






Spark-Streaming简介
概述:用于流式数据处理,支持Kafka、Flume等多种数据输入源,可使用Spark原语运算,结果能保存到HDFS、数据库等。它以DStream(离散化流)为抽象表示,是RDD在实时场景的封装,具有易用、容错、易整合到Spark体系的特点。
架构:1.5版本前通过设置静态参数限制Receiver数据接收速率,1.5版本起引入背压机制,依据JobScheduler反馈动态调整Receiver数据接收率 ,可通过“spark.streaming.backpressure.enabled”控制是否启用。
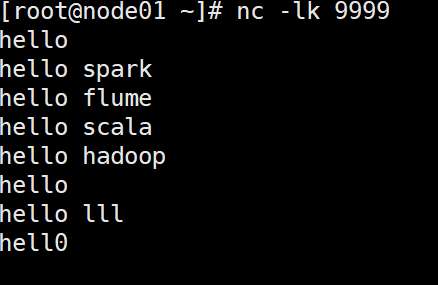
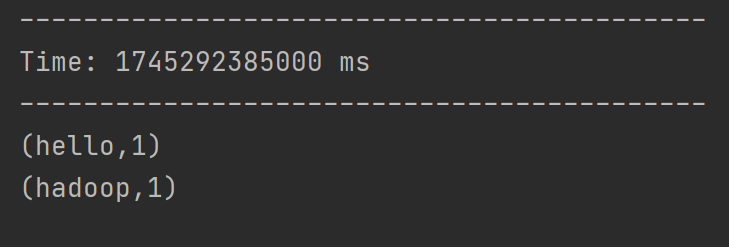
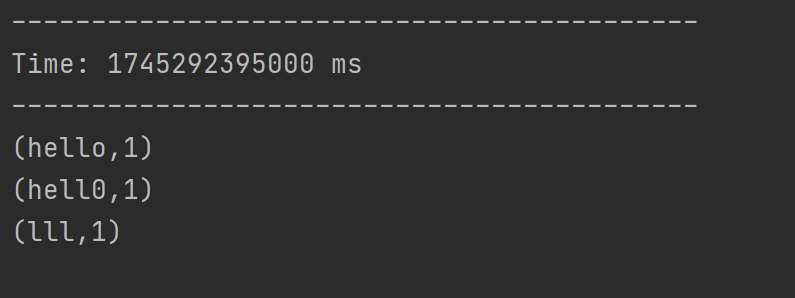
DStream实操-WordCount案例:
