






YOLO系列
YOLO-V3
优点:
终于到V3了,最大的改进就是网络结构,使其更适合小目标检测。
特征做的更细致,融入多持续特征图信息来预测不同规格物体。
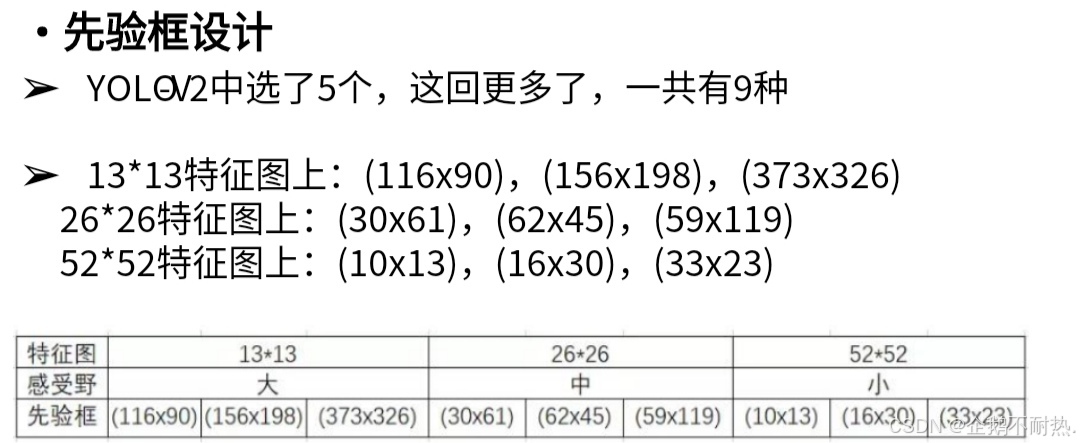
先验框更丰富了,3种scale,每种3个规格,一共9种。
softmax改进,预测多标签任务。
多scale
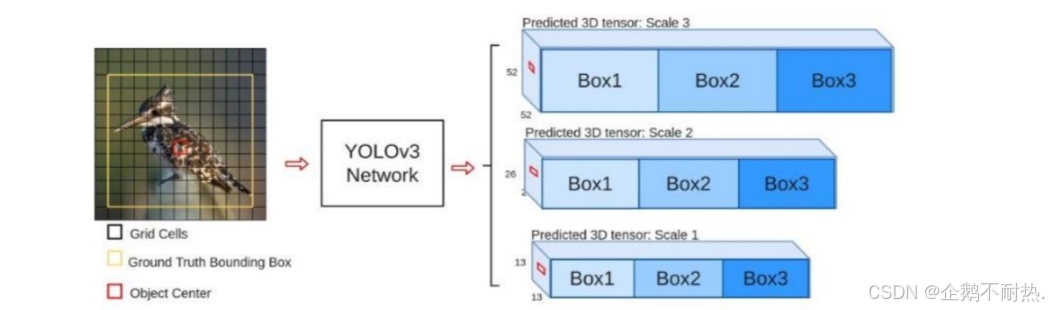
步长越大代表我们得到的最后一个图像尺寸越小。
scale变换经典方法
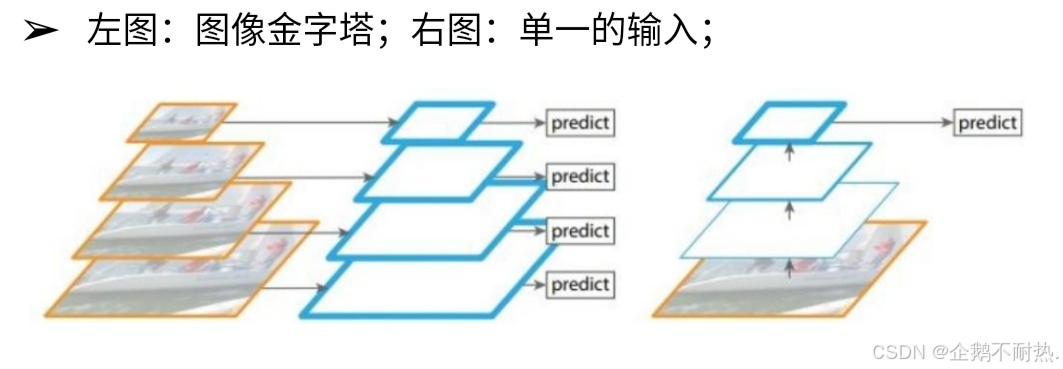
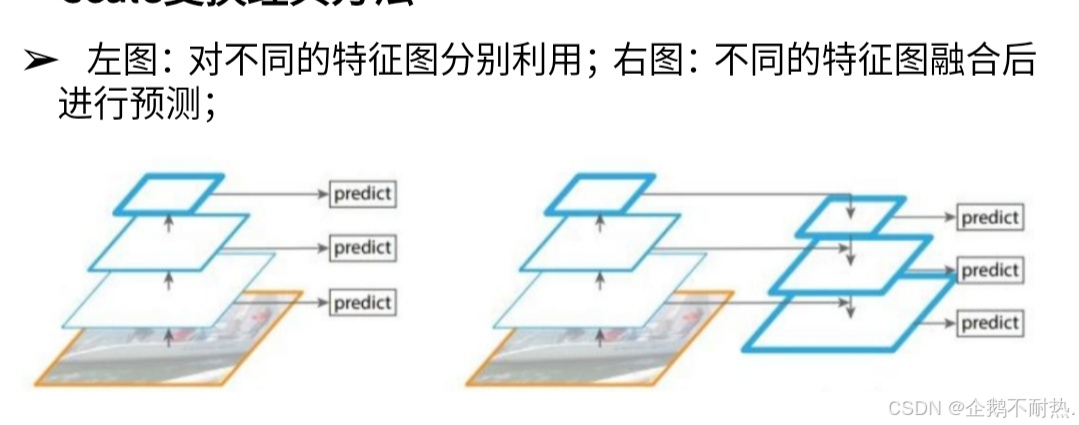 卷积 可以实现下采集,图片尺寸变小是下采样,图片尺寸变大是上采样。
