




这里写目录标题
什么是web?
Web(万维网)是一个建立在互联网之上的巨大信息空间,它的核心是通过“超链接”将全球各地的文档、图片、视频等资源相互连接起来。你可以使用浏览器访问这些资源,每个资源都有一个唯一的网址(URL)。简单来说,如果把互联网看作连接全球电脑的公路系统,那么Web就是运行在这些公路上、让你能轻松穿梭于不同站点(网站)之间的神奇世界。
什么是web网站?
Web网站是存放在网络服务器上、通过特定网址(域名)可以访问的网页集合,它像一个在互联网上的信息站点,用户通过浏览器即可浏览其中的文字、图片和视频等内容。
Web技术核心知识点详解

在此向大家推荐一个非常适合系统性学习计算机知识的网站——菜鸟教程。其内容全面、结构清晰,是入门和巩固基础的优秀资源。
链接: https://www.runoob.com/
0. 知道Web必备四大件以及其作用
这指的是一个动态网站能够运行起来所必需的四个基础组件,它们共同协作,处理用户请求并返回响应。
-
操作系统:如Linux或Windows Server。它是所有软件运行的基础平台,负责管理硬件资源、网络连接和文件系统。


-
Web服务器(有时候也叫中间件):如Nginx或Apache。它接收来自用户浏览器的HTTP请求,并根据请求的URL决定如何处理(Web服务器就像餐厅的服务员,负责接收你的点单(请求),然后自己上菜(静态文件)或交给后厨处理(动态请求),最后把成品端给你(网页))。

-
后端编程语言/框架:如PHP、Python(Django/Flask)、Java(Spring)、Node.js等。它负责处理核心业务逻辑,比如用户登录、数据查询、动态生成网页内容。(后端编程语言/框架就像是餐厅的后厨团队,他们接收服务员(Web服务器)送来的点单(用户请求),然后按照菜谱(业务逻辑)进行烹饪(处理数据),最终做出一道道菜肴(动态网页内容))
ps:这里我需要简单讲解一下我们日常口中的前后端的区别
前端 vs. 后端
| 特性维度 | 前端 | 后端 |
|---|---|---|
| 核心职责 | 呈现与交互:负责用户能看到、能交互的一切内容,追求美观、流畅的体验。 | 逻辑与数据:负责服务器端的业务处理、数据存储与安全,追求稳定、高效、安全。 |
| 工作地点 | 在用户的浏览器中运行。 | 在远程服务器上运行。 |
| 所用技术 | HTML(结构)、CSS(样式)、JavaScript(交互)。 | PHP, Python, Java, Go, Node.js 等语言及其框架。 |
| 关注点 | 用户体验:页面是否美观?加载是否快?交互是否流畅?是否兼容不同浏览器和设备? | 业务逻辑:功能如何实现?数据如何存储和读取?如何应对高并发?如何防止攻击? |
| 与用户的关系 | 直接相关:直接服务于用户,界面就是产品。 | 间接相关:通过API为前端提供数据和服务,用户感知不到它的存在。 |
“Web四大件”是支撑网站运行的服务器引擎和基础设施。而前端是这个基础设施加工制造出来的最终产品,它运行在客户端的浏览器里。 所以,在列举服务器层面的核心组件时,不会把前端算进去,但它们是一个完整Web应用不可分割的两大部分。

