







- 自定义参数:SQL任务类型,而存储过程是自定义参数顺序的给方法设置值自定义参数类型和数据类型同存储过程任务类型一样。区别在于SQL任务类型自定义参数会替换sql语句中${变量}。
- 前置sql:前置sql在sql语句之前执行。
- 后置sql:后置sql在sql语句之后执行。
SPARK节点
- 通过SPARK节点,可以直接直接执行SPARK程序,对于spark节点,worker会使用
spark-submit方式提交任务
拖动工具栏中的
任务节点到画板中,如下图所示:
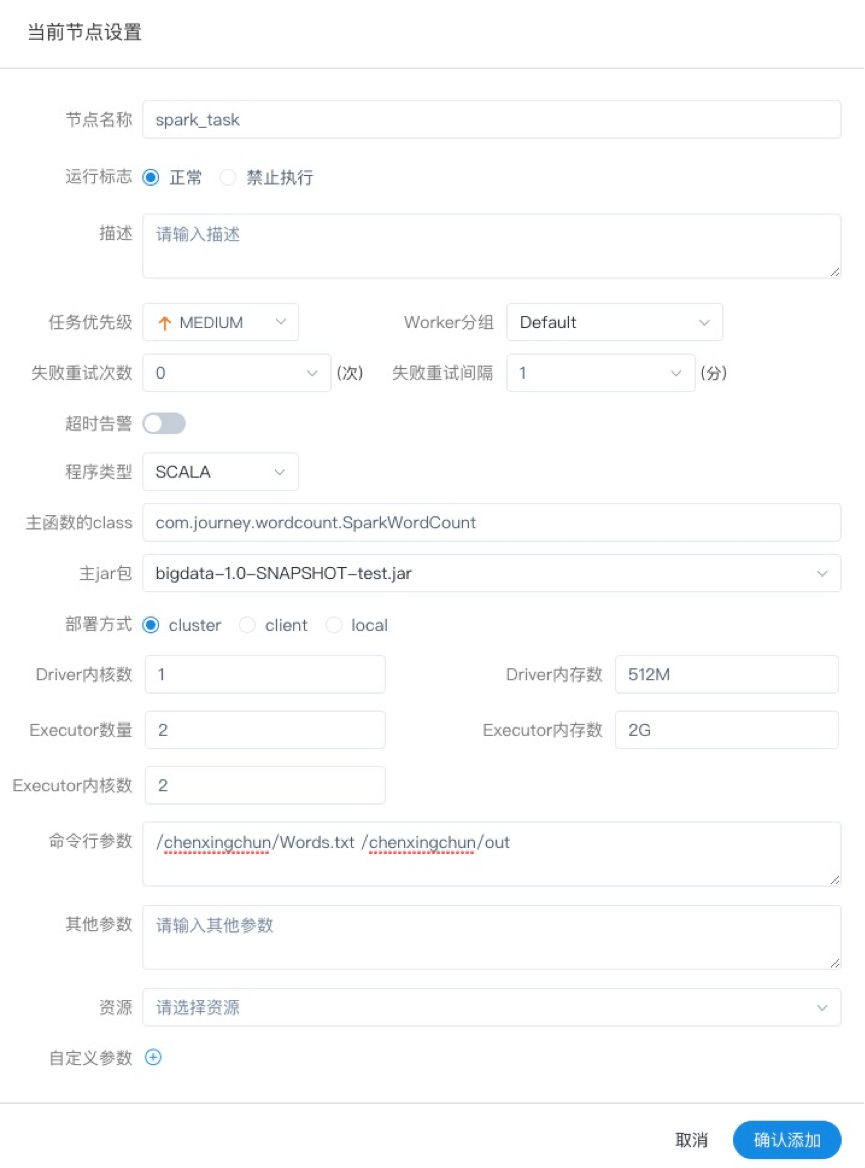
- 程序类型:支持JAVA、Scala和Python三种语言
- 主函数的class:是Spark程序的入口Main Class的全路径
- 主jar包:是Spark的jar包
- 部署方式:支持yarn-cluster、yarn-client和local三种模式
- Driver内核数:可以设置Driver内核数及内存数
- Executor数量:可以设置Executor数量、Executor内存数和Executor内核数
- 命令行参数:是设置Spark程序的输入参数,支持自定义参数变量的替换。
- 其他参数:支持 --jars、–files、–archives、–conf格式
- 资源:如果其他参数中引用了资源文件,需要在资源中选择指定
- 自定义参数:是MR局部的用户自定义参数,会替换脚本中以${变量}的内容
注意:JAVA和Scala只是用来标识,没有区别,如果是Python开发的Spark则没有主函数的class,其他都是一样
MapReduce(MR)节点
- 使用MR节点,可以直接执行MR程序。对于mr节点,worker会使用
hadoop jar方式提交任务
拖动工具栏中的
任务节点到画板中,如下图所示:
JAVA程序
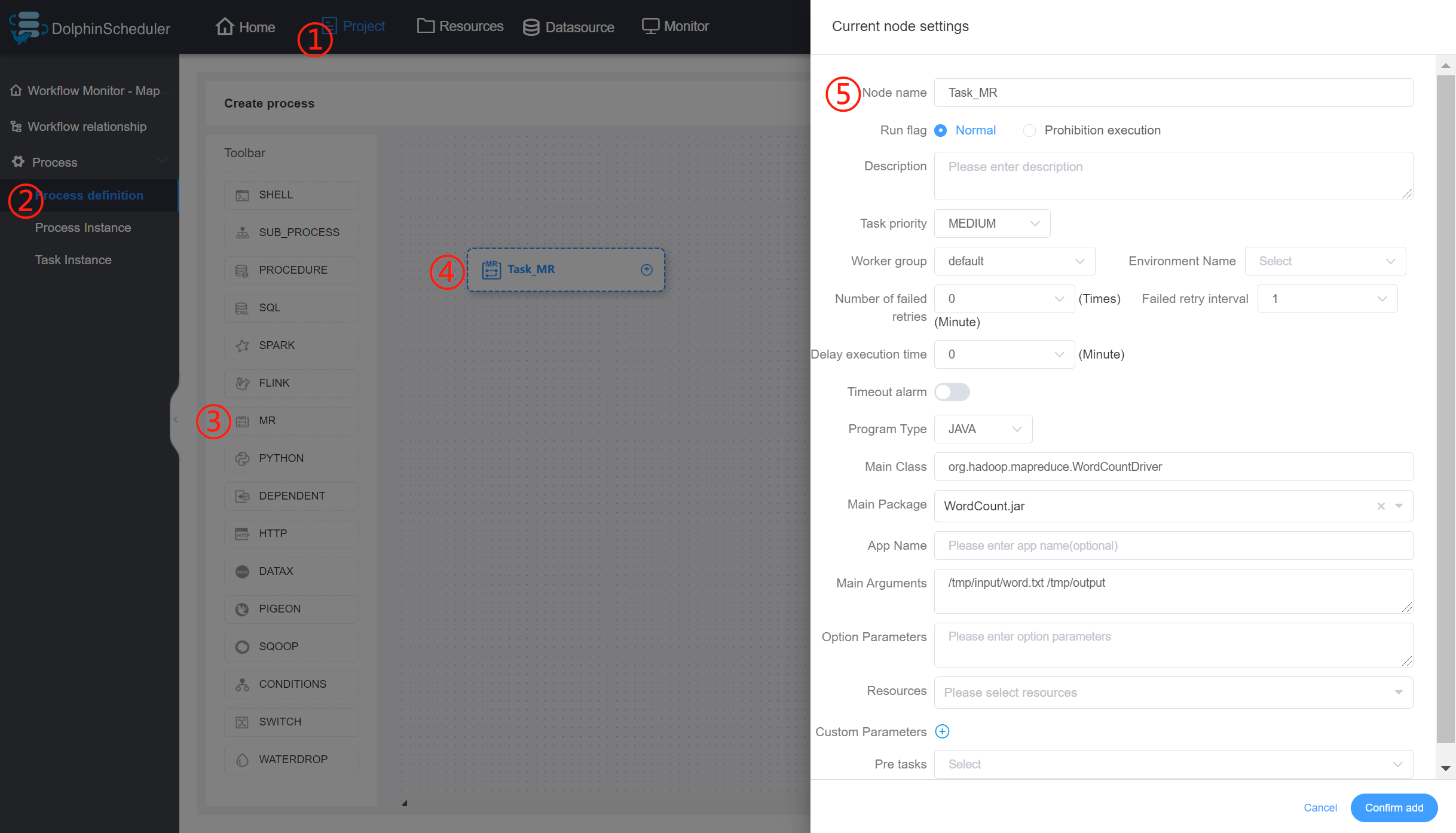
- 主函数的class:是MR程序的入口Main Class的全路径
- 程序类型:选择JAVA语言
- 主jar包:是MR的jar包
- 命令行参数:是设置MR程序的输入参数,支持自定义参数变量的替换
- 其他参数:支持 –D、-files、-libjars、-archives格式
- 资源: 如果其他参数中引用了资源文件,需要在资源中选择指定
- 自定义参数:是MR局部的用户自定义参数,会替换脚本中以${变量}的内容
Python程序
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p1oexZeW-1683205971444)(null)]
- 程序类型:选择Python语言
- 主jar包:是运行MR的Python jar包
- 其他参数:支持 –D、-mapper、-reducer、-input -output格式,这里可以设置用户自定义参数的输入,比如:
- -mapper “mapper.py 1” -file mapper.py -reducer reducer.py -file reducer.py –input /journey/words.txt -output /journey/out/mr/${currentTimeMillis}
- 其中 -mapper 后的 mapper.py 1是两个参数,第一个参数是mapper.py,第二个参数是1
- 资源: 如果其他参数中引用了资源文件,需要在资源中选择指定
- 自定义参数:是MR局部的用户自定义参数,会替换脚本中以${变量}的内容
Python节点
- 使用python节点,可以直接执行python脚本,对于python节点,worker会使用
python **方式提交任务。
拖动工具栏中的
任务节点到画板中,如下图所示:
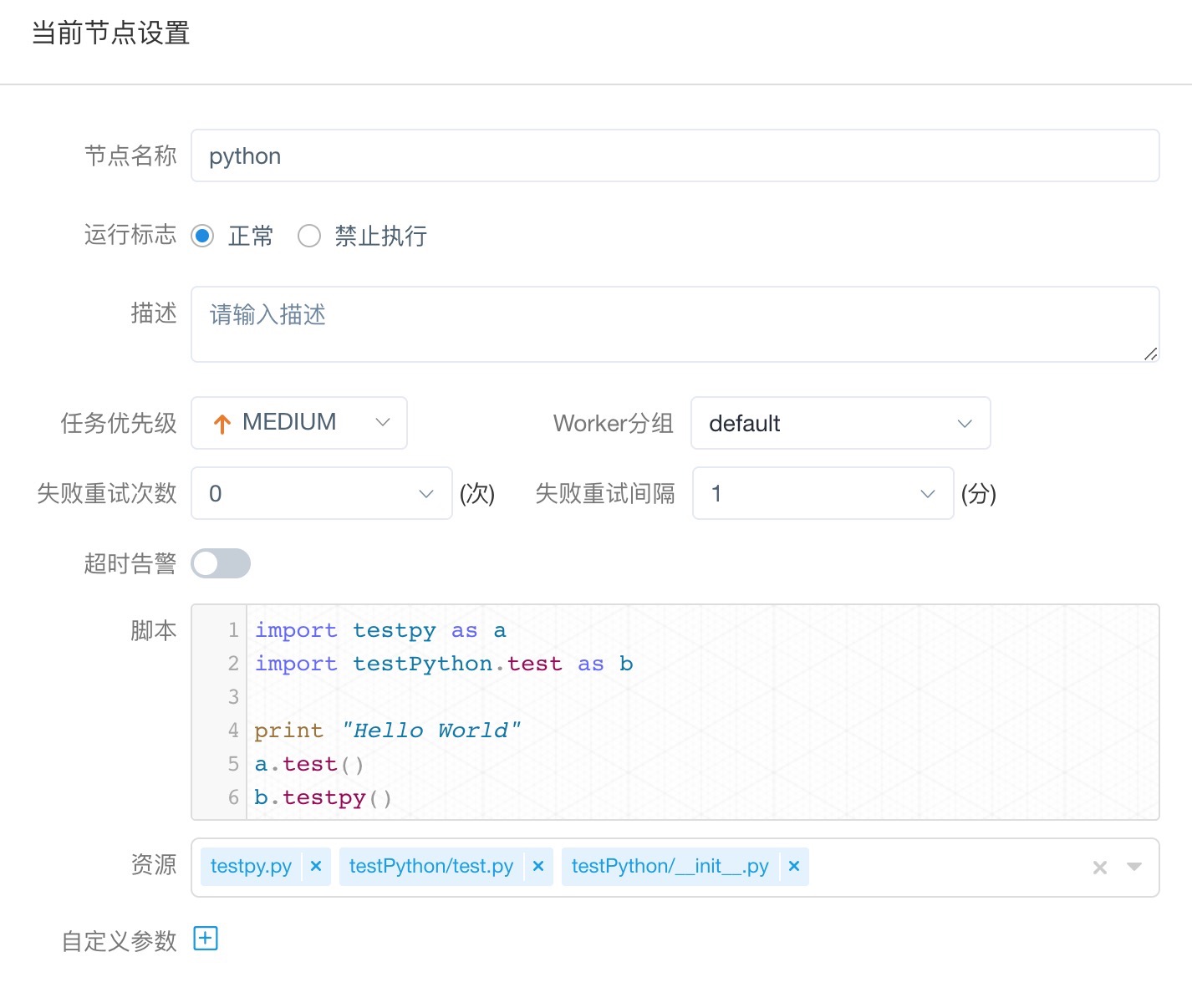
- 脚本:用户开发的Python程序
- 环境名称:执行Python程序的解释器路径,指定运行脚本的解释器。当你需要使用 Python 虚拟环境 时,可以通过创建不同的环境名称来实现。
- 资源:是指脚本中需要调用的资源文件列表
- 自定义参数:是Python局部的用户自定义参数,会替换脚本中以${变量}的内容
- 注意:若引入资源目录树下的python文件,需添加
__init__.py文件
Flink节点
- 拖动工具栏中的
 任务节点到画板中,如下图所示:
任务节点到画板中,如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D8Zut6Pc-1683205976158)(null)]
- 程序类型:支持JAVA、Scala和Python三种语言
- 主函数的class:是Flink程序的入口Main Class的全路径
- 主jar包:是Flink的jar包
- 部署方式:支持cluster、local三种模式
- slot数量:可以设置slot数
- taskManage数量:可以设置taskManage数
- jobManager内存数:可以设置jobManager内存数
- taskManager内存数:可以设置taskManager内存数
- 命令行参数:是设置Spark程序的输入参数,支持自定义参数变量的替换。
- 其他参数:支持 --jars、–files、–archives、–conf格式
- 资源:如果其他参数中引用了资源文件,需要在资源中选择指定
- 自定义参数:是Flink局部的用户自定义参数,会替换脚本中以${变量}的内容
注意:JAVA和Scala只是用来标识,没有区别,如果是Python开发的Flink则没有主函数的class,其他都是一样
http节点
- 拖动工具栏中的
 任务节点到画板中,如下图所示:
任务节点到画板中,如下图所示:
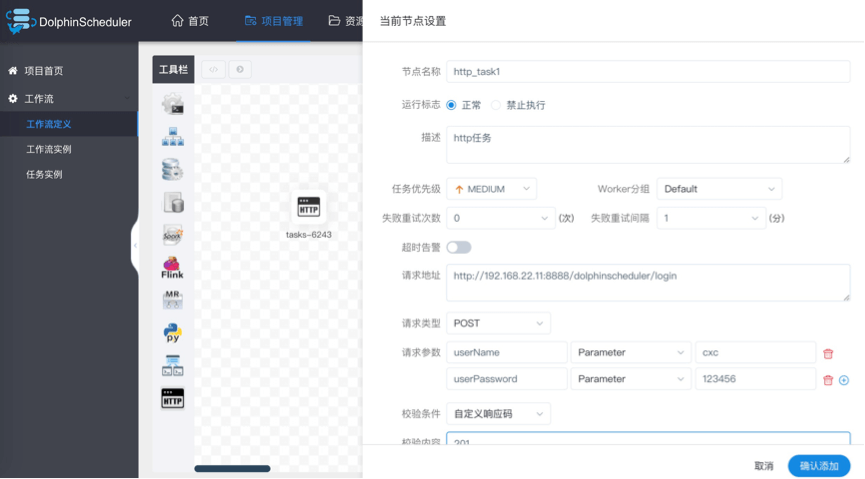
- 节点名称:一个工作流定义中的节点名称是唯一的。
- 运行标志:标识这个节点是否能正常调度,如果不需要执行,可以打开禁止执行开关。
- 描述信息:描述该节点的功能。
- 任务优先级:worker线程数不足时,根据优先级从高到低依次执行,优先级一样时根据先进先出原则执行。
- Worker分组:任务分配给worker组的机器机执行,选择Default,会随机选择一台worker机执行。
- 失败重试次数:任务失败重新提交的次数,支持下拉和手填。
- 失败重试间隔:任务失败重新提交任务的时间间隔,支持下拉和手填。
- 超时告警:勾选超时告警、超时失败,当任务超过"超时时长"后,会发送告警邮件并且任务执行失败.
- 请求地址:http请求URL。
- 请求类型:支持GET、POSt、HEAD、PUT、DELETE。
- 请求参数:支持Parameter、Body、Headers。
- 校验条件:支持默认响应码、自定义响应码、内容包含、内容不包含。
- 校验内容:当校验条件选择自定义响应码、内容包含、内容不包含时,需填写校验内容。
- 自定义参数:是http局部的用户自定义参数,会替换脚本中以${变量}的内容。
DATAX节点
- 拖动工具栏中的
 任务节点到画板中
任务节点到画板中
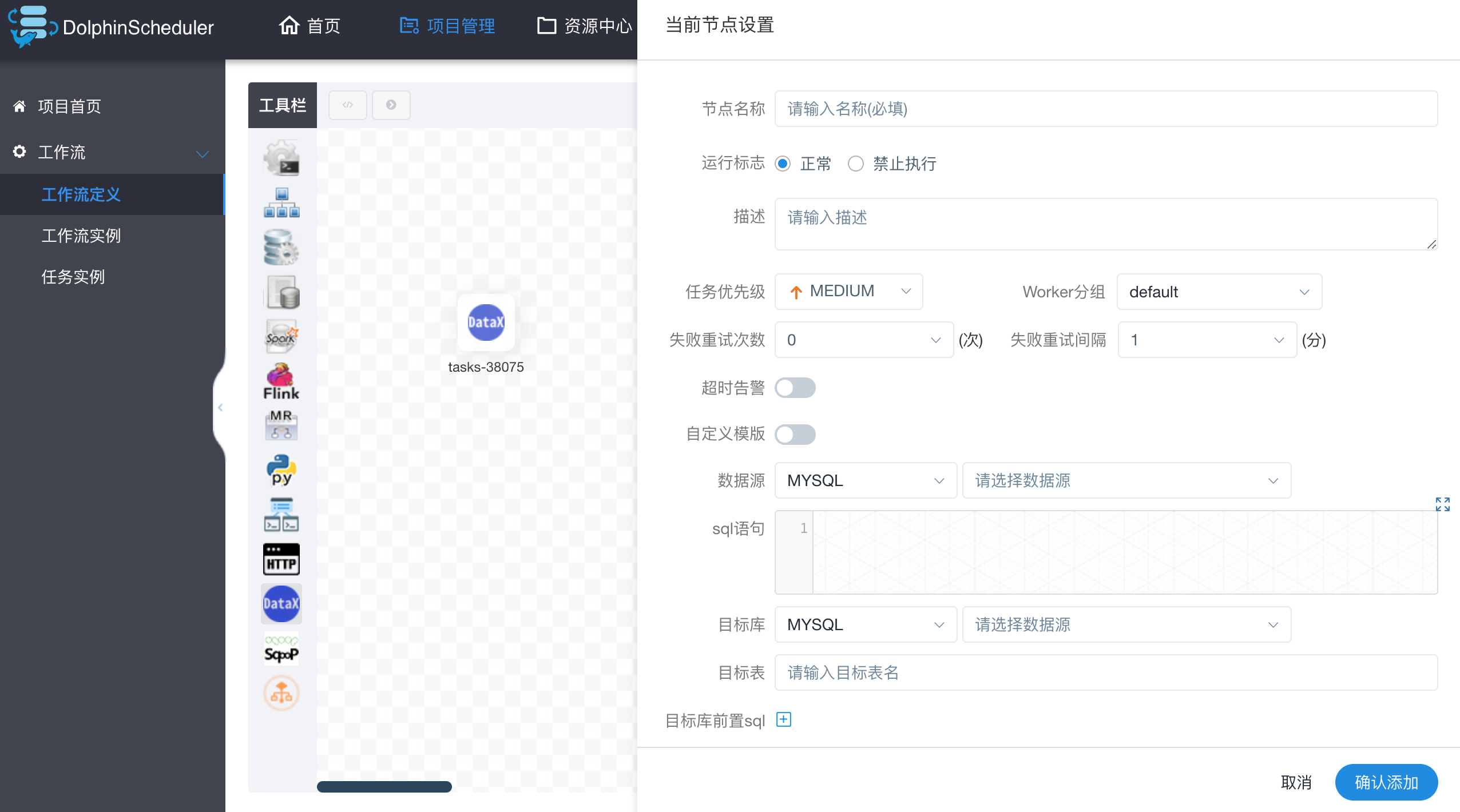
- 自定义模板:打开自定义模板开关时,可以自定义datax节点的json配置文件内容(适用于控件配置不满足需求时)
- 数据源:选择抽取数据的数据源
- sql语句:目标库抽取数据的sql语句,节点执行时自动解析sql查询列名,映射为目标表同步列名,源表和目标表列名不一致时,可以通过列别名(as)转换
- 目标库:选择数据同步的目标库
- 目标表:数据同步的目标表名
- 前置sql:前置sql在sql语句之前执行(目标库执行)。
- 后置sql:后置sql在sql语句之后执行(目标库执行)。
- json:datax同步的json配置文件
- 自定义参数:SQL任务类型,而存储过程是自定义参数顺序的给方法设置值自定义参数类型和数据类型同存储过程任务类型一样。区别在于SQL任务类型自定义参数会替换sql语句中${变量}。
参数
内置参数
基础内置参数
| 变量名 | 声明方式 | 含义 |
|---|---|---|
| system.biz.date | ${system.biz.date} | 日常调度实例定时的定时时间前一天,格式为 yyyyMMdd,补数据时,该日期 +1 |
| system.biz.curdate | ${system.biz.curdate} | 日常调度实例定时的定时时间,格式为 yyyyMMdd,补数据时,该日期 +1 |
| system.datetime | ${system.datetime} | 日常调度实例定时的定时时间,格式为 yyyyMMddHHmmss,补数据时,该日期 +1 |
衍生内置参数
- 支持代码中自定义变量名,声明方式:${变量名}。可以是引用 “系统参数”
- 我们定义这种基准变量为
[
.
.
.
