






第21节课 元组、集合与字典
1 元组
元组是一个有序但不可变的序列(元素内容,以及序列长度不可变),使用圆括号()来创建元组。
那我们可以把元组理解为是一个不可变的列表。
既然是序列,那么序列的通用操作(索引、切片、len、in和not int)同样适用于元组。
tup = ()
tup = tuple()
tup = (1,2,3)
lst = [4,5,6]
# 将一个列表转换为元组
tup = tuple(lst)
# 将一个字符串转换为元组
tup = tuple("Hello")
# 如果元组只有一个元素的话
tup = (1) # <class 'int'>
# 加一个逗号
tup = (1,) # <class 'tuple'>
# 也可以不用括号来去创建元组
tup = 7,8,9
# 输入数据时 用逗号分隔
# 输入"1,2,3"
# tup = 1,2,3
# eval执行代码
# 输入"a,b,c"
# tup = a,b,c # NameError: name 'a' is not defined
# 输入"'a','b','c'""
# tup = 'a','b','c'
# tup = eval(input())
def show():
# 多个返回值 实际上 返回的是一个元组对象
return 9,10,11
tup = show()
# 元组的解包
# a,b,c = (9,10,11)# tup
# a = tup[0] b = tup[1] c = tup[2]
a,b,c = show()
print(a,b,c)
print(tup)
print(type(tup)) # <class 'tuple'>
tup = (1,2,3,4,5,6,7,8,9)
# ValueError: too many values to unpack (expected 3)
# a,b,c = tup
# * 多个元组数据被解包时 创建一个列表
a, *b, c = tup
print(a)
print(b)
print(c)
关于不可变的问题,元组中存储的实际上是数据对象在堆内存中的地址,这个存储的地址是不能改变的!同样元组的长度不能改变。但是,如果元组中存储了可变对象的话,那么可变对象内部的数据是可以修改的!
tup = (1,2,3,4)
print(tup[0])
# TypeError: 'tuple' object does not support item assignment
# tup[0] = 666
tup = (1, [2, 3], 4)
print(tup[1])