- 数据库:如MySQL、PostgreSQL、MongoDB等。简单的理解就是数据存储的仓库,它负责持久化地存储和管理网站的数据,如用户信息、文章内容、商品数据等。
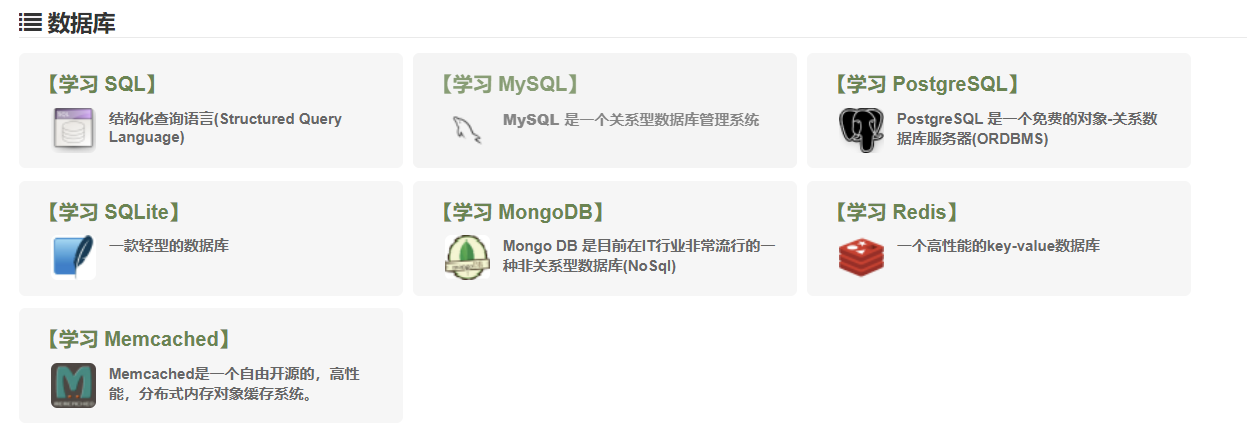
他们的关系:用户在浏览器输入网址 -> 操作系统上的Web服务器接收到请求 -> Web服务器将请求交给后端程序处理 -> 后端程序从数据库中查询或修改数据 -> 生成HTML页面 -> 经由Web服务器返回给用户的浏览器。
1. 知道网站有哪些形式展示
网站并非只有一种形态,理解其不同类型有助于选择正确的技术栈。
- 静态网站:由纯粹的HTML、CSS、JavaScript文件构成。内容固定,每个用户看到的都一样。适合展示型官网、博客(早期)。部署简单,性能高。
静态网站就像一张印好的纸质宣传单。上面的文字、图片、电话都是固定的,无法改变。发给100个人,100个人看到的内容都一模一样。
- 动态网站:内容可以根据用户请求、时间或数据库内容动态变化。绝大部分现代网站(如电商、社交平台)都是动态网站,需要上述“四大件”支持。
动态网站如 知乎、淘宝、微博。你登录后看到的是为你个性化定制的时间线、商品推荐和私信。
- 单页面应用:如使用React、Vue等框架开发的网站。只在用户首次访问时加载一个HTML页面,后续通过与后端API进行数据交互(通常是JSON格式)来动态地更新页面内容,用户体验更流畅,类似于桌面应用。
单页面应用如 Gmail、网易云音乐Web版。你在收件箱里点开一封邮件,只有邮件内容区域变化,侧边栏和顶栏都不动,体验非常流畅。
- 渐进式Web应用:可以看作是强化版的网站,具备类似原生应用的功能,比如可以离线工作、接收推送通知、被添加到手机桌面。
渐进式Web应用如Twitter、Telegram的网页版。即使网络信号不好,你依然能浏览之前加载过的内容。
2. 知道源码和URL访问对应关系
URL(统一资源定位符)是互联网上标准的内容地址协议,其核心作用是通过标准化语法为客户端提供资源的精确定位与访问方式。就是我们口中的网址/链接如
www.baidu.com,浏览器根据这个地址去互联网上找到对应的网站或资源。
第一步:理解基础——网站就是一个放在服务器上的文件夹

