







蓝桥杯省一
前言
这份 题单 是我前段时间关注的一个B站up分享的 我觉得非常好 能针对性的复习和提升 我最近这这几天争取把这份提单刷完 显然 对应题目 题单里都有 所以不在每一题下面附上链接了 我保证每一题都是手敲 会附上我自己的解析 也并没有大家看不懂的语法 因为我自己水平就很菜 同时没有拿到全部分的代码也会附上 因为考试的时候 我觉得就算想不到满分解 只要能拿部分分也很好了
他的个人主页 建议大家看看他的解析 非常好
学籍管理

AC代码
#include <iostream>
#include <map>
#include <string>
using namespace std;
map<string,int>mp;//表示学生名字和分数的映射
int op;//表示操作数量
int flag;//表示要进行什么操作
string name;
int score;
int main() {
cin>>op;
while(op--)//处理每种操作
{
cin>>flag;
if(flag==1)
{
cin>>name>>score;//其实用结构体会更好 表示一个学生的属性
mp[name]=score;
cout<<"OK"<<endl;
}else if(flag==2)
{
cin>>name;
if(mp.find(name)==mp.end())//没找到
{
cout<<"Not found"<<endl;
}else{
cout<<mp[name]<<endl;//找到了把成绩输出
}
}else if (flag==3)
{
cin>>name;
if(mp.find(name)==mp.end())//没找到
{
cout<<"Not found"<<endl;
}else{
mp.erase(name);
cout<<"Deleted successfully"<<endl;//找到了把对应数据删除
}
}else {
cout << mp.size() << endl;
}
}
return 0;
}
木材仓库

AC代码
solution 1(map)
其实再用map写的时候 所有都很好写 除了这句话:“如果没有刚好长度的木材,取出仓库中存在的和要求长度最接近的木材。如果有多根木材符合要求,取出比较短的一根。输出取出的木材长度。”
这是真不好实现 难点在于 当我找不到合适的木头的时候 要找到一个小于它且最靠近它的长度 如果没有 大于我们要的length 也凑合 大概就这意思
#include <iostream>
#include <algorithm>
#include <map>
using namespace std;
int main()
{
map<int,int> m;
int i,j,n,x,y;
cin >> n;
for (i=0; i<n; i++) {
cin >> x >> y;
if (x == 1) {
if (m.count(y)) cout << "Already Exist" << endl;
else m[y] = 1;
}
else {
if(m.empty()) cout << "Empty" << endl;
else if (m.count(y)) {
m.erase(y);
cout << y << endl;
}
else {
m[y] = 1; // 假装存一下该木头
auto it = m.find(y); // 指针定位
auto it2 = it;
it++;
// 几种特判
if (it2 == m.begin()) { // 没有比它短的
cout << it->first << endl;
m.erase(it);
}
else if (it == m.end()) { // 没有比它长的
cout << (--it2)->first << endl;
m.erase(it2);
}
// 长度比较
else if (y-(--it2)->first > it->first-y) {
cout << it->first << endl;
m.erase(it);
}
else {
cout << it2->first << endl;
m.erase(it2);
}
m.erase(y); // 删掉假装存的木头
}
}
}
return 0;
}
solution 2(set 推荐)
为什么这题推荐set?
因为set能完美解决我们上面用map遇到的难点
怎么用代码表示:
当我找不到合适的木头的时候 要找到一个小于它且最靠近它的长度 如果没有 大于我们要的length 也凑合
基本思路:

常用函数:

注释:由于我们定义的 it 与bf (before)都是迭代器 可以简单理解为指针 所以在输出的时候需要解引用也就是*bf来得到它指向的值
/c++
#include <bits/stdc++.h>
using namespace std;
// 定义一个集合s,用于存储整数
set<int> s;
// 主函数
int main(){
// 定义变量opp, len, n,分别表示操作类型,长度,和操作数量
int opp, len, n;
// 从标准输入读取操作数量n
cin >> n;
// 循环n次,处理每个操作
for(int i = 1; i <= n; i++){
cin >> opp >> len;
// 如果操作类型为1,表示尝试向集合中插入一个元素
if(opp == 1){
// 如果集合中已经存在len,则输出"Already Exist"
//之所以找到的判断条件是s.find(len) != s.end()
//是因为找不到的话 find函数会返回s.end()
if(s.find(len) != s.end()) cout << "Already Exist"<< endl;
// 否则,将len插入到集合中
else s.insert(len);
// 如果操作类型不为1,表示尝试从集合中移除一个元素
}else{
// 如果集合为空,则输出"Empty"
if(s.empty()) cout << "Empty" << endl;
// 否则,找到集合中第一个不小于len的元素
else{
set<int>::iterator it = s.lower_bound(len);
// 定义一个迭代器bf,用于指向it之前的元素
set<int>::iterator bf=it;
// 如果it不是集合的开始,则bf指向it前一个元素
if(it != s.begin()) bf--;
// 如果it不是末尾,因为结束的时候it是一个空指针 意味着我们必须输出bf
//并且bf离len的距离比it远了 我们就要输出*it或者将it赋值给bf
if(it != s.end() && len - *bf > *it - len)
{
// 将bf指向it,因为离len近的元素优先级更高
bf=it;
}
// 输出bf指向的元素,并将其从集合中移除 相当于把木材取走了
cout << *bf << endl;
s.erase(bf);
}
}
}
return 0;
}
小梦的AB交换
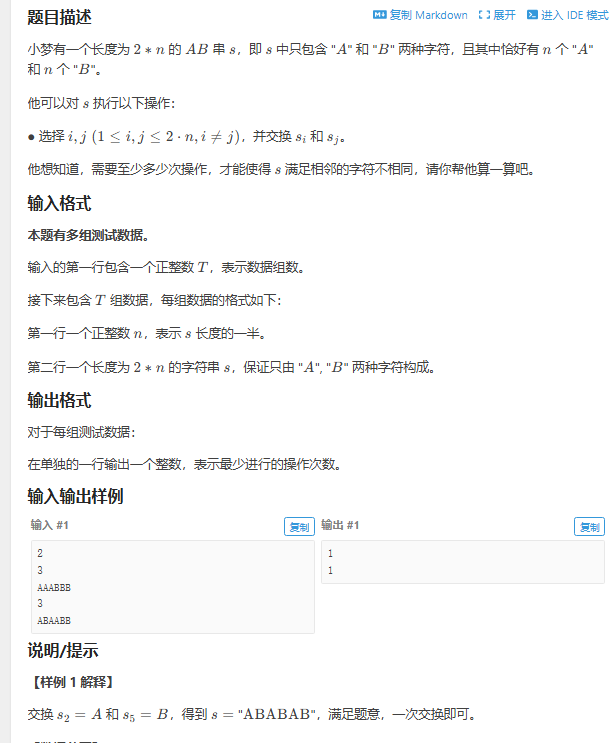
AC代码
#include <bits/stdc++.h>
using namespace std;
int T,n;
string s,a,b;
int ans;
//可以采用贪心和枚举的思想
//基本思路:对于这个AB串 如果想让他满足相邻的字符不相同 举个例子 AAABBB
//只有两种可能吧就是 ABABAB BABABA 所以我们可以枚举两种情况 分别计算交换次数取一个min
//那次数怎么算?
//不就是 我们的目标串和最终两种情况 相比较 交换 不同的位置
//并且每次交换都能解决两个不匹配的字符串 那我们 需要交换的次数=(不匹配的字符数量)/2
int calc(string &x)//返回比较之后的操作次数
{
//寻找不匹配的位置
int pos=0;
for(int i=0;i<s.size();i++)
{
if(s[i]!=x[i])
{
pos++;//两两比较 统计不匹配的位置
}
}
ans=pos/2;
return ans;
}
int main() {
cin>>T;
while (T--)
{
cin >> n >> s;
//把两种情况构造出来
for (int i = 0; i < n * 2; i++) {
if (i % 2 != 0)//奇数
{
a += 'A';
b += 'B';
} else {
a += 'B';
b += 'A';
}
}
cout << min(calc(a), calc(b)) << endl;
}
return 0;
}
Farmer John 的 N 头奶牛
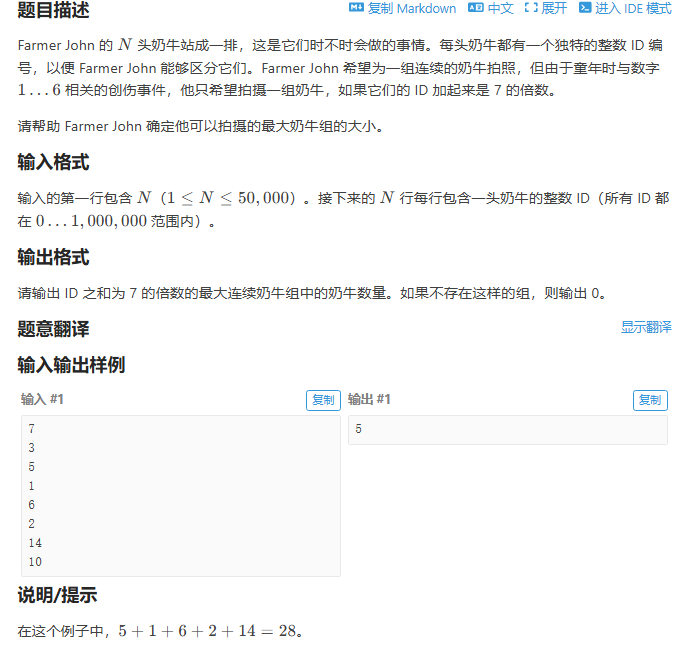
AC代码
solution 1(暴力双指针 62分)