卷积 可以实现下采集,图片尺寸变小是下采样,图片尺寸变大是上采样。
残差连接-为了更好的特征
从今天的角度来看,基本所有网络架构都用上了残差连接的方法。
V3中也用了resnet的思想,堆叠更多的层来进行特征提取。
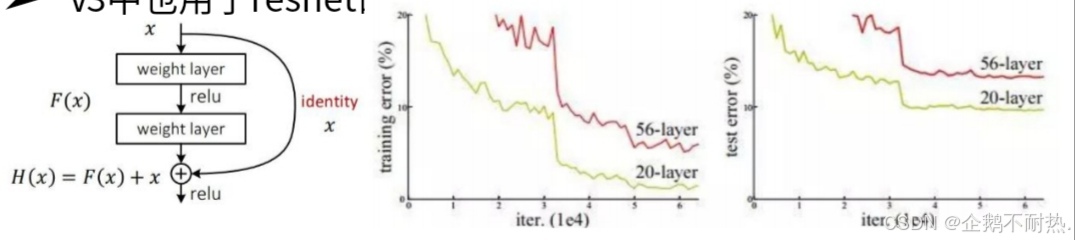
resnet可以确保它增加层数,但不会对最后的结果产生下降的影响。
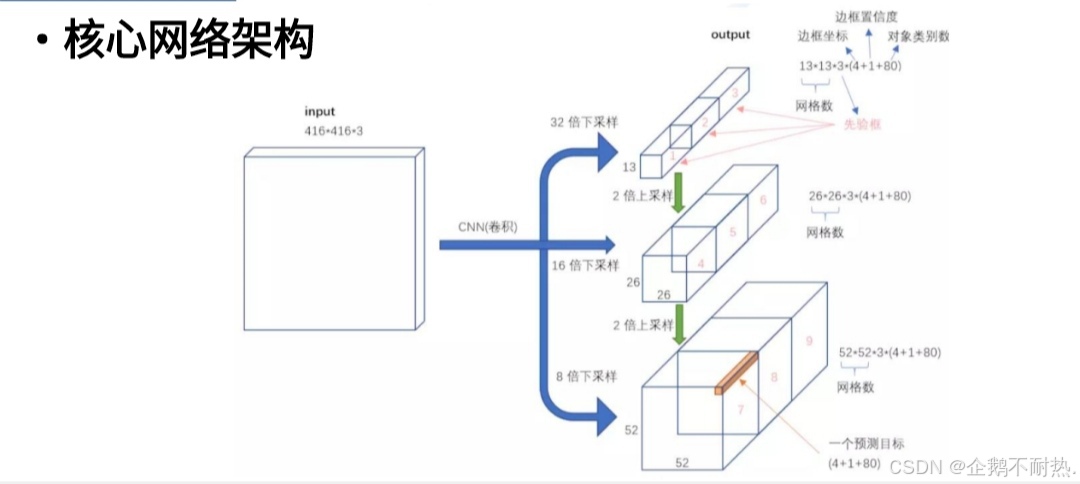
核心网络架构
没有池化和全连接层,全部卷积下采样通过stride为2实现3种scale,更多先验框基本上当下经典做法全融入了。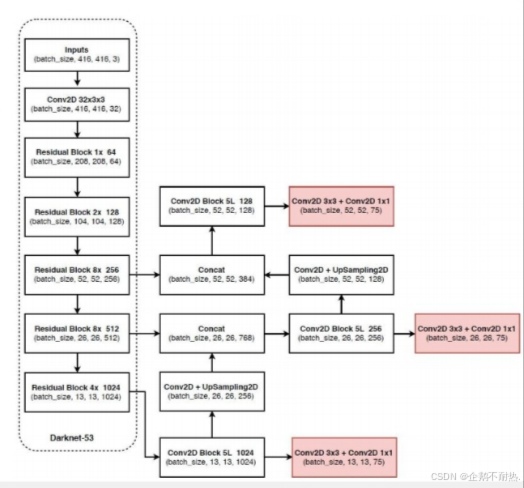
52x52适合测试小目标,26x26适合测试中目标,13x13适合测试大目标。图中的block代表一些卷积操作。