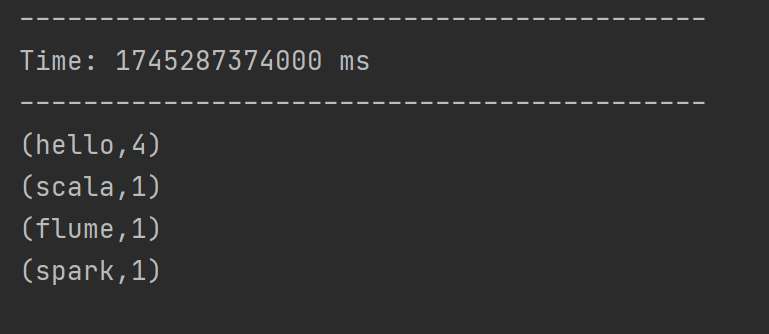
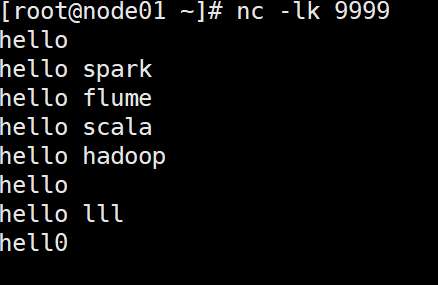
添加相关依赖后,编写代码从指定端口读取数据,经flatMap、map、reduceByKey等操作统计单词出现次数,启动netcat发送数据后即可运行。
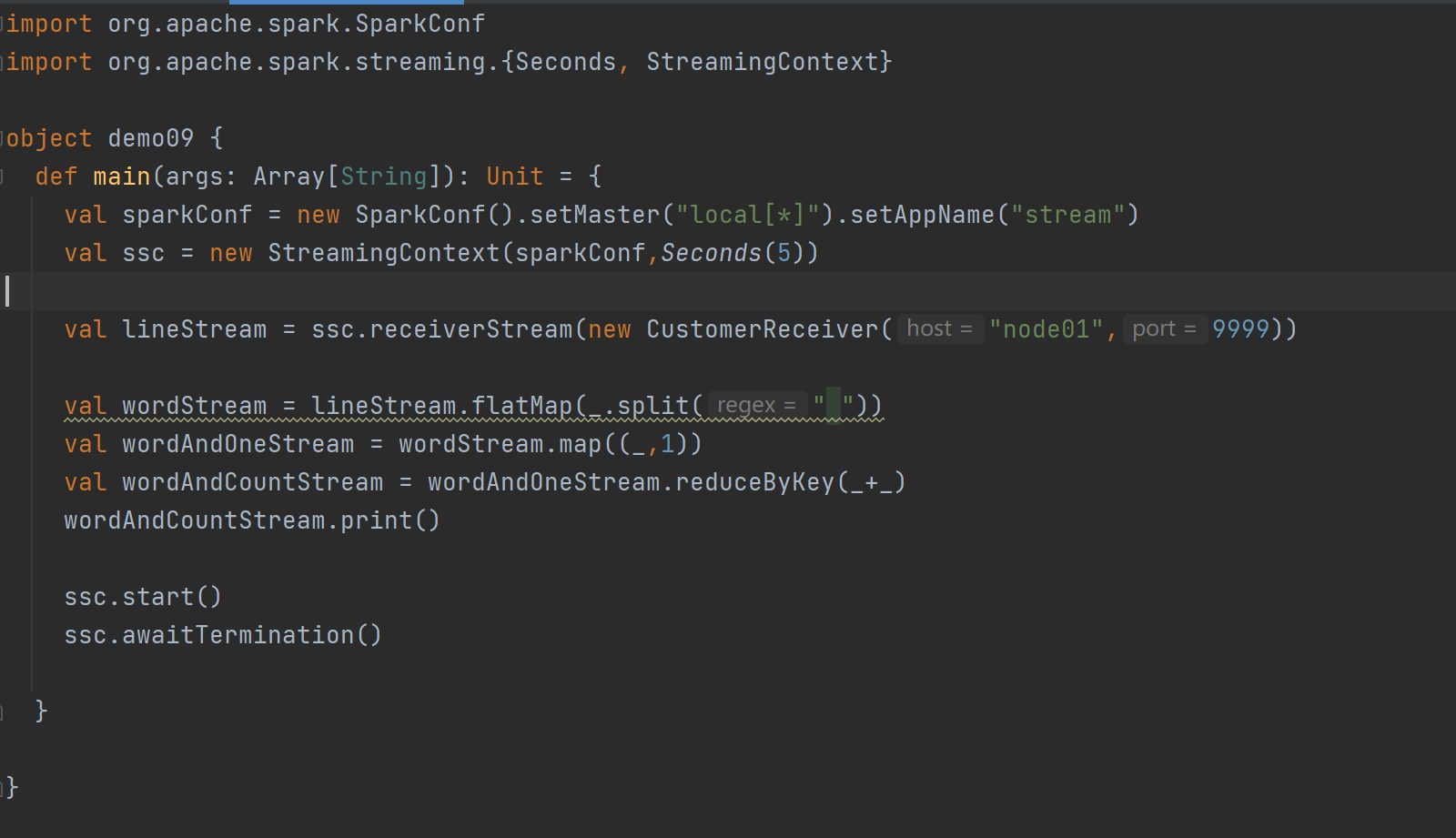
案例代码:
Spark-Streaming核心编程
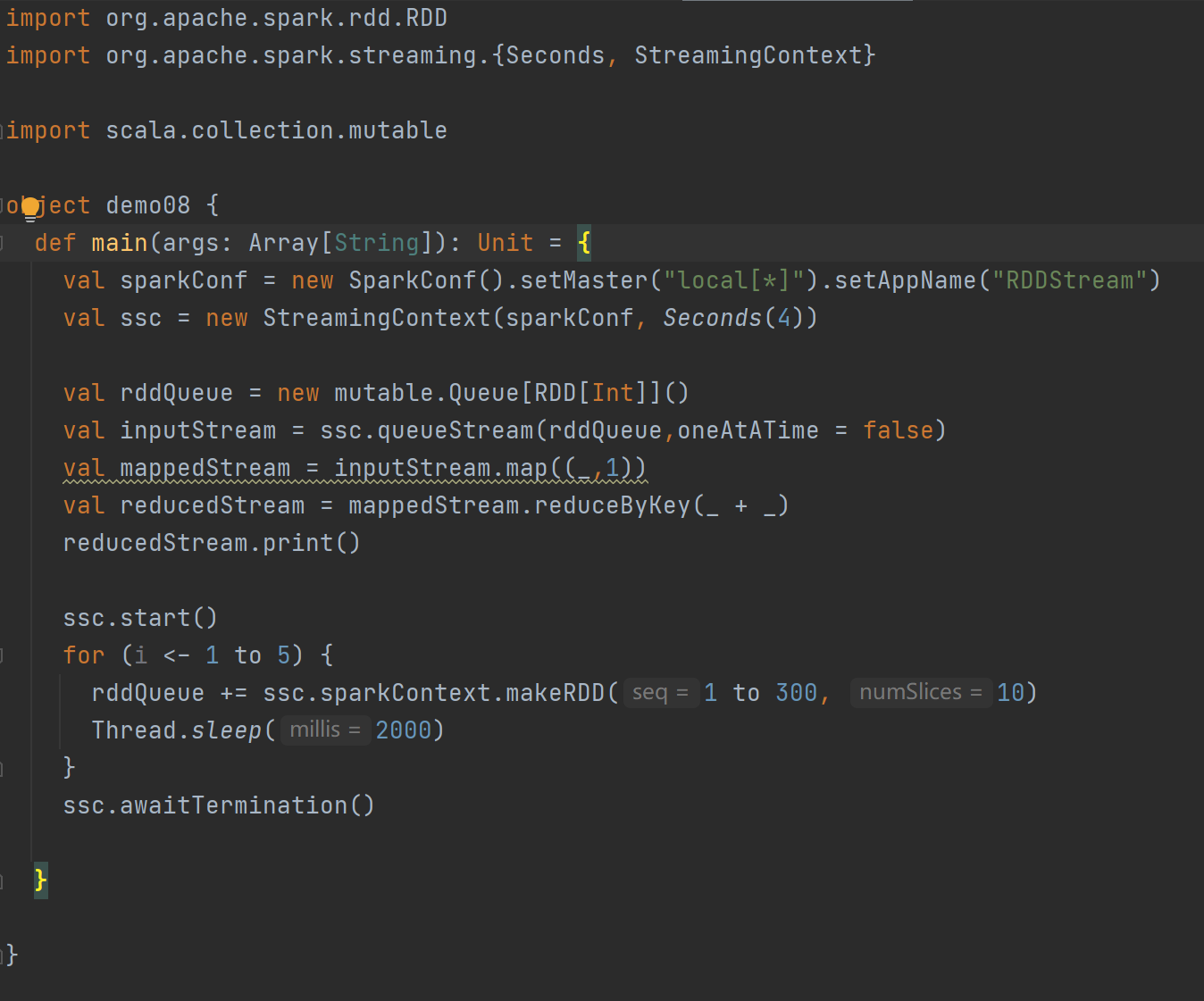
DStream创建 - RDD队列:
使用ssc.queueStream(queueOfRDDs)创建DStream,计算wordcount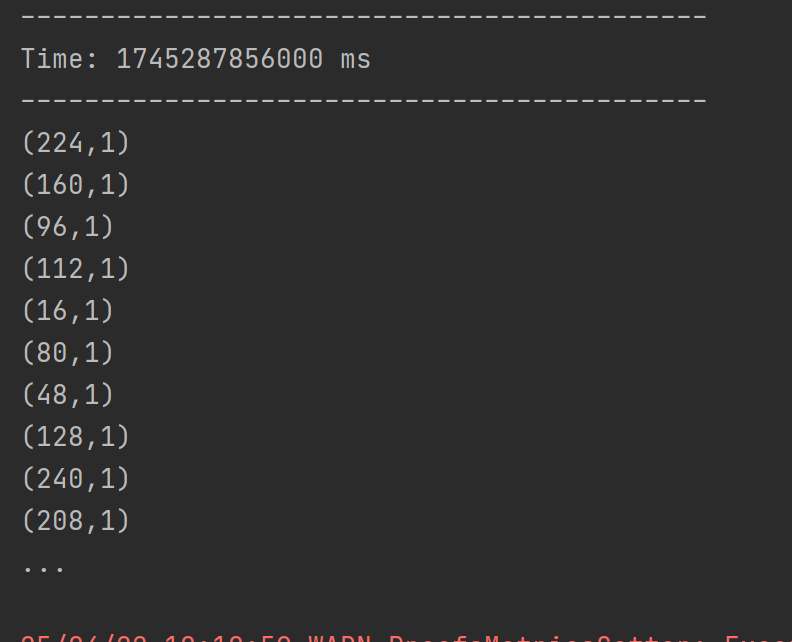
案例代码
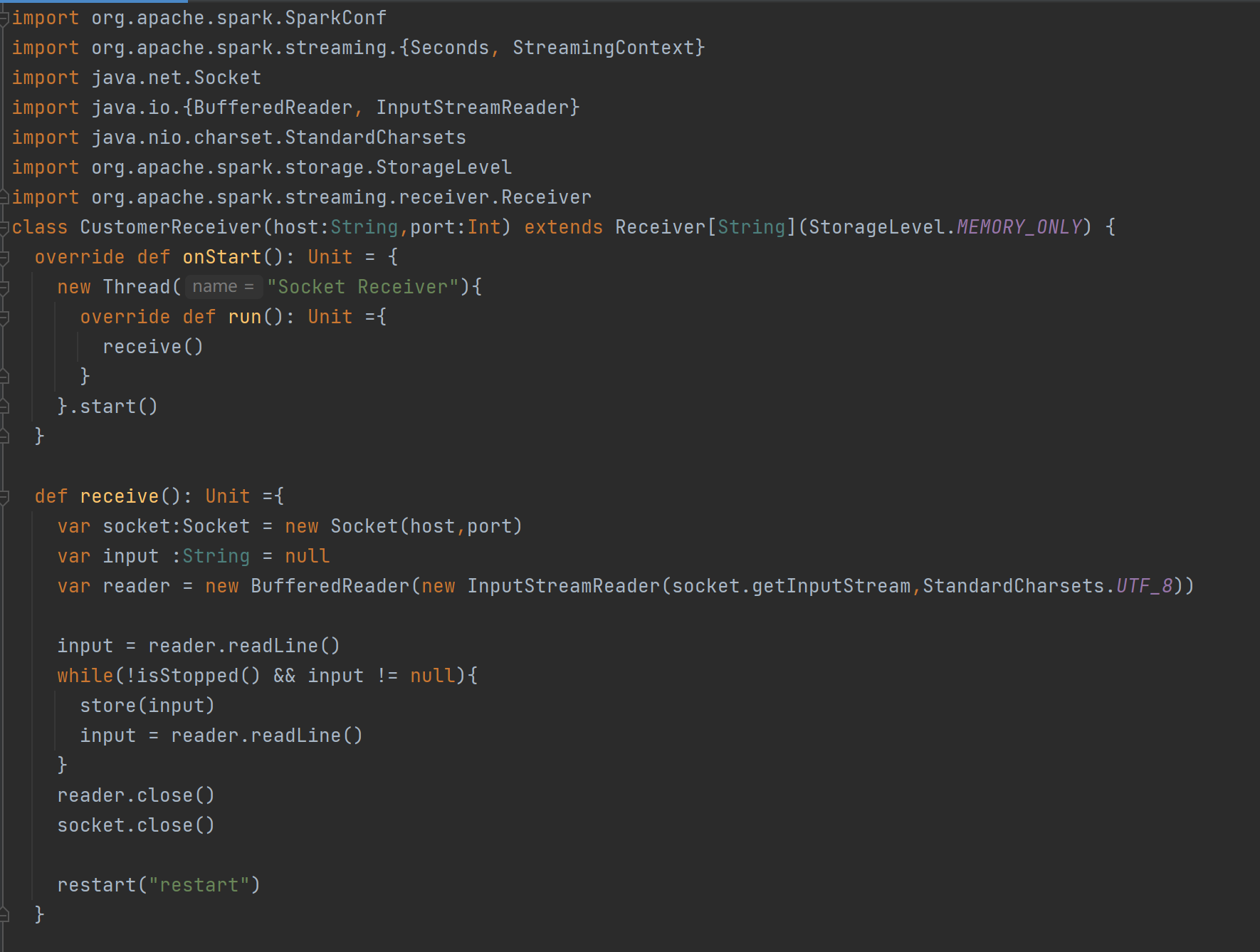
