






#include "studio.h"是预处理指令,用于包含标准输入输出库头文件,这个头文件包含了标准输入输出函数的声明,如printf(),scanf()
int main() 函数是所有程序的入口点,它标志着程序执行的开始。
printf 函数用于向用户显示一条消息,scanf 函数则用于从标准输入(键盘)读取整数类型的输入,并将其存储到变量 中。%d 是格式说明符,表示要读取的是一个十进制整数。& 是地址运算符,获得变量的内存地址。
printf("<格式化字符串>", <参量表>);
scanf()是C语言中的一个输入函数,按用户指定的格式从键盘上把数据输入到指定的变量之中。
如果使用 , 来分隔输入的 %d, 相应的输入时也需要添加 ,
#include <stdio.h> // 引入 printf 和 scanf 的头文件
#include "studio.h"会先在用户自己编写的文件里找,找不到会去库文件里找
#include <studio.h>会直接去库文件里找
给代码加上的一些解释部分,不会被编译器识别,不会进入到编译过程中去。
单行注释使用 //(文字)
多行注释使用 /* (文字)*/
iostream
用于存储iostream类库的源文件,在这个程序中用于提供输出这项功能。
C标准中定义了C库,标准I/O就是C库中用来输入和输出的函数。include output
缓冲区(Buffer)就是在内存中预留指定大小的存储空间用来对输入/输出(I/O)的数据作临时存储,这部分预留的内存空间就叫做缓冲区
stdio.h属于C语言的标准I/O库,是以函数的方式向buffer写入或读取字符。
其输入表达为:scanf(…) , 输出为:printf(…)
iostream.h和iostream是C++的I/O库,引入了输入/输出流的概念,是一个类库,是以类方法从streambuf中读取或写入字符。
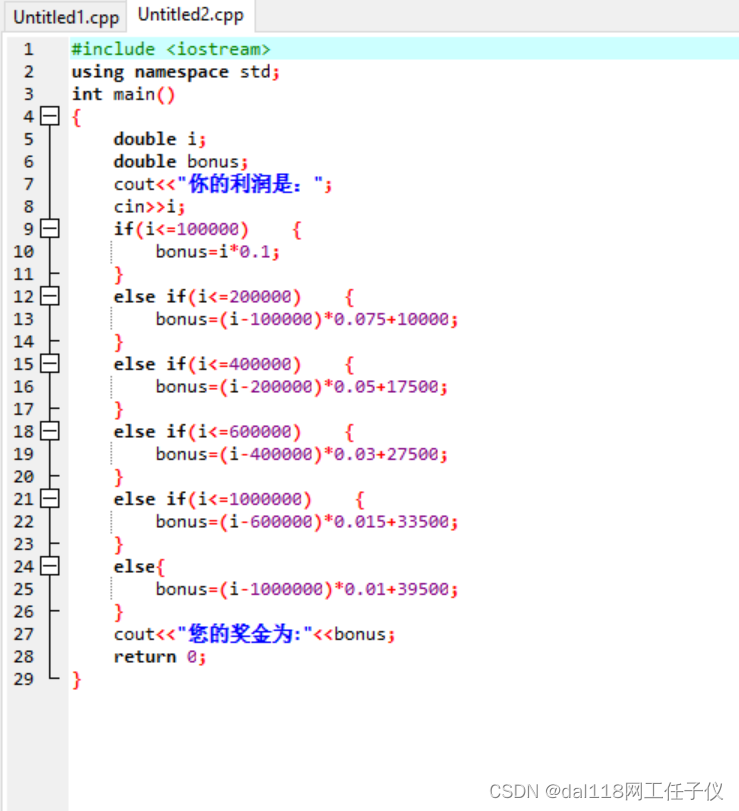
其输入表达为:cin>>… , 输出为:cout<<…
有“.h”的就是非标准的,C的标准库函数,无“.h”的,就要用到命令空间,是C++的。
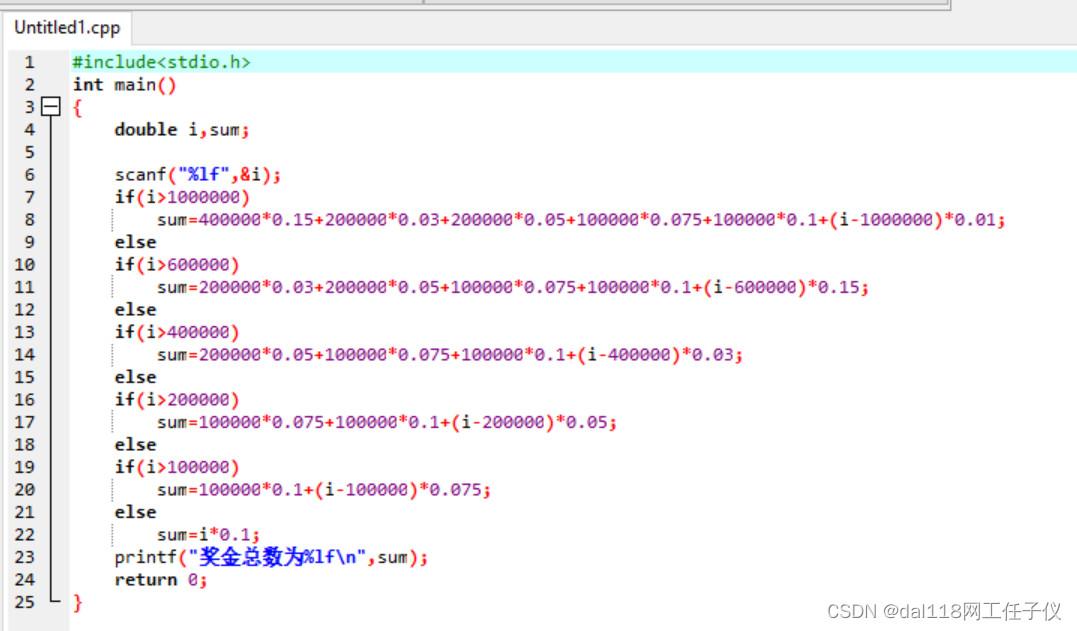
C语言中采用float和double关键字来定义小数,float称为单精度浮点型,double称为双精度浮点型,long double更长的双精度浮点型。例如:scanf("%lf",&i)的意思是使用scanf函数从标准输入设备读取一个double类型的值,并将其存储在变量i中。
格式说明由“%”和格式字符组成,作用是将输出的数据转换为指定的格式输出
%f 对应的是float %lf 对应的是double %2lf同上,不过限制了输出的值只保留2位小数 %d 表示有符号十进制整数。
C中一般设置一个变量flag,是一个来表示判断的变量,当做标志。比如当一种情况的时候,置flag为1,当另外一种情况时,置flag为2。 变量名为flag,只是习惯问题,也可以取别的名字。
所谓namespace,是指标识符的各种可见范围。C++标准程序库中的所有标识符都被定义于一个名为std的namespace中。