就像我们现在打开的一个我们电脑上的一个文件夹,本质上和下面访问这个网址下的一个目录是一样的

在互联网早期,URL和文件的对应关系非常简单直接:
想象一下,你电脑上有一个文件夹,名字叫 my_website,里面放着这些东西:
my_website/
│
├── index.html (网站首页)
├── about.html (关于我们页面)
├── style.css (样式文件)
├── logo.png (logo图片)
└── images/
└── photo.jpg (一张图片)
- 你访问
https://example.com/index.html-> 服务器就直接找到并返回my_website/index.html这个文件。 - 你访问
https://example.com/about.html-> 服务器就返回my_website/about.html。 - 你访问
https://example.com/images/photo.jpg-> 服务器就返回my_website/images/photo.jpg。
这种模式的特点是:URL的路径结构,完全反映了服务器上文件夹和文件的真实物理结构。 就像在Windows里打开一个又一个文件夹一样。
第二步:问题出现——动态网站和“不存在的”URL
但是,随着网站变得复杂(比如出现了电商、社交网络),我们遇到了问题。比如,有一个用户个人主页的功能,我们的用户量有100万人。
如果还用老办法,我们需要在服务器上预先创建100万个HTML文件:
/users/user1.html, /users/user2.html, … /users/user1000000.html
这显然是不可能的!
这时,我们需要的是动态生成页面。我们只需要一个“万能模板” user_profile.html,然后根据不同的用户ID,从数据库里取出对应的数据(名字、头像、简介),再把这个模板填充成不同的页面。
那么,新的问题来了:当用户访问 https://example.com/users/profile/123 时,服务器上根本不存在一个叫 123 的文件或文件夹。服务器该怎么办?
第三步:解决方案——“路由”机制(像公司的总机接线员)
为了解决这个问题,现代网站引入了一个叫做 “路由” 的聪明机制。它就像一个公司的总机接线员。
-
你的网站文件夹,现在变成了这样:
my_website/ │ ├── index.html ├── style.css └── **server.py** (这是后端程序,包含了“路由”规则) -
“路由”规则(接线员的工作手册):
这本手册上写着:- 如果访问的是
/images/...或/style.css,直接去文件夹里找对应的文件返回。(这是静态文件,按老办法处理) - 如果访问的URL是
/users/profile/用户ID-> 那么请把这条线路转接给server.py程序里的get_user_profile(用户ID)这个函数来处理。
- 如果访问的是
第四步:完整流程演示——访问 /users/profile/123
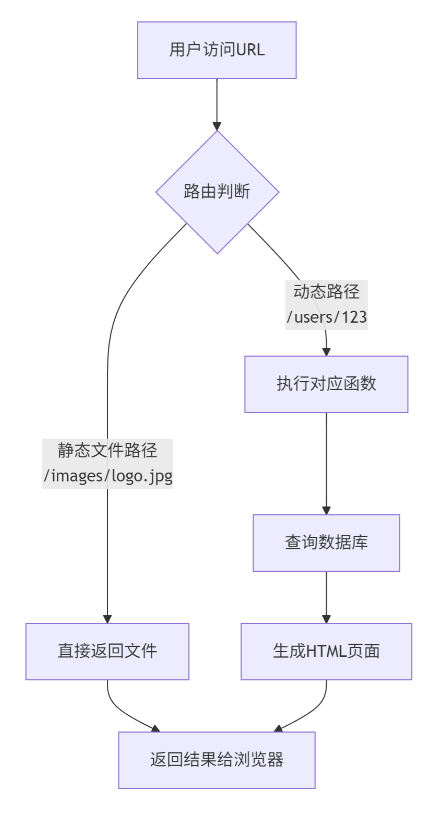
现在,我们再来看一次访问 https://example.com/users/profile/123 的完整过程:
- 请求到达:你的请求到达服务器。
- 接线员(路由系统)工作:服务器上的Web框架(如Django, Express等)的“路由”系统开始工作。它分析URL路径
/users/profile/123。 - 模式匹配:它发现这个路径符合手册里写的规则
/users/profile/用户ID,并提取出关键信息:用户ID = 123。 - 转接给处理函数:它不会去硬盘上找
/users/profile/123这个文件夹,而是调用预先写好的处理函数,比如get_user_profile(123),并把提取到的123作为参数传过去。 - 后端程序处理:
get_user_profile函数开始执行:- 它拿着用户ID
123去数据库里查询用户信息。 - 数据库返回ID为123的用户数据(比如:用户名“小明”,年龄25岁)。
- 函数把这些数据填充到一个用户主页的HTML模板里。
- 它拿着用户ID
- 生成并返回页面:一个完整的、为“小明”定制的HTML页面在内存中动态生成了。这个页面通过服务器返回给你的浏览器。
核心总结
| 对比项 | 传统方式(静态网站) | 现代方式(动态网站 + 路由) |
|---|---|---|
| 核心思想 | URL直接映射物理文件 | URL映射一段处理逻辑(函数) |
| 像什么 | 在文件管理器里找文件 | 给公司总机打电话,由接线员转接到具体部门 |
| 处理流程 | 访问 /page.html -> 返回 page.html 文件 | 访问 /path/abc -> 执行 handle_abc() 函数 -> 返回函数生成的结果 |
| 灵活性 | 低,内容固定 | 极高,可以实现无限复杂的动态功能 |
所以,“知道源码和URL访问对应关系”,本质就是理解:今天的URL不再是一个“文件地址”,而是一个“指令”或“命令”,它告诉服务器应该启动哪一段代码来为你服务。 这是理解现代Web开发至关重要的一步。、
3. 知道源码有加密开源闭源类型

