






一、案例背景
精细化管理是一种以数据驱动、精准度量为基础的管理方式,它强调对组织内部各项工作的深入剖析、细化分解,以及对关键指标的持续跟踪与优化。在考勤管理领域,通过钉钉等数字化工具自动统计各月各部门各员工在不同时间段下班的人次,能够为实现精细化管理提供有力支持。以下是如何运用这一统计功能进行精细化管理的探讨:
1.数据精准度提升
钉钉考勤记录能够精确捕捉每位员工的打卡时间,自动统计各时段下班次数,消除了传统人工统计可能存在的误差和遗漏。这种精确度高的数据源有助于管理层获得真实、可靠的考勤信息,为决策提供坚实依据。
2.人力资源规划与成本控制
长期、系统的下班时间统计能够反映部门间或岗位间的劳动强度差异,为人力资源规划提供依据。例如,若某部门经常性晚下班,可能意味着人员配置不足或任务分配不均,需要考虑增员或调整工作分配。此外,对加班成本的精确核算也有助于企业控制人力成本,合理安排预算。
3.员工满意度与福利优化
通过对下班时间的统计分析,企业可以了解员工实际工作负担,评估其工作生活平衡情况。这有助于制定更为人性化的福利政策,如弹性工作制、合理调休安排等,提升员工满意度和忠诚度,降低人才流失率。
4.绩效评估与激励机制设计
下班时间数据可作为绩效考核的辅助指标之一,特别是在那些对工作时长有一定要求的岗位。合理的绩效评价体系应兼顾工作成果与工作投入,下班时间统计有助于更全面地衡量员工工作努力程度。此外,基于考勤数据的激励机制,如设置准时下班奖励或加班补偿机制,也能激发员工积极性,引导形成良好的工作习惯。
综上所述,通过钉钉考勤记录自动统计各月各部门各员工在不同时间段下班的次数,企业能够实现考勤管理的精细化,从而提升管理效能、优化人力资源配置、提升员工满意度,并为绩效管理和激励机制设计提供精准数据支持。这种精细化管理不仅有助于企业提升运营效率和降低成本,还有利于营造积极健康的工作氛围,促进员工与企业的共同发展。
以上分析来自通义千问AI大模型,在钉钉APP上搜索“通义千问”即可。
二、案例数据
特别声明,涉及数据均已脱敏处理,请勿对号入座。
1.原始表样
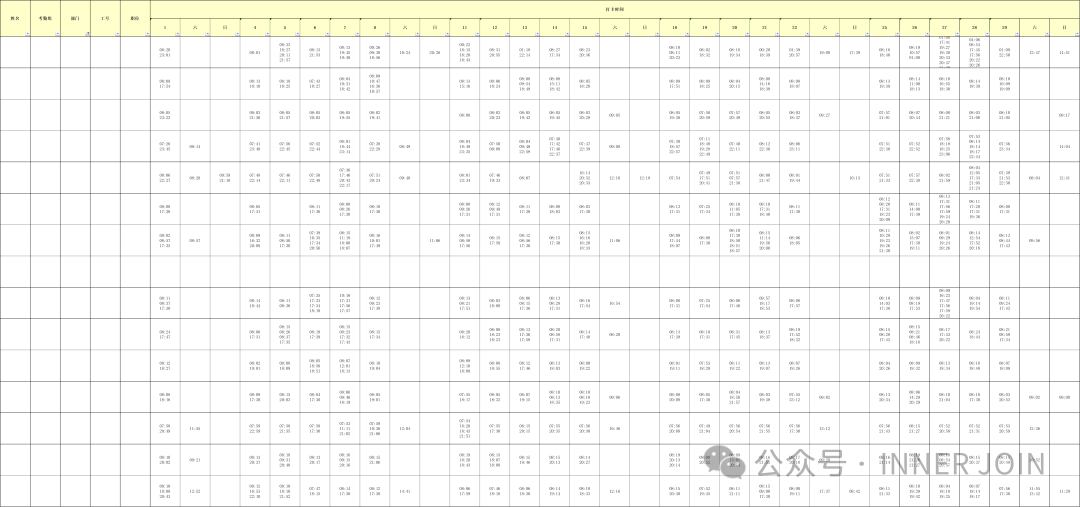
2.汇总结果

三、执行代码
1 读入第三方库
# 读写与处理数据
import pandas as pd
# 设置表格样式
from openpyxl import load_workbook
from openpyxl.styles import Font, Border, Side, Alignment
import xlwings as xw
# 判断是否工作日
from chinese_calendar import is_workday
# 生成标准日期
from datetime import date
# 文件夹管理
import os
# 忽略警告信息
import warnings
warnings.filterwarnings('ignore')
2 预定义函数库
2.1 表格样式设置
def formation(path,date_title):
# 读取工作簿
wb = load_workbook(path)
# 遍历工作表名
for sheet in wb.sheetnames:
# 获取工作表
ws = wb[sheet]
# 插入表格表头
ws.insert_rows(1,1)
ws['A1'] = f'{date_title[:4]}年{date_title[4:6]}月总行部室人员在不同时间段的下班人次统计表'
# 设置单元格的边框、对齐方式
for i in range(ws.max_column):
for j in range(1, ws.max_row+1):
row = ws[chr(ord('A')+i) + str(j)]
row.alignment = Alignment(horizontal='center', vertical='center')
row.border = Border(left=Side(border_style='thin'),
right=Side(border_style='thin'),
top=Side(border_style='thin'),
bottom=Side(border_style='thin'))
# 合并表头单元格
ws.merge_cells(f"A1:{chr(ord('A')+i)}1")
ws['A1'].font = Font(name='微软雅黑',size=20,bold=True)
# 另存为工作簿
wb.save(path)
2.2 调整行高列宽
def adjust(path):
# 读取工作簿
wb_ = app.books.open(path)
for sheet in wb_.sheet_names:
# 获取工作表
ws_ = wb_.sheets[sheet]
