






ElasticSearch
简介:ElasticSearch简称ES是一个开源的分布式搜素和数据分析引擎。是使用Java开发并且是当前最流行的开源的企业级搜索引擎,能够达到近实时搜索,它专门设计用于处理大规模的文本数据和实现高性能的全文搜索。它基于 Apache Lucene 构建,专为处理海量数据而设计。它支持全文搜索、结构化查询、数据分析,并广泛应用于日志管理(如 ELK Stack)、电商搜索、实时监控等场景。

基本概念
| 术语 | 说明 |
|---|---|
| 索引(Index) | 类似数据库中的“表”,存储相关文档(如 user_index)。 |
| 文档(Document) | 索引中的基本数据单元,格式为 JSON(如一条用户信息)。 |
| 分片(Shard) | 索引被分割成的子部分,支持分布式存储和并行计算。 |
| 节点(Node) | 一个运行中的 Elasticsearch 实例,多个节点组成集群(Cluster)。 |
ELK技术栈
Elasticsearch结合Kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析,实时监控等领域:

核心组件
| 组件 | 功能 | 配图示意(文字描述) |
|---|---|---|
| Logstash、Beats | 数据采集与处理:从多种来源(如日志文件、数据库)收集数据,过滤并格式化后传输到 Elasticsearch。 | [输入] → Logstash(过滤/转换) → [输出] |
| Elasticsearch | 数据存储与检索:分布式存储处理后的数据,支持快速搜索和分析。 | [数据存储] → Elasticsearch(索引/分片) |
| Kibana | 数据可视化:通过图表、仪表盘展示 Elasticsearch 中的数据。 | Kibana ← [查询] → Elasticsearch |
总结:ELK 技术栈通过 Logstash/Beats(采集)→ Elasticsearch(存储)→ Kibana(可视化) 实现数据全生命周期管理,适用于日志分析、运维监控等场景。学习时需掌握各组件配置和协同工作原理。
Elasticsearch和lucene之间的关系
说的专业一点:Elasticsearch 基于 Apache Lucene(高性能全文检索引擎库)构建,核心的索引和搜索功能由 Lucene 实现。
说的通俗一点:Lucene 是“发动机”,专注单机性能;Elasticsearch 是“整车”,集成发动机并添加了方向盘、底盘(分布式、易用性)
