






有一类特殊字符以及文本字符所编写的一个模式,模式用来匹配文件当中的内容(字符)
作用:校验我们输入的内容是否满足规定,格式,长度等等要求。
主要用来匹配文本内容以及命令的结果。
通配符:只能用于匹配文件名和目录名。不能匹配文件名的内容和命令的结果。
正则表示有两种:
基本正则表达式
元字符(字符匹配)
. 任意单个字符,也可以是一个汉字

\ 转义符 恢复其本义
[] 匹配指定范围内的任意单个字符或者数字。


[^] 取反 ^不加[] 匹配开头的的字符
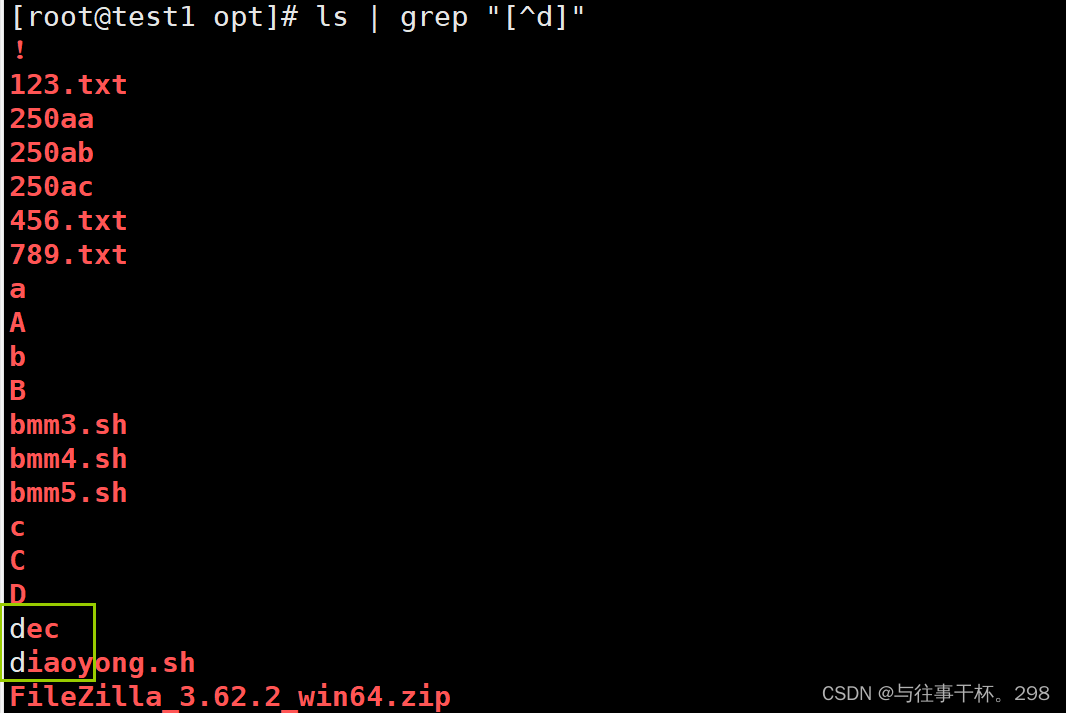 除了d以外显示所有的内容。
除了d以外显示所有的内容。
匹配字符出现的次数:
”*“ 匹配前面的字符任意次,0次也可以。贪婪模式,尽可能的匹配。

”.*“ 匹配前面的任意字符,至少要有一次,匹配所有。
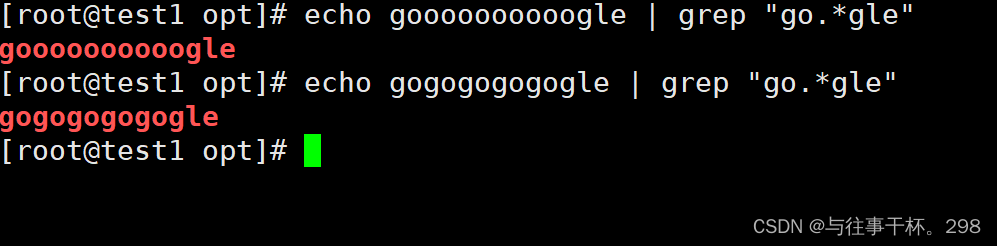
\?匹配前面的字符0次或者一次,可有可无。