# 实现表格行高或列宽自动调整
ws_.autofit()
# 保存工作簿
wb_.save(path)
# 关闭工作簿
wb_.close()
2.3 计算下班时段
def TimePeriod(x):
# 通过空值返回缺卡类型1
if x == 'nan':
return '全天缺卡'
# 通过时间数据中":"的个数返回缺卡类型2
elif x.count(':') < 2:
return '下班缺卡'
# 其余均存在下班打卡记录,获取最迟的下班打卡记录
# 获取第二迟的下班打卡记录或上班打卡记录(如果只有1次下班打卡记录)
else:
y1 = int(x.replace(' ','').split('\n')[-1].replace(':',''))
y2 = int(x.replace(' ','').split('\n')[-2].replace(':',''))
# 返回下班时区1(暂时也将早退的纳入)
if (1730 <= y1 < 1800) or (815 <= y1 < 1730):
return '17:30-18:00'
# 返回下班时区4
elif y1 < 1730 and (y2 >= 1730 or y2 <= 815):
return '20:00-'
# 返回下班时区2
elif 1800 <= y1 < 1900:
return '18:00-19:00'
# 返回下班时区3
elif 1900 <= y1 < 2000:
return '19:00-20:00'
# 返回下班时区4
else:
return '20:00-'
3 时段人次统计
# 创建文件夹,存储统计报表
if not os.path.exists('C:/ZeroTrain/每月总行部室人员在不同时间段的下班人次统计表'):
os.makedirs('C:/ZeroTrain/每月总行部室人员在不同时间段的下班人次统计表')
# 启动Excel程序
app = xw.App(visible=False, add_book=False)
# 设定钉钉考勤数据的存储路径
cwd = 'C:/ZeroTrain/考勤报表202310-202403'
# 获取该路径下的全部文件名称
files = os.listdir(cwd)
# 遍历该路径下的全部文件名称
for file in files:
# 根据文件名称获取考勤数据的截止日期
date_point = file.split('.')[0].split('-')[-1]
# 读取某个月的考勤数据,注意【工作表名】、【工作表头】、【字段类型】的设定
df = pd.read_excel(f'{cwd}/{file}',sheet_name='打卡时间',header=3,dtype={'工号':'str'})
# 更新工作表的字段,特别将包含“周六”、“周日”的日期数据序列化
df.columns = ['姓名','考勤组','部门','工号','职位','UserId'] + list(range(1,len(df.columns[6:])+1))
# 字段【工号】存在缺失值,默认为浮点型,获取标准的工号
df['工号'] = df['工号'].fillna('工号缺失')
df['工号'] = df['工号'].apply(lambda x: str(x).split('.')[0])
# 筛选考核对象的记录明细
department = df[(df['考勤组'] == '总行人员考勤')&(df['部门'].str.contains('-'))&(df['部门'].str[-3:] != '驾驶班')].reset_index(drop=True)
# 提取考核对象的固定信息
user_info = department[['姓名','考勤组','部门','工号','职位','UserId']]
# 将字段【部门】标准展示
user_info['部门'] = user_info['部门'].apply(lambda x: x.split('-')[-1]).replace('党群工作部(党委办公室)','党群工作部')
# 提取考核对象的考勤信息
attendance_all = department.iloc[:,6:]
# 区分日期为工作日还是非工作日
non_workday = []
# 遍历列名,实际为日期的day属性
for i in attendance_all.columns:
# 根据截止日期拼接出当前日期
cur_date = date(int(date_point[:4]),int(date_point[4:6]),i)
# 判断并存储非工作日的day属性
if not is_workday(cur_date):
non_workday.append(i)
# 为了方便需求统计,在考勤信息中直接剔除非工作日打卡记录
attendance_workday = attendance_all.copy().drop(columns=non_workday)