# TypeError: 'tuple' object does not support item assignment
# tup[1] = [6,7]
tup[1][0] = 8
print(tup) # (1, [8, 3], 4)
既然是不可变,那么元组就不会提供关于增、删和改的操作,顶多有个查
元组对象函数只有两个
- count():统计某一个元素出现的次数
- index():查找元素第一次出现的位置角标,如果没找到则报错
tup = (1,1,1,2,2,3,3,3,3,3)
print(tup.count(3))
print(tup.index(1))
# ValueError: tuple.index(x): x not in tuple
# print(tup.index(4))
# AttributeError: 'tuple' object has no attribute 'sort'
# tup.sort()
关于元组存在的一个必要性
- 因为元组是不可变的,所以今后我们在定义编程数据时,如果发现有些数据其内容是不能修改的,我可能可以考虑使用元组(坐标,时间,属性);可以作为字典的键(作为一种索引)。
- 时间效率更高,同样内容的列表和元组,后者的创建时间会更小;比如,在进行大批量数据处理和分析时。
import timeit
# 计算stmt代码在执行number次后,所用的时间是多少
time1 = timeit.timeit(stmt = "[1,2,3,4,5,6,7,8,9,10]", number = 1000000)
time2 = timeit.timeit(stmt = "(1,2,3,4,5,6,7,8,9,10)", number = 1000000)
print(time1) # 0.03029770008288324
print(time2) # 0.005637900088913739
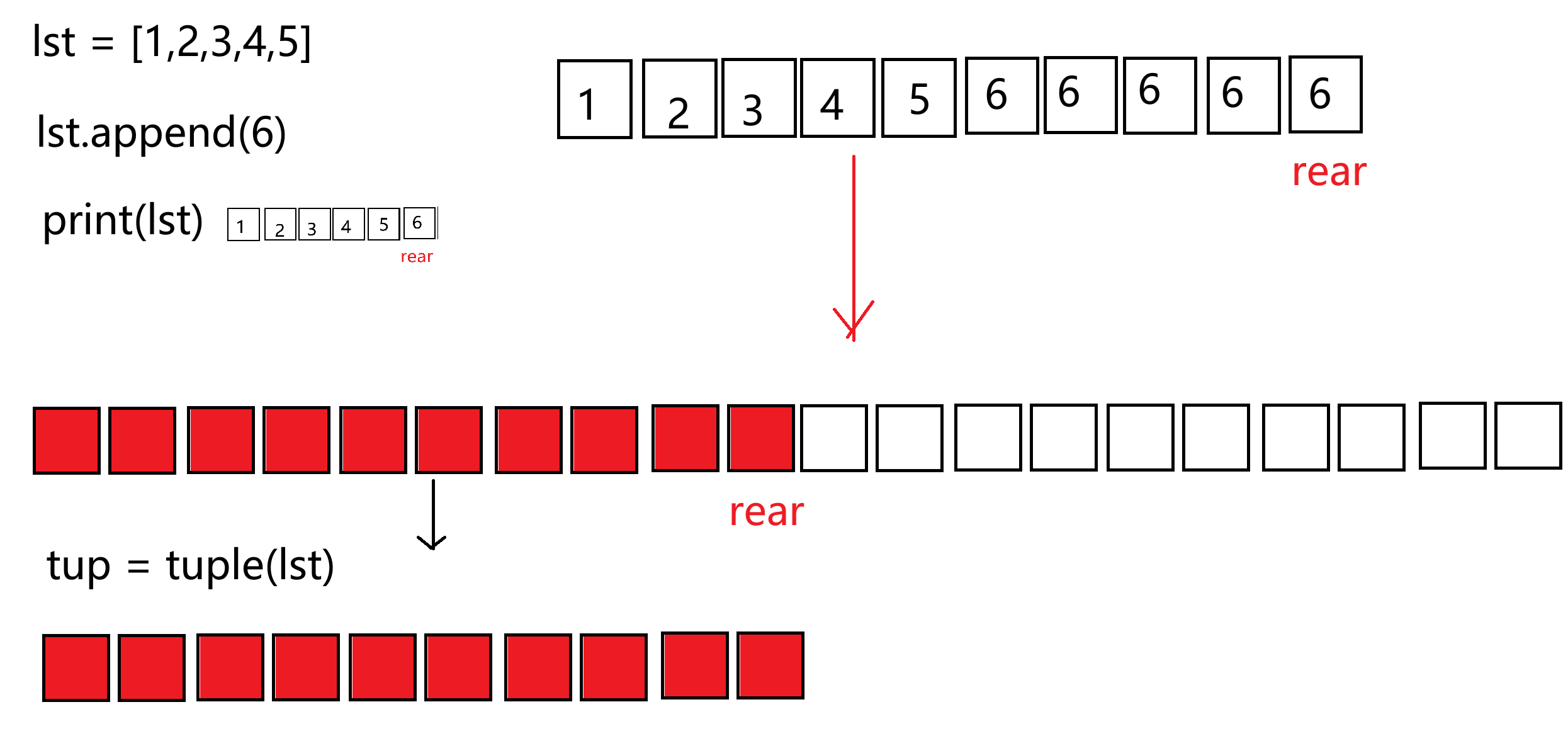
- 内存更小,同样内容的列表和元组,后者所需的内存空间会更小;比如,在进行大批量数据处理和分析时。
import sys
lst = []
for i in range(1,10000):
lst.append(i)
tup = tuple(lst)
# 获取数据对象的内存大小
size1 = sys.getsizeof(lst)
size2 = sys.getsizeof(tup)
print(size1) # 85176 字节 byte
print(size2) # 80032 字节 byte
因为在列表中,除了存储元素之外,还会存储一些长度信息、表尾的信息、闲置位置的信息。
2 集合
集合是一个无序的、不包含重复元素的集合体,使用花括号{}来表示。注意 不是序列!!!
