






题目链接:https://leetcode.cn/problems/remove-linked-list-elements/description/

typedef struct ListNode ListNode;
struct ListNode* removeElements(struct ListNode* head, int val)
{
ListNode* pcur = head;//遍历原链表
ListNode *newtail = NULL;//创建新链表
ListNode*newhead = NULL;
while (pcur)
{
if (pcur->val != val)//找值不为val的值,往新链表进行尾插
{
if (newhead == NULL)//链表为空
{
newhead = newtail = pcur;
}
else//链表不为空
{
newtail->next = pcur;
newtail = newtail->next;
}
}
pcur = pcur->next;
}
if(newtail)
newtail->next=NULL;
return newhead;
}
详细讲解:
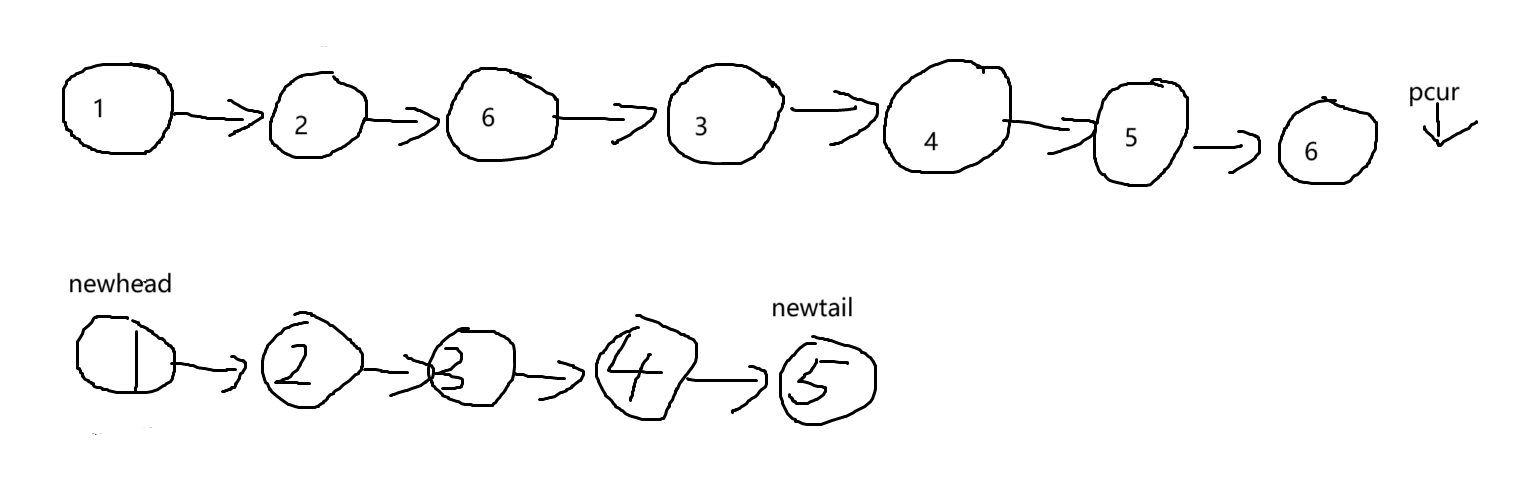
1. 首先我们创建一个新链表,然后定义两个指针,一个用来指向新链表的第一个节点(newhead),一个用来遍历新链表(newtail),继续向后尾插数据,如果用newhead遍历链表的话会找不到链表的第一个节点,无法返回,所以我们创建(newtail)这个新指针,让它遍历新链表。
2. 遍历原链表找到值不为val的节点尾插到我们的新链表,,因为新链表我们起始设为了空,所以把pcur(原链表中第一个值不为val的节点)赋值给(newtail和newhead),因为此时新链表就一个节点。newtail和newhead都指向第一个节点。
之后继续遍历原链表找到值不为val的节点尾插到我们的新链表,但此时新链表不为空,我们需让newtail->next=pcur(尾插节点),之后newtail = newtail->next(让newtail走到新链表新尾插的节点处),循环此过程尾插完成。
3. 尾插结束后我们的newtail已经走到了新链表的最后一个位置,我们把newtail的next指针置为空就好( newtail->next=NULL)。那为什么要判断newtail是否为空呢,因为原链表结点的值可能全是val,此时原链表中的节点一次也不尾插到新链表中,所以newtail为空,如果不判断newtail是否为空,直接执行newtail->next=NULL的话
此时相当于对空指针解引用,程序会报错,所以我们需判断newtail是否为空。
最后我们返回新链表的第一个节点,也就是题目说的新的头节点(newhead)就OK了,我们画图理解一下。
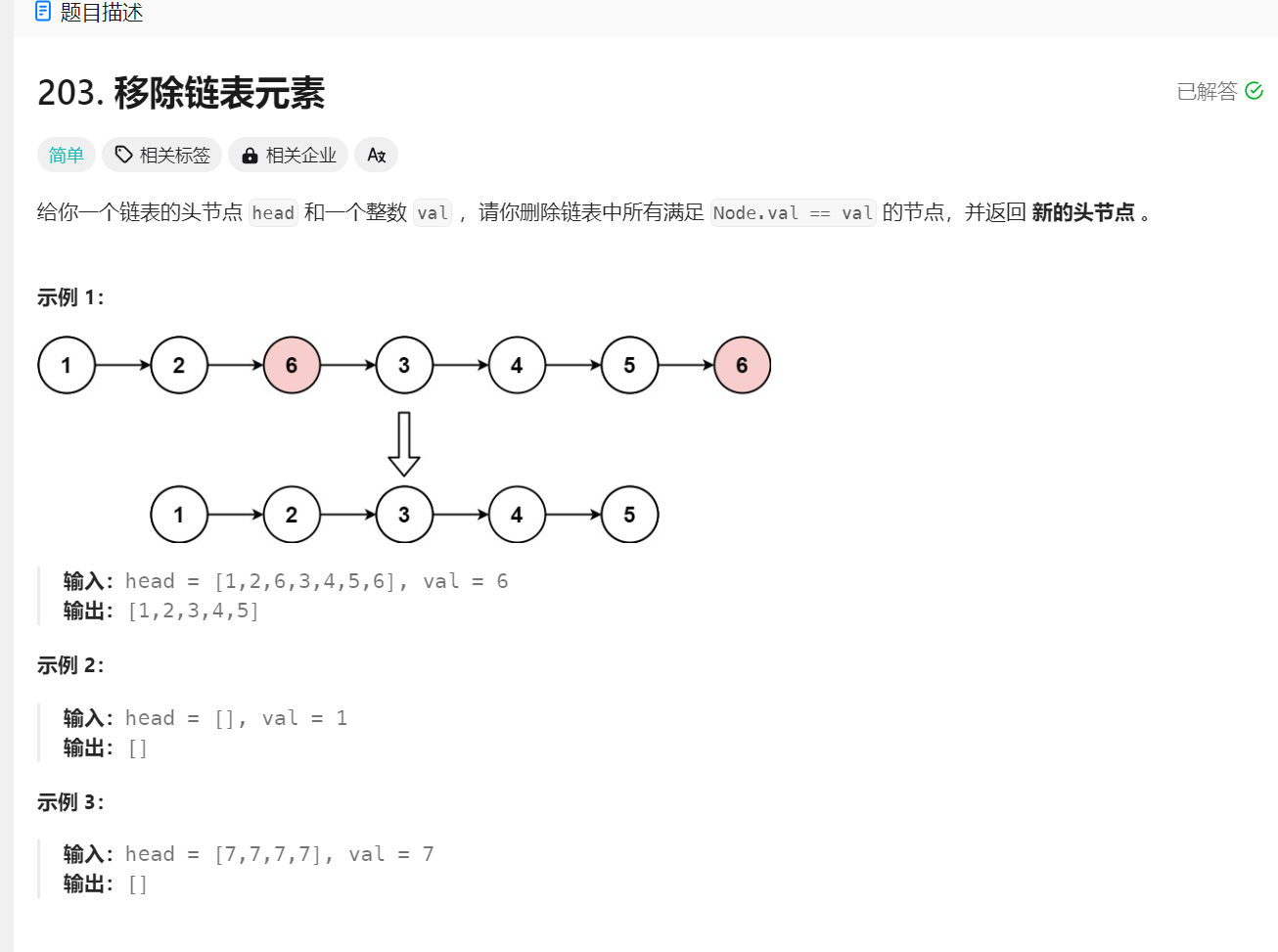
以示例一为例:
这是跳出循环的情况,此时像上述所述把newtail->next=NULL,然后返回newhead,就OK了。本题结束。
题目链接:https://leetcode.cn/problems/reverse-linked-list/description/
typedef struct ListNode ListNode;
struct ListNode* reverseList(struct ListNode* head)
{
if(head==NULL)
return NULL;
ListNode*n1=NULL;
ListNode*n2=head;
ListNode*n3=head->next;
while(n2)
{
n2->next=n1;
n1=n2;
n2=n3;
if(n3)
n3=n3->next;
}
return n1;
}
详细讲解:
1.首先我们定义三个指针(n1,n2,n3),n1指向空,n2指向原链表的第一个节点,n3指向原链表的第一个节点的下一个节点(原链表第二个节点),然后先让n2的下一个节点指向n1,然后n1走到n2的位置,n2走到n3的位置,以n2不为空为循环终止条件,最后返回n1,此时n1正好是反转完链表之后的新的第一个节点。
2.那为什么n3要判空呢,因为循环条件是n2是否为空,但n3会先比n2先跳出循环,所以n3会先为空,防止对空指针解引用,所以我们需判断一下n3是否为空,不为空才能继续向后遍历。
3.需要注意的是我们也需判断一下我们要反转的链表是否为空,如果为空我们直接返回NULL,因为此时我们反转不了空链表,不为空才能执行上述过程。此时我们就完成了反转链表,这个方法很妙,并且代码也很简单,现在我们画图理解一下。
以示例1为例:
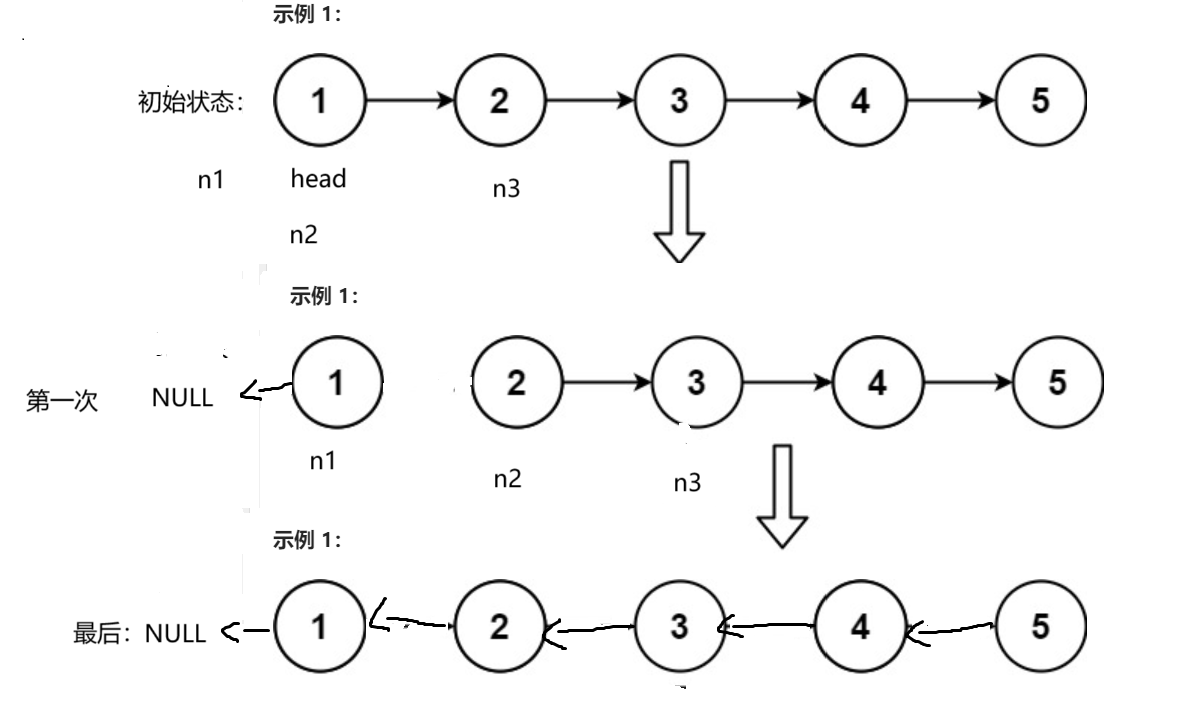
大家可以依照我这样画图理解,把第二次,第三次以及后续的情况画出来,这样更好理解,本题结束。
题目链接:
https://leetcode.cn/problems/middle-of-the-linked-list/description/
typedef struct ListNode ListNode;
struct ListNode* middleNode(struct ListNode* head)
{
ListNode*slow=head;
ListNode*fast=head;
while(fast&&fast->next)
{
fast=fast->next->next;
slow=slow->next;
}
return slow;
}
详细讲解:
1.首先这道题我们用了非常常见,且常用的方法快慢指针这个方法后续会经常用到,他就是用来找链表的中间节点的,注意如果节点个数是偶数时此时slow指向的中间节点是以示例2为例的值为4的节点。

