






昆仑万维旗下SkyReels团队重磅发布并正式开源全球首个基于“扩散强迫框架”的长时长视频生成模型SkyReels-V2。该模型融合了多模态大语言模型、多阶段预训练、强化学习与扩散强迫机制,协同优化推动视频生成迈入新纪元。模型聚焦于解决视频生成中的提示词响应性、画面质量、运动流畅性以及长短协调等核心痛点,当前已能输出30至40秒高一致性、高运动精度和高保真的视频成果,广泛支持故事生成、图像转视频、多视角运镜和多主体一致性(SkyReels-A2)等场景。
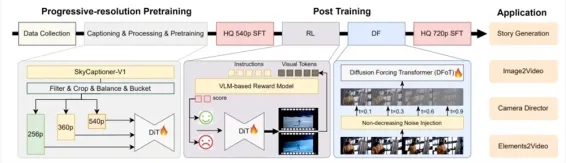
SkyReels-V2的技术进展主要体现在以下几个方面: (1) SkyCaptioner-V1作为影视级视频理解引擎,结合结构化表示和多模态大语言模型,增强镜头语言理解与描述生成能力; (2) 借助强化学习优化视频运动表现,通过标注数据与合成训练缓解动态扭曲问题; (3) 高效的扩散强迫结构微调预训练模型,有效降低长视频生成成本; (4) 多阶段渐进式训练策略配合海量数据,实现资源可控条件下的高质量视频合成。
评测数据显示,SkyReels-V2在SkyReels-Bench(含1020条文本提示词)四大指标中——提示响应性、动作流畅度、一致性与画面质量——表现均衡领先。在V-Bench1.0评估中,其综合得分(83.9%)及视觉质量得分(84.7%)均优于HunyuanVideo-13B、Wan2.1-14B等同类产品,展现出领先的生成能力。
在应用层面,该模型借助滑动窗口生成机制实现连贯长镜头生成,支持图像转视频两种路径,配合优选样本提升AI导播运镜能力,基于SkyReels-A2则可实现文本引导下的任意视觉要素融合。
昆仑万维表示,未来将持续推动SkyReels-V2系列模型与SkyCaptioner-V1的开源优化,降低大规模生成视频的计算门槛,赋能影视制作、虚拟仿真等产业场景加速落地。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









