







一. 为什么需要异常处理机制
在理想的世界里,用户输入数据的格式永远设置正确的,选择打开的文件格式也一定存在,代码永远不会出现Bug。可事实并非如此。
人们往往在遇到错误时感到不爽。如果是由于程序的错误或者是一些外部环境的影响,导致用户在运行程序期间做的所有工作统统消失,那么,这个用户就有可能再也不用这个程序了。为了避免此类事情发生,至少要做到以下几点
- 向用户通知错误
- 保存所有工作
- 允许用户妥善的退出程序
对于异常情况,例如,可能造成程序崩溃的糟糕的输入数据,Java使用了一种称为异常处理的错误捕获机制
异常处理机制是现代编程语言中至关重要的组成部分,其核心目的是将程序从不可预知的错误中恢复或优雅地终止,同时提升代码的健壮性、可维护性和可读性。
二.处理错误
Java中出现异常(在Java语言中,将程序执行中发生的不正常情况称为为异常)可能有以下几种情况:
- 错误(Error):JVM虚拟机无法解决的严重问题,他描述的了Java运行时系统的内部错误和资源耗尽问题。一般遇到这种不需要处理,而且这种情况很少出现,如果出现了这样的内部错误,除了通知用户,并尽力妥善的终止程序之外,你几乎无能为力。
- 异常:这个可能是包含错误信息的文件导致的,或者是网络连接问题导致的,等等,这类问题是你需要处理的
- 还有最后一种,使用了非法的数组索引,使用了一个还没有指定对象的对象引用......关于这类问题有相应的处理机制,但希望你不要使用,你应该考虑的是如何修正代码,而不是以这种方式来处理代码
我们需要做的事情就是,由于出现了错误而导致一个操作无法完成,这时程序应该返回到一种安全状态,并允许用户执行其他的命令,或者允许用户保存所有的工作,并妥善的终止程序
首先来说一下所面临的困难
检测(或者甚至引发)错误条件的代码通常与那些能够让数据回滚到安全状态或者能够保存用户工作并妥善退出程序的代码相距很远。异常处理的任务就是将控制权从产生错误的地方转移到能够处理这种情况的一个错误处理器。为了在程序中处理异常情况,必须考虑程序中可能出现的错误和问题。
需要考虑哪些问题
- 用户输入错误:例如,输入类型不匹配(程序需要整数,而用户输入字符串),输入格式错误(例如输入日期是不符合格式要求),输入超出范围(例如输入的年龄为负数)......
- 设备错误:硬件并不总是让他做什么他就做什么。打印机可能被关掉了。网页可能临时不能浏览。设备经常在完成任务的过程中出问题。例如,打印机在打印的过程中没纸了
- 物理限制。磁盘已满,用尽了所有的可用内存
- 代码错误。方法有可能没有没有正确的完成工作。例如,方法可能返回一个错误的答案,或者错误的使用了其他的代码,或者让一个空栈实现弹出操作......