总结:Elasticsearch = Lucene + 分布式 + 易用接口 + 高级功能(如聚合、近实时搜索)。
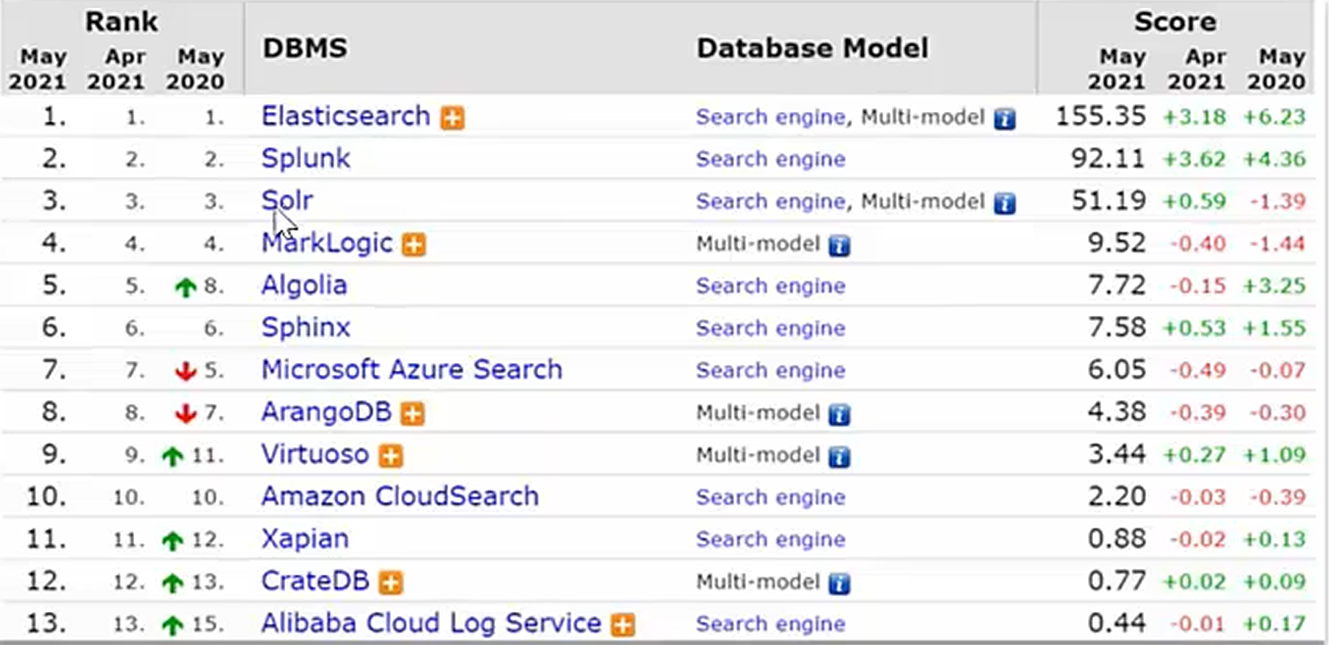
索引
两个基本概念:
文档(Document):文档是 Elasticsearch 中 最小的数据存储单元,类似于 Excel 表格中的一行数据,但更灵活。
词条(Term):词条是文档内容经过 分词处理 后的最小单位,是搜索引擎操作的基本元素。
文档与词条的关系:
| 维度 | 文档(Document) | 词条(Term) |
|---|---|---|
| 角色 | 数据存储的基本单位(“完整信息包”) | 搜索的基本单位(“信息碎片”) |
| 存储方式 | 原始 JSON 格式,保存在索引(Index)中 | 分词后存储在反向索引(Inverted Index)中 |
| 操作目标 | 用于增删改查完整数据 | 用于快速检索和匹配内容 |
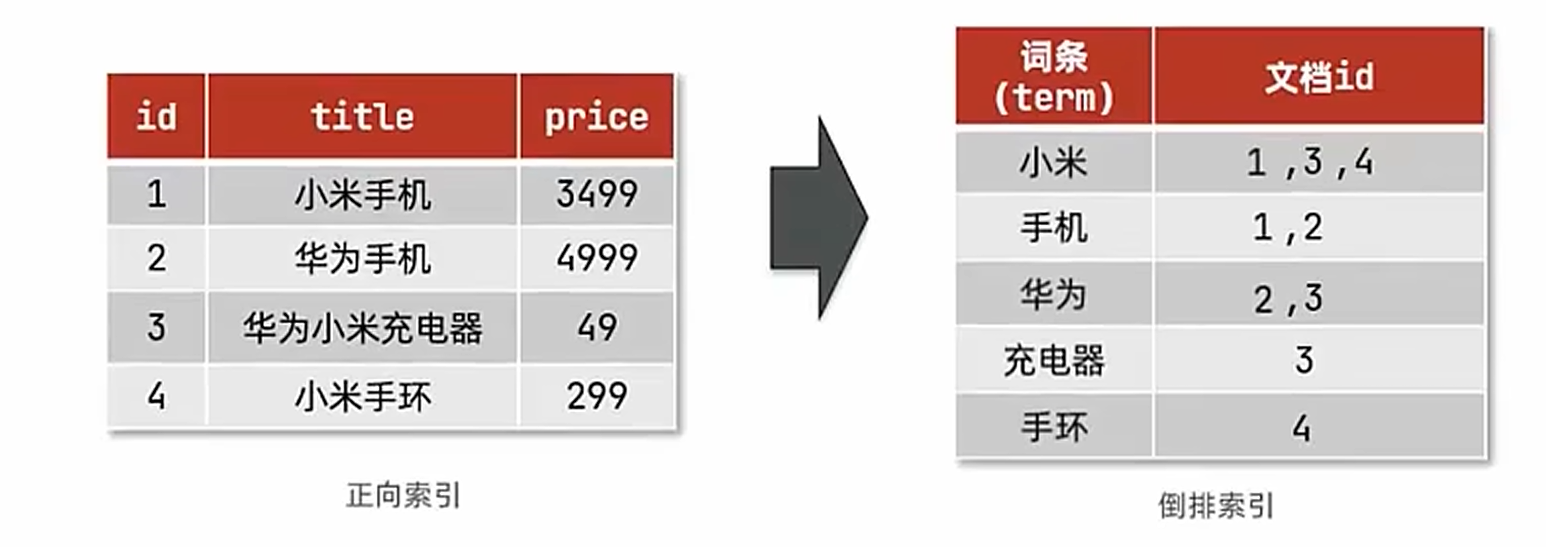
正向索引:正向索引是 以文档为中心 的索引结构,记录每个文档包含哪些关键词(类似书的目录,告诉你每本书里有什么内容)。
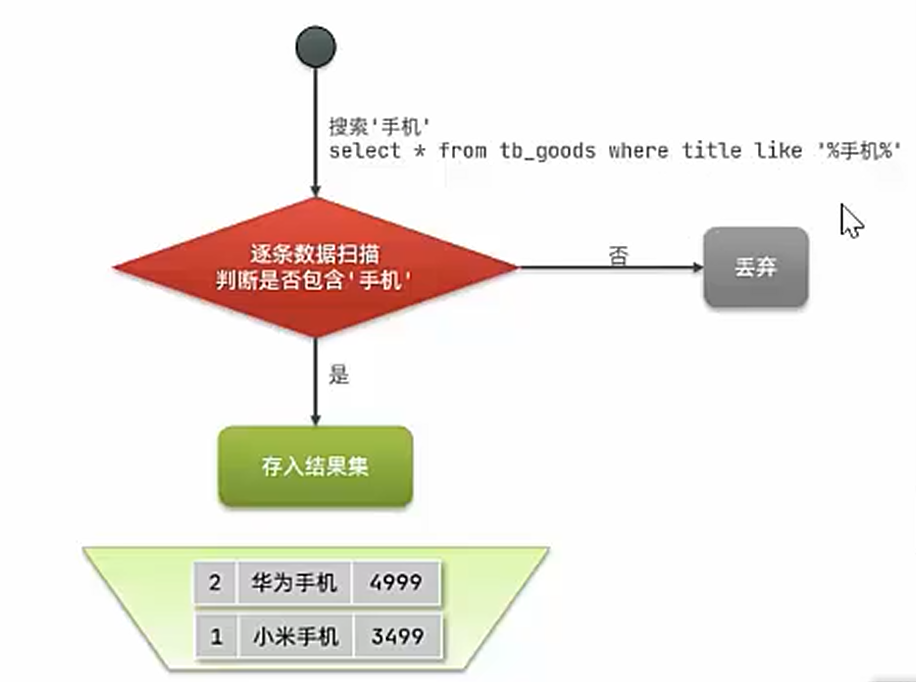