]
格式的,
[…] 格式的,
[…]格式的,[yyyyMMddHHmmss] 是可以任意分解组合的,比如:$[yyyyMMdd], $[HHmmss], $[yyyy-MM-dd] 等
- 也可以通过以下两种方式:
1.使用add_months()函数,该函数用于加减月份, 第一个入口参数为[yyyyMMdd],表示返回时间的格式 第二个入口参数为月份偏移量,表示加减多少个月
+ 后 N 年:$[add\_months(yyyyMMdd,12\*N)]
+ 前 N 年:$[add\_months(yyyyMMdd,-12\*N)]
+ 后 N 月:$[add\_months(yyyyMMdd,N)]
+ 前 N 月:$[add\_months(yyyyMMdd,-N)]
2.直接加减数字 在自定义格式后直接“+/-”数字
+ 后 N 周:$[yyyyMMdd+7\*N]
+ 前 N 周:$[yyyyMMdd-7\*N]
+ 后 N 天:$[yyyyMMdd+N]
+ 前 N 天:$[yyyyMMdd-N]
+ 后 N 小时:$[HHmmss+N/24]
+ 前 N 小时:$[HHmmss-N/24]
+ 后 N 分钟:$[HHmmss+N/24/60]
+ 前 N 分钟:$[HHmmss-N/24/60]
全局参数
作用域
在工作流定义页面配置的参数,作用于该工作流中全部的任务
使用方式
全局参数配置方式如下:在工作流定义页面,点击“设置全局”右边的加号,填写对应的变量名称和对应的值,保存即可
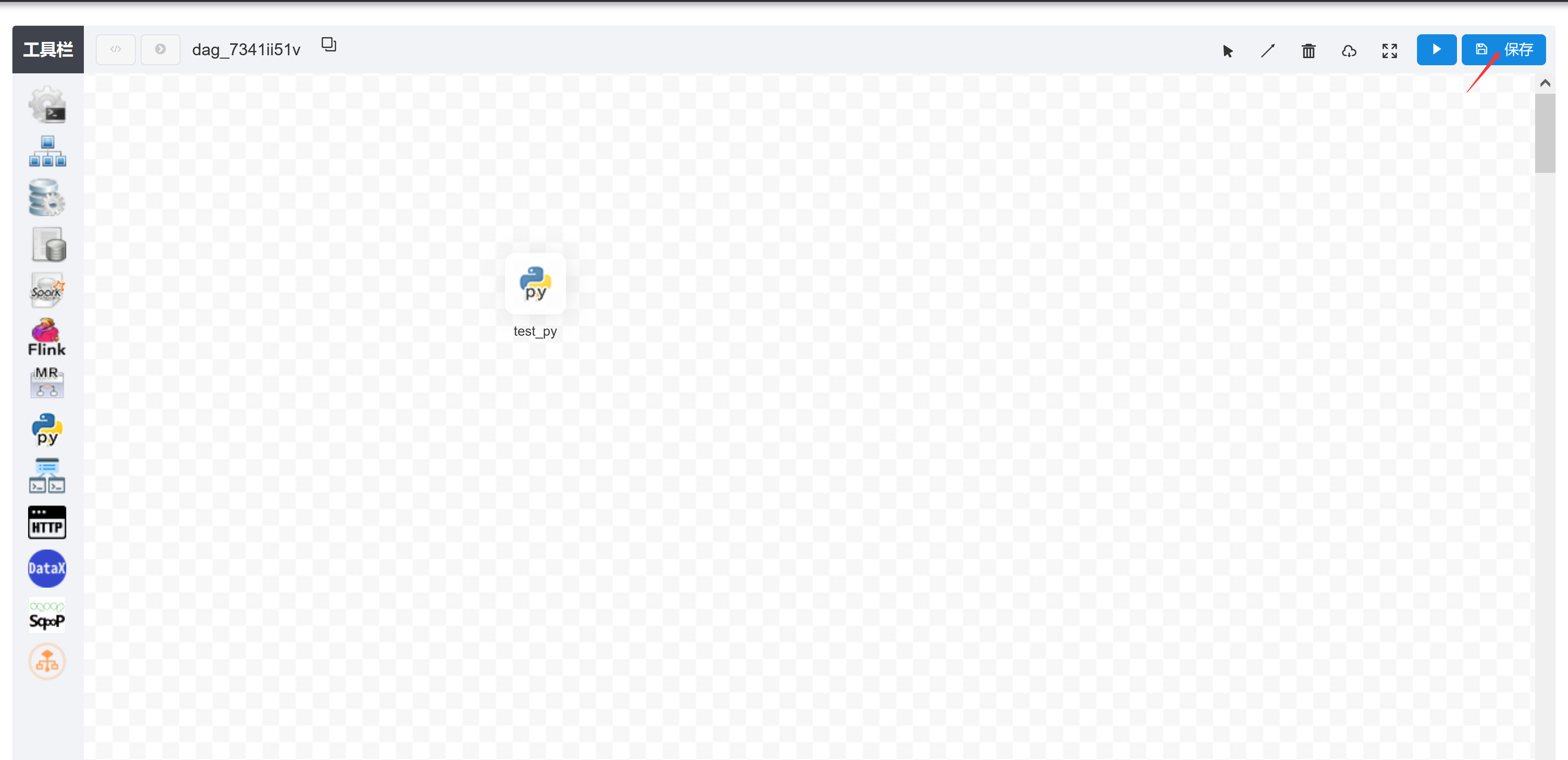
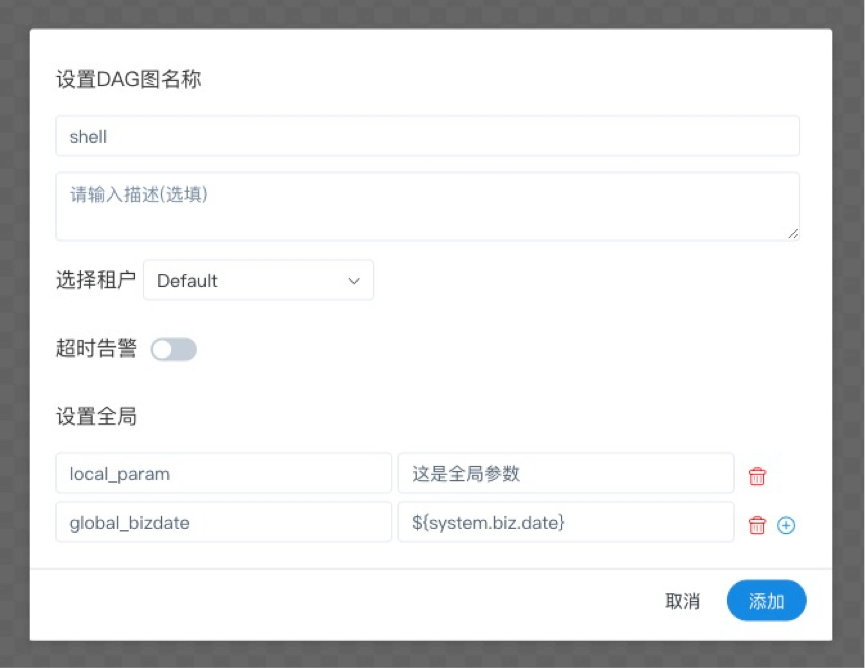
这里定义的global_bizdate参数可以被其它任一节点的局部参数引用,并设置global_bizdate的value为通过引用系统参数system.biz.date获得的值
本地参数
作用域
在任务定义页面配置的参数,默认作用域仅限该任务,如果配置了参数传递则可将该参数作用到下游任务中。
使用方式
本地参数配置方式如下:在任务定义页面,点击“自定义参数”右边的加号,填写对应的变量名称和对应的值,保存即可
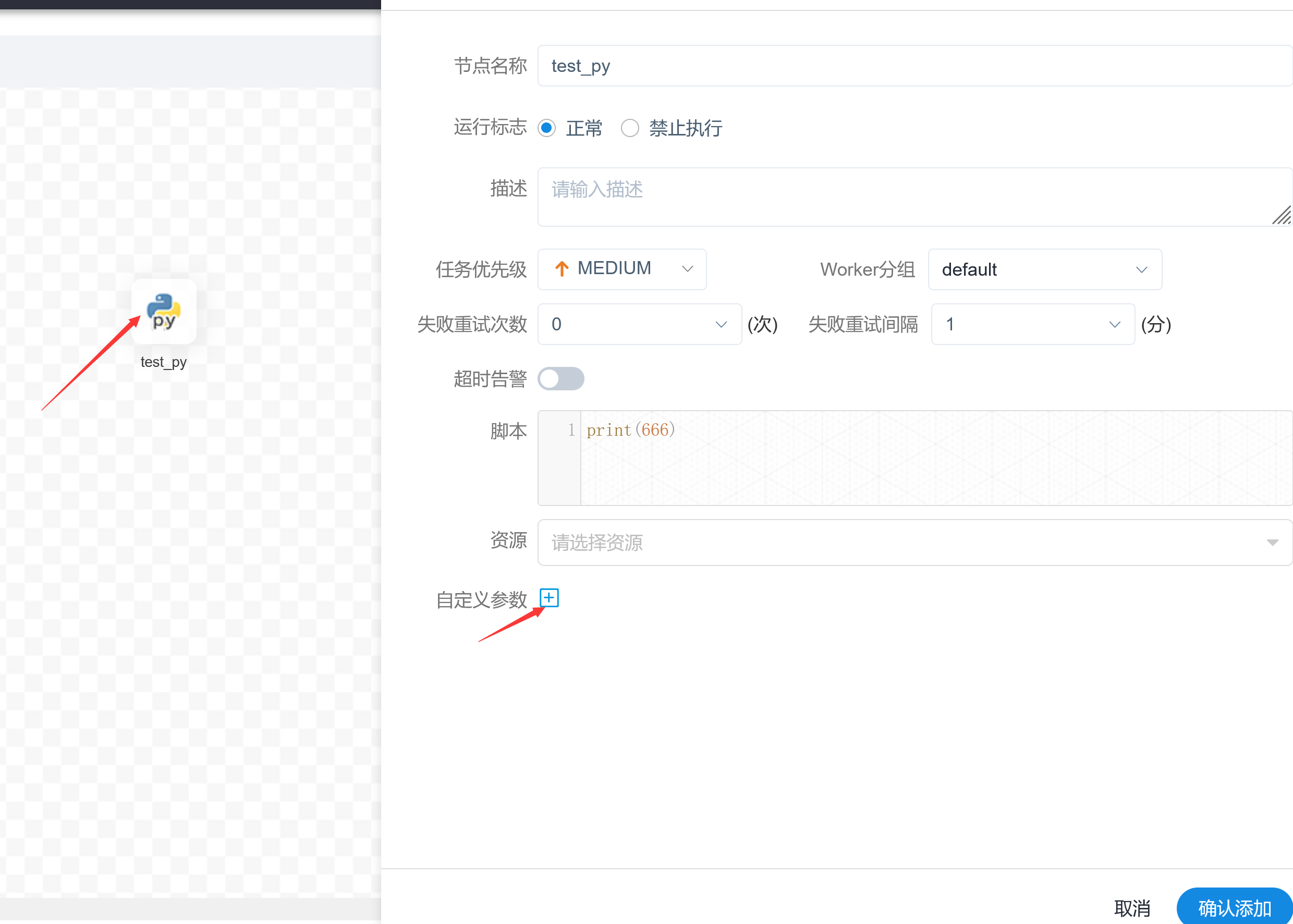

如果想要在本地参数中调用系统内置参数,将内置参数对应的值填到value中,如上图中的${biz_date}以及${curdate}
参数的引用
DolphinScheduler 提供参数间相互引用的能力,包括:本地参数引用全局参数、上下游参数传递。因为有引用的存在,就涉及当参数名相同时,参数的优先级问题,详见参数优先级
本地任务引用全局参数
本地任务引用全局参数的前提是,你已经定义了全局参数,使用方式和本地参数中的使用方式类似,但是参数的值需要配置成全局参数中的key
如上图中的${biz_date}以及${curdate},就是本地参数引用全局参数的例子。观察上图的最后一行,local_param_bizdate通过
g
l
o
b
a
l
b
i
z
d
a
t
e
来引用全局参数,在
s
h
e
l
l
脚本中可以通过
{global_bizdate}来引用全局参数,在shell脚本中可以通过
globalbizdate来引用全局参数,在shell脚本中可以通过{local_param_bizdate}来引全局变量 global_bizdate的值,或通过JDBC直接将local_param_bizdate的值set进去。同理,local_param通过{local_param}引用上一节中定义的全局参数。biz_date、biz_curdate、system.datetime都是用户自定义的参数,通过{全局参数}进行赋值。
上游任务传递给下游任务
DolphinScheduler 允许在任务间进行参数传递,目前传递方向仅支持上游单向传递给下游。目前支持这个特性的任务类型有:
当定义上游节点时,如果有需要将该节点的结果传递给有依赖关系的下游节点,需要在【当前节点设置】的【自定义参数】设置一个方向是 OUT 的变量。目前我们主要针对 SQL 和 SHELL 节点做了可以向下传递参数的功能。
SQL
prop 为用户指定;方向选择为 OUT,只有当方向为 OUT 时才会被定义为变量输出;数据类型可以根据需要选择不同数据结构;value 部分不需要填写。
如果 SQL 节点的结果只有一行,一个或多个字段,prop 的名字需要和字段名称一致。数据类型可选择为除 LIST 以外的其他类型。变量会选择 SQL 查询结果中的列名中与该变量名称相同的列对应的值。
如果 SQL 节点的结果为多行,一个或多个字段,prop 的名字需要和字段名称一致。数据类型选择为LIST。获取到 SQL 查询结果后会将对应列转化为 LIST,并将该结果转化为 JSON 后作为对应变量的值。