当使用<iostream>的时候,该头文件没有定义全局命名空间,必须使用namespacestd;这样才能正确使用cout。
switch 语句会对表达式进行求值,并将表达式的值与一系列 case 子句进行匹配,一旦遇到与表达式值相匹配的第一个 case 子句后,将执行该子句后面的语句,直到遇到 break 语句为止。若没有 case 子句与表达式的值匹配,则会跳转至 switch 语句的 default 子句执行。switch case 语句判断一个变量与一系列值中某个值是否相等,每个值称为一个分支。switch 语句可以拥有多个 case 语句。每个 case 后面跟一个要比较的值和冒号。case 语句中的值的数据类型必须与变量的数据类型相同,而且只能是常量或者字面常量。当遇到 break 语句时,switch 语句终止。switch 语句可以包含一个 default 分支,该分支一般是 switch 语句的最后一个分支(可以在任何位置,但建议在最后一个)。default 在没有 case 语句的值和变量值相等的时候执行。default 分支不需要 break 语句。default是一个常见的关键字,主要用于两个方面:在switch语句中提供备选选项以及在接口的默认方法中提供默认实现,当没有任何case匹配时会执行该语句块。
利润在 0 - 100000 区间,奖金为利润的 10%。利润在 100001 - 200000 区间,100000 以内的部分按 10%计算,超过 100000 的部分按 7.5%计算。利润在 200001 - 400000 区间,200000 以内的部分按前两个区间计算,超过 200000 的部分按 5%计算。利润在 400001 - 600000 区间,400000 以内的部分按前三个区间计算,超过 400000 的部分按 3%计算。利润在 600000- 1000000 区间,600000 以内的部分按前四个区间计算,超过 600000 的部分按 1.5%计算。利润超过 1000000 的部分,1000000 以内的部分按前五个区间计算,超过 1000000 的部分按 1%计算。
1. main 函数部分:
变量 profit 用于接收用户输入的利润值。通过 printf 和 scanf 提示用户输入利润值并存储到 profit 变量中。调用 CountBonus 函数计算奖金,并将结果存储在 bonus 变量中。最后输出利润值和对应的奖金。
2. CountBonus 函数部分:
flag 用于判断利润区间, bonus 用于存储最终奖金,以及 bonus0 到 bonus10 等中间变量。通过计算 profit/100000 的值得到 flag ,用于确定利润所在的区间。根据不同的区间计算奖金,使用了一系列中间变量来逐步累加奖金。最后通过 switch 语句根据 flag 的值确定不同区间的奖金计算方式,并返回最终的奖金值。















 2765
2765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