”\ + “ 匹配前面的字符,至少要有一次。

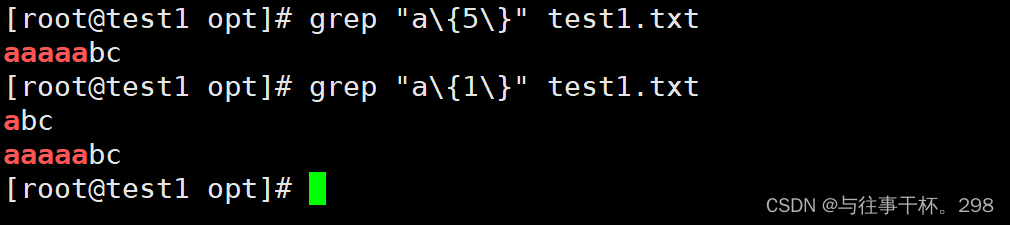
\ {n \ } 匹配前面的字符等于n次,可以小于n,但是不能大于n,而且前面的字符必要连续出现。
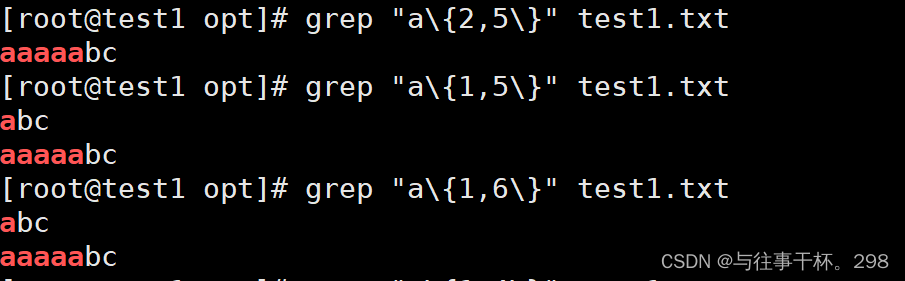
\ {m,n \ } 匹配前面的字符至少m次,最多n次。必须是连续出现,超出不在匹配范围。
位置锚定:
^ :以什么为开头 行首锚定


$: 以什么为结尾 行尾锚定

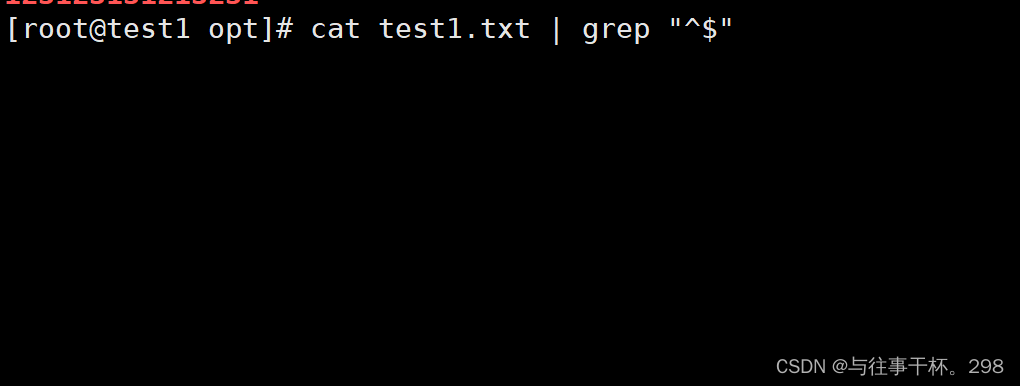
^$ : 空行
\ <或者\b 词首锚定,匹配单词的左侧(连续的数字,字母,下划线都算单词内部)

\ >或者\b 词尾锚定,匹配单词的右侧(连续的数字,字母,下划线都算单词内部)

区别
\broot\b : 匹配整个单词,空格隔开的也算整个单词

^root$ : 整个一行只有这个单词

分组和逻辑关系
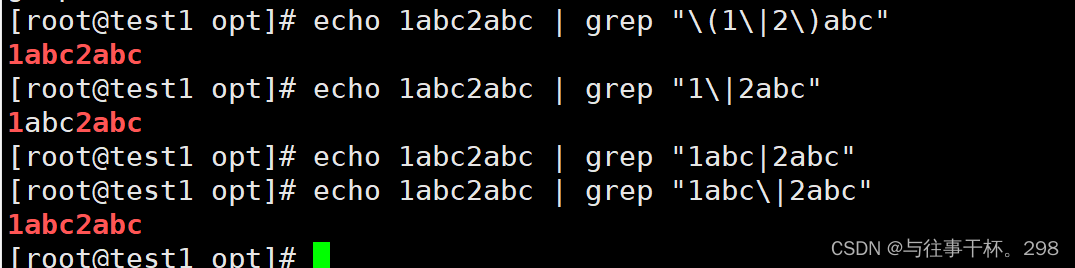
分组:()

或者: \ |
扩展正则表达式
把基本正则表达式前面的\删除就是扩展正则表达式
”*“ 匹配前面的字符任意次,0次也可以。贪婪模式,尽可能的匹配。
”.*“ 匹配前面的任意字符,至少要有一次,匹配所有。
?匹配前面的字符0次或者一次,可有可无。
”+ “ 匹配前面的字符,至少要有一次,
{n } 匹配前面的字符等于n次,可以小于n,但是不能大于n,而且前面的字符必要连续出现。
{m,n } 匹配前面的字符至少m次,最多n次。必须是连续出现,超出不在匹配范围。
{,n } 配前面的字符最多n次
{n,} 匹配前面的字符最少n次
位置锚定:
^ :以什么为开头 行首锚定
$: 以什么为结尾 行尾锚定
^$ : 空行
【\ <或者\b 词首锚定,匹配单词的左侧(连续的数字,字母,下划线都算单词内部)】
【\ >或者\b 词尾锚定,匹配单词的右侧(连续的数字,字母,下划线都算单词内部)】
唯一的区别就是词首词尾锚定\b要加\
扩展正则表达式命令行:grep -E或者egrep 都可以















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