我们再以上图中包含 SQL 节点的流程举例说明:
上图中节点【createParam1】的定义如下:
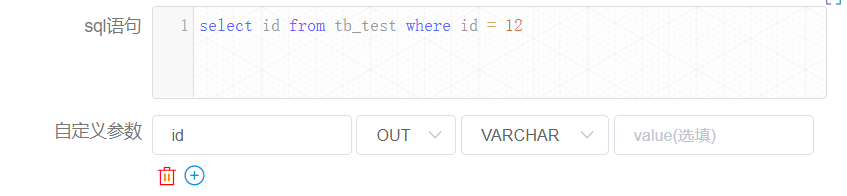
节点【createParam2】的定义如下:
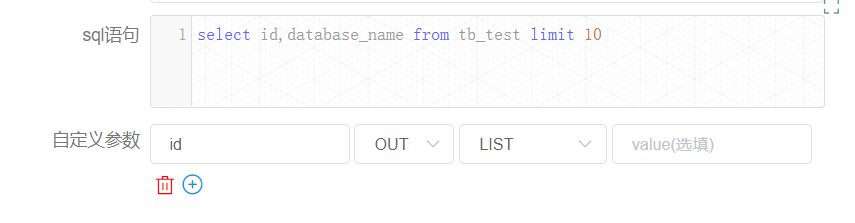
您可以在【工作流实例】页面,找到对应的节点实例,便可以查看该变量的值。
节点实例【createParam1】如下:
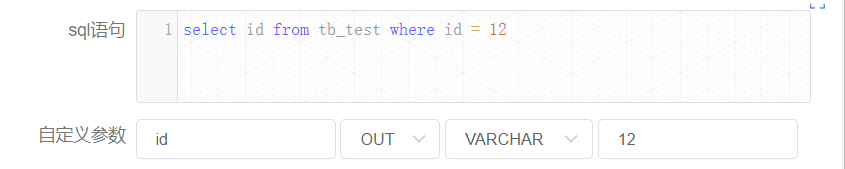
这里当然 “id” 的值会等于 12.
我们再来看节点实例【createParam2】的情况。
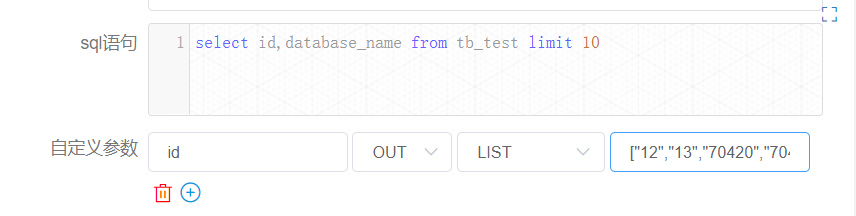
这里只有 “id” 的值。尽管用户定义的 sql 查到的是 “id” 和 “database_name” 两个字段,但是由于只定义了一个为 out 的变量 “id”,所以只会设置一个变量。由于显示的原因,这里已经替您查好了该 list 的长度为 10。
Shell
prop 为用户指定;方向选择为 OUT,只有当方向为 OUT 时才会被定义为变量输出;数据类型可以根据需要选择不同数据结构;value 部分不需要填写。
用户需要传递参数,在定义 shell 脚本时,需要输出格式为 ${setValue(key=value)} 的语句,key 为对应参数的 prop,value 为该参数的值。
例如下图中, 通过 echo '${setValue(trans=hello trans)}', 将’trans’设置为"hello trans", 在下游任务中就可以使用trans这个变量了:
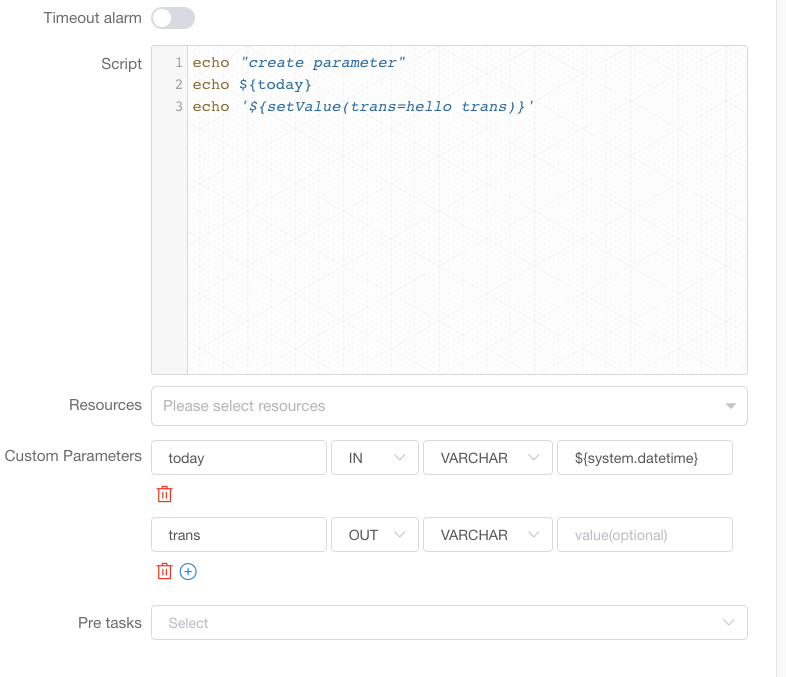
shell 节点定义时当日志检测到 ${setValue(key=value1)} 的格式时,会将 value1 赋值给 key,下游节点便可以直接使用变量 key 的值。同样,您可以在【工作流实例】页面,找到对应的节点实例,便可以查看该变量的值。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6pUPPoeR-1683205971021)(null)]
参数优先级
DolphinScheduler 中所涉及的参数值的定义可能来自三种类型:
因为参数的值存在多个来源,当参数名相同时,就需要会存在参数优先级的问题。DolphinScheduler 参数的优先级从高到低为:全局参数 > 上游任务传递的参数 > 本地参数
在上游任务传递的参数的情况下,由于上游可能存在多个任务向下游传递参数。当上游传递的参数名称相同时:
- 下游节点会优先使用值为非空的参数
- 如果存在多个值为非空的参数,则按照上游任务的完成时间排序,选择完成时间最早的上游任务对应的参数
例子
下面例子向你展示如何使用任务参数传递的优先级问题
1:先以 shell 节点解释第一种情况
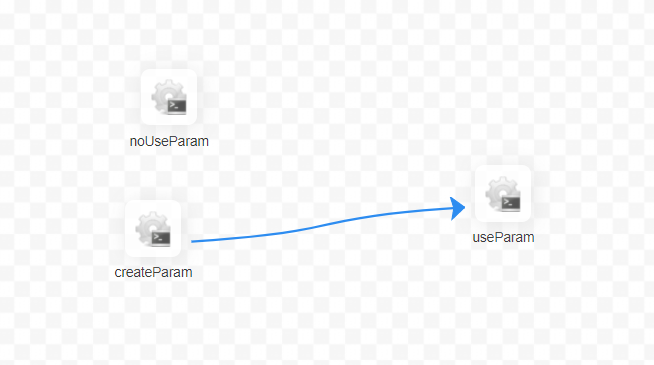
节点 【useParam】可以使用到节点【createParam】中设置的变量。而节点 【useParam】与节点【noUseParam】中并没有依赖关系,所以并不会获取到节点【noUseParam】的变量。上图中只是以 shell 节点作为例子,其他类型节点具有相同的使用规则。
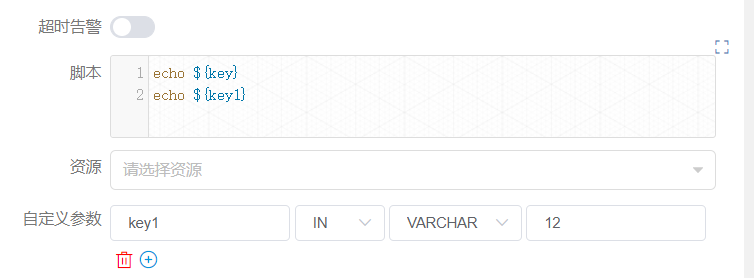
其中节点【createParam】在使用变量时直接使用即可。另外该节点设置了 “key” 和 “key1” 两个变量,这里用户用定义了一个与上游节点传递的变量名相同的变量 key1,并且复制了值为 “12”,但是由于我们设置的优先级的关系,这里的值 “12” 会被抛弃,最终使用上游节点设置的变量值。
2:我们再以 sql 节点来解释另外一种情况
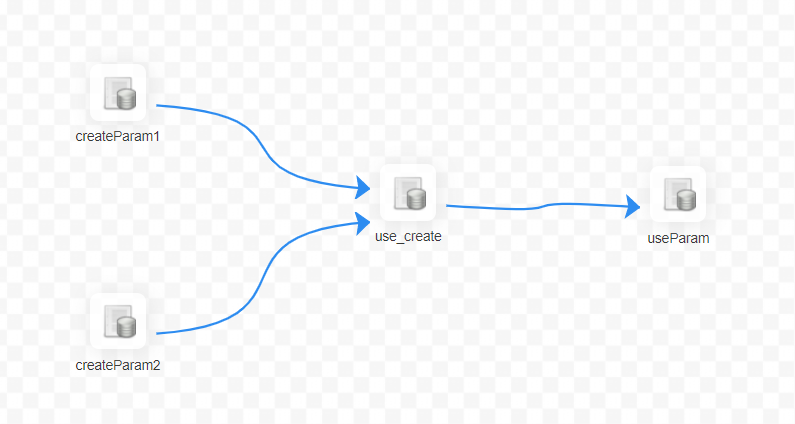
节点【use_create】的定义如下:

“status” 是当前节点设置的节点的自有变量。但是用户在保存时也同样设置了 “status” 变量,并且赋值为 -1。那在该 SQL 执行时,status 的值为优先级更高的 -1。抛弃了节点的自有变量的值。
这里的 “id” 是上游节点设置的变量,用户在节点【createParam1】、节点【createParam2】中设置了相同参数名 “id” 的参数。而节点【use_create】中使用了最先结束的【createParam1】的值。
数据源中心
数据源
数据源中心支持MySQL、POSTGRESQL、HIVE/IMPALA、SPARK、CLICKHOUSE、ORACLE、SQLSERVER等数据源。