- 无序:集合中的元素没有固定顺序,每次打印集合时,可能元素顺序是不同的
- 不包含重复元素:元素在集合中时唯一存在的
主要应用场景:
- 关于集合数学运算的:交集、并集、差集、子集、超集
- 做重复元素去重操作
st = {} # 字典也是用{}表示的
st = set()
st = {3,1,2,6,5,8,7,9,4} # {1, 2, 3, 4, 5, 6, 7, 8, 9} 不代表排序了 特殊情况
st = {"C","A","E","F","B","D","D"}
lst = [1,2,3,3,4,4,2,1,3,5,2,5,8,3,4,6,8,9,3,4,2]
st = set(lst)
st = set("banana")
# TypeError: 'set' object is not subscriptable
# print(st[0])
print(st)
print(type(st))
关于集合常用操作
- add():向集合中添加一个元素
- remove():在集合中删除一个指定的元素,如果元素不存在则报错
- discard():在集合中删除一个指定的元素,如果元素不存在,不会报错
- update():添加多个元素进入到集合中,列表、元组、其他集合等可迭代的数据对象
- pop():随机删除一个元素
- clear():清空
st = set()
st.add(1)
st.add(3)
st.add(2)
print(st)
st.remove(2)
print(st)
# KeyError: 4
# st.remove(4)
st.update([1,2,3,4,5,6,7,8,9,9,9,1,2,3,4,4,4])
st = {"C","A","E","F","B","D"}
while len(st) != 0:
print(st.pop())
print(st)
关于集合的数学操作
set1 = {1,2,3}
set2 = {3,4,5}
# 并集
print(set1 | set2)
print(set1.union(set2))
print(set2.union(set1))
# 交集
print(set1 & set2)
print(set1.intersection(set2))
print(set2.intersection(set1))
# 差集 在set1中存在但不在set2中存在的元素
print(set1 - set2)
print(set2 - set1)
print(set1.difference(set2))
print(set2.difference(set1))
# 对称差集 获取两个集合中不共同的元素
# 并集 - 交集
print(set1 ^ set2)
print(set2 ^ set1)
print(set1.symmetric_difference(set2))