#include <bits/stdc++.h>
using namespace std;
const int N=5e4+10;
int a[N],sum[N];
int n;
int main() {
cin>>n;
for(int i=1;i<=n;i++)
{
cin>>a[i];
}
sum[0]=0;
for(int i=1;i<=n;i++)
{
sum[i]=sum[i-1]+a[i];
}
//我们只需要在这个sum数组里面用双指针来找一下
int res=0;
for(int i=1;i<=n;i++)
{
for(int j=i;j<=n;j++)
{
if((sum[j]-sum[i-1])%7==0)
{
res=max(res,j-i+1);//不断更新找到最大区间
}
}
}
cout<<res<<endl;
return 0;
}
solution 2(同余定理+map优化 AC)
这个实际是92分的代码有两个测试点没过 原因就是当n足够大的时候 sum数组会有溢出的风险 把sum改成long long类型就好啦 为了便于大家观看这里还是放上我的源代码 同时res最后其实并不需要特判 因为如果找不到这样一个连续的区间 res就没有被更新 也就是初始值为0 为了debug我还是加上去了
#include <bits/stdc++.h>
using namespace std;
const int N=5e4+10;
int a[N], sum[N];
int n;
int main() {
cin >> n;
for(int i = 1; i <= n; i++) {
cin >> a[i];
}
// 初始化前缀和数组
sum[0] = 0;
// 计算前缀和数组
for(int i = 1; i <= n; i++) {
sum[i] = sum[i - 1] + a[i];
}
// 使用哈希表记录每个前缀和模7的结果 与第一次出现的映射
unordered_map<int, int> mod_index;
// 初始化,前缀和为0时的位置为0
mod_index[0] = 0;
// 初始化结果变量
int res = 0;
// 遍历前缀和数组,计算每个前缀和模7的结果 并根据同余定理计算最大长度
for(int i = 1; i <= n; i++) {
int mod = sum[i] % 7;
// 随着遍历,如果当前前缀和模7的结果再次出现,说明出现了7的倍数区间 我们更新最大长度
if(mod_index.find(mod) != mod_index.end()) {
res = max(res, i - mod_index[mod]);
} else {
// 一开始都不在,则加入哈希表
mod_index[mod] = i;
}
}
// 输出最大长度
if (res == 0)
{
cout << 0 << endl;
}else
{
cout << res << endl;
}
return 0;
}
K倍区间
既然把他放在奶牛这题后面 我觉得自然是有道理的 这题跟奶牛的相同点在于都是需要用到同余定理和map来优化
说是定理 其实举个例子就能明白 比如说 (10-3)%7=0 10%7-3%7=0所以如果应用到前缀和区间上则能很快地确定 我们要找的区间 这题跟上一题的区别就是 我们这题统计的不是区间长度 而是有多少个区间
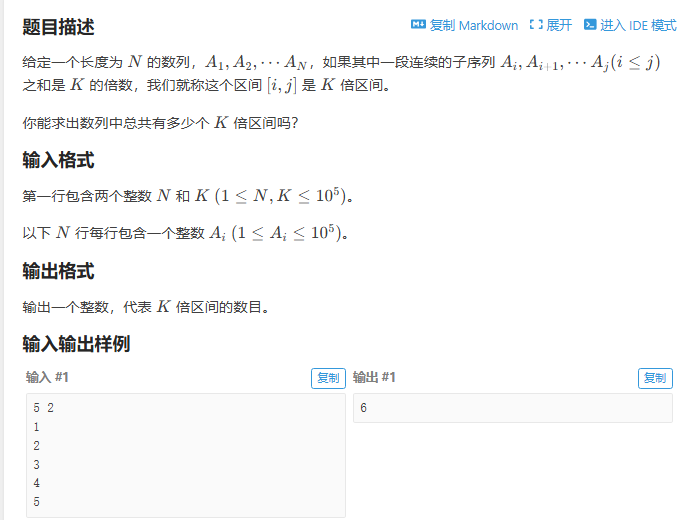
AC代码