- 点击“数据源中心->创建数据源”,根据需求创建不同类型的数据源。
- 点击“测试连接”,测试数据源是否可以连接成功。
MySQL数据源
- 数据源:选择MYSQL
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP主机名:输入连接MySQL的IP
- 端口:输入连接MySQL的端口
- 用户名:设置连接MySQL的用户名
- 密码:设置连接MySQL的密码
- 数据库名:输入连接MySQL的数据库名称
- Jdbc连接参数:用于MySQL连接的参数设置,以JSON形式填写
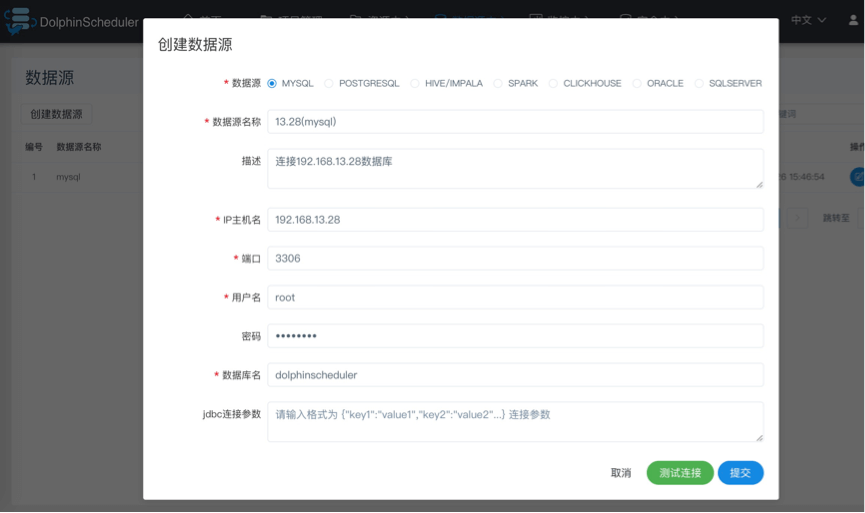
POSTGRESQL数据源
- 数据源:选择POSTGRESQL
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP/主机名:输入连接POSTGRESQL的IP
- 端口:输入连接POSTGRESQL的端口
- 用户名:设置连接POSTGRESQL的用户名
- 密码:设置连接POSTGRESQL的密码
- 数据库名:输入连接POSTGRESQL的数据库名称
- Jdbc连接参数:用于POSTGRESQL连接的参数设置,以JSON形式填写
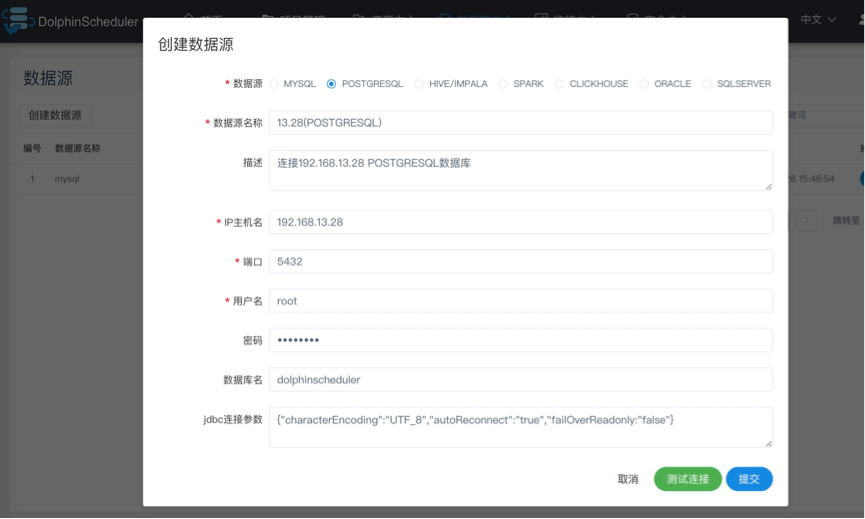
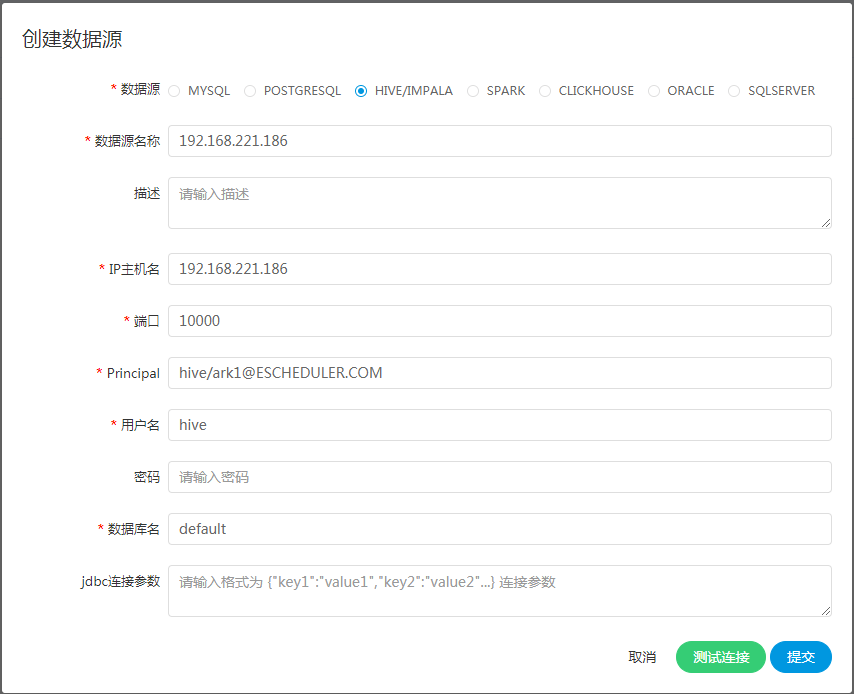
HIVE数据源
使用HiveServer2
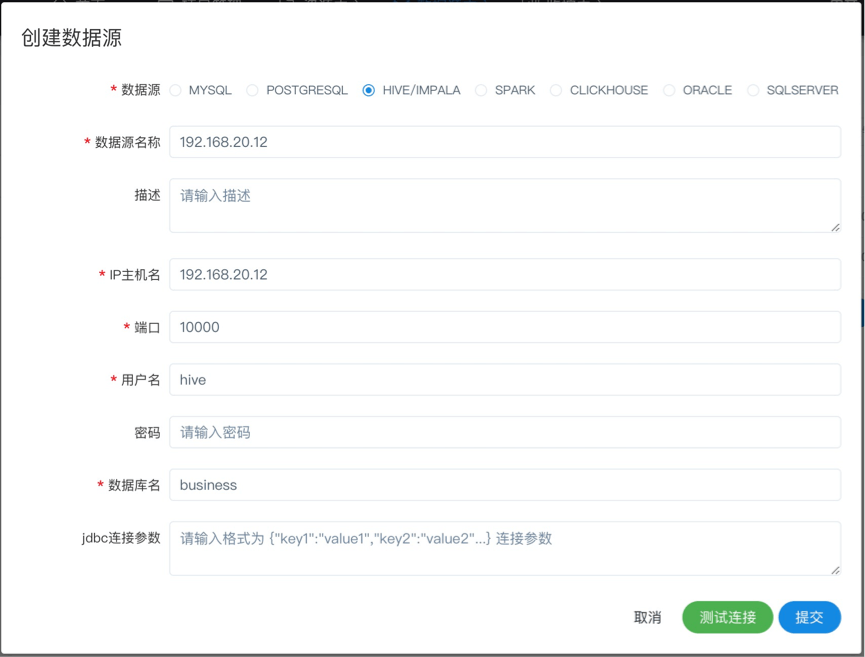
- 数据源:选择HIVE
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP/主机名:输入连接HIVE的IP
- 端口:输入连接HIVE的端口
- 用户名:设置连接HIVE的用户名
- 密码:设置连接HIVE的密码
- 数据库名:输入连接HIVE的数据库名称
- Jdbc连接参数:用于HIVE连接的参数设置,以JSON形式填写
使用HiveServer2 HA Zookeeper
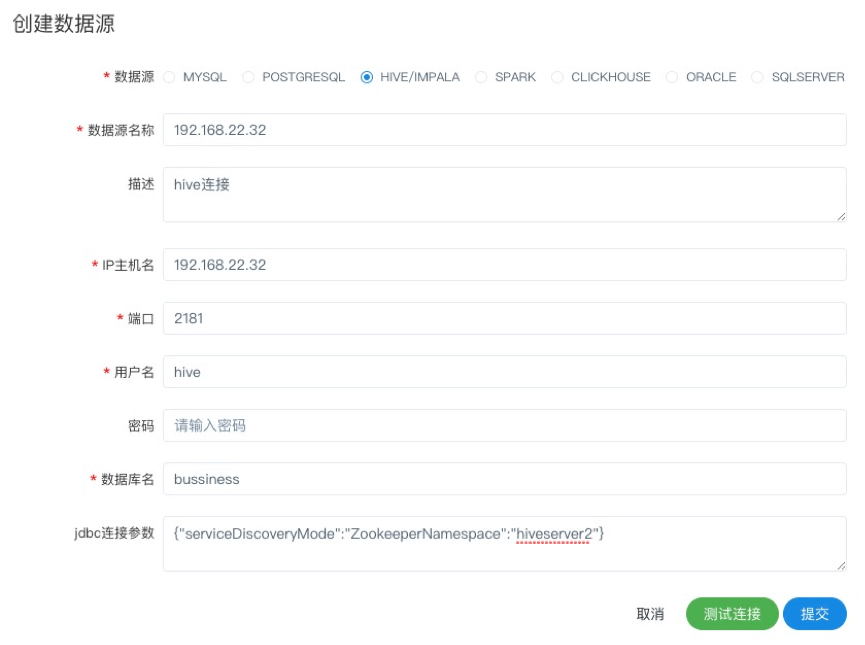
注意:如果开启了kerberos,则需要填写 Principal
Spark数据源
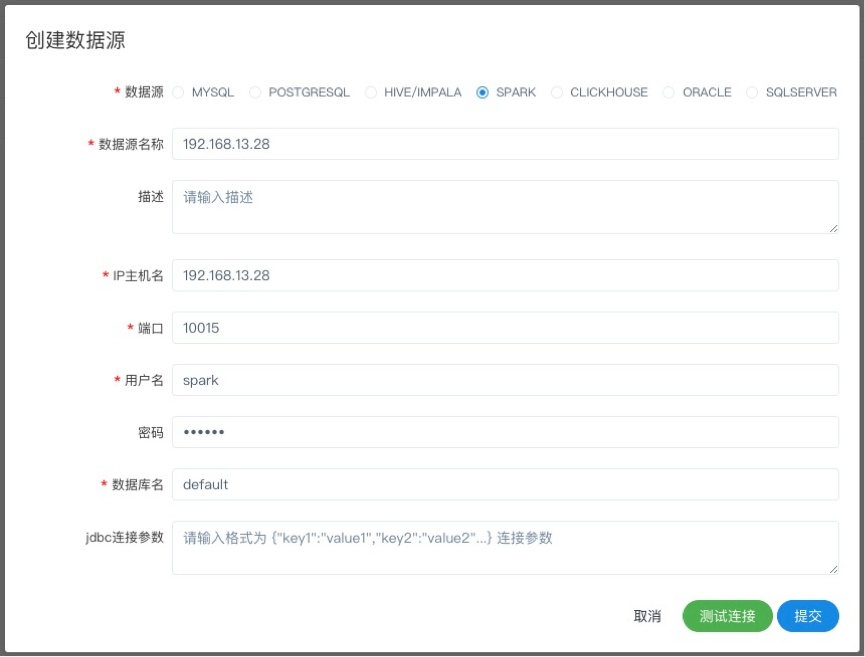
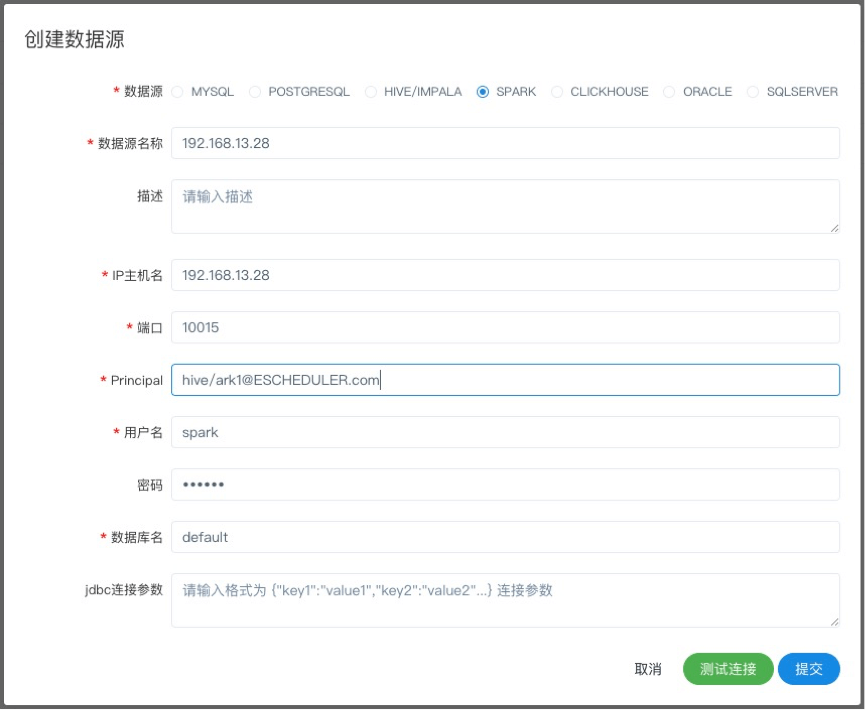
- 数据源:选择Spark
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP/主机名:输入连接Spark的IP
- 端口:输入连接Spark的端口
- 用户名:设置连接Spark的用户名
- 密码:设置连接Spark的密码
- 数据库名:输入连接Spark的数据库名称
- Jdbc连接参数:用于Spark连接的参数设置,以JSON形式填写
注意:如果开启了kerberos,则需要填写 Principal
告警
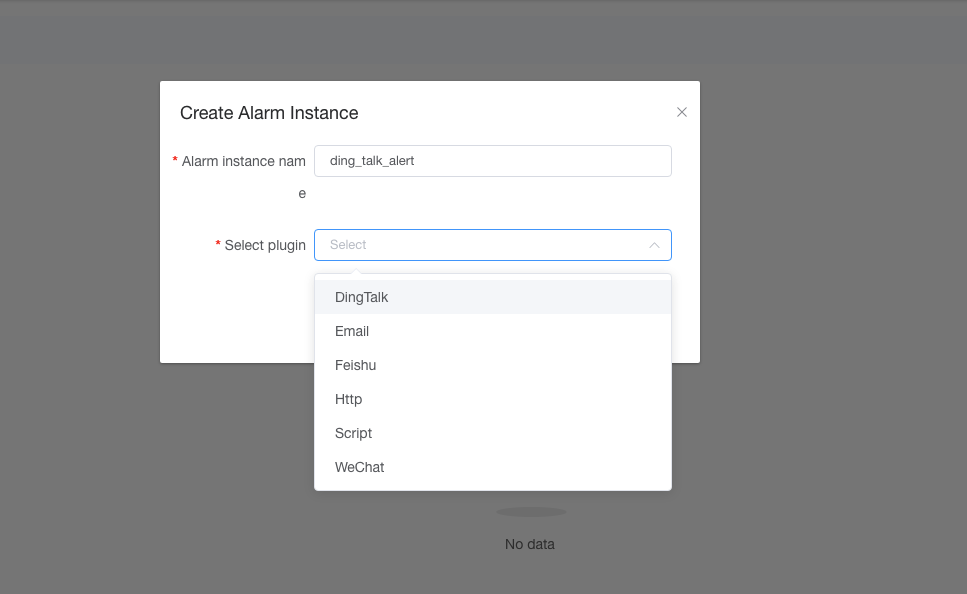
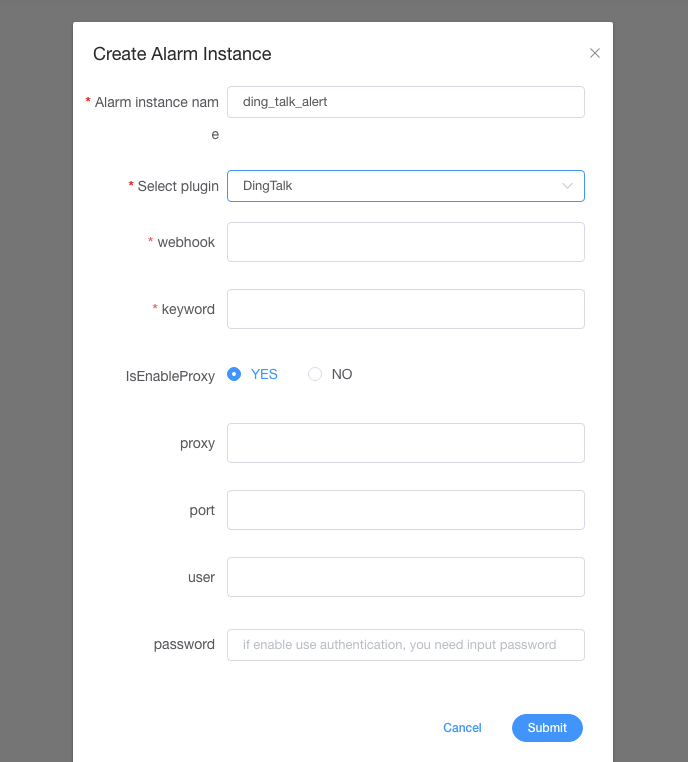
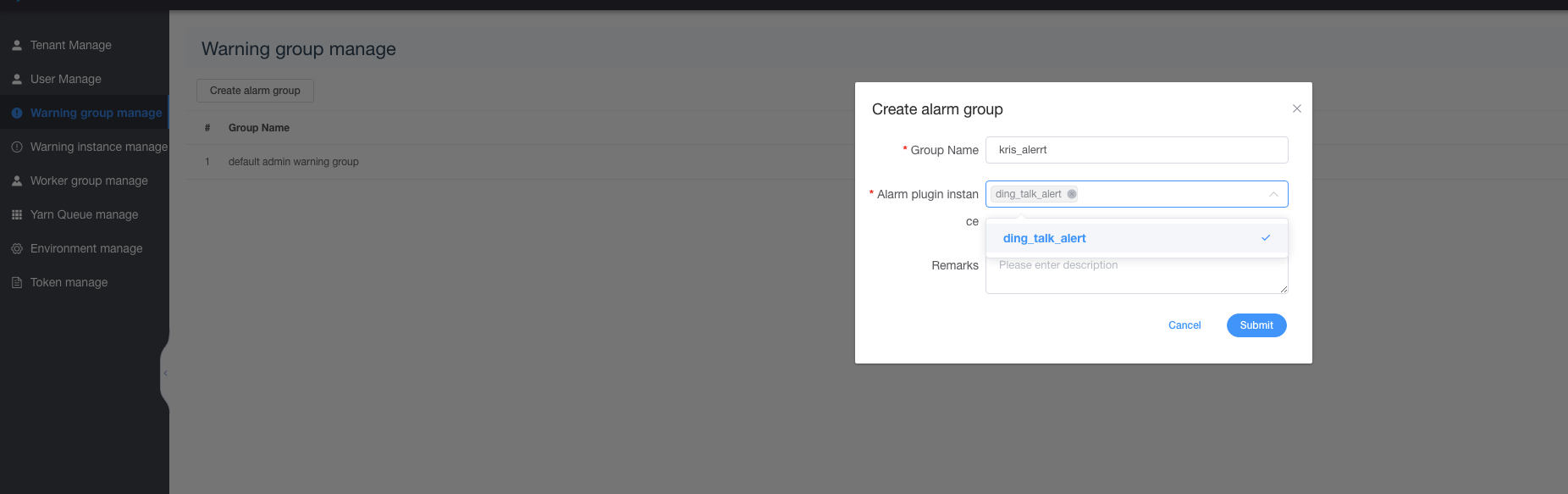
如何创建告警插件以及告警组
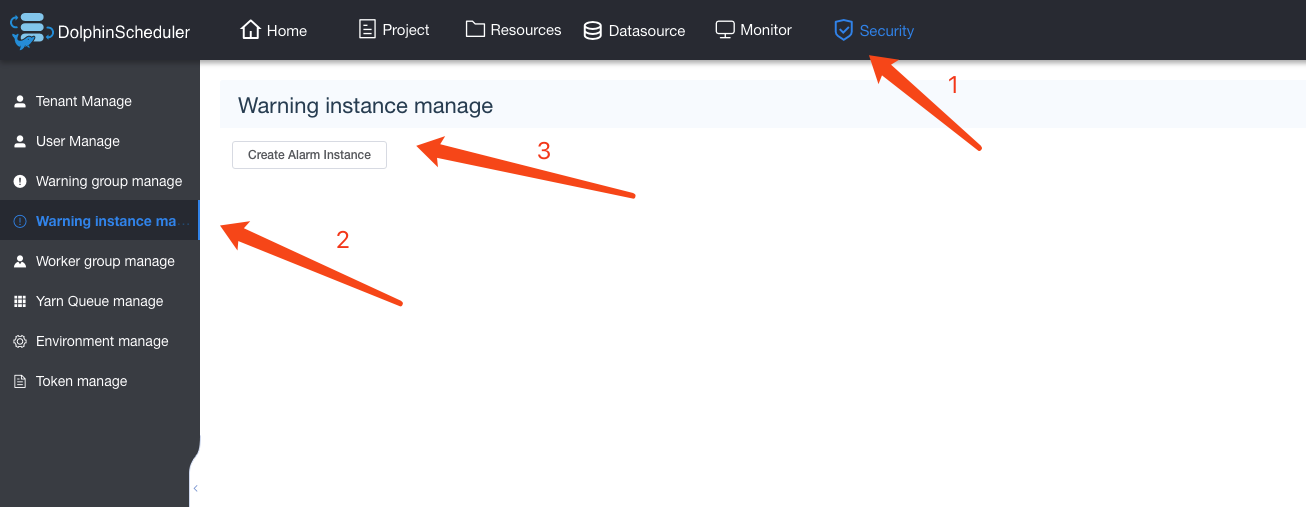
在2.0.0版本中,用户需要创建告警实例,然后同告警组进行关联,一个告警组可以使用多个告警实例,我们会逐一进行进行告警通知。
首先需要进入到安全中心,选择告警组管理,然后点击左侧的告警实例管理,然后创建一个告警实例,然后选择对应的告警插件,填写相关告警参数。
然后选择告警组管理,创建告警组,选择相应的告警实例即可。
企业微信
如果您需要使用到企业微信进行告警,请在安装完成后,修改 alert.properties 文件,然后重启 alert 服务即可。企业微信的配置样例如下
# 设置企业微信告警功能是否开启:开启为 true,否则为 false
enterprise.wechat.enable="true"
# 设置 corpid,每个企业都拥有唯一的 corpid,获取此信息可在管理后台 “我的企业” - “企业信息” 下查看 “企业 ID”(需要有管理员权限)
enterprise.wechat.corp.id="xxx"
# 设置 secret,secret 是企业应用里面用于保障数据安全的 “钥匙”,每一个应用都有一个独立的访问密钥
enterprise.wechat.secret="xxx"