2.显而易见我们直接定义两个指针,一个快指针,一个慢指针,快指针每次走两步,慢指针每次走一步,循环结束时,此时slow指向的就是链表的中间节点,我们直接返回就可以,那循环条件为什么这么写?
(1) 首先我们循环条件不需要判断slow是否为空,因为fast肯定比slow走得快,所以我们只需判断fast是否为空就好了。
(2) 因为fast每次走两步,所以(fast->next) 也需判断是否为空,因为可能 fast 此时不为空,但是它连续走了两步,可能fast走完一步之后(fast->next)变成了空,空指针不能继续解引用(fast->next->next),此时这个操作就是非法操作,这么写的话程序就会报错。
(3) 那么大家再思考一个问题,循环条件可不可以交换?
答案是:不可以。为什么呢?我们画图理解一下。
分为两种情况:
1. 结点个数是奇数个:不影响。
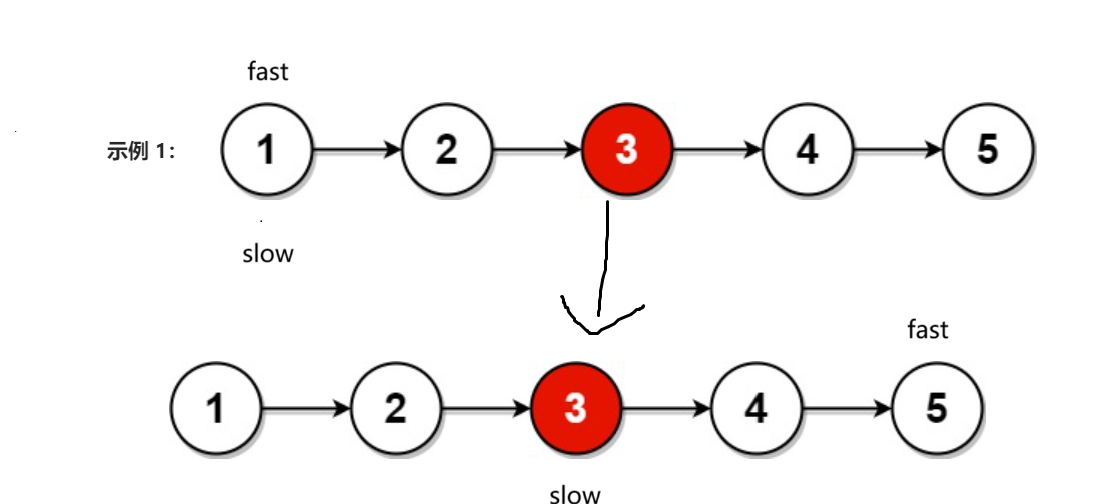
此时循环条件换不换都不会影响我们slow指向中间节点,大家可以验证一下很简单。
2. 结点个数为偶数个:会
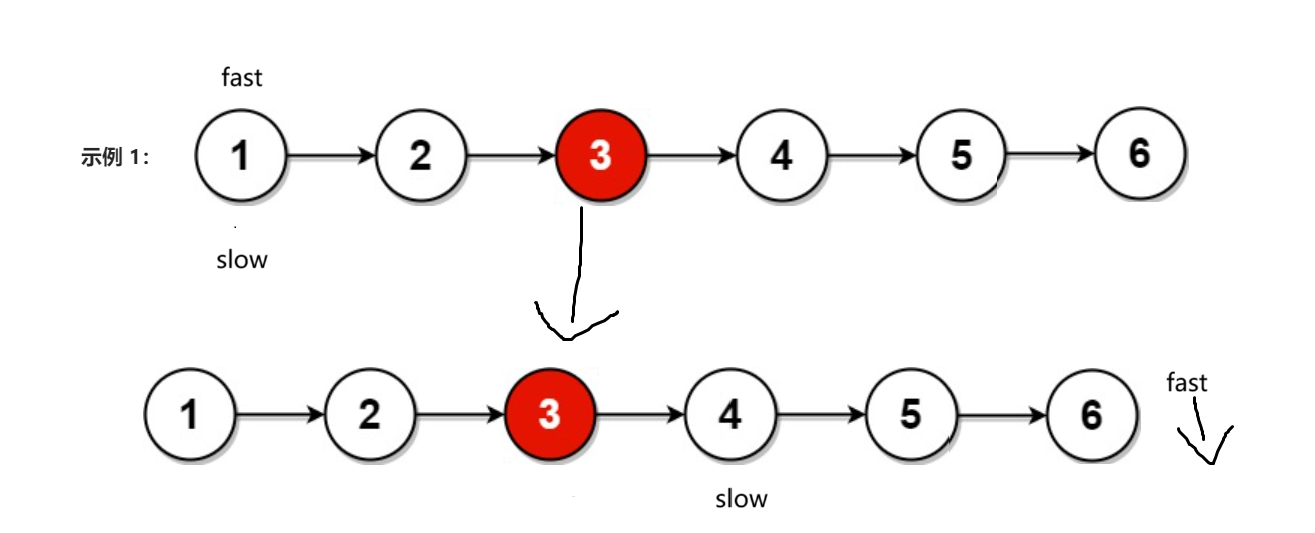
此时我们fast为NULL,按原来的循环条件(fast&&fast->next)直接跳出循环,因为此时fast直接为空,条件为假fast->next直接短路并且不会执行,但如果我们把循环条件换了一下(fast->next&&fast)此时fast为空,但却进行了解引用操作,此时相当于对空指针进行了解引用,程序报错。本题结束。
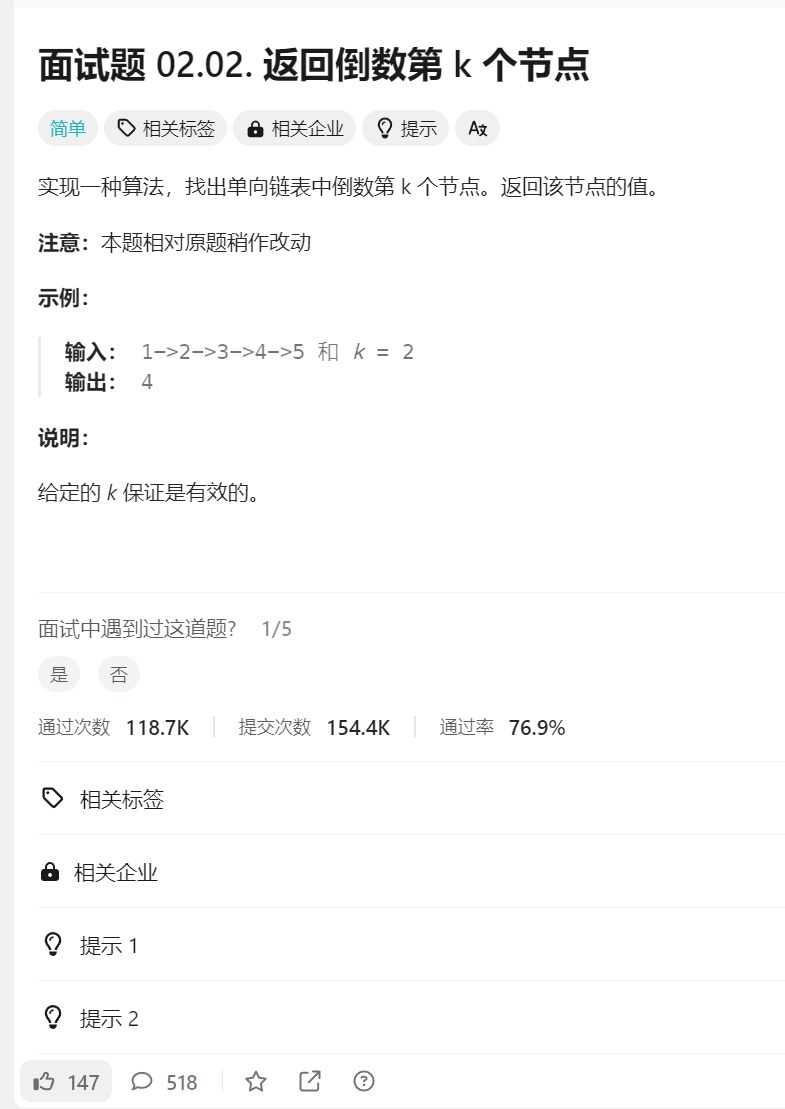
4.题目链接:
https://leetcode.cn/problems/merge-two-sorted-lists/description/
typedef struct ListNode ListNode;
int kthToLast(struct ListNode* head, int k)
{
ListNode* n1 = NULL;
ListNode* n2 = head;
ListNode* n3 = n2->next;
while (n2)
{
n2->next = n1;
n1 = n2;
n2 = n3;
if (n3)
n3 = n3->next;
}
ListNode* pcur = n1;
while (--k)
{
pcur = pcur->next;
}
return pcur->val;
}
详细讲解:这道算法题,力扣说是面试题,这道题正好可以用我们反转链表时用的代码。
1. 题目说找出单向链表中倒数第 k 个节点。返回该结点的值,这时我们很难找到,因为它是倒数第K个结点,那我们可不可以逆向思维,先把链表反转,之后再正数找结点呢?
2. 像上述代码一样我们先用之前的反转链表方法将链表反转,之后用程序给的K值,循环找要找的结点,但我们要先- -k再判断是否能进入循环,因为起始状态(k=0)时pcur就指向反转完链表后的第一个节点,但题目中(k=1)pcur才指向反转完链表后的第一个节点,所以我们先- -k,再进入循环,让pcur循环遍历直到找到目标节点,而题目中返回类型是int,所以我们要返回该结点的数据域,也就是pcur->val。返回之后,本题结束。
注:这里的绿字是题目已经定义好的,我们直接用就可以。
4.题目链接:
https://www.nowcoder.com/practice/0e27e0b064de4eacac178676ef9c9d70
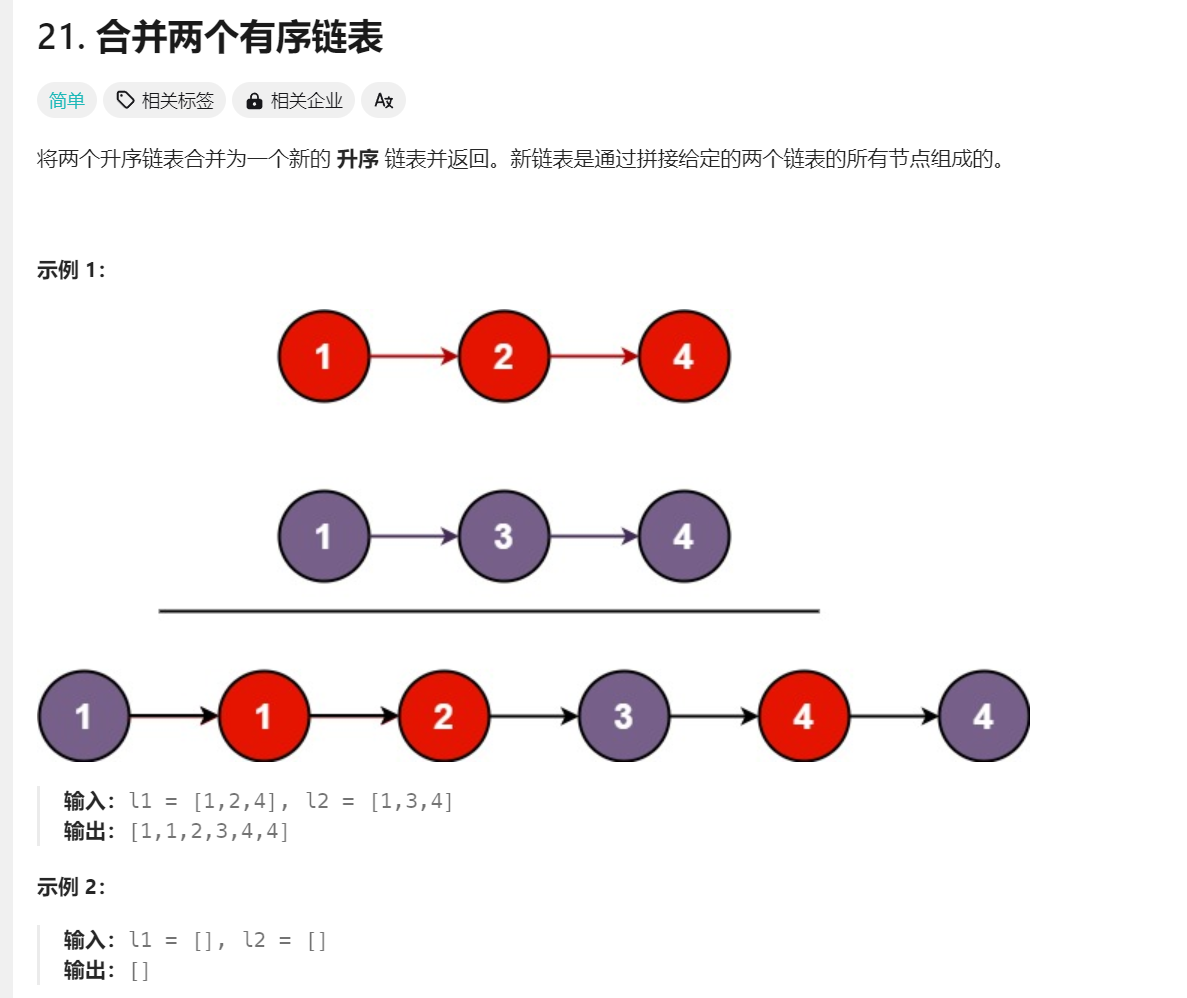
详细讲解: 之前我们写过合并两个有序数组,现在我们来看下合并两个有序链表。