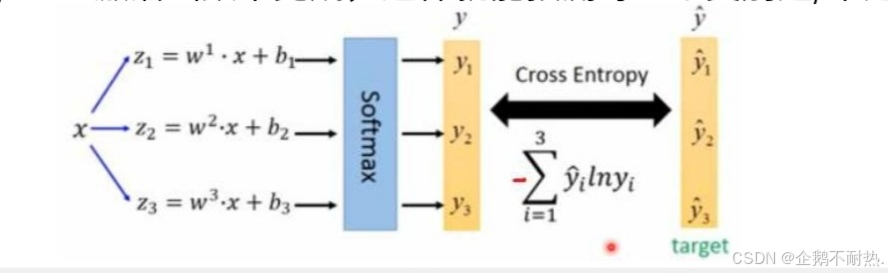
softmax层替代
物体检测任务中可能一个物体有多个标签。
logistic激活函数来完成,这样就能预测每一个类别是/不是。
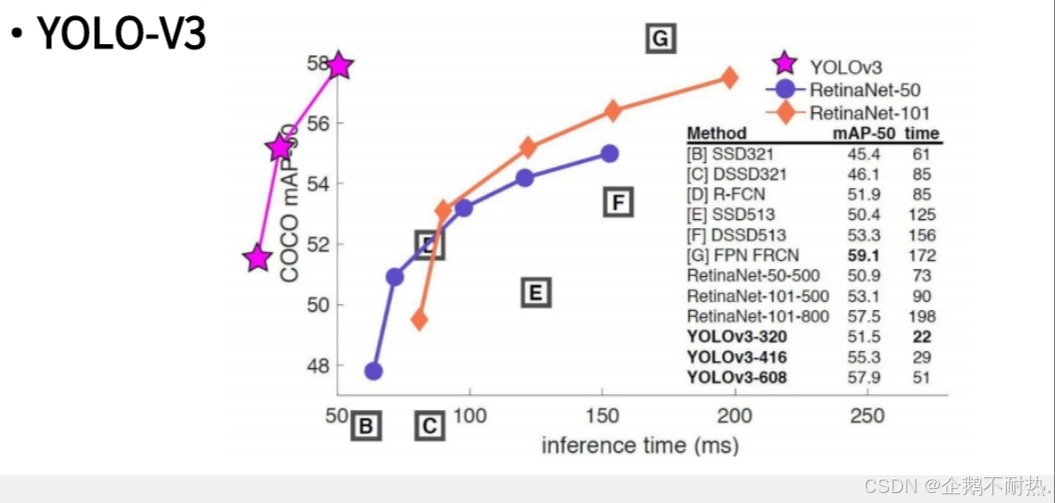
总结: v3与前两个对比,v3在预测时间和MAP(平均精度均值)上更有优势。
在网络结构改进方面,v3更适合检测小目标,并且特征提取更加细致,融入了多尺度的特征图信息。
在softmax回归改进方面,针对多标签任务,v3采用了新的激活函数,允许一个物体存在多标签,并通过设定阈值来确定标签。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