# 设置 agentid,每个应用都有唯一的 agentid。在管理后台 -> “应用与小程序” -> “应用”,点进某个应用,即可看到 agentid
enterprise.wechat.agent.id="xxxx"
# 设置 userid,多个用逗号分隔。每个成员都有唯一的 userid,即所谓 “帐号”。在管理后台 -> “通讯录” -> 点进某个成员的详情页,可以看到
enterprise.wechat.users=zhangsan,lisi
# 获取 access\_token 的地址,使用如下例子无需修改
enterprise.wechat.token.url=https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid={corpId}&corpsecret={secret}
# 发送应用消息地址,使用如下例子无需改动
enterprise.wechat.push.url=https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token={token}
# 发送消息格式,无需改动
enterprise.wechat.user.send.msg={\"touser\":\"{toUser}\",\"agentid\":\"{agentId}\",\"msgtype\":\"markdown\",\"markdown\":{\"content\":\"{msg}\"}}
资源中心
如果需要用到资源上传功能,针对单机可以选择本地文件目录作为上传文件夹(此操作不需要部署 Hadoop)。当然也可以选择上传到 Hadoop or MinIO 集群上,此时则需要有Hadoop (2.6+) 或者 MinIO 等相关环境
*注意:*
- 如果用到资源上传的功能,那么 安装部署中,部署用户需要有这部分的操作权限
- 如果 Hadoop 集群的 NameNode 配置了 HA 的话,需要开启 HDFS 类型的资源上传,同时需要将 Hadoop 集群下的
core-site.xml和hdfs-site.xml复制到/opt/dolphinscheduler/conf,非 NameNode HA 跳过次步骤
hdfs资源配置
- 上传资源文件和udf函数,所有上传的文件和资源都会被存储到hdfs上,所以需要以下配置项:
conf/common.properties
# Users who have permission to create directories under the HDFS root path
hdfs.root.user=hdfs
# data base dir, resource file will store to this hadoop hdfs path, self configuration, please make sure the directory exists on hdfs and have read write permissions。"/dolphinscheduler" is recommended
resource.upload.path=/dolphinscheduler
# resource storage type : HDFS,S3,NONE
resource.storage.type=HDFS
# whether kerberos starts
hadoop.security.authentication.startup.state=false
# java.security.krb5.conf path
java.security.krb5.conf.path=/opt/krb5.conf
# loginUserFromKeytab user
login.user.keytab.username=hdfs-mycluster@ESZ.COM
# loginUserFromKeytab path
login.user.keytab.path=/opt/hdfs.headless.keytab
# if resource.storage.type is HDFS,and your Hadoop Cluster NameNode has HA enabled, you need to put core-site.xml and hdfs-site.xml in the installPath/conf directory. In this example, it is placed under /opt/soft/dolphinscheduler/conf, and configure the namenode cluster name; if the NameNode is not HA, modify it to a specific IP or host name.