1. 首先可能一开始两个原链表都为空,为空根据题目要求直接返回NULL,然后创建新链表用来存放原来两个原链表的节点,创建两个指针遍历原来的两个链表,比较谁的val值小谁尾插到新链表中,但是我们需要判断新链表是否为空,为空和不为空的尾插情况不一样,所以不管L1或L2尾插到新链表都需判断新链表是否为空,这就导致代码非常冗余,很不好,所以我们直接看下一个方法。
typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* s1, struct ListNode* s2)
{
if (s1 == NULL)
return s2;
if (s2 == NULL)
return s1;
ListNode* newphead = (ListNode*)malloc(sizeof(ListNode));
ListNode* newtail = newphead;
while (s1 && s2)
{
if (s1->val < s2->val)
{
newtail->next = s1;
newtail = newtail->next;
s1 = s1->next;
}
else
{
newtail->next = s2;
newtail = newtail->next;
s2 = s2->next;
}
}
if (s1)
{
newtail->next = s1;
}
if (s2)
{
newtail->next = s2;
}
ListNode* ret = newphead->next;
free(newphead);
newphead = NULL;
return ret;
}
这个方法很完美的解决了这个问题,现在我们来详细讲解一下。
1. 首先可能一开始两个原链表都为空,为空根据题目要求直接返回NULL,这步是不变的,然后我们申请一个新节点,注意这个新申请的节点只是用来占位置的,并不存放有效数据,然后创建newtail指针用来遍历新链表,方便进行尾插数据。
2. 循环条件为s1 && s2,他们进行比较然后尾插到新链表肯定会有一个先走到空,只要有一个先为空就终止循环,这里的s1和s2分别指向题目给的两个链表的第一个节点的指针,但我们后续用不到原链表的第一个节点了,所以我就不创建新指针遍历原来的链表了,但大家也可以保持良好习惯创建两个新指针遍历也是可以的。
3. 最后循环比较谁的val值小谁尾插到新链表中,然后让原链表和新链表的指针全部向后走一步,出了循环之后谁不为空谁就把原链表后续的数据全部尾插到新链表中,此时newphead并不是我们新链表中的第一个节点,而是我们申请的占位置的无用节点,所以我们创建个ret指针保存newphead的下一个节点,也是真正有意义的新链表的第一个节点,之后free掉我们所申请的占位置的节点,因为此时这个节点无用了,再把它置为空,防止后续对野指针解引用,最后返回ret,本题结束。
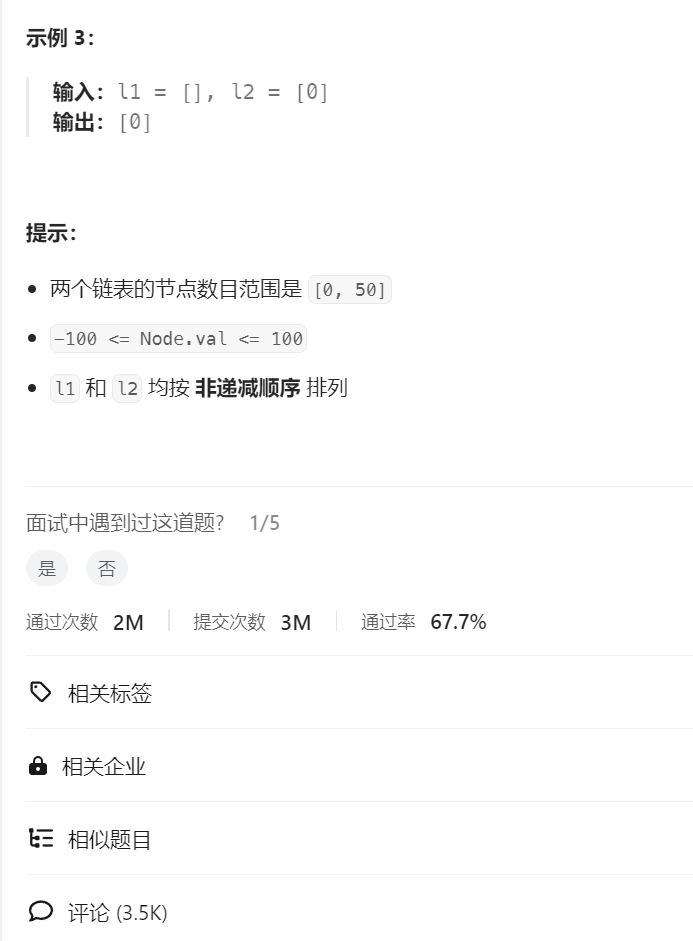
但大家一定有许多困惑,所以我们画图理解一下。
以示例1为例:
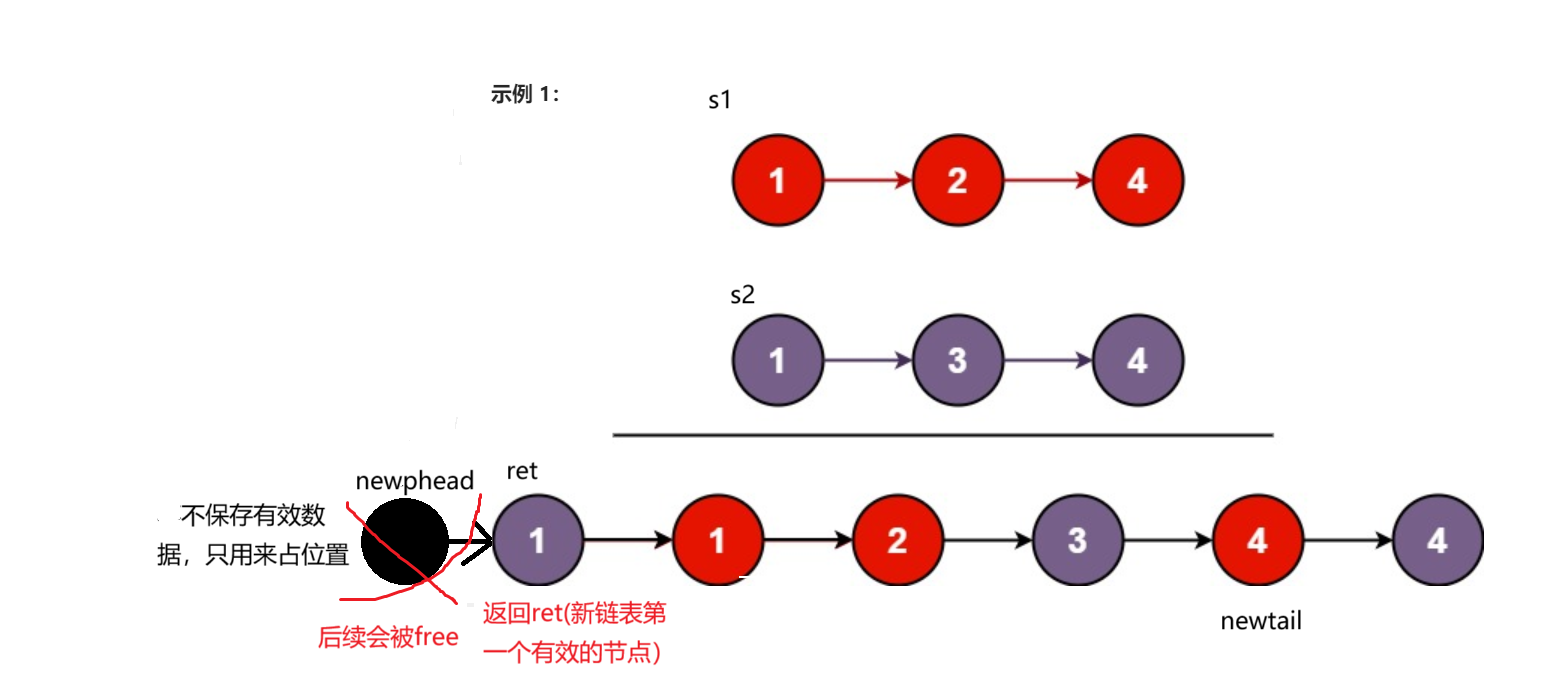
最后还有一个问题就是为什么出了循环之后后续尾插节点的条件为if呢,那是因为链表都是相连的,只要尾插一个结点,如果后续不做任何修改,后续的结点都会尾插到后面。
就像这样
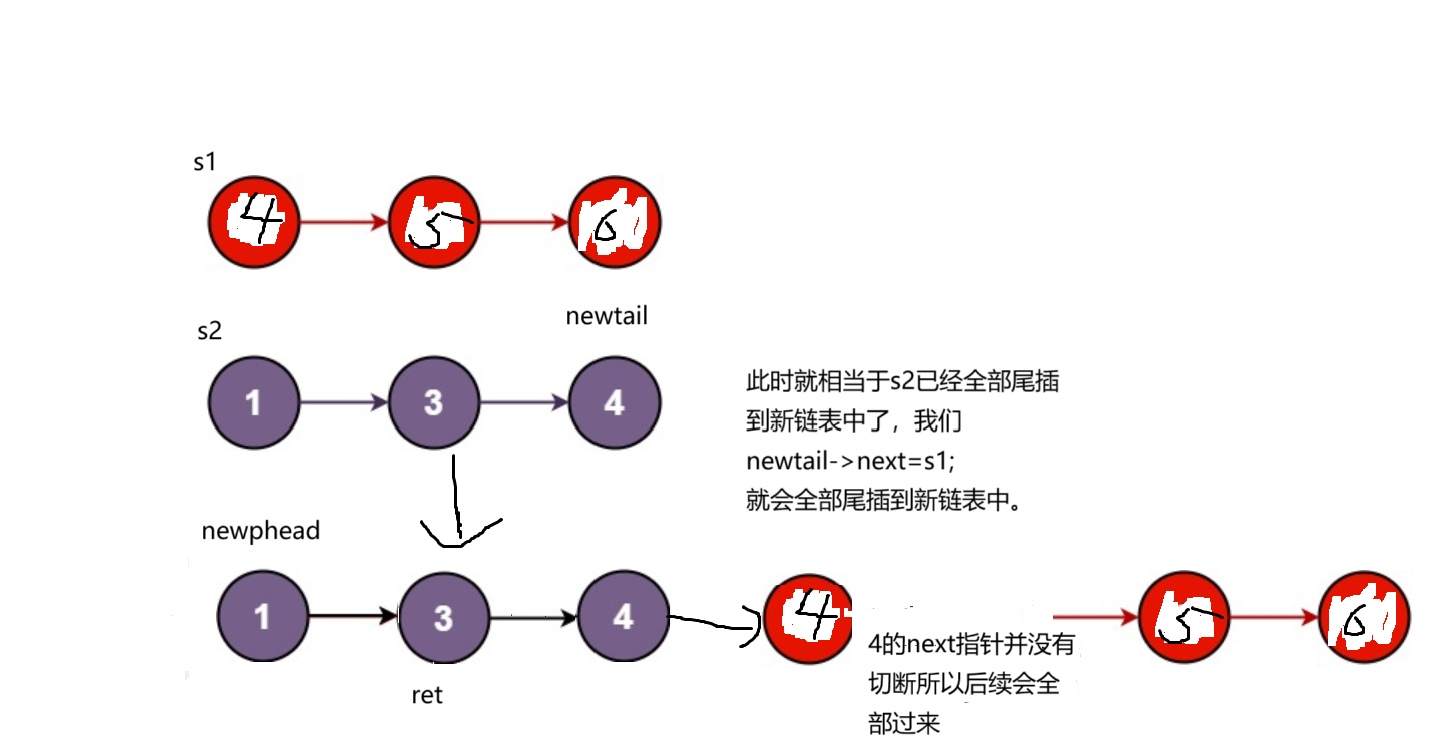
本题结束。
4.题目链接:
https://www.nowcoder.com/practice/0e27e0b064de4eacac178676ef9c9d70
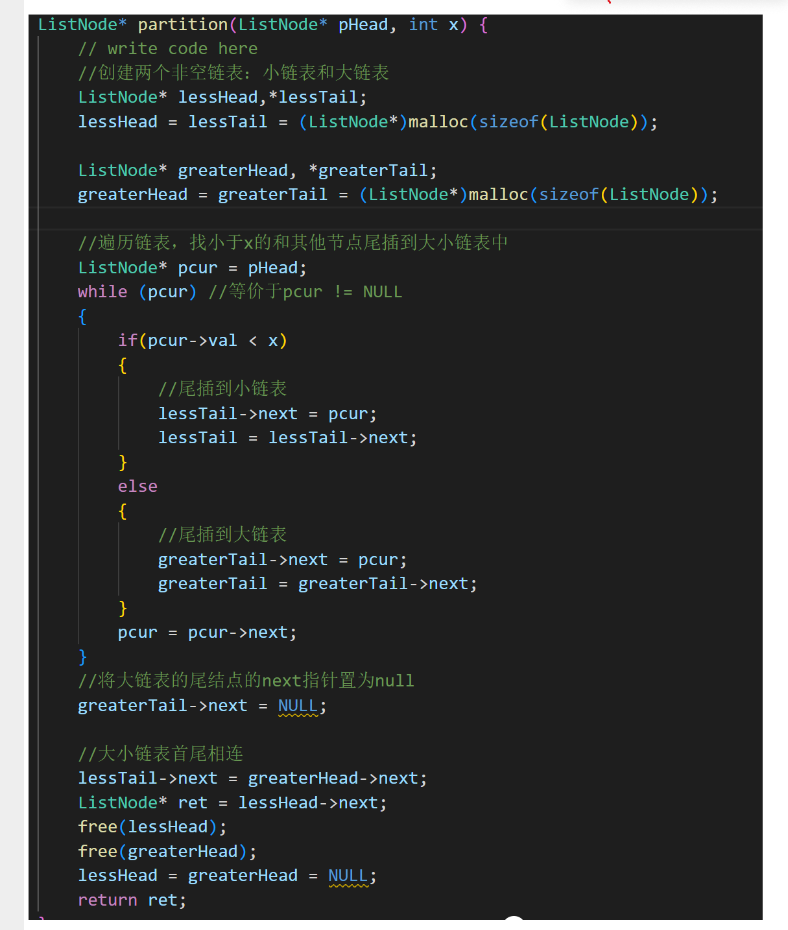
详细讲解: 这道题是牛客网的一道题,没有测试用例,可以自测运行,这个是用C++写的,不用typedef了,我们可以直接用ListNode*,但思路跟c语言一样。
1. 题目的意思就是已经给好了一个链表,然后让我们排列小于x的结点排在其余结点之前,且不能改变原来的数据顺序,返回重新排列后的链表的头指针。有了这个信息后我们就可以创建两个链表,一个所有结点的val值都小于x的链表也叫小链表(lessHead),一个所有结点的val值都大于x的链表也叫大链表(greaterHead)。
