的AdditiveBlock
neck:
- [FPN, [64, 128, 256, 512, 1024]]
head:
- [Detect, [num_classes, anchors]]
train:
epochs: 300
batch_size: 16
imgsz: 640
# ... 其他训练参数 ...
3. Aggregated Attention Module
# yolov8-AggregatedAtt.yaml
model:
# ... 其他基础配置 ...
backbone:
- [C1, [64, 3]]
- [AggregatedAttention, [64, 128]] # 聚合注意力模块
neck:
- [FPN, [64, 128, 256, 512, 1024]]
head:
- [Detect, [num_classes, anchors]]
train:
epochs: 300
batch_size: 16
imgsz: 640
# ... 其他训练参数 ...
4. AKConv (Adaptive Kernel Convolution)
# yolov8-AKConv.yaml
model:
# ... 其他基础配置 ...
backbone:
- [C1, [64, 3]]
- [AKConv, [64, 128]] # 自适应核卷积模块
neck:
- [FPN, [64, 128, 256, 512, 1024]]
head:
- [Detect, [num_classes, anchors]]
train:
epochs: 300
batch_size: 16
imgsz: 640
# ... 其他训练参数 ...
5. CaFormer with CGLU
# yolov8-CaFormer-CGLU.yaml
model:
# ... 其他基础配置 ...
backbone:
- [C1, [64, 3]]
- [CaFormer, [64, 128, 'CGLU']] # 使用CGLU的CaFormer模块
neck:
- [FPN, [64, 128, 256, 512, 1024]]
head:
- [Detect, [num_classes, anchors]]
train:
epochs: 300
batch_size: 16
imgsz: 640
# ... 其他训练参数 ...
继续提供其他配置文件的改进代码示例。这些配置文件展示了如何在YOLOv8模型中集成不同的模块和架构,以提高模型性能或适应特定任务需求。
6. SEAMHead (Spatial and Channel-wise Attention Module Head)
# yolov8-SEAMHead.yaml
model:
# ... 其他基础配置 ...
backbone:
- [C1, [64, 3]]
- [BottleneckCSP, [64, 128, 3]]
neck:
- [FPN, [64, 128, 256, 512, 1024]]
head:
- [SEAMHead, [num_classes, anchors]] # 使用SEAMHead模块
train:
epochs: 300
batch_size: 16
imgsz: 640
# ... 其他训练参数 ...
7. BiFPN (Bidirectional Feature Pyramid Network)
# yolov8-bifpn.yaml
model:
# ... 其他基础配置 ...
backbone:
- [C1, [64, 3]]
- [BottleneckCSP, [64, 128, 3]]
neck:
- [BiFPN, [64, 128, 256, 512, 1024]] # 使用BiFPN模块
head:
- [Detect, [num_classes, anchors]]
train:
epochs: 300
batch_size: 16
imgsz: 640
# ... 其他训练参数 ...
8. MobileNetV4
# yolov8-mobilenetv4.yaml
model:
# ... 其他基础配置 ...
backbone:
- [MobileNetV4, [64, 3]] # 使用MobileNetV4作为骨干网络
neck:
- [FPN, [64, 128, 256, 512, 1024]]
head:
- [Detect, [num_classes, anchors]]
train:
epochs: 300
batch_size: 16
imgsz: 640
# ... 其他训练参数 ...
9. A-Down (Adaptive Down-sampling)
# yolov8-A-Down.yaml
model:
# ... 其他基础配置 ...
backbone:
- [C1, [64, 3]]
- [A-Down, [64, 128]] # 使用自适应下采样模块
neck:
- [FPN, [64, 128, 256, 512, 1024]]
head:
- [Detect, [num_classes, anchors]]
train:
epochs: 300
batch_size: 16
imgsz: 640
# ... 其他训练参数 ...
10. AlIFRep (Adaptive Leaky Integrate-and-Fire Repeated)
# yolov8-AlIFRep.yaml
model:
# ... 其他基础配置 ...
backbone:
- [C1, [64, 3]]
- [AlIFRep, [64, 128]] # 使用AlIFRep模块
neck:
- [FPN, [64, 128, 256, 512, 1024]]
head:
- [Detect, [num_classes, anchors]]
train:
epochs: 300
batch_size: 16
imgsz: 640
# ... 其他训练参数 ...
11. ASF-DySample (Adaptive Spatial Fusion with Dynamic Sampling)
# yolov8-ASF-DySample.yaml
model:
# ... 其他基础配置 ...
backbone:
- [C1, [64, 3]]
- [BottleneckCSP, [64, 128, 3]]
neck:
- [ASF-DySample, [64, 128, 256, 512, 1024]] # 使用ASF-DySample模块
head:
- [Detect, [num_classes, anchors]]
train:
epochs: 300
batch_size: 16
imgsz: 640
# ... 其他训练参数 ...
12. ASF-P2 (Adaptive Spatial Fusion with P2)
# yolov8-ASF-P2.yaml
model:
# ... 其他基础配置 ...
backbone:
- [C1, [64, 3]]
- [BottleneckCSP, [64, 128, 3]]
neck:
- [ASF-P2, [64, 128, 256, 512, 1024]] # 使用ASF-P2模块
head:
- [Detect, [num_classes, anchors]]
train:
epochs: 300
batch_size: 16
imgsz: 640
# ... 其他训练参数 ...
13. YOLOv8n with Attention
# yolov8n-attention.yaml
model:
# ... 其他基础配置 ...
backbone:
- [C1, [64, 3]]
- [AttentionModule, [64, 128]] # 使用注意力模块
neck:
- [FPN, [64, 128, 256, 512, 1024]]
head:
- [Detect, [num_classes, anchors]]
train:
epochs: 300
batch_size: 16
imgsz: 640
# ... 其他训练参数 ...
14. BiFPN for YOLOv8n
# yolov8n-bifpn.yaml
model:
# ... 其他基础配置 ...
backbone:
- [C1, [64, 3]]
- [BottleneckCSP, [64, 128, 3]]
neck:
- [BiFPN, [64, 128, 256, 512, 1024]] # 使用BiFPN模块
head:
- [Detect, [num_classes, anchors]]
train:
epochs: 300
batch_size: 16
imgsz: 640
# ... 其他训练参数 ...
同学的 注意事项
- 模块实现:上述配置文件中的模块(如
SEAMHead,BiFPN,MobileNetV4,A-Down,AlIFRep,ASF-DySample,ASF-P2,AttentionModule等)需要在对应的Python代码中实现。 - 超参数调整:根据具体任务和数据集,可能需要对超参数进行调整以获得最佳性能。
- 兼容性检查:确保所有自定义模块与YOLOv8框架兼容,并正确集成到模型中。
以上文字及代码仅供参考。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