源码的三种形态与审计策略
| 源码类型 | 核心特征 | 典型场景 | 审计/分析思路 |
|---|---|---|---|
| 开源 | 代码完全公开,可自由查看、修改、分发。 | GitHub等平台上的公共项目、Linux等开源软件。 | 白盒审计:可直接阅读源码,利用SAST工具进行静态分析,甚至融入CI/CD流程实现自动化安全扫描。 |
| 闭源 | 仅发布编译后的二进制文件(如.exe, .dll)。 | 多数商业软件、如Microsoft Office、Adobe Photoshop。 | 黑盒测试 & 逆向工程:只能通过分析其输入输出、网络行为、文件操作等来推断逻辑。需使用调试器、反汇编器等工具。 |
| 加密/混淆 | 代码虽可见,但被故意处理得难以理解。 | 前端JavaScript代码保护、商业算法的部分开源。 | 去混淆与逆向:需结合静态分析(识别混淆模式)和动态分析(跟踪运行时内存状态)来还原原始逻辑。 |
对小白来说,可以这样理解:
-
开源代码如同完全公开的菜谱,所有制作方法和步骤都清晰可见。任何人都能自由查看、学习甚至改进这份“菜谱”,比如Linux系统就是这样通过全球开发者共同协作不断完善,具有高度透明性和可学习性。
-
闭源代码好比餐厅的独家秘方,你只能品尝最终菜肴却无从知晓具体配方。商业软件如Windows或Photoshop只提供成品程序,其核心代码作为商业机密受到严格保护,用户无法直接查看或修改内部实现逻辑。
-
代码混淆则像把菜谱加密成天书,虽然内容可见但已被故意打乱。变量名被替换成无意义的字符,逻辑结构变得迂回曲折,这种保护方式常见于网页JavaScript代码,旨在增加他人理解和复现的难度。
不同源码类型的保护策略
了解如何分析,自然也需知道如何保护。这与源码类型紧密相关。
- 开源项目的保护核心是“流程与协作”:虽然代码公开,但保护靠的是严格的代码审查机制、依赖项漏洞管理(定期扫描和更新)以及完善的安全文档和响应流程,确保社区能共同维护安全。
- 闭源项目的保护核心是“防逆向与强加密”:主要手段包括代码混淆、强加密算法保护关键数据,以及引入反调试机制增加逆向难度。
- 加密/混淆的技术实现:这是保护闭源和敏感代码最常用的技术组合,具体手段丰富:
- 代码混淆:通过变量/函数名混淆(如将
calculateSalary改为a1b2)、控制流扁平化(打乱正常执行流程)等手段,大幅降低代码可读性。 - 源码加密:例如使用AES等加密算法对源码加密,运行时再解密;或将代码编译为字节码/中间语言,如Java的.class文件。
- 高级工具:可借助专业工具,如Virbox Protector提供的加密外壳、碎片代码执行等高级功能,能有效对抗逆向分析。
- 代码混淆:通过变量/函数名混淆(如将

















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