2. 这两个大小链表我们也需要动态申请一个结点的空间来占位置,否则向上道题一样,又需要判断大小链表是否为空,导致代码冗余。创建指针pcur指针用来遍历原链表,pcur不为空循环遍历尾插到大小链表中,尾插的代码与上到题基本一致,大家很容易看懂。而在跳出循环后我们把大链表的最后一个结点的next指针置为空(greaterTail->next=NULL),因为最后大小链表会进行连接,大链表会在小链表之后,否则会死循环。(等下画图理解)
3. 最后大小链表连接,LessTail->next=greaterHead->next(把小链表的最后一个节点连接在大链表的第一个有效节点),然后ret保存小链表的第一个有效结点,释放申请大小链表占位置的两个节点空间,并置为空,最后返回ret,本题就写完了。
我们画图理解一下:
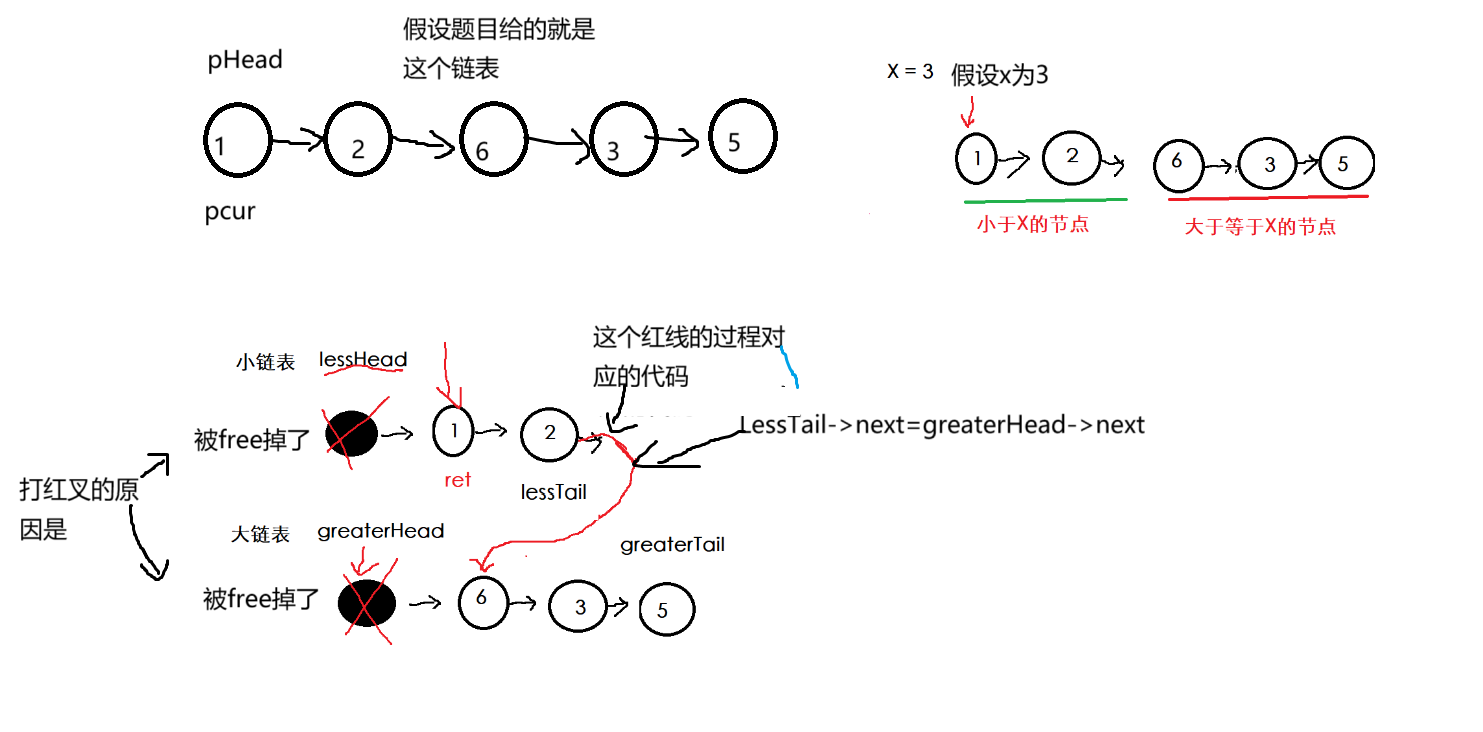
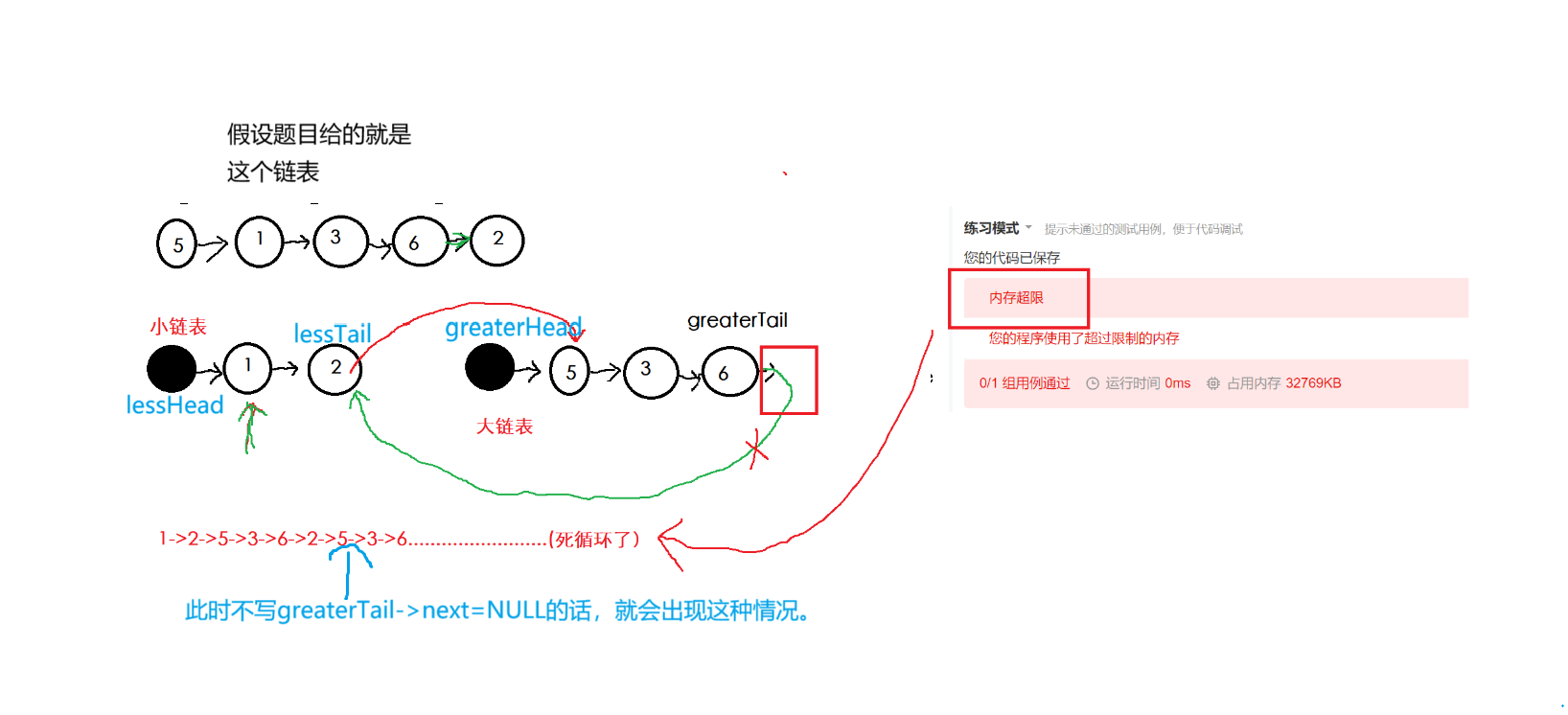
本题结束。
题目链接:
https://www.nowcoder.com/practice/d281619e4b3e4a60a2cc66ea32855bfa
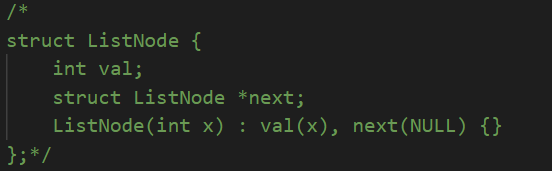
ListNode* middle(ListNode* s)
{
ListNode* fast = s;
ListNode* slow = s;
while (fast && fast->next)
{
slow = slow->next;
fast = fast->next;
}
return slow;
}
ListNode* reverse(ListNode* b)
{
ListNode* n1 = NULL;
ListNode* n2 = b;
ListNode* n3 = b->next;
while (n2)
{
n2->next = n1;
n1 = n2;
n2 = n3;
if (n3)
n3 = n3->next;
}
return n1;
}
class PalindromeList
{
public:
bool chkPalindrome(ListNode* A)
{
// write code here
ListNode* Findmiddle = middle(A);
ListNode*newnode= reverse(Findmiddle);
ListNode*pcur=newnode;
ListNode*pur=A;
while(pcur)
{
if(pcur->val!=pur->val)
{
return false;
}
pcur=pcur->next; 继续向后遍历
pur=pur->next; 继续向后遍历
}
return true;
}
};
详细讲解: 这道题也是牛客网的一道题,没有测试用例,可以自测运行,这个也是用C++写的,不用typedef了,我们可以直接用ListNode*,但思路跟c语言一样。这道题需用到本篇博客之前用过的两种算法。
1. 快慢指针找链表的中间结点
2. 用反转链表的方法将中间结点之后的链表反转
3. 从原链表和反转链表比较结点的值。
前两点我们都讲过了,我们主要看一下第3点,此时newnode指向反转完中间结点之后的链表的第一个节点,定义一个pcur指针遍历反转之后的链表,定义pur指针遍历原链表,当pcur走到空时跳出循环,因为反转完中间结点之后的链表肯定比原链表要短,更先能走到空,所以以pcur!=NULL为跳出循环条件,循环期间如果有一个val值不相同,就不是回文结构返回false,如果都相同就是回文结构,返回true。本题就写完了,这道题看似简单,其实是建立在我们会了之前的两种算法,否则就像牛客网给的那样,本题就较难了。
以牛客网给的测试样例,我们画图理解一下:
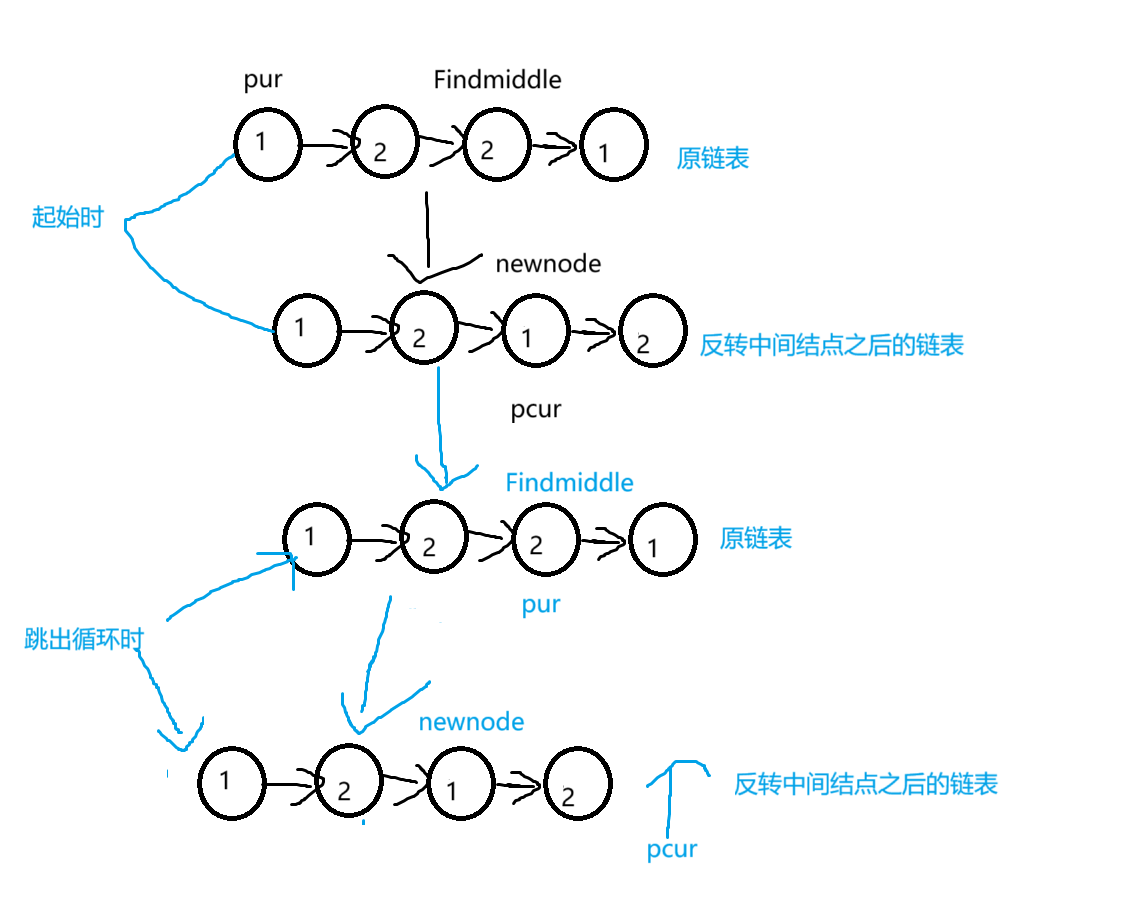
本题结束。
题目链接:
https://leetcode.cn/problems/intersection-of-two-linked-lists/description/