反向索引:反向索引是 以关键词为核心 的索引结构,记录每个关键词出现在哪些文档中(类似词典的索引页,告诉你哪个词在哪本书出现)。
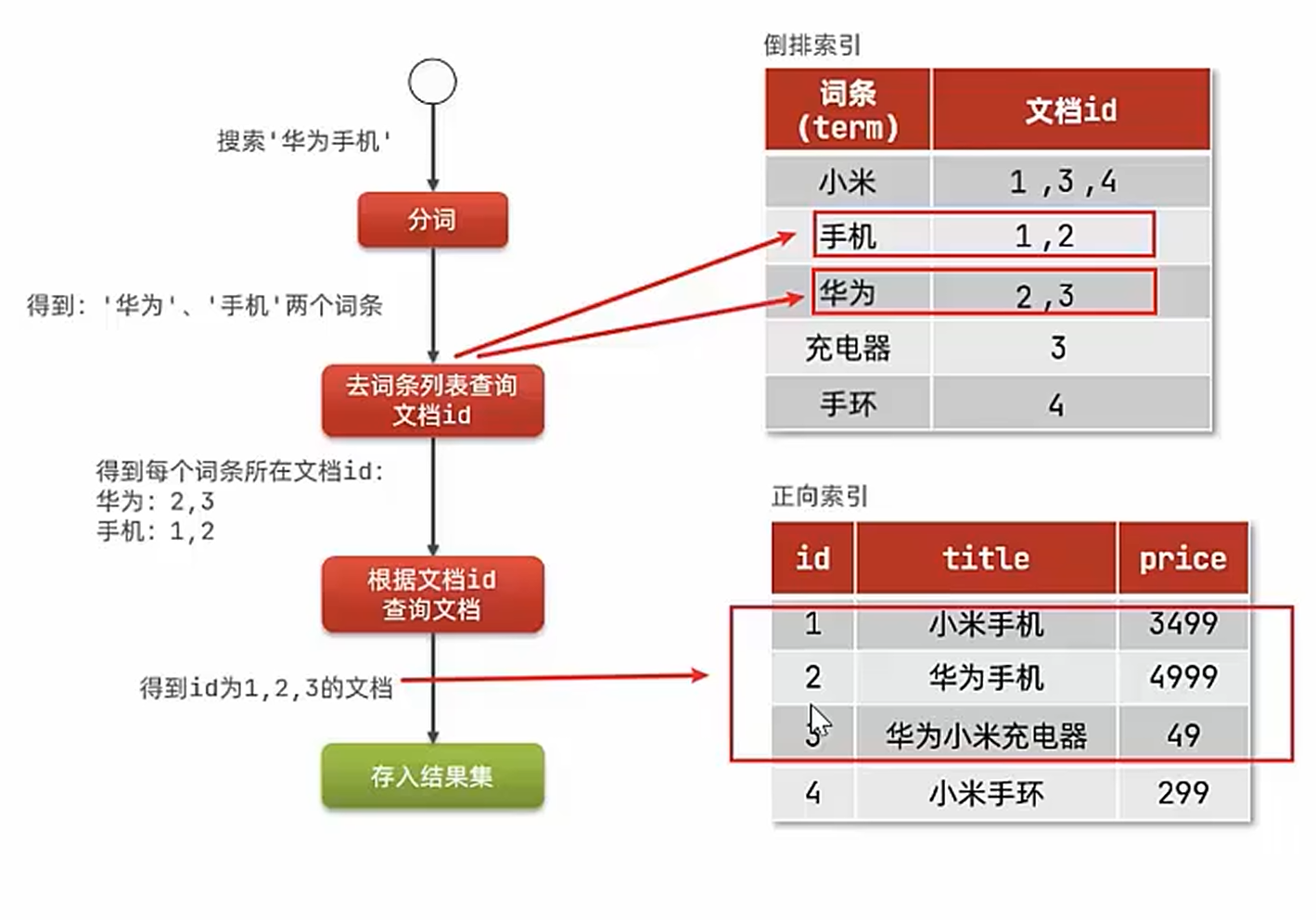
正向索引VS反向索引
| 正向索引 | 反向索引 | |
|---|---|---|
| 核心逻辑 | 文档→关键词(书→内容) | 关键词→文档(词典→书页) |
| 搜索效率 | 慢(需遍历所有文档) | 快(直接查关键词对应的文档) |
| 存储空间 | 较小 | 较大(需存储词频、位置等额外信息) |
| 典型应用 | 早期搜索引擎、小规模系统 | 现代搜索引擎(Google/Bing)、大数据系统 |
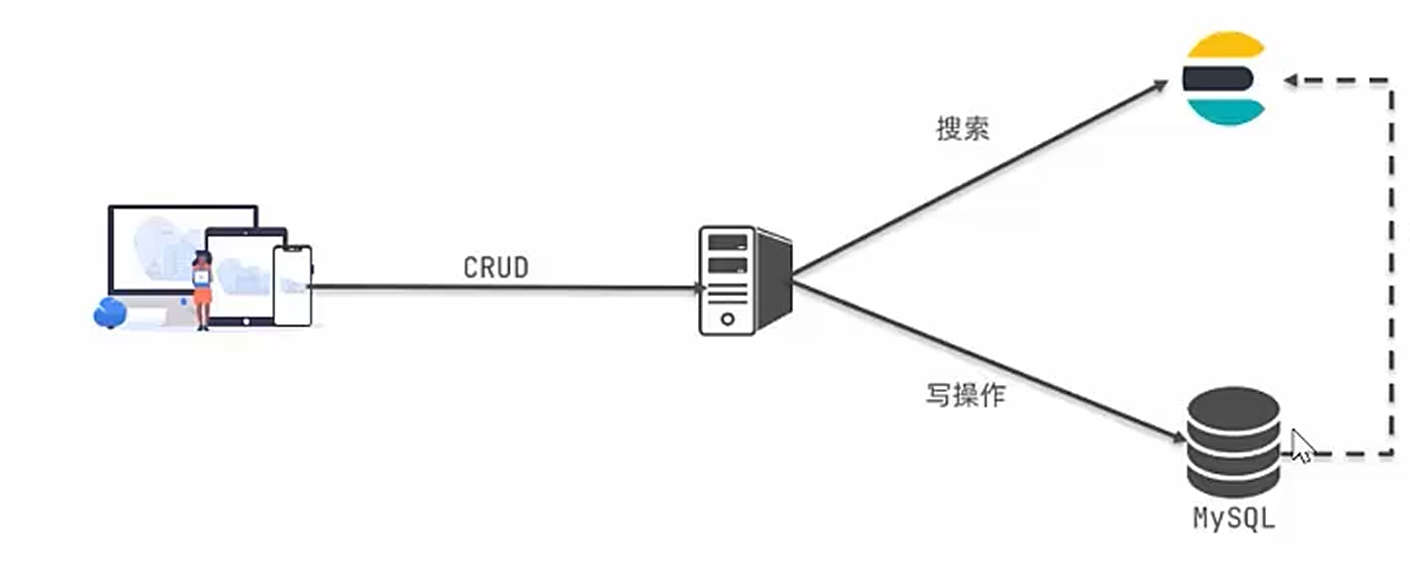
Mysql与ElasticSearch
-
ES 适合全文搜索和实时分析(如日志、商品搜索)。
-
MySQL 适合强事务和高一致性的业务(如支付、订单)。
-
实际项目中常结合使用(如 MySQL 存储业务数据,ES 提供搜索服务)。

















 942
942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