#include <iostream>
#include <map>
#define int long long
using namespace std;
map <int, int> mp; //记录每个余数出现个数的数组
signed main()
{
int n, k, ans = 0;
cin >> n >> k;
mp[0] = 1; //初始化 0 出现的次数为 1
//1是当余数为0时,它不需要等到后面的前缀和%k再次出现0才有第一个k倍区间,它自身就是第一个k倍区间。
for(int i = 1;i <= n;i++)
{
int x;
cin >> x;
ans += (x % k); //计算前缀和
mp[ans % k]++; //前缀和模 k
ans %= k;
}
int cnt = 0;
for(int i = 0;i < k;i++) cnt += (mp[i] * (mp[i] - 1)) / 2; //根据上述公式计算答案
cout << cnt << endl;
return 0;
}

AC代码
solution 1(暴力枚举 50分)
#include <bits/stdc++.h>
using namespace std;
int n;
struct food {
int s; // 酸度
int b; // 苦度
} f[10];
int res = INT_MAX; // 使用INT_MAX表示最大值
int main() {
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> f[i].s >> f[i].b; // 读入食物的酸度和苦度
}
for (int i = 1; i <= n; i++) {
for (int j = i; j <= n; j++) { // 枚举区间[i, j]
int mult = 1; // 酸度初始化为1
int plus = 0; // 苦度初始化为0
for (int a = i; a <= j; a++) {
mult *= f[a].s; // 累乘酸度
plus += f[a].b; // 累加苦度
}
res = min(res, abs(mult - plus)); // 更新最小差值
}
}
cout << res << endl; // 输出结果
return 0;
}
solution 2(DFS AC)
#include <bits/stdc++.h>
using namespace std;
int n;
struct food {
int s; // 酸度
int b; // 苦度
} f[10];
int res = INT_MAX; // 使得min能够正常更新最小差值
void dfs(int i,int s,int b){
if(i>n)
{
//判断不加调料的情况
if(s==1&&b==0)
{
return;
}
res=min(res,abs(s-b));
return;
}
//就两种情况 加调料和不加调料
dfs(i+1,s*f[i].s,b+f[i].b);
dfs(i+1,s,b);
}
int main() {
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> f[i].s >> f[i].b; // 读入食物的酸度和苦度
}
dfs(1,1,0);//酸度得初始化为1 因为是累乘法
cout<<res;
return 0;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