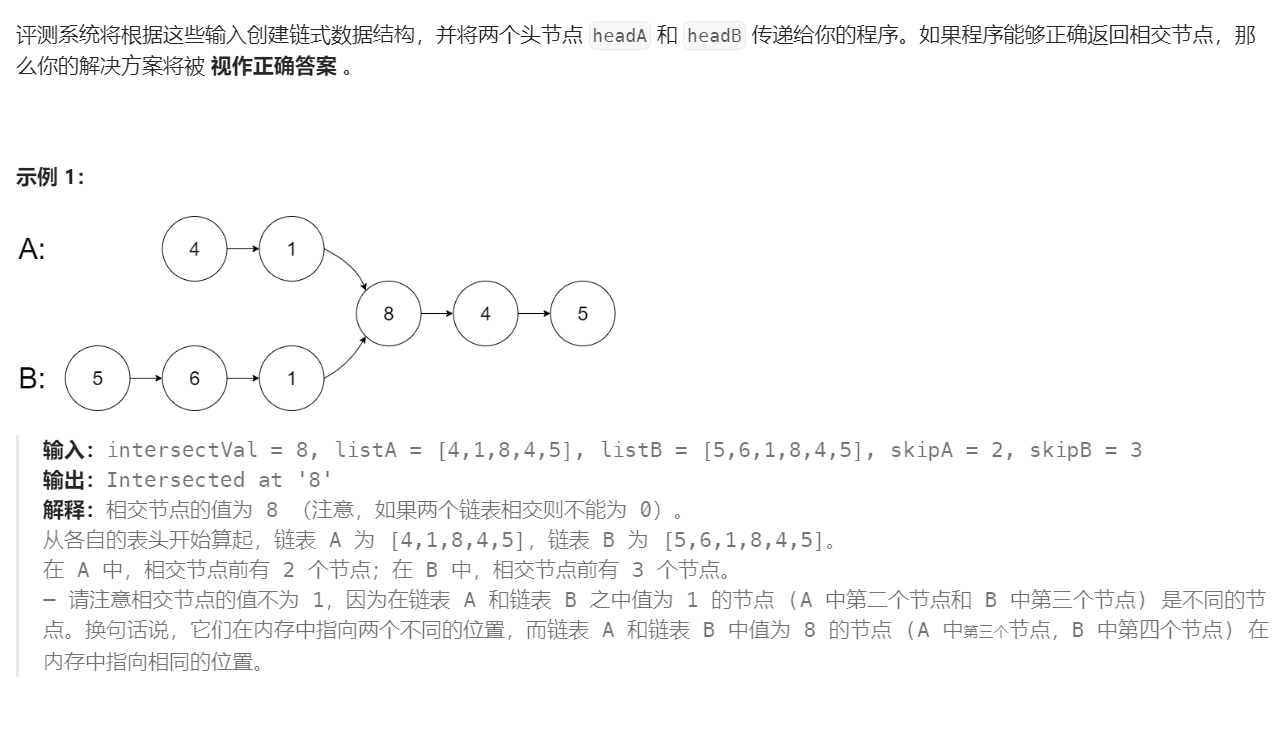

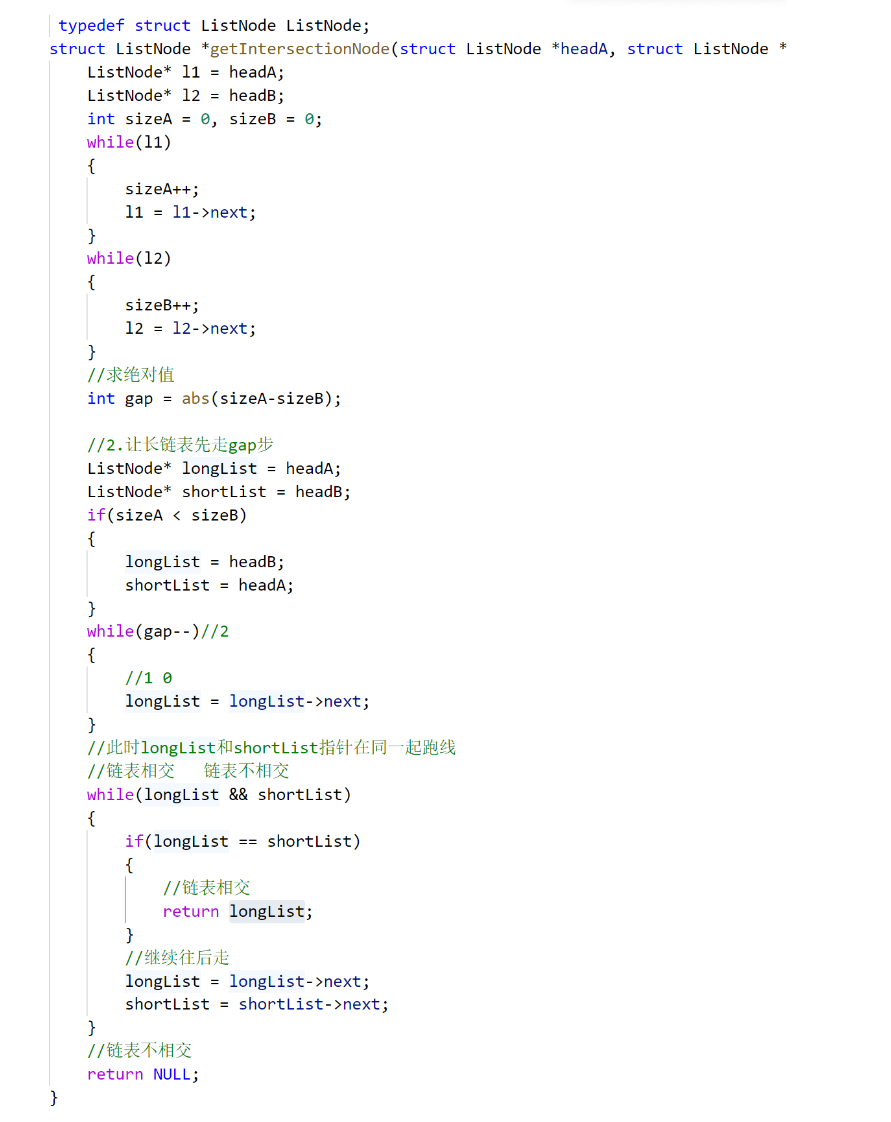
算法思路:
1. 首先我们要理解何为相交,相交链表是指两个链表从头开始遍历,尾结点一定是同一个节点,并且题目说数据保证整个链式结构中不存在环,表示这个链表一定是不死循环的,就是尾结点的next指针一定为空,还有题目说要求函数返回结果后,链表必须保持原始结构,也就是我们不能更改题目给的链表。
2. 相交链表有两种情况
链表结点个数相同:两个链表开始遍历,比较是否为同一个节点。
链表结点个数不同:
(1) 找两个链表的节点数差值。
(2) 长链表先走差值步。
(3)两个链表开始遍历,比较是否为同一个节点。
详细讲解:
1. 创建连个指针(l1,l2),分别指向题目给的两个链表,然后创建两个表变量(sizeA和sizeB)。
sizeA记录headA结点的个数,sizeB记录headB中结点的个数用abs(sizeA-sizeB),此时求出的是差值的绝对值,原因是防止负数的出现
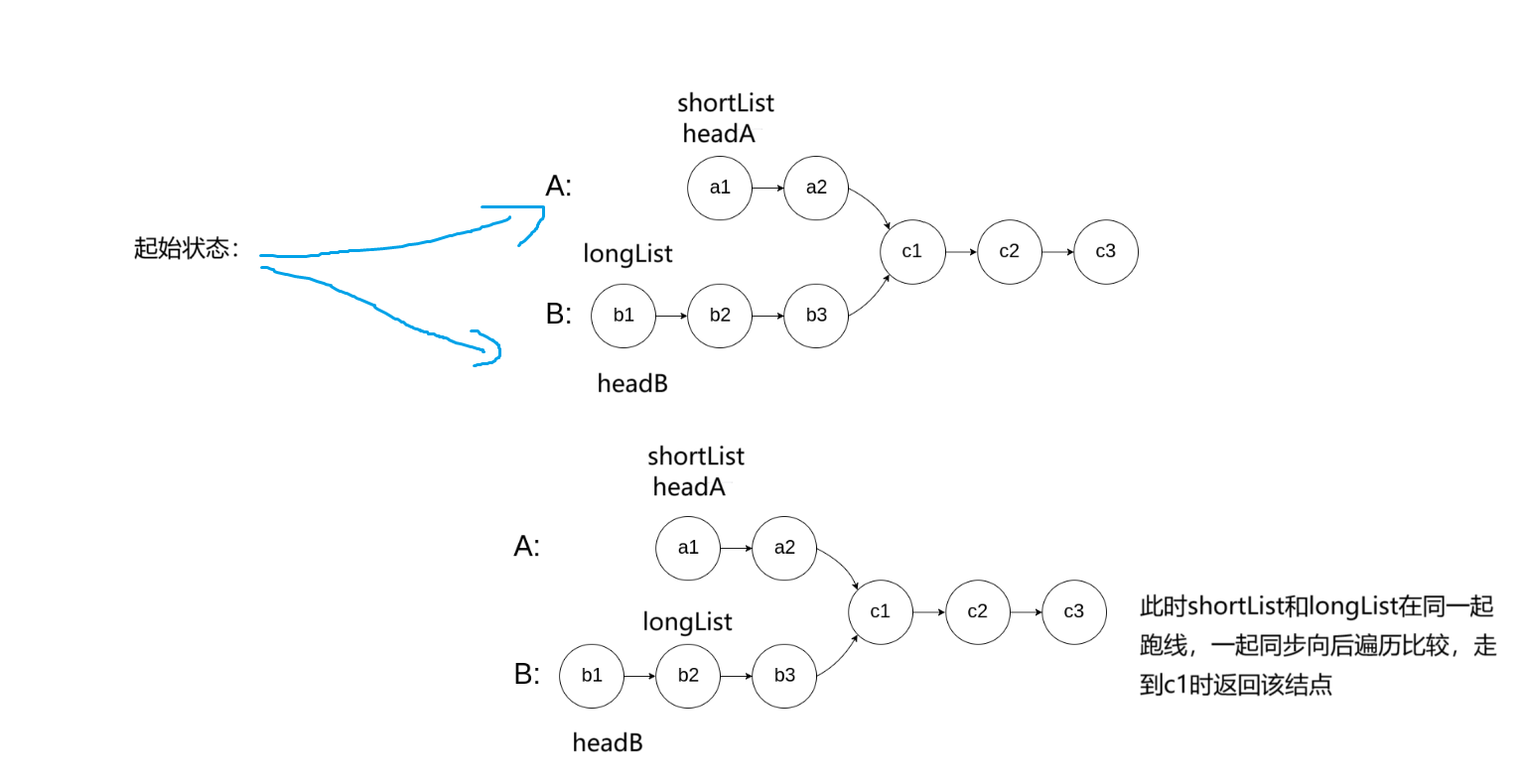
2. 我们首先默认headA是长链表(longList),headB是短链表(shortList),但是如果sizeA<sizeB,证明此时headA就是短链表(shortList),而headB就是长链表(longList),之后让长链表先走差值步(gap)
3. 此时longList和shortList指针在同一起跑线上,循环遍历比较,找到了相交结点返回该节点,如果跳出了循环(longList&&shortList)就证明没到,返回NULL。
以示例1为例,我们画图理解一下:
本题结束。
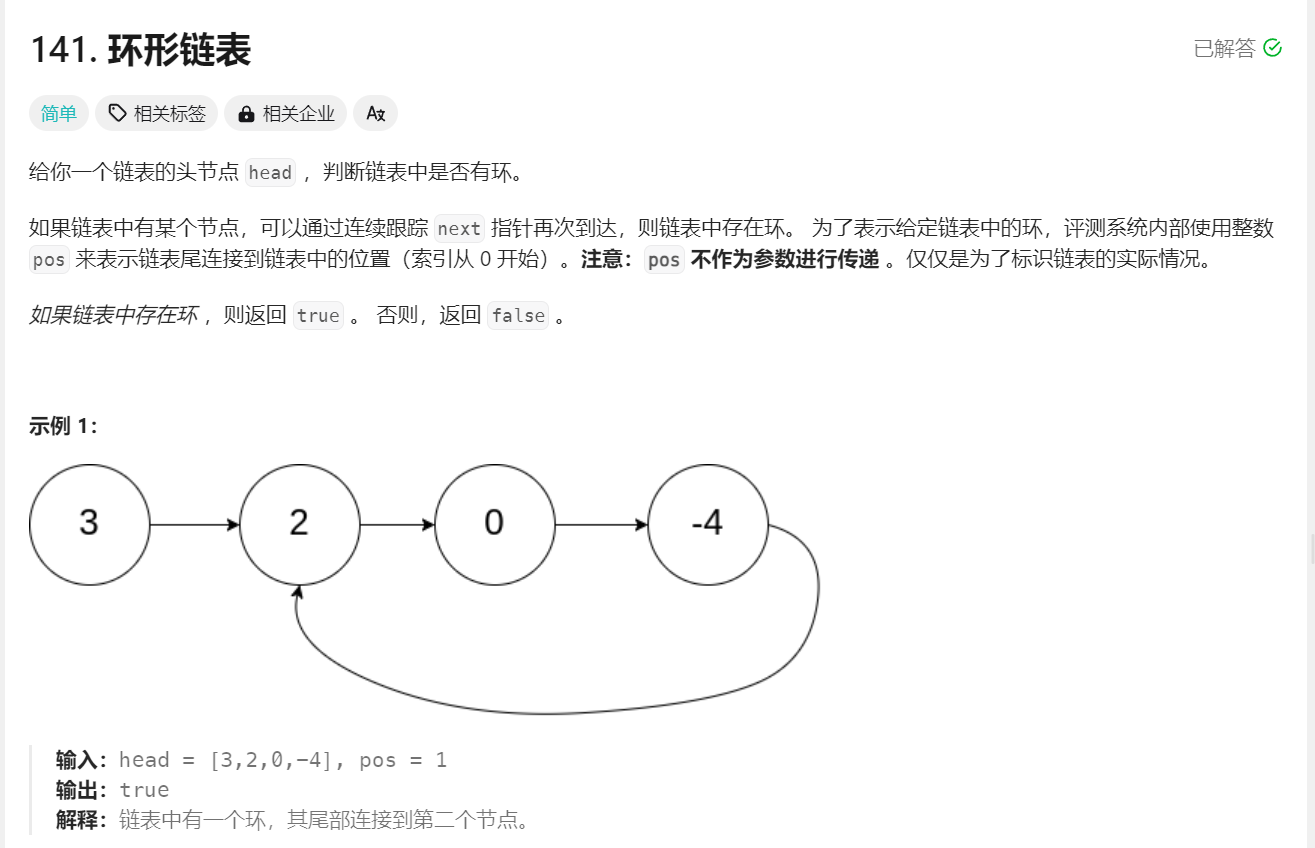
题目链接: https://leetcode.cn/problems/linked-list-cycle/description/
typedef struct ListNode ListNode;
bool hasCycle(struct ListNode* head)
{
ListNode* fast = head;
ListNode* slow = head;
while (fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
if (fast == slow)
{
return true;
}
}
return false;
}
详细讲解:本题又一次用到了快慢指针,显而易见,快慢指针是多么重要。