# if resource.storage.type is S3,write S3 address,HA,for example :s3a://dolphinscheduler,
# Note,s3 be sure to create the root directory /dolphinscheduler
fs.defaultFS=hdfs://mycluster:8020
#resourcemanager ha note this need ips , this empty if single
yarn.resourcemanager.ha.rm.ids=192.168.xx.xx,192.168.xx.xx
# If it is a single resourcemanager, you only need to configure one host name. If it is resourcemanager HA, the default configuration is fine
yarn.application.status.address=http://xxxx:8088/ws/v1/cluster/apps/%s
文件管理
是对各种资源文件的管理,包括创建基本的txt/log/sh/conf/py/java等文件、上传jar包等各种类型文件,可进行编辑、重命名、下载、删除等操作。
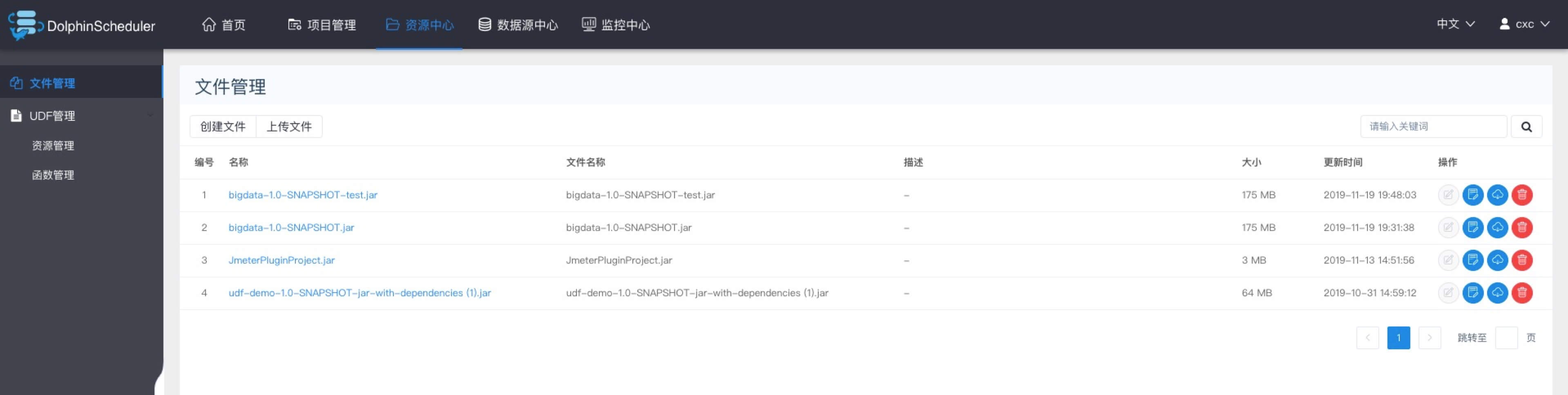
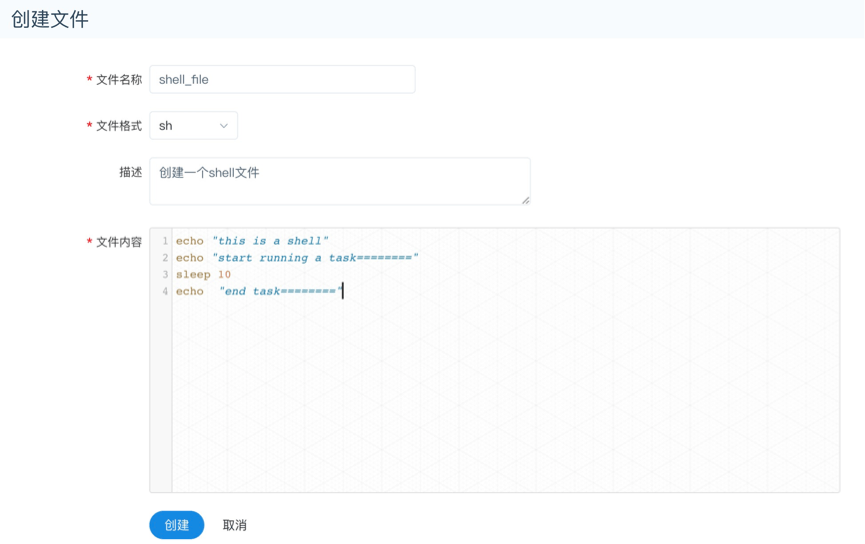
- 创建文件
文件格式支持以下几种类型:txt、log、sh、conf、cfg、py、java、sql、xml、hql、properties
- 上传文件
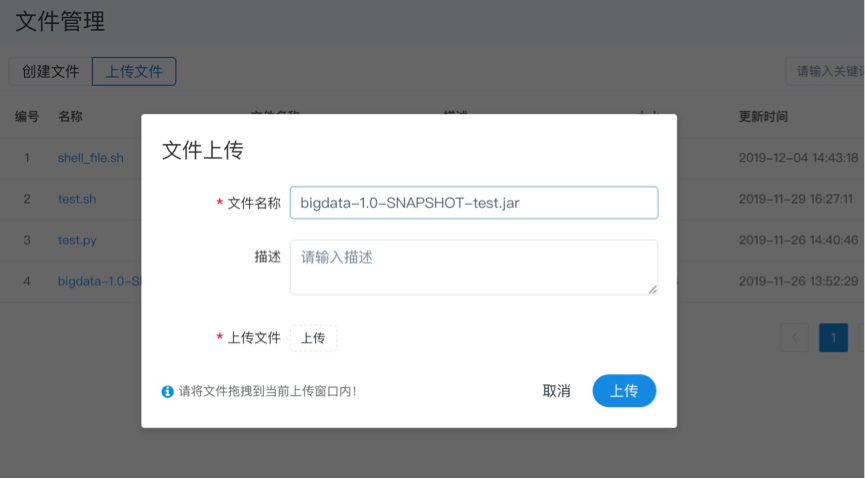
上传文件:点击"上传文件"按钮进行上传,将文件拖拽到上传区域,文件名会自动以上传的文件名称补全
- 文件查看
对可查看的文件类型,点击文件名称,可查看文件详情
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rUFXelKK-1683205976507)(null)]
- 下载文件
点击文件列表的"下载"按钮下载文件或者在文件详情中点击右上角"下载"按钮下载文件
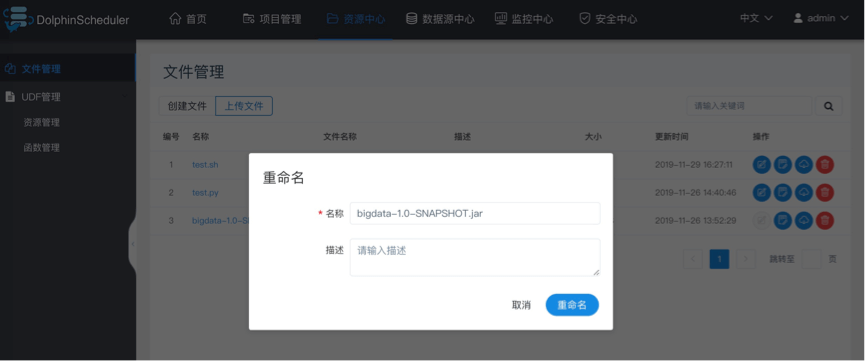