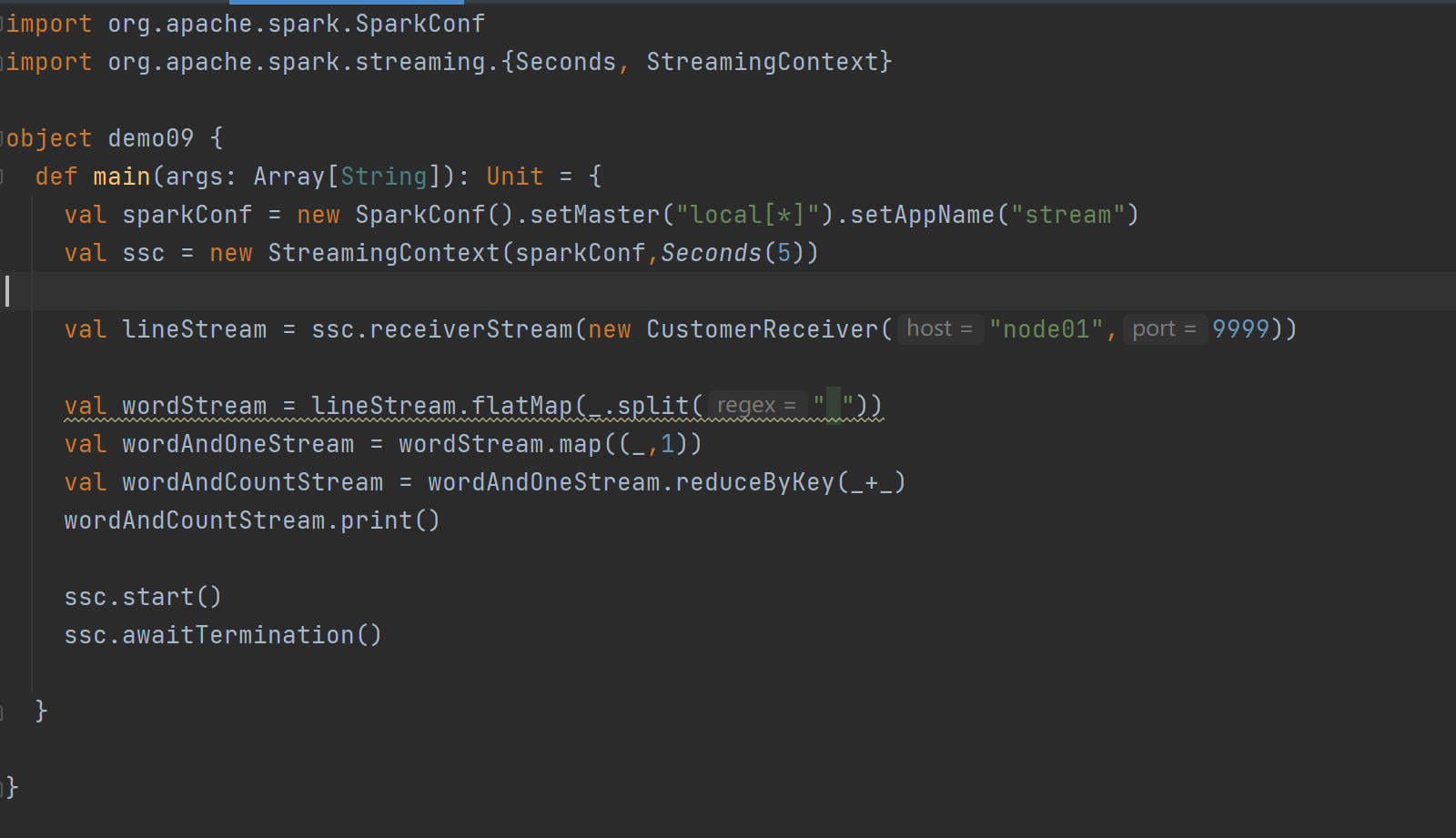
DStream创建 - 自定义数据源:
自定义数据源需继承Receiver并实现onStart、onStop方法。案例中自定义数据源监控指定端口获取内容,在使用时通过ssc.receiverStream引入,进而进行数据处理。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