1. 所以我们本题直接用快慢指针就好了,如果快指针和慢指针相遇就代表链表带环,此时返回true就好了,而出了循环代表快慢指针一直没有相遇就代表链表不带环,返回false就可以了。
思考1:为什么快指针每次⾛两步,慢指针⾛⼀步在带环链表中可以相遇,有没有可能遇不上,我们推理证明一下
step1:
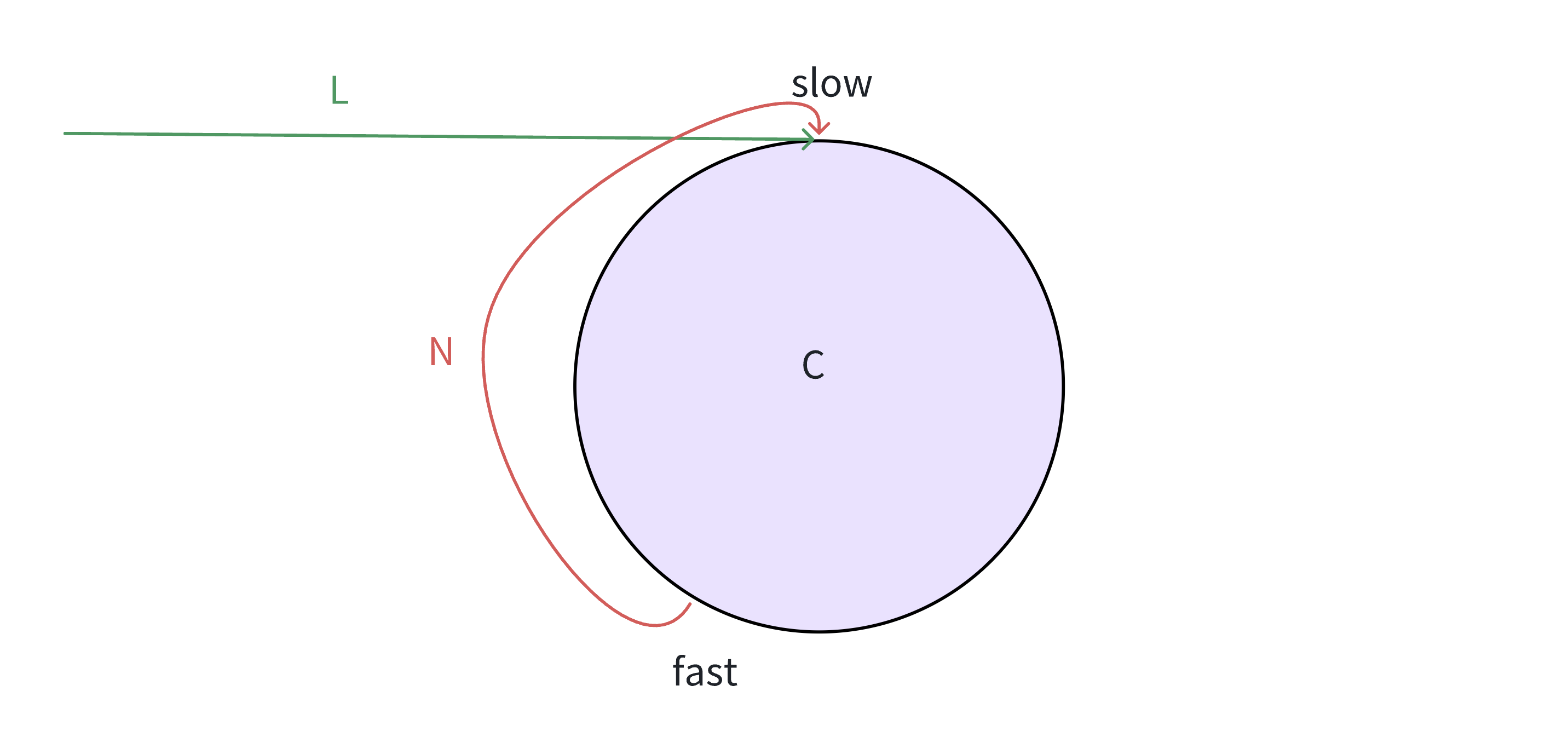
slow⼀次⾛⼀步,fast⼀次⾛2步,fast先进环,假设slow也⾛完⼊环前的距离,准备进环,此时fast和slow之间的距离为N,接下来的追逐过程中,每追击⼀次,他们之间的距离缩⼩1步追击过程中fast和slow之间的距离变化:

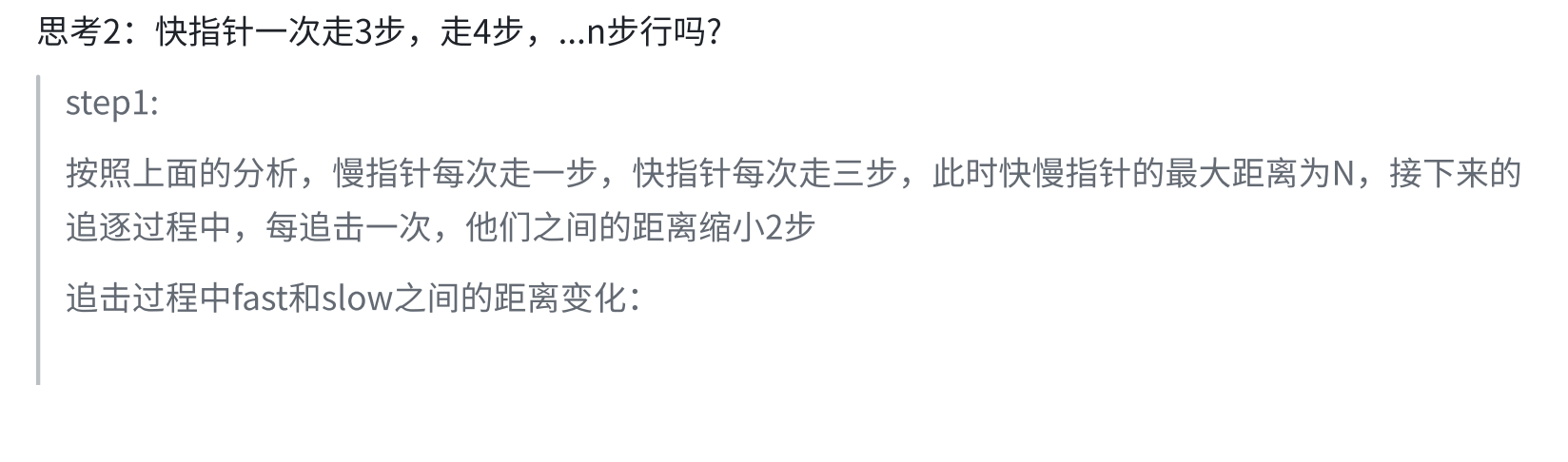
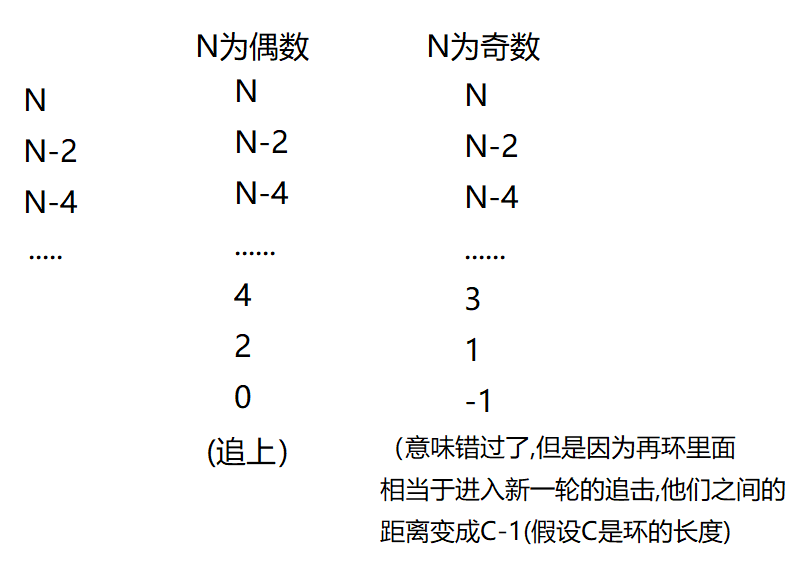

例2:
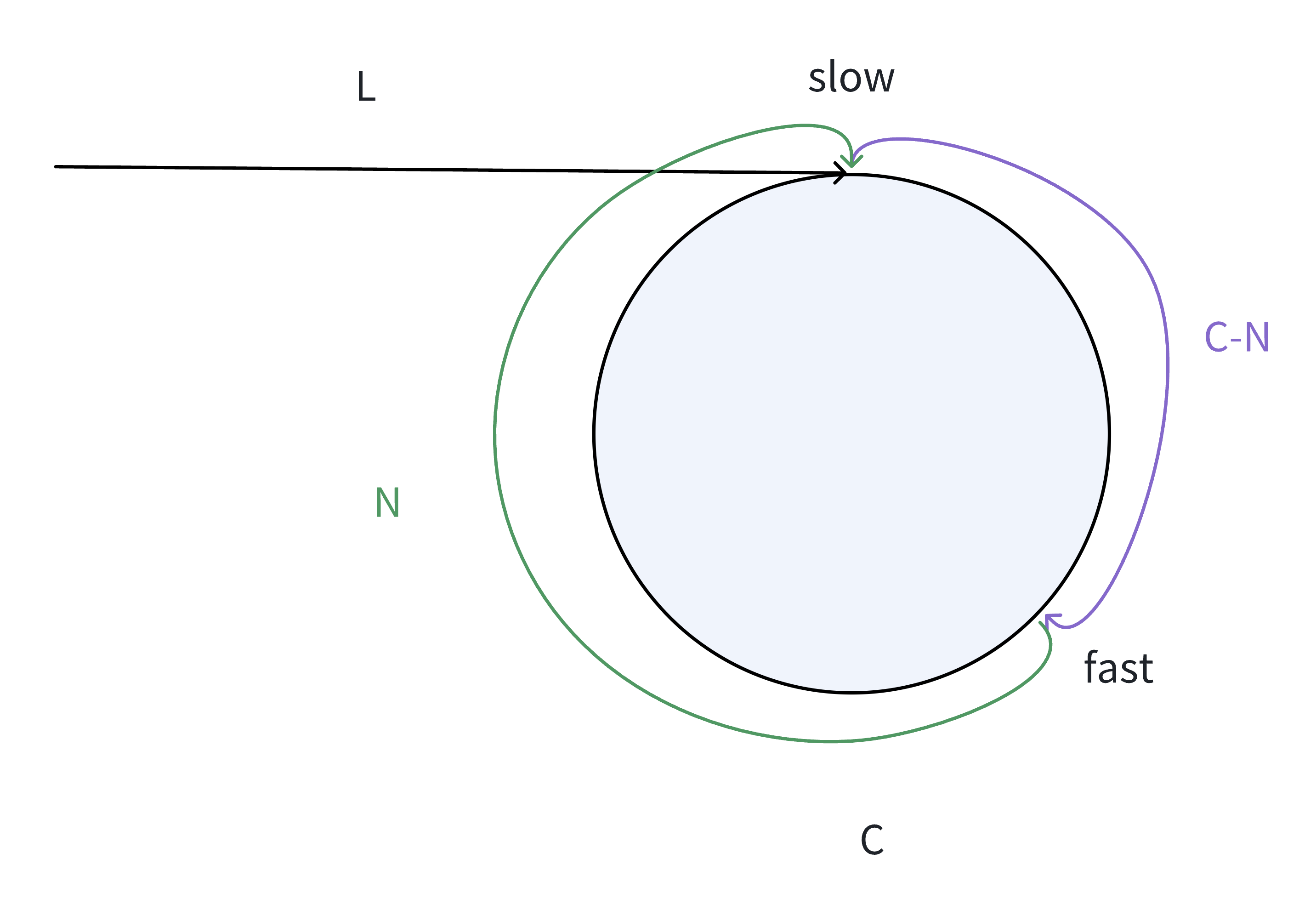



本题结束。
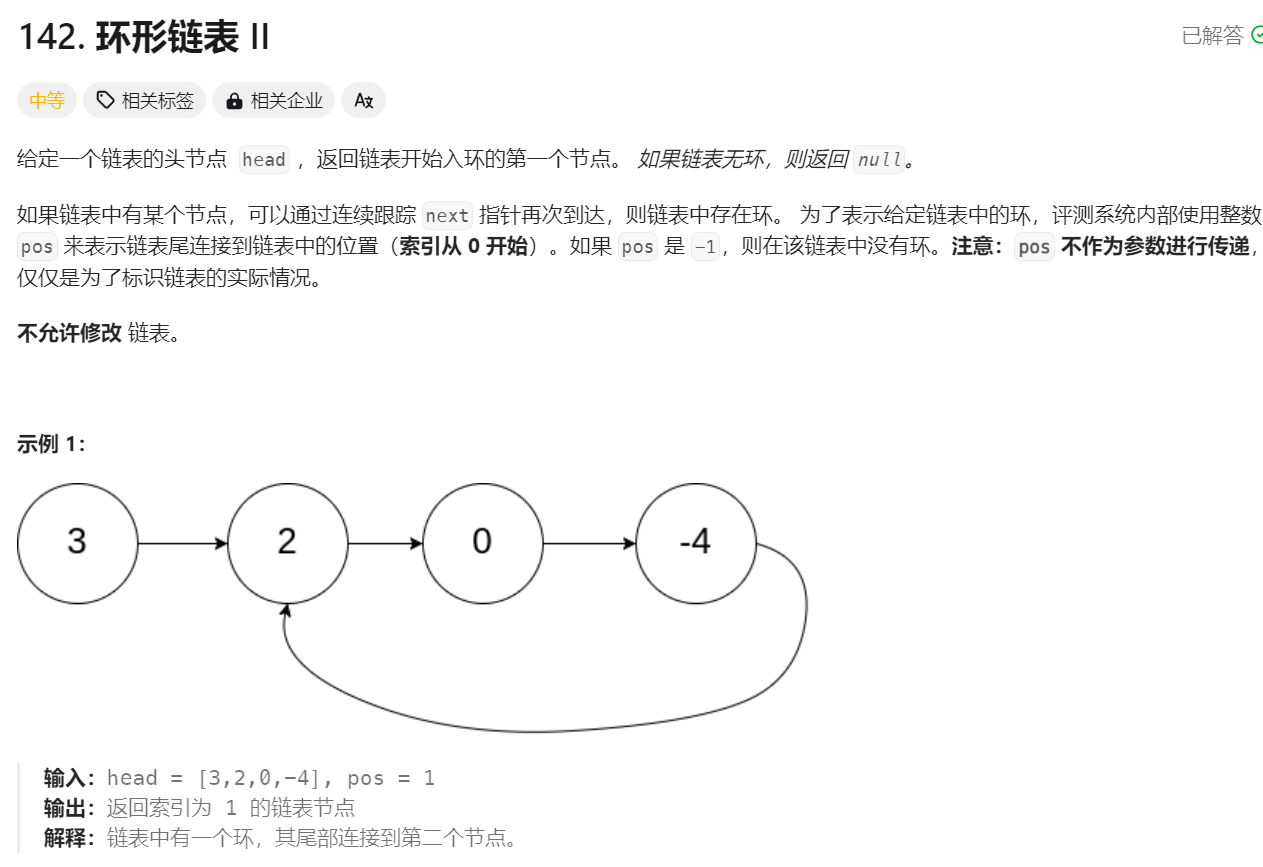
题目链接:
https://leetcode.cn/problems/linked-list-cycle-ii/description/

