







一.Hadoop生态圈
Hadoop生态圈是围绕Hadoop构建的一系列开源软件组件和工具,用于处理大数据的存储、处理、管理和分析。Hadoop是一个能够对大量数据进行分布式处理的软件框架。具有 可靠、高效、可伸缩的特点。Hadoop的核心是HDFS和Mapreduce,hadoop2.0还包括YARN。以下是Hadoop生态圈中一些常见的组件:
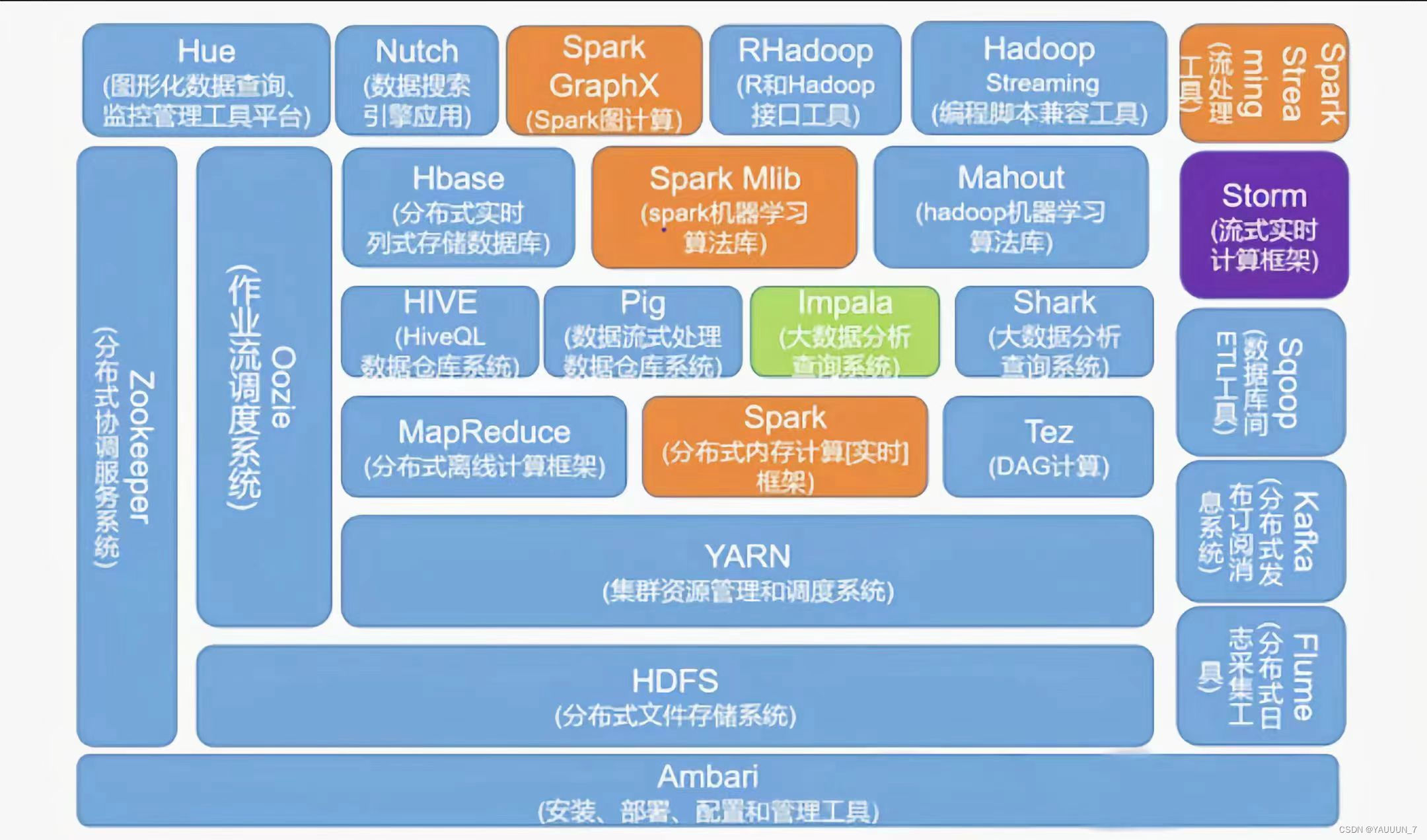
1. HDFS(Hadoop分布式文件系统):用于存储大规模数据的分布式文件系统,提供高容错性和高可靠性。
2. MapReduce:Hadoop的计算框架,用于并行处理大规模数据集。
3. YARN(Yet Another Resource Negotiator):Hadoop的集群资源管理器,用于管理和调度集群上的资源。
4. Hive:基于Hadoop的数据仓库基础设施,提供类SQL查询语言(HiveQL)来进行数据分析和查询。
5. Pig:用于大规模数据分析的高级编程语言和平台,可以将复杂的数据处理流程转化为简单的脚本。
6. HBase:分布式、可扩展的列式数据库,适用于大规模结构化数据的实时读写操作。
7. ZooKeeper:用于分布式应用程序的协调服务,提供配置管理、命名服务、分布式同步和组服务等功能。
8. Spark:高速大数据处理框架,支持内存计算和更广泛的数据处理模型,比传统的MapReduce更快速。
9. Kafka:高吞吐量的分布式消息系统,用于发布和订阅流数据。
10. Flume:用于可靠地收集、聚合和移动大规模日志和事件数据的分布式系统。
11. Storm:用于处理实时流数据的分布式计算系统,提供容错性和可扩展性。
12. Sqoop:用于在Hadoop和关系型数据库之间进行数据传输的工具。
13. Oozie:用于协调和管理Hadoop作业流程的工作流调度系统。
14. Maout:用于实现大规模机器学习和数据挖掘的库。
15. Zeppelin:交互式数据分析和可视化的Web界面,支持多种数据处理引擎。
二.spark生态圈及特点
1.spark生态圈
Spark使用Scala语言进行实现,它是一种面向对象、函数式编程语言,能够像操作本地集合对象一样轻松地操作分布式数据集。

1.Spark Core:Spark核心组件,它实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed Datasets,简称RDD)的API 定义,RDD是只读的分区记录的集合,只能基于在稳定物理存储中的数据集和其他已有的RDD上执行确定性操作来创建。
2.Spark SQL:用来操作结构化数据的核心组件,通过Spark SQL可以直接查询Hive、HBase等多种外部数据源中的数据。Spark SQL的重要特点是能够统一处理关系表和RDD。在处理结构化数据时,开发人员无需编写MapReduce程序,直接使用SQL命令就能完成更加复杂的数据查询操作。
3.Spark Streaming:Spark提供的流式计算框架,支持高吞吐量、可容错处理的实时流式数据处理,其核心原理是将流数据分解成一系列短小的批处理作业,每个短小的批处理作业都可以使用Spark Core进行快速处理。Spark Streaming支持多种数据源,例如Kafka、Flume以及TCP套接字等数据源。
4.MLlib:Spark提供的关于机器学习功能的算法程序库,包括分类、回归、聚类、协同过滤算法等,还提供了模型评估、数据导入等额外的功能,开发人员只需了解一定的机器学习算法知识就能进行机器学习方面的开发,降低了学习成本。
5.GraphX:Spark提供的分布式图处理框架,拥有对图计算和图挖掘算法的API接口以及丰富的功能和运算符,极大的方便了对分布式图处
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