# 遍历【工作日】表的索引
for i in attendance_workday.index:
# 遍历【工作日】表的列名
for j in attendance_workday.columns:
# 返回哪种类型的下班时区
attendance_workday.loc[i,j] = TimePeriod(str(attendance_workday.loc[i,j]))
# 新建空列表,用以存储处理结果
result = []
# 遍历【工作日】表的索引
for i in attendance_workday.index:
# 读取某一行的考勤数据记录
one_record = pd.DataFrame(attendance_workday.loc[i,:])
# 增加计数字段【count】,值为常量1
one_record['count'] = 1
# 以【下班时区】为行,字段【计数】为列,汇总方式为“求和”
# 重置索引并行列转置
pt = one_record.pivot_table(index=i,values='count',aggfunc='sum').reset_index().T
# 字段名称替换为【下班时区】
pt.columns = pt.loc[i,:]
# 在记录中删除【下班时区】
pt.drop(index=i,inplace=True)
# 将处理结果添加至列表中
result.append(pt)
# 将列表result纵向合并,并以零填充缺失值
user_stat = pd.concat(result,ignore_index=True).fillna(0)
# 新增字段【总计】,沿横轴方向求和,记为当月的工作日天数
user_stat['总计'] = user_stat.sum(axis=1)
# 将考核对象的固定/考勤信息按索引值横向拼接
user_res = pd.concat([user_info,user_stat],axis=1)
# 提取字段列表的部分索引来展示数据
user_res2 = user_res.iloc[:,[2,0,3,7,6,8,9,10,11,12]]
# 在第一个位置插入字段【数据日期】,即考勤数据的截止日期
user_res2.insert(0,'数据日期',date_point)
# 设定处理结果的存储路径
filepath = f'C:/ZeroTrain/每月总行部室人员在不同时间段的下班人次统计表/{date_point[:4]}年{date_point[4:6]}月总行部室人员在不同时间段的下班人次统计表.xlsx'
# 另存为excel文件
user_res2.to_excel(filepath,index=False)
# 调用预定义函数,设置表格样式
formation(filepath,date_point)
# 调用预定义函数,设置行高列宽
adjust(filepath)
# 退出Excel程序
app.quit()
四、难点解析
第一、由于仅考虑工作日的下班打卡情况,所以需要将考勤日期(包含周六、周日)转换为标准日期,同时再判断是否为工作日;
第二、由于存在全天缺卡、下班缺卡、误提前签退而未更新、多次下班打卡和跨夜签退等情形,Python代码需要囊括全部可能情形,并在测试中优化调整;
第三、由于原始数据呈宽表形态,在正确返回了下班时段后,如何快速分类统计,并将下班时段的类别设置为列名,需要进行数据透视以及二维表转置等操作;
第四、为了提高Pandas库的性能,将原始数据拆分为两个表格,分别是维度(员工的固定信息,包括部门、姓名和工号等)、度量(每月每日的考勤记录)。后续过程中只要对度量做数据处理即可,最终以共同的索引作横向拼接。
关于Python学习指南
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
👉Python所有方向的学习路线👈
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取)

👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python70个实战练手案例&源码👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉Python大厂面试资料👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉Python副业兼职路线&方法👈
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。

👉 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