typedef struct ListNode ListNode;
struct ListNode* detectCycle(struct ListNode* head)
{
ListNode* fast = head;
ListNode* slow = head;
ListNode* pcur = head;
while (fast&&fast->next)
{
slow = slow->next;
fast = fast->next->next;
if (fast == slow)
{
pcur = head;
while (pcur != fast)
{
pcur = pcur->next;
fast = fast->next;
}
return fast;
}
}
return NULL;
}
详细讲解:这道题也是环形链表,肯定也就用到了快慢指针,但不同的是这次返回的是开始入环的第一个结点。
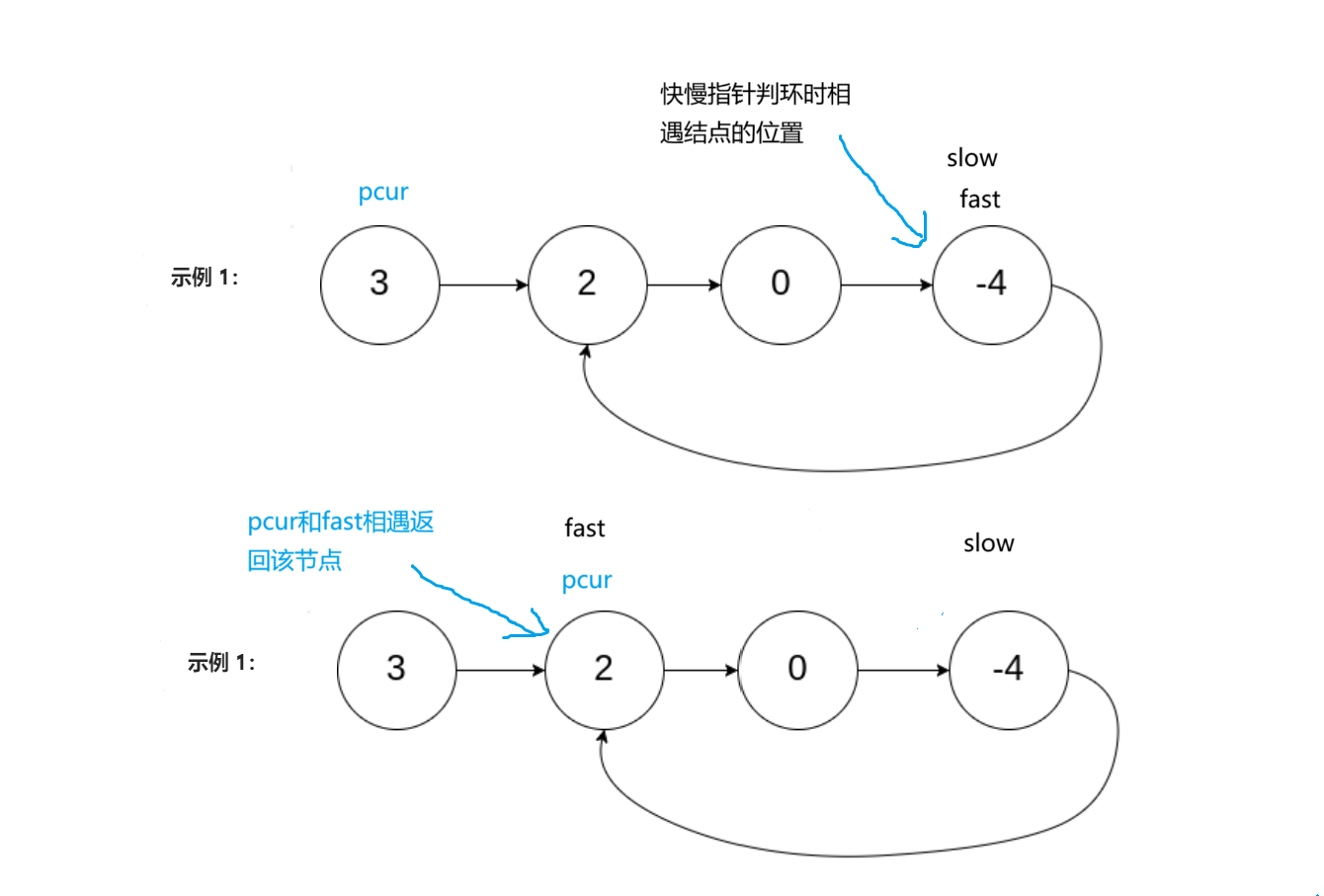
1. 这个算法就是先用快慢指针找到判环时快慢指针相遇结点的位置,然后创建一个pcur从链表的第一个结点开始和快慢指针的任意一个指针同步向后遍历,以快指针为例,fast和pcur每次都向后走一步,直到pcur和fast相遇返回该结点,此时该结点就是题目要求的入环结点,如果出了循环还没有相遇,就代表链表无环,此时返回NULL。
以示例1为例,我们画图理解一下:

接下来我们来证明一下:
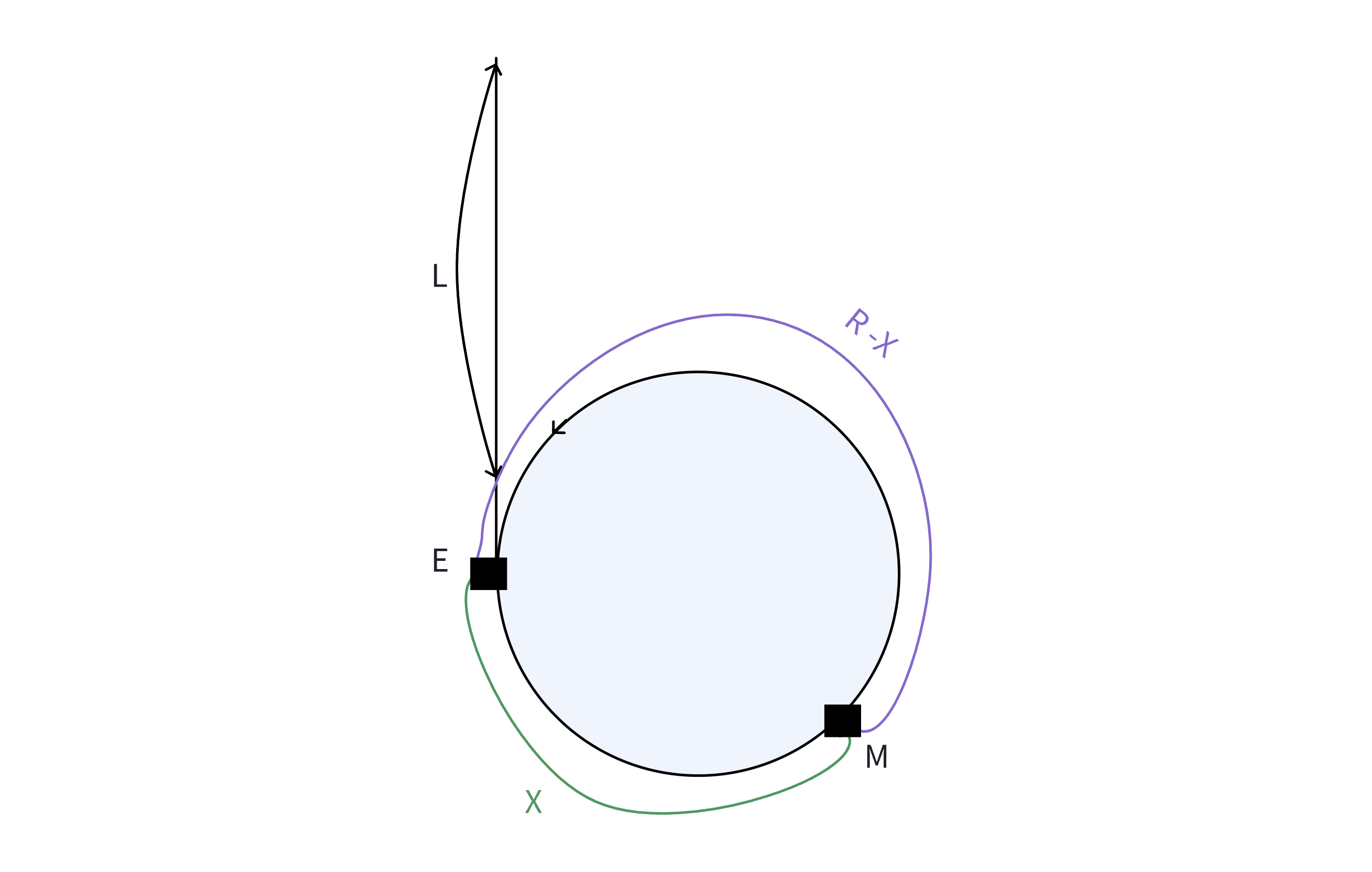


本题结束。
题目链接:
https://leetcode.cn/problems/copy-list-with-random-pointer/description/

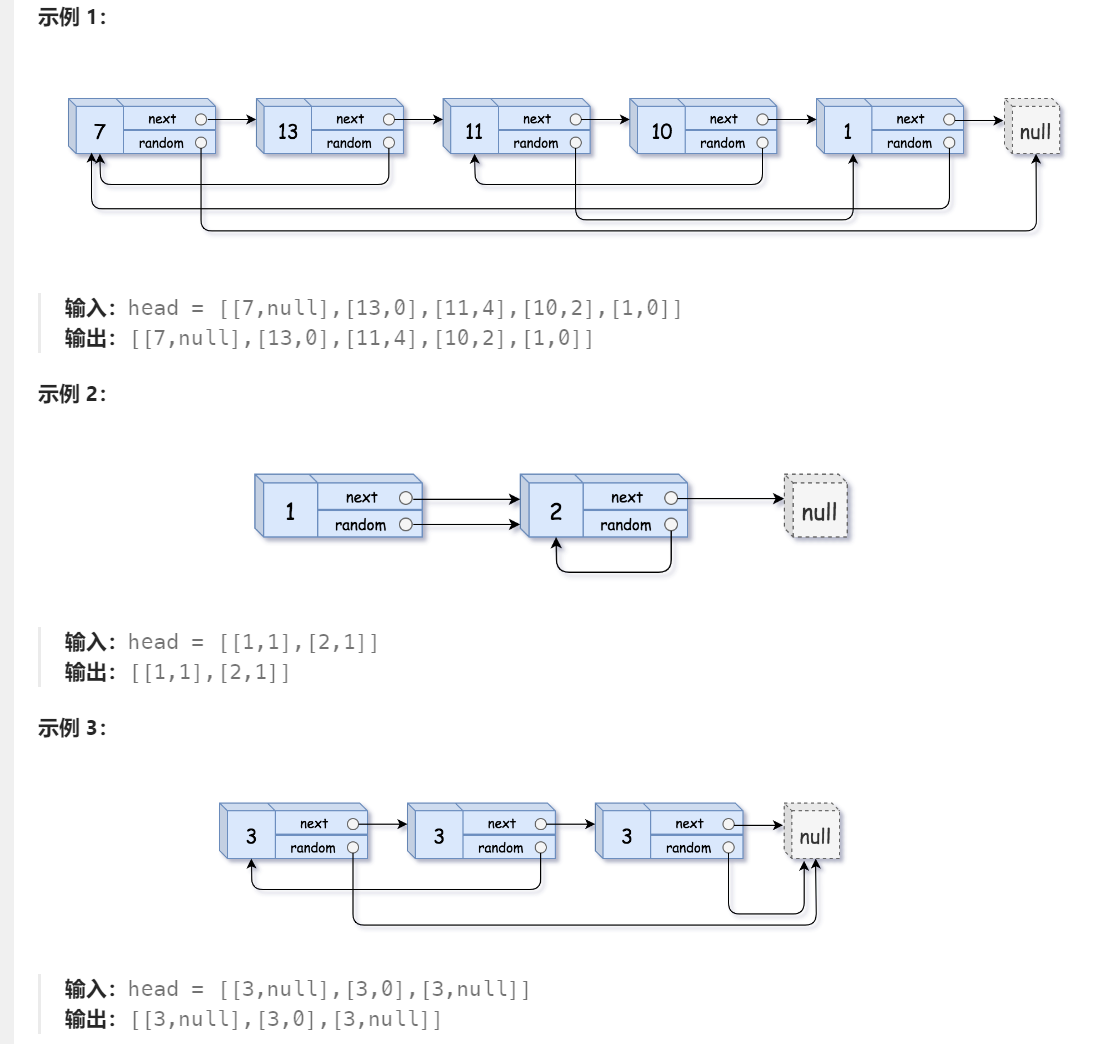

typedef struct Node Node;
Node* Buynewnode(int x) //动态申请新结点
{
Node* newnode = (Node*)malloc(sizeof(Node));
newnode->val = x;
newnode->next = newnode->random = NULL;
return newnode;
}
void Addnewnode(Node* phead) //在原链表基础上继续复制链表
{
Node* pcur = phead;
while (pcur)
{
Node* Next=pcur->next;
Node* newnode = Buynewnode(pcur->val);
pcur->next = newnode;
newnode->next = Next;
pcur = Next;
}
}
struct Node* copyRandomList(struct Node* head)
{
if (head == NULL)
{
return NULL;
}
Addnewnode(head);
Node*pcur = head;
while (pcur) //置random指针
{
Node* copy = pcur->next;
if (pcur->random != NULL)
{
copy->random = pcur->random->next;
}
pcur = copy->next;
}
Node *newhead, *newtail;
pcur = head;
newhead = newtail = pcur->next;
while (pcur->next->next) //复制链表和原链表断开
{
pcur = pcur->next->next;
newtail->next = pcur->next;
newtail = newtail->next;
}
return newhead;
}
详细讲解:本题说了要深拷贝,那我们就不能在原链表进行修改了,而是新建一个链表。
首先如果链表为空直接返回NULL,具体步骤:我们分三步走。

