






找出所有有效数据,要求电话号码为11位,但只要列中没有空值就算有效数据。
按地址分类,输出条数最多的前20个地址及其数据。
代码讲解:
导包和声明对象,设置Spark配置对象和SparkContext对象。
使用Spark SQL语言进行数据处理,包括创建数据库、数据表,导入数据文件,进行数据转换。
筛选有效数据并存储到新表中。
按地址分组并统计出现次数,排序并输出前20个地址。
Spark Streaming介绍Spark Streaming概述:
用于流式计算,处理实时数据流。
支持多种数据输入源(如Kafka、Flume、Twitter、TCP套接字等)和输出存储位置(如HDFS、数据库等)。
Spark Streaming特点:
易用性:支持Java、Python、Scala等编程语言,编写实时计算程序如同编写批处理程序。
容错性:无需额外代码和配置即可恢复丢失的数据,确保实时计算的可靠性。
整合性:可以在Spark上运行,允许重复使用相关代码进行批处理,实现交互式查询操作。
Spark Streaming架构:
驱动程序(StreamingContext)处理数据并传给SparkContext。
工作节点接收和处理数据,执行任务并备份数据到其他节点。
背压机制协调数据接收能力和资源处理能力,避免数据堆积和资源浪费。
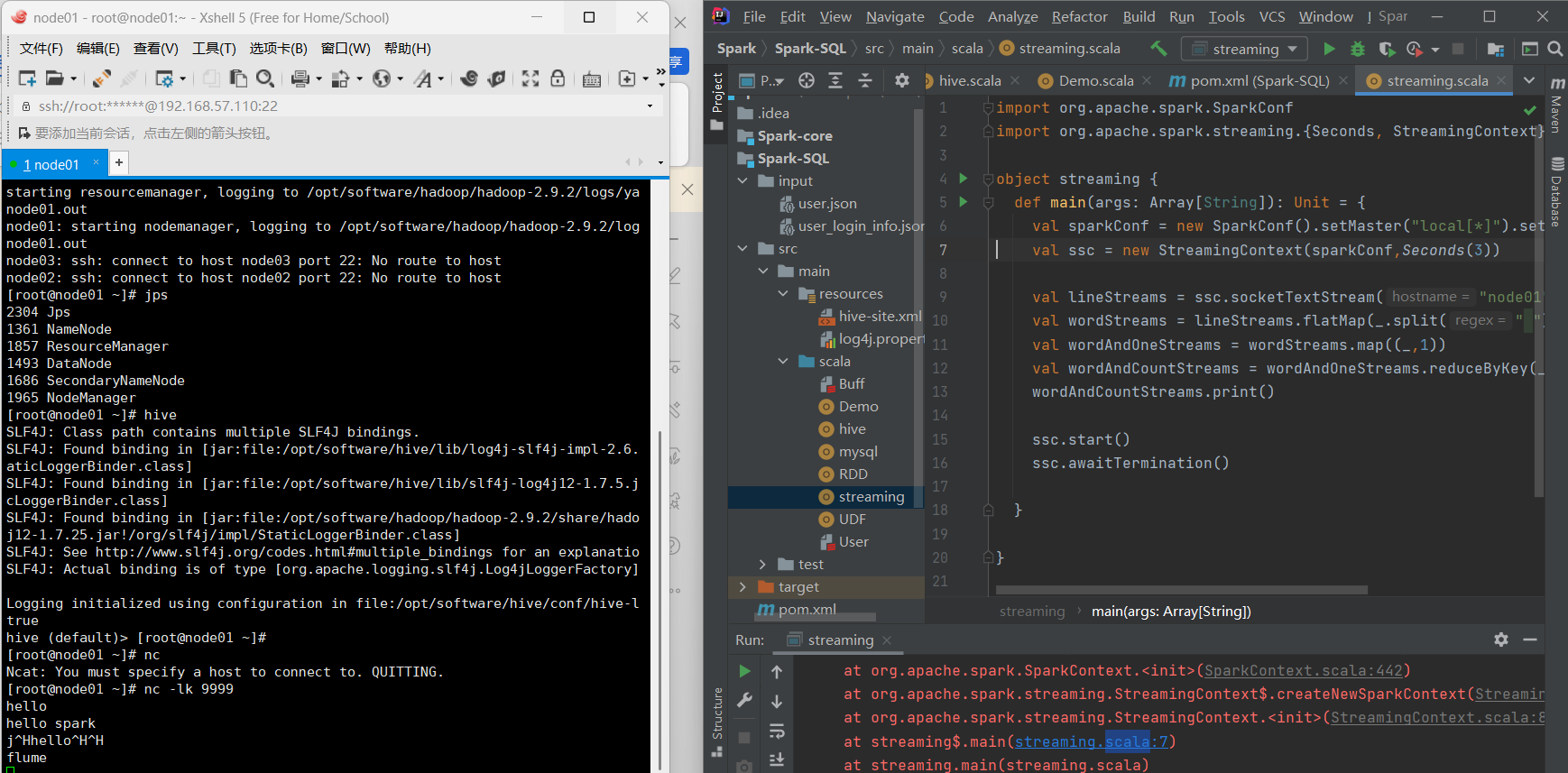
Spark Streaming实操词频统计案例:
使用ipad工具向999端口发送数据,Spark Streaming读取端口数据并统计单词出现次数。
代码配置包括设置关键对象、接收TCP套接字数据、扁平化处理、累加相同键值对、分组统计词频。
启动和运行:
启动netpad发送数据,Spark Streaming每隔三秒收集和处理数据。
代码中没有显式关闭状态,流式计算默认持续运行,确保数据处理不间断。
DStream创建DStream创建方式:
RDD队列:
通过SSC创建RDD队列,将RDD推送到队列中作为DStream处理。
自定义数据源:下节课详细讲解。
RDD队列案例:循环创建多个RDD并推送到队列中,使用Spark Streaming处理RDD队列进行词频统计。
代码包括配置对象、创建可变队列、转换RDD为DStream、累加和分组统计词频。
结果展示:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