- 文件重命名
- 删除
文件列表->点击"删除"按钮,删除指定文件
UDF管理
资源管理
资源管理和文件管理功能类似,不同之处是资源管理是上传的UDF函数,文件管理上传的是用户程序,脚本及配置文件 操作功能:重命名、下载、删除。
- 上传udf资源
和上传文件相同。
函数管理
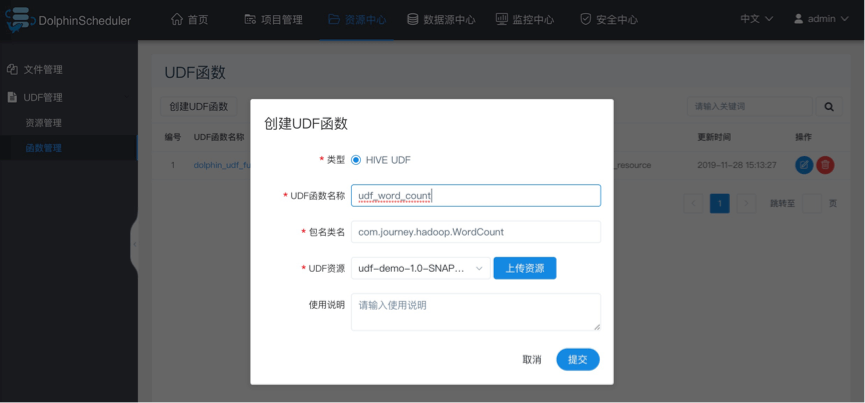
- 创建udf函数
点击“创建UDF函数”,输入udf函数参数,选择udf资源,点击“提交”,创建udf函数。 目前只支持HIVE的临时UDF函数
- UDF函数名称:输入UDF函数时的名称
- 包名类名:输入UDF函数的全路径
- UDF资源:设置创建的UDF对应的资源文件
监控中心
服务管理
- 服务管理主要是对系统中的各个服务的健康状况和基本信息的监控和显示
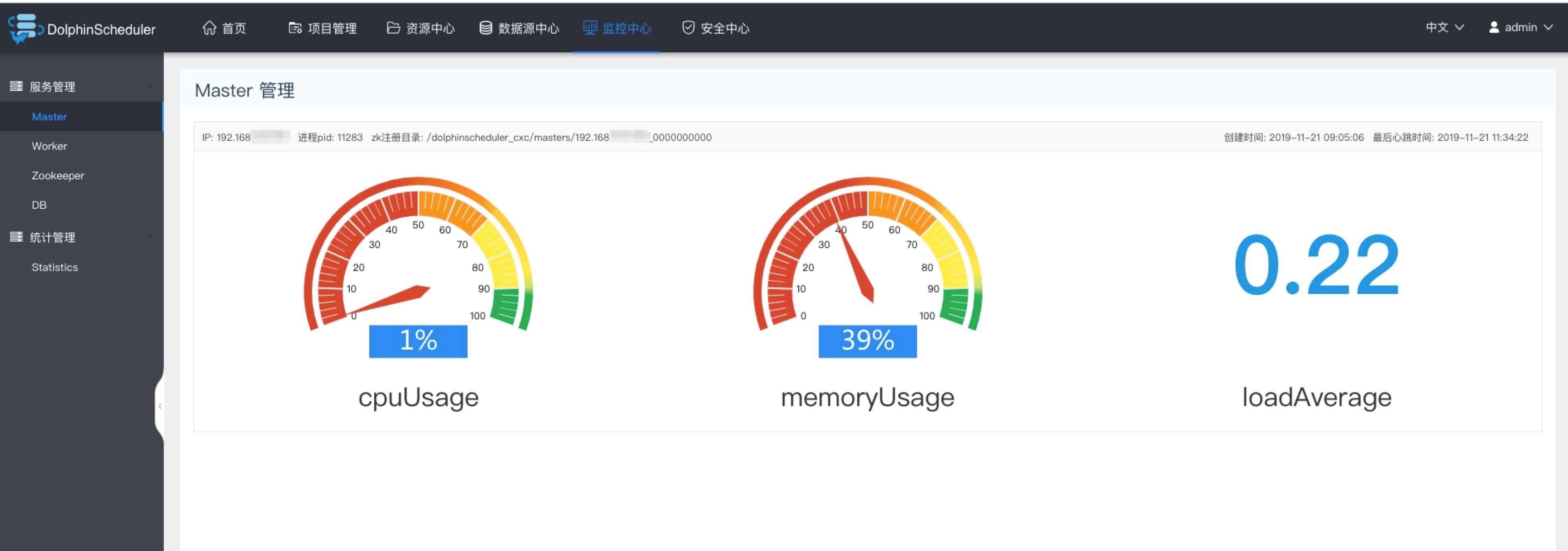
master监控
- 主要是master的相关信息。
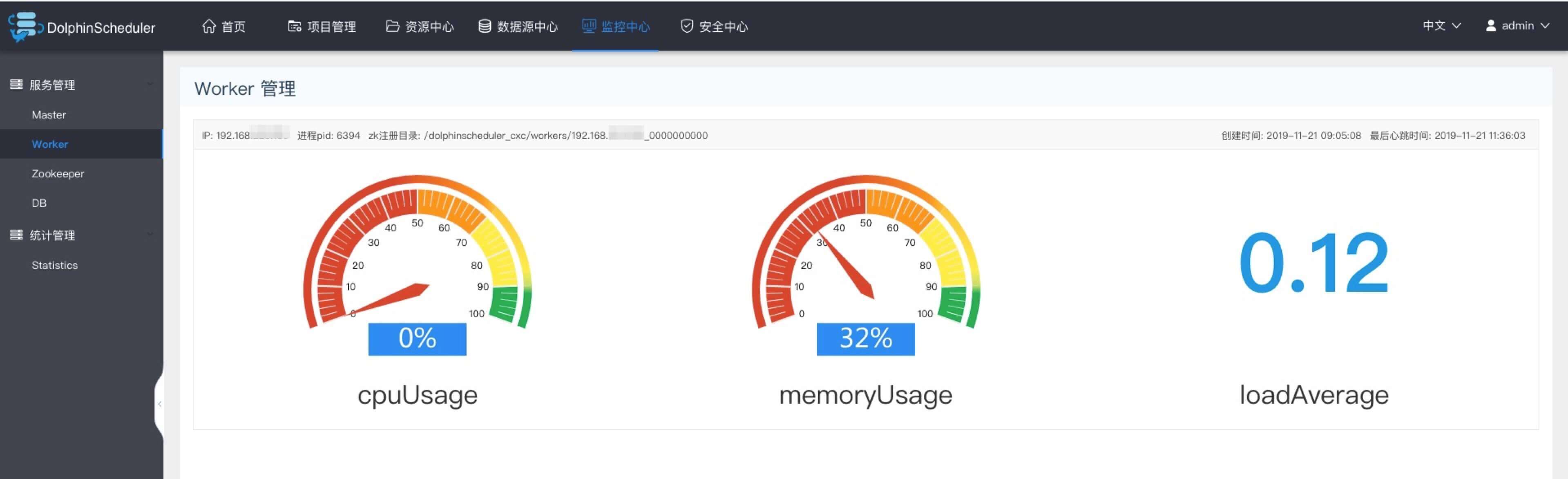
worker监控
- 主要是worker的相关信息。
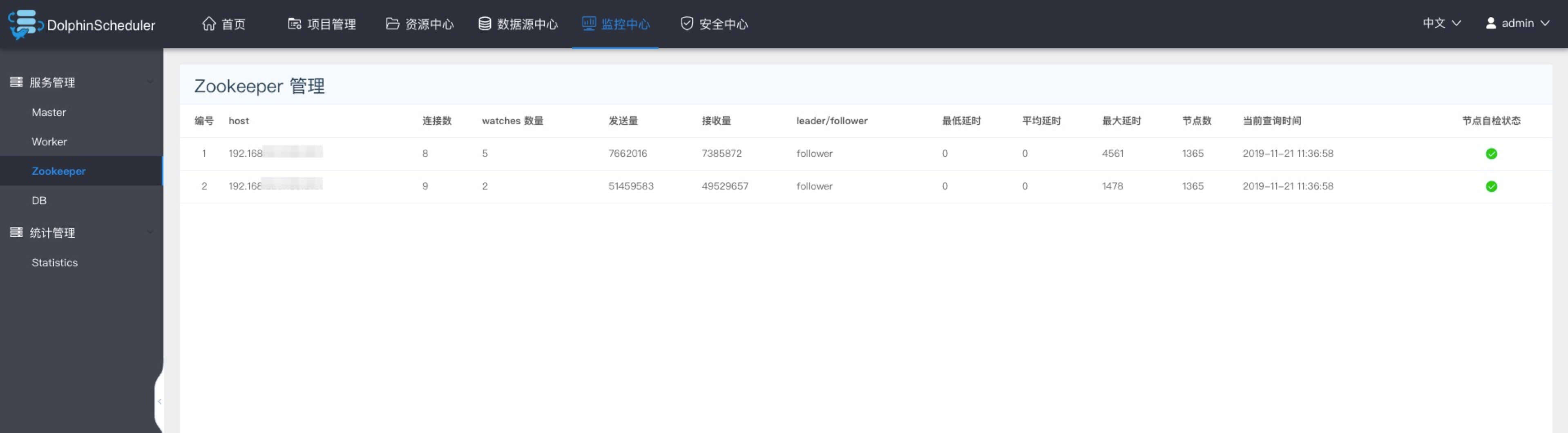
Zookeeper监控
- 主要是zookpeeper中各个worker和master的相关配置信息。
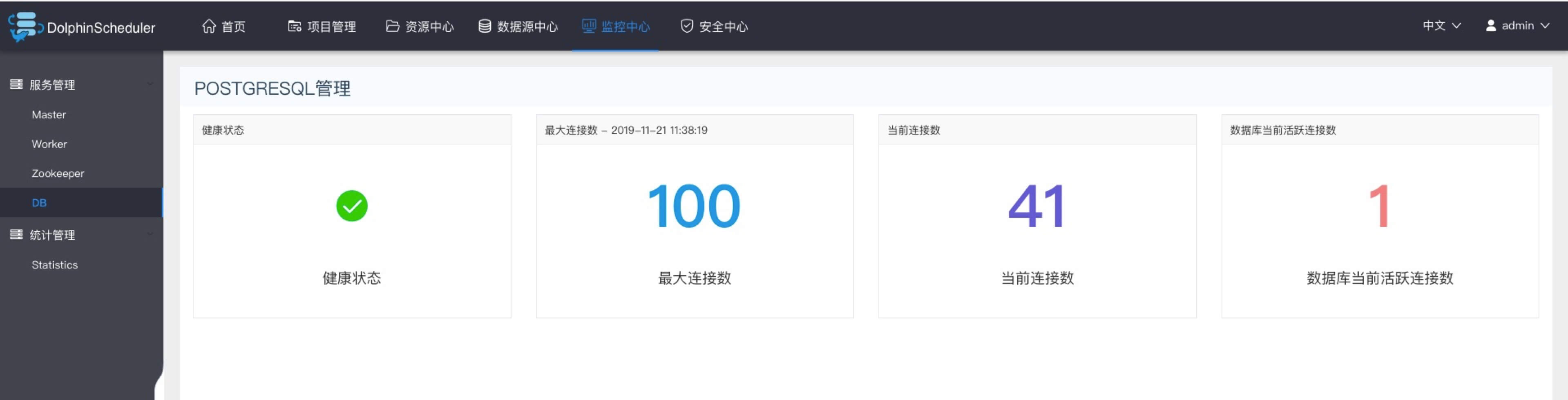
DB监控
- 主要是DB的健康状况
统计管理
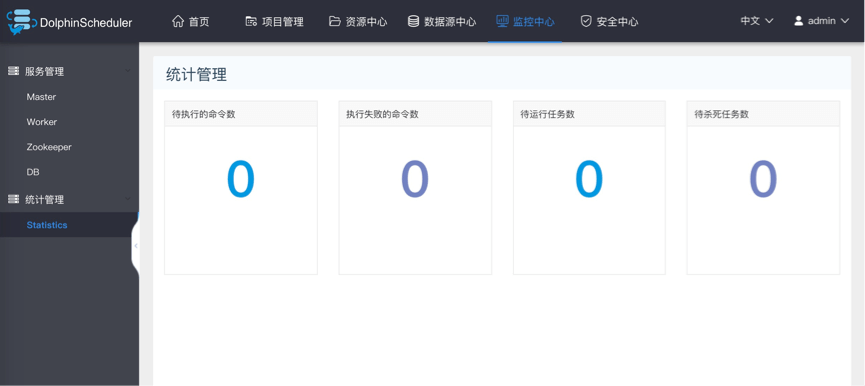
- 待执行命令数:统计t_ds_command表的数据
- 执行失败的命令数:统计t_ds_error_command表的数据
- 待运行任务数:统计Zookeeper中task_queue的数据
- 待杀死任务数:统计Zookeeper中task_kill的数据
安全中心(权限系统)
- 安全中心只有管理员账户才有权限操作,分别有队列管理、租户管理、用户管理、告警组管理、worker分组管理、令牌管理等功能,在用户管理模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1222
1222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