1. 在原链表基础上继续复制链表:我们先创建一个pcur指针遍历原链表,创建Next指针保存pcur的下一个结点,动态申请新结点 (newnode) 把它尾插到pcur的下一个结点(pcur->next=newnode),此时pcur的next指针已经被修改了,所以我们才会创建Next指针保存原pcur的下一个结点,然后让newnode的next指针指向原pcur的下一个节点(Next)。此时插入成功。
然后让pcur走到Next的位置。此时链表变成:
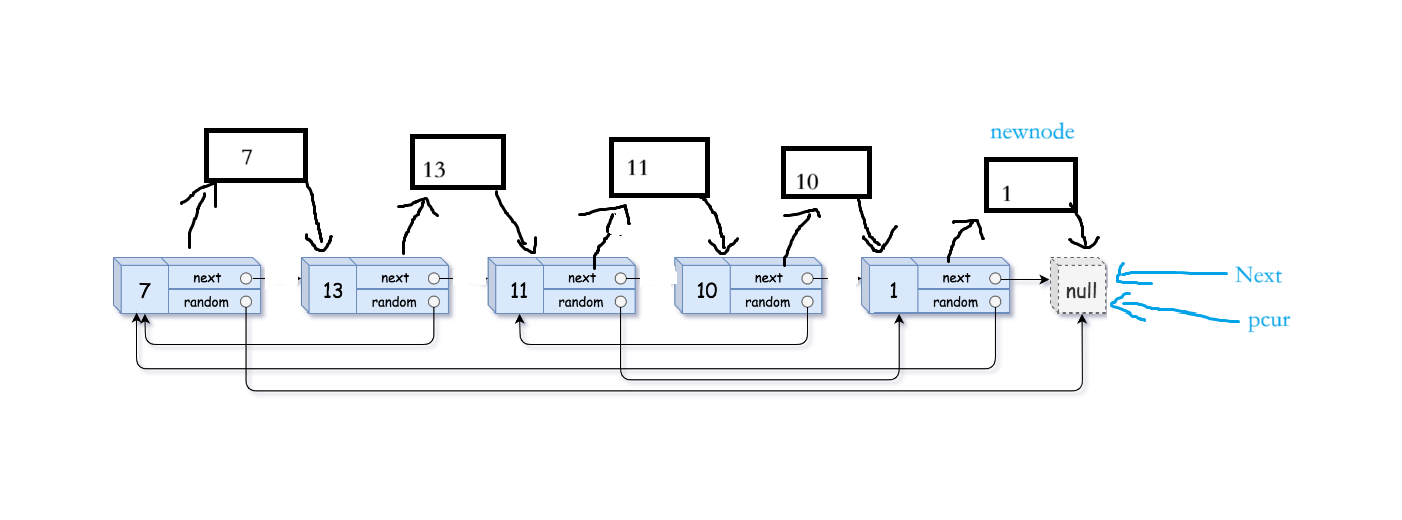
大家根据代码理解很容易看懂。
2. 置random指针:pcur重新指向链表第一个结点,如果原链表的random指针为空,我们就不用置random指针了,因为我们申请新结点空间时,默认就是把random指针置为空,所以我们不进行处理,但如果不为空我们进行处理。
我们创建的新链表与原链表的random指针一样,原链表13的random指针指向原链表值为7的节点,那我们新链表13的random指针也指向我们新申请链表的值为7的节点。
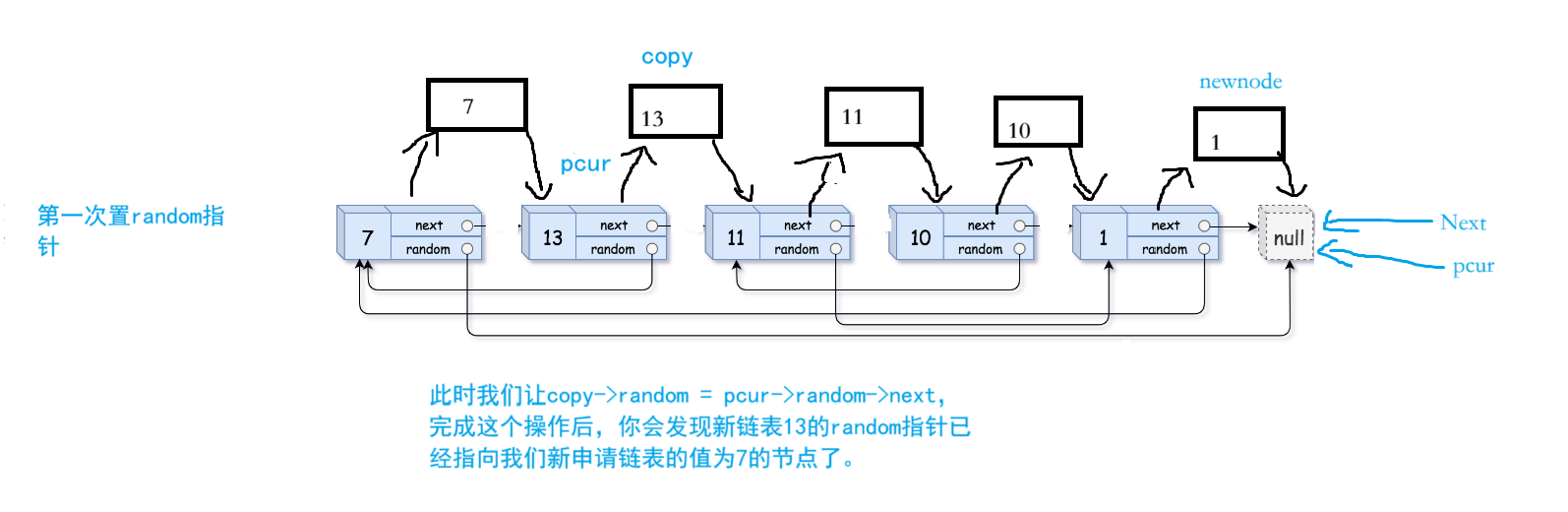
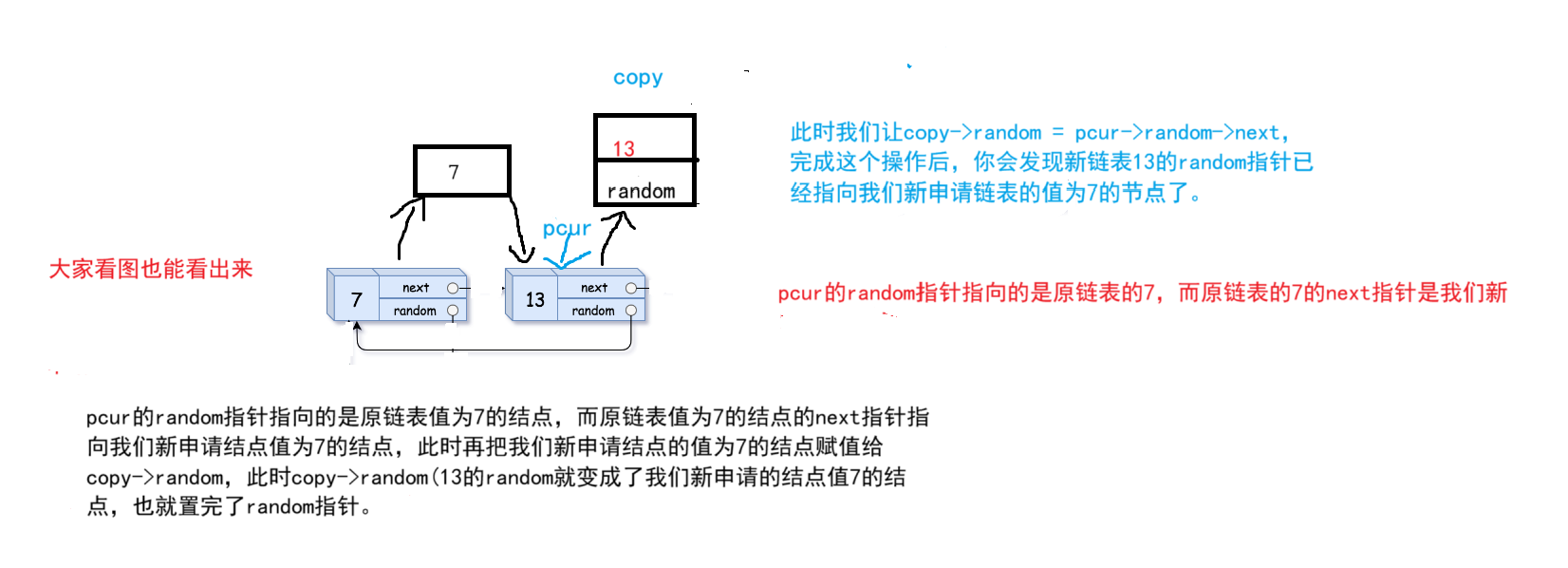
注意每个结点都有一个值和两个指针,只是我没画出来,因为画出来会比较乱,画的图会不直观,也会不好理解。
3. 复制链表和原链表断开:我们继续把pcur指向原链表的第一个结点,再创建两个指针(newhead和newtail)。
注:pcur->next就是新链表的第一个节点。
newhead:保存新链表的第一个节点。
newtail: 遍历新链表。
我们先让pcur走两步,然后newtail->next = pcur->next(改变新链表next指针的指向),
newtail = newtail->next(新链表继续向后遍历)。
最后返回新链表的第一个节点(newhead)。
注:因为pcur每次走两步,所以循环条件为pcur->next->next !=NULL
注意:这道题目之前的举例都是以示例1为例,现在这个例子也是一样,我们画图一看就会:
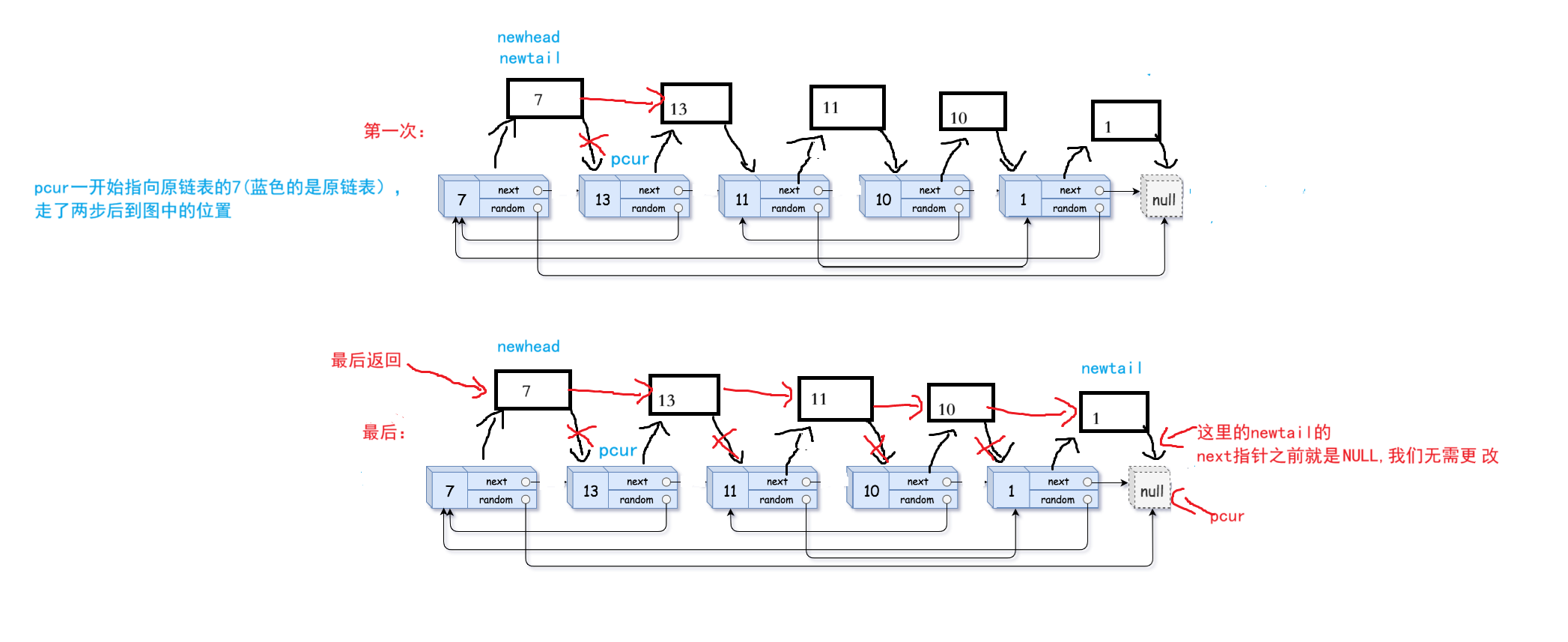
注意:pcur进入循环后就会先走两步,所以第一次就到了图中的位置。
大家对照代码一看就会。
本篇博客结束。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