# 子集与超集的问题
set1 = {1, 2}
set2 = {1, 2, 3}
# set1是否是set2的子集
print(set1 < set2)
# set1是否是set2的真子集
print(set1 <= set2)
# 判断真子集
print(set1.issubset(set2))
print(set1.issuperset(set2))
print(set2.issuperset(set1))
set1 = {1,2,3}
set2 = {2,1,3}
print(set1 == set2) # 判断内容是否相等
延伸:为什么说集合是无序的,且pop是随机的【了解 理解】
在Python中,集合底层的数据结构为哈希表(广义表),说白了也是一个一维数组,只不过不是按照角标顺序进行存储的,而是根据哈希函数算得该元素的哈希值,来决定元素的存储位置。如果元素之间的哈希值一样的话,这个现象叫做哈希冲突,如果出现哈希冲突的话,先看元素是否相等,相等的话就不存储。如果元素不相等,且出现哈希冲突的话:
开放定址法:当发生哈希冲突时,通过一定的探测序列在哈希表中寻找下一个空的位置来存储数据。常见的探测方法有线性探测、二次探测和双重哈希等。【Python集合底层的实现思路】
线性探测:从发生冲突的位置开始,依次向后探测下一个位置,直到找到空位置为止。例如,哈希函数计算出的位置为 i,如果 i 位置已被占用,则依次探测 i+1、i+2、i+3 等位置。
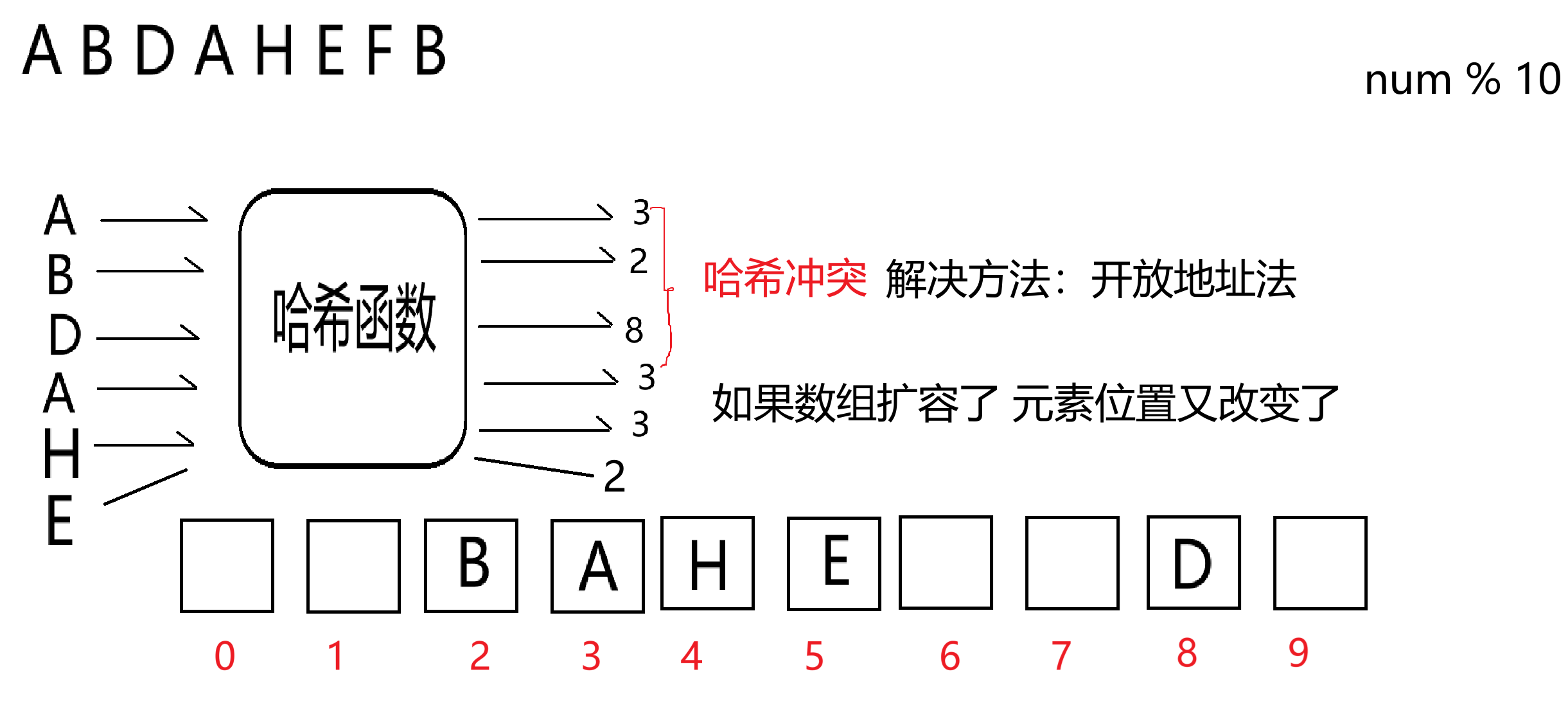
总而言之:哈希函数的策略、哈希冲突的解决方法、哈希表底层的扩容问题,都会导致元素的顺序不能直接确定,这就是集合为什么无序的原因。但是可以确定的是,实际上pop就是从左到右删除。
3 字典
字典是一个无序的键值对的集合,每个键值对之间用逗号,分隔,键和值之间用冒号:分隔,使用花括号{}来表示。所谓的字典,其实就是一个特殊的集合而已。键必须是唯一的,值是可以重复的。也就是说所有键组成一个集合,所有的值组成一个列表。
dic = {"姓名":"张三", "年龄":18, "性别":"男"}
dic = dict(name = "张三", age = 18, sex = "男")
# 可以汉字做标识符 但不推荐
数字 = 3
print(数字)
dic = dict(姓名 = "张三", 年龄 = 18, 性别 = "男")
lst = [("name", "张三"), ("age", 18), ("sex", "男")]
dic = dict(lst)
print(dic)
# 获取字典的内容
print(dic["name"])
# 不存在的键 则报错
# KeyError: 'girlfriend'
# print(dic["girlfriend"])
print(dic.get("name"))
