









一、RabbitMQ 核心原理与架构
1. 核心组件与工作流程
RabbitMQ 基于 AMQP 协议,核心组件包括 生产者(Producer)、交换机(Exchange)、队列(Queue) 和 消费者(Consumer)。其消息传递流程如下:
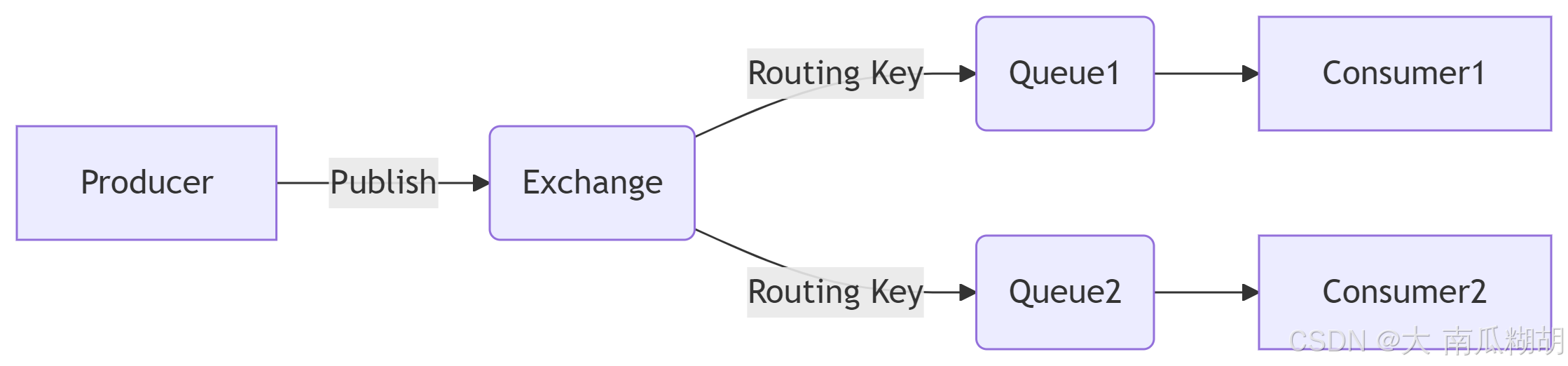
-
生产者:发送消息到交换机(如订单系统发送支付成功事件)。
-
交换机:根据类型(
direct/fanout/topic)和路由键(Routing Key)分发消息到队列。 -
队列:缓存消息,等待消费者处理。
-
消费者:从队列拉取或接收推送的消息进行处理(如库存服务扣减库存)。
2. 高性能与高可用设计
-
高性能:
-
内存存储:默认将消息缓存在内存,单机支持每秒数万条消息。
-
多路复用(Channel):单 TCP 连接支持多虚拟通道,减少资源消耗。
-
-
高可用:
-
集群模式:多节点组成集群,单节点故障不影响整体服务。
-
镜像队列:队列数据在集群内复制,防止数据丢失。
-
二、消息可靠性保障
1. 防止消息丢失
通过 持久化、生产者确认(Confirm) 和 消费者手动 ACK 三重机制保障:
// 1. 队列持久化
channel.queueDeclare("order_queue", true, false, false, null);
// 2. 消息持久化
channel.basicPublish(exchange, "order", MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes());
// 3. 开启生产者确认
channel.confirmSelect();
channel.addConfirmListener((sequence, multiple) -> {
// 消息成功到达 Broker
}, (sequence, multiple) -> {
// 消息未到达 Broker,需重试
});
// 4. 消费者手动 ACK
channel.basicConsume("order_queue", false, (consumerTag, delivery) -> {
processOrder(delivery.getBody());
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
});2. 幂等性设计
-
原理:通过唯一标识(如订单 ID)或状态机确保多次处理结果一致。
-
实现示例:
// 数据库唯一约束 String orderId = "ORDER_123"; if (orderService.checkDuplicate(orderId)) { return; // 已处理,直接跳过 } orderService.processOrder(orderId);
三、消息有序性与延迟队列
1. 保证消息有序性
-
单一队列 + 单一消费者:同一队列内消息按 FIFO 顺序处理。
-
哈希路由:将同一订单 ID 的消息路由到固定队列:
String orderId = "ORDER_123"; String routingKey = "order." + (orderId.hashCode() % 10); // 路由到固定队列 channel.basicPublish("order_exchange", routingKey, null, message.getBytes());
2. 延迟队列实现
-
死信队列(DLX):消息超时后自动转发到死信队列:
// 设置队列 TTL 和死信交换机 Map<String, Object> args = new HashMap<>(); args.put("x-message-ttl", 60000); // 消息 60 秒后过期 args.put("x-dead-letter-exchange", "dlx_exchange"); channel.queueDeclare("delay_queue", true, false, false, args);
四、消费者模式:PUSH vs PULL
