






冒泡排序是一种简单的排序算法,它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
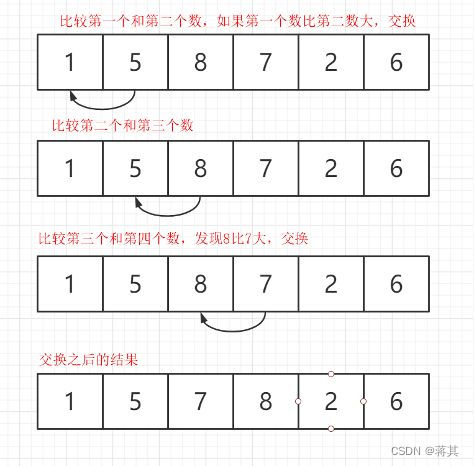
下面是一个简单的冒泡排序的步骤,我会用代码来配合解释:
1.比较相邻的元素。如果第一个比第二个大,就交换它们两个;
1.对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数;
1.针对所有的元素重复以上的步骤,除了最后一个;
1.持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
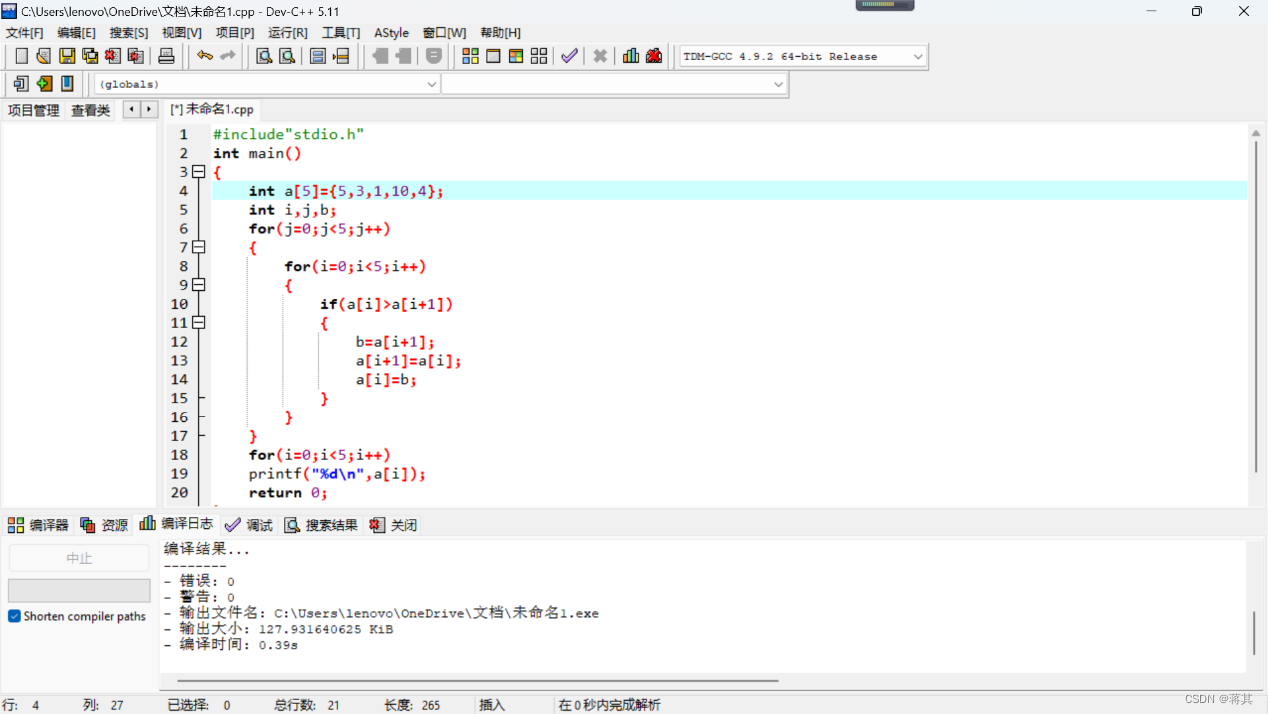
现在我将用C语言来实现这个算法,并提供相应的示例代码:
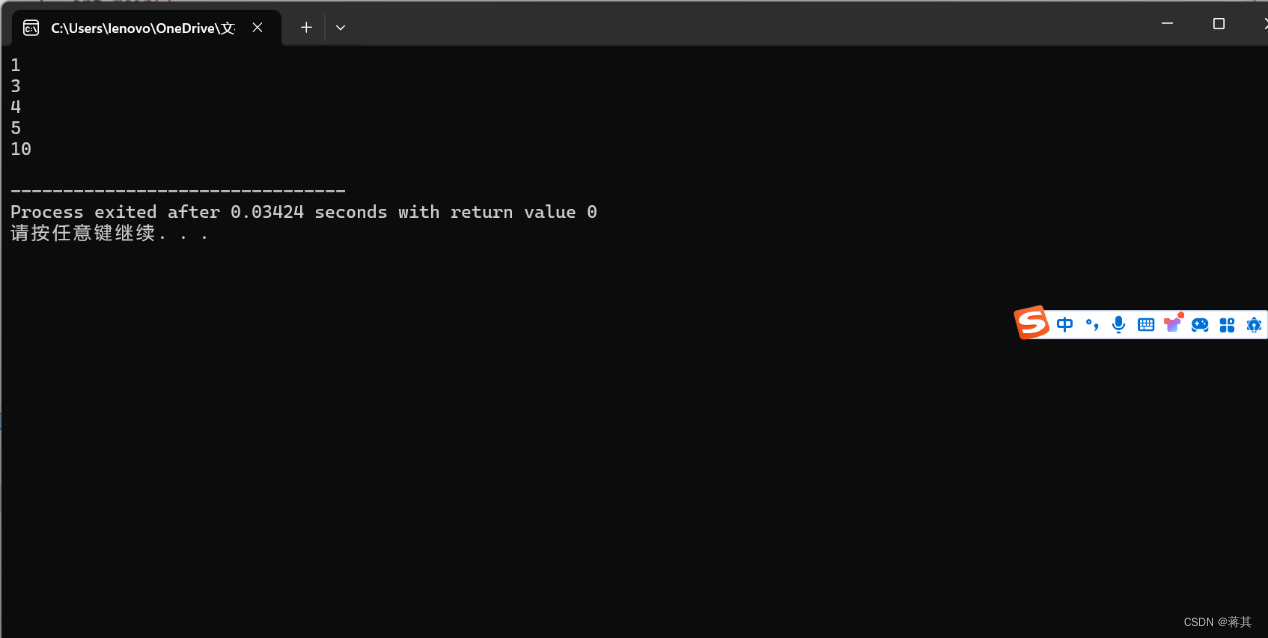
运行结果如下:
排序过程可以用一个例子来说明,比如我们有数组 [64, 34, 25, 12, 22, 11, 90],下面是每次遍历后的结果:
1.第一轮遍历结束后,最大数 90 "冒泡" 到了正确的位置,数组变为 [34, 25, 12, 22, 64, 11, 90];
1.第二轮遍历结束后,次大的数 64 被放到其正确的位置,数组变为 [25, 12, 22, 34, 64, 11, 90];
1.第三轮遍历结束后,第三大的数 34 被放到其正确的位置,数组变为 [12, 22, 25, 34, 64, 11, 90];
1.第四轮遍历结束后,第四大的数 25 被放到其正确的位置,数组变为 [12, 22, 25, 34, 11, 64, 90];
1.最后一轮遍历结束后,最小的数 11 被放到其正确的位置,数组变为 [11, 12, 22, 25, 34, 64, 90]。
这样,我们就通过冒泡排序算法得到了一个有序的数组。冒泡排序的时间复杂度是 O(n^2),所以在处理大数据集时可能不是最有效的排序方法,但对于小规模的数据集是一个很好的选择。
希望这个解释对你有所帮助!
下一次,交换排序算法分享。















 43万+
43万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