# 可以看到 所谓的键 大胆的理解为 角标
dic = {0:1,1:2,2:3,3:4}
print(dic)
添加或修改字典:通过给不存在的键进行赋值可以添加新的键值对,如果该键已存在,则为修改
dic = {"name":"张三", "age":18}
dic["name"] = "李四" # 修改
dic["sex"] = "男" # 添加
print(dic)
删除元素:使用del语句进行删除,也可以使用pop(key)删除指定的键值对。popitem()随机删除一个键值对
dic = {"name":"张三", "age":18}
dic["name"] = "李四" # 修改
dic["sex"] = "男" # 添加
print(dic)
del dic["sex"] # 直接删除sex的键值对 没有任何返回的结果
print(dic)
value = dic.pop("name") # 删除name的键值对 返回name的值
print(value)
print(dic)
dic = {"name":"张三", "age":18, "sex":"男"}
# 随机删除一个键值对,返回值是一个元组,由于字典是无序的,所以删除可能是随机的
print(dic.popitem())
print(dic)
获取字典所有的键、值、键值对
# 键必须是唯一的 如果出现多个键 则以最后一个键的值为准
dic = {"name":"张三", "age":"张三", "sex":"张三", "sex":"女"}
# dict_keys(['name', 'age', 'sex'])
keys = set(dic.keys())
print(keys)
# dict_values(['张三', 18, '男'])
values = list(dic.values())
print(values)
items = list(dic.items())
print(items)
遍历字典的内容
dic = {"name":"张三", "age":"张三", "sex":"张三"}
for key in dic.keys():
print(key)
for value in dic.values():
print(value)
for key, value in dic.items():
print(key, value)
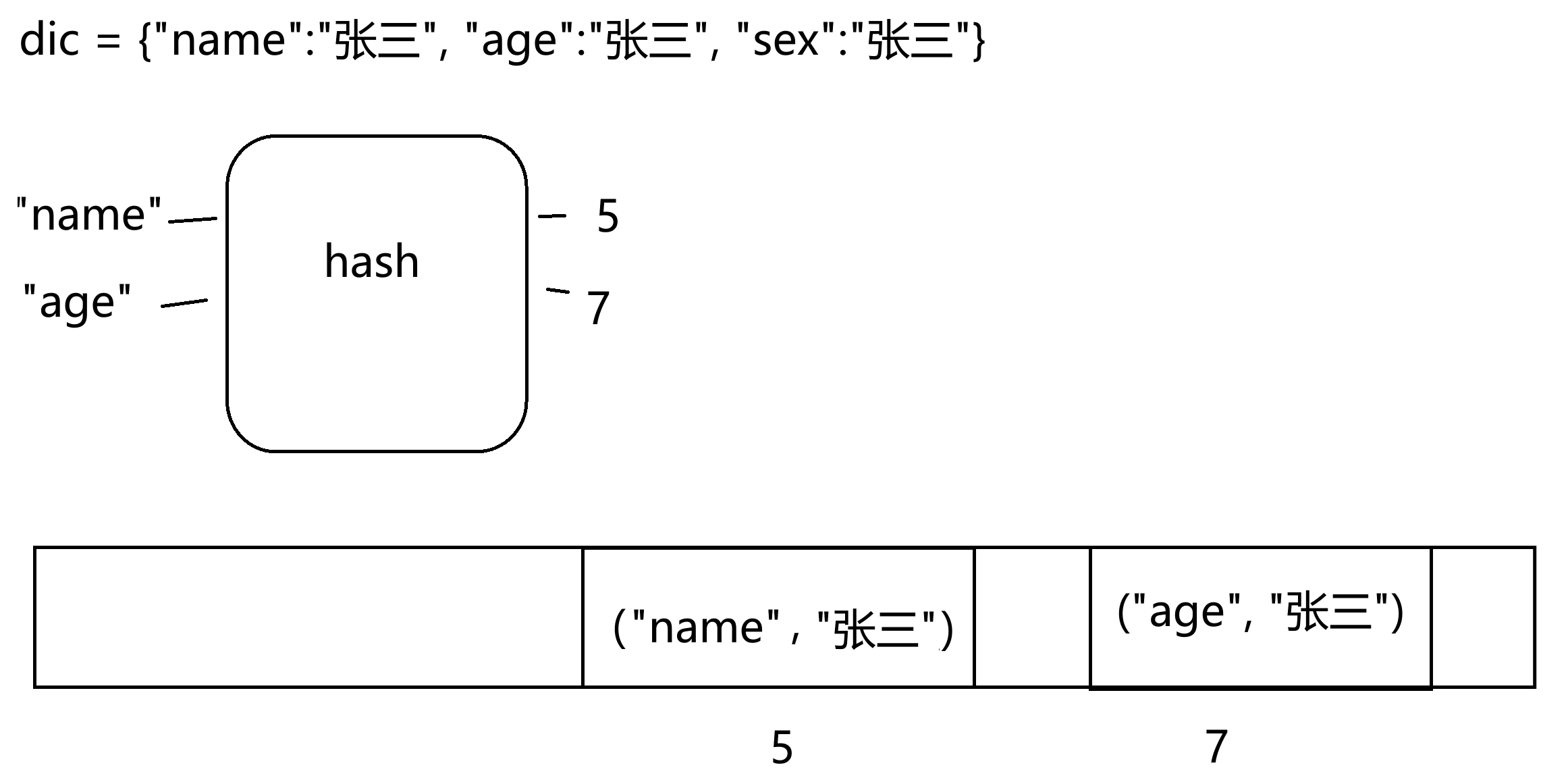
字典的键必须是可哈希的,即就是不可变数据类型(字符串、数字、元组)
字典的本质:底层是哈希表,以键进行哈希来计算存储位置,存储的是键值对的元组对象。
4 内置容器总结
列表
字符串
元组
集合
字典

















 2149
2149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