1. PUSH 模式(默认)
-
特点:RabbitMQ 主动推送消息给消费者。
-
适用场景:实时性要求高的任务(如支付通知)。
channel.basicConsume("order_queue", false, (consumerTag, delivery) -> { process(delivery.getBody()); channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false); }, consumerTag -> {});
2. PULL 模式
-
特点:消费者按需拉取消息。
-
适用场景:批量处理任务(如生成报表)。
GetResponse response = channel.basicGet("report_queue", false); if (response != null) { generateReport(response.getBody()); channel.basicAck(response.getEnvelope().getDeliveryTag(), false); }
五、消息积压解决方案
1. 千万级消息堆积处理
-
增加消费者:水平扩展消费者实例,提升并发能力。
-
惰性队列:消息直接写入磁盘,避免内存溢出:
Map<String, Object> args = new HashMap<>(); args.put("x-queue-mode", "lazy"); channel.queueDeclare("lazy_queue", true, false, false, args); -
批量消费:单次拉取多条消息:
channel.basicQos(100); // 每次预取 100 条
2. 常见误区
-
误区 1:盲目增加消费者,导致数据库连接池耗尽。
-
解决:结合下游服务容量评估消费者数量。
-
-
误区 2:未设置消息 TTL,导致无效消息堆积。
-
解决:为队列或消息设置合理的过期时间。
-
六、实战场景案例
1. 电商订单超时关闭
-
需求:用户下单后 15 分钟未支付则自动关闭订单。
-
实现:
// 发送延迟消息 Map<String, Object> headers = new HashMap<>(); headers.put("x-delay", 900000); // 15 分钟延迟 channel.basicPublish("delayed_exchange", "order", new AMQP.BasicProperties.Builder().headers(headers).build(), message.getBytes());
2. 日志异步处理
-
需求:异步处理海量日志,避免阻塞主业务。
-
配置:
// 使用惰性队列防止内存溢出 channel.queueDeclare("log_queue", true, false, false, Collections.singletonMap("x-queue-mode", "lazy"));
3. 秒杀库存扣减
-
需求:高并发下保证库存准确性。
-
实现:
// 消费者批量扣减库存 channel.basicQos(100); // 每次处理 100 条 channel.basicConsume("seckill_queue", false, (consumerTag, delivery) -> { batchUpdateStock(delivery.getBody()); channel.basicAck(delivery.getEnvelope().getDeliveryTag(), true); // 批量 ACK });
七、总结
RabbitMQ 的核心价值在于 解耦、异步 和 削峰填谷。通过合理配置交换机、队列、消费者模式及可靠性机制,可应对复杂业务场景。对于消息积压,需结合业务特点选择扩展消费者、惰性队列或异步处理方案。
避坑指南:
-
始终开启持久化和手动 ACK。
-
避免无界队列,防止内存溢出。
-
幂等性设计是分布式系统的必备能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