遇到这种问题,要如何进行处理,传统的方法是,返回一个特殊的错误码,由调用方法分析。例如,对于从文件中读取信息的方法,通常返回一个特殊值-1(而不是一个标准字符)表示文件结束。这对于很多异常处理都是很高效的。还有一个表示错误状态的常用返回值是null引用。
可这种处理方式并不是很好的,因为它有时无法区分合法数据和非法数据,例如,在返回整型的方法中,返回-1并不合理,因为你并不知道这里它代表是合法还是非法
这个时候就可以引出异常处理机制了。
Java允许每个方法有一个候选的退出路径,如果这个方法不能以正常的方式完成它的任务,就会选择这个退出路径。在这种情况下,方法不会返回一个值,而是抛出(throw)一个封装了错误信息的对象。需要注意的是,这个方法会立刻退出,并不返回任何值或任意值。此外,也不会调用这个方法的代码继续执行,取而代之的是,异常处理机制开始搜索一个能够处理这种异常状况的异常处理器
下面就开始异常的讲解了
异常分类
前文已经简单说明了异常,这里进行进一步细化
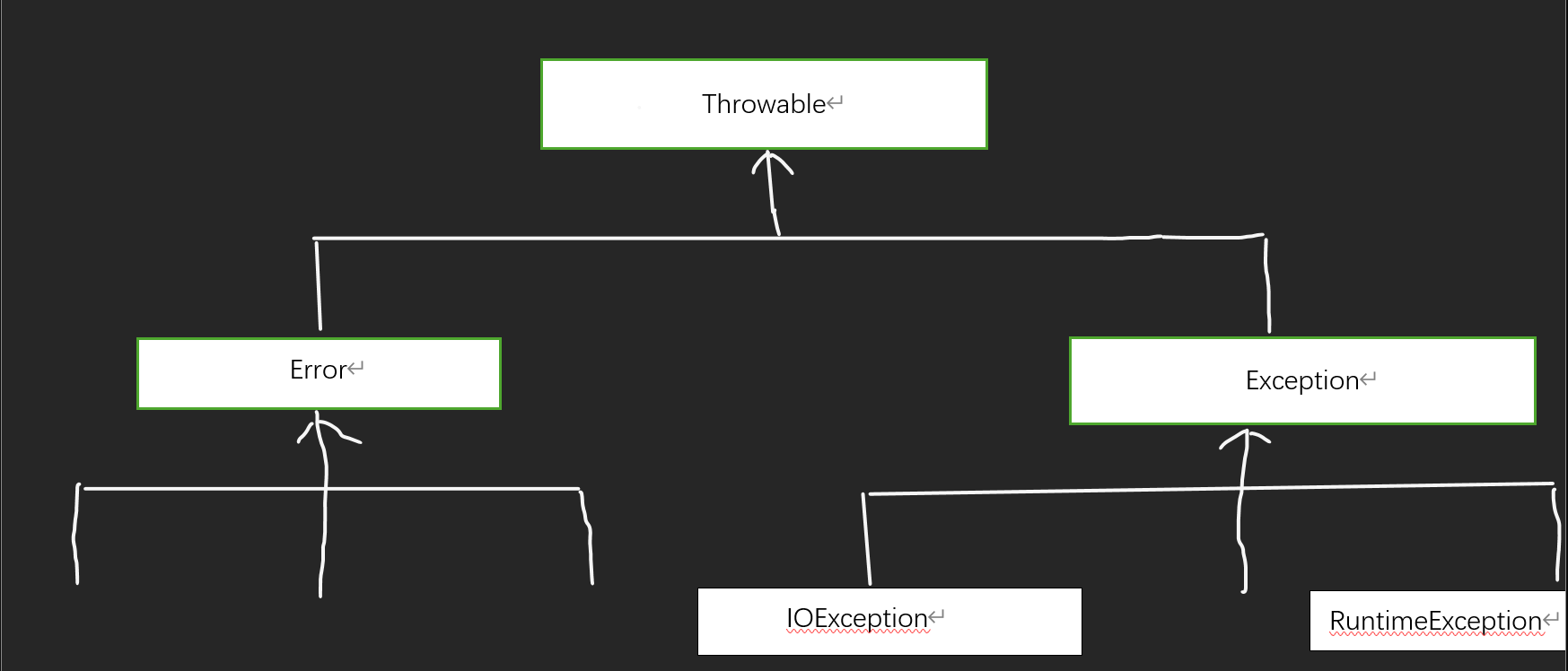
在Java程序设计语言中,异常对象对象都是派生于Throwable类的一个类的实例。
看这个Java异常层次结构的简化示意图可以看出,Throwable下一层有两个分支Error,Exception
在这里我们需要知道的是,对于Error类,我们很难进行处理,所以我们重点关注的应该是Exception层次结构。这个结构又分为两个分支:一个分支派生于RuntimeException;另一个分支包括其他异常,不继承这个类。一般规则是:由编程错误导致的异常属于RuntimeException(例如:错误的强制类型转换;越界的数组访问;访问null指针);如果程序本身没有问题,但由于I/O错误之类的问题导致的异常属于其他异常(例如:试图越过文件末尾继续数据;试图打开一个不存在的文件;试图根据给定的字符串查找Class对象,而这个字符串表示的类并不存在)
有这么一句话"如果出现RuntimeException异常,那么一定是你的问题",所以,你一定要要通过更加严密的逻辑实现代码来避免出现这种问题。例如,可以通过检测数组索引是否越界避免ArrayIndexOutOfBoundsException异常;如果你在使用变量之前先检查它是否为null,NullPointerException异常就不会发生。
那么关于不存在的文件该如何处理呢?如果先检查它是否存在,再进行操作不就行了吗?不,对于这个问题的处理并没有表面上那么简单。可能就是说你在前一刻检查他还存在,在下一刻你再去进行操作的时候他就可能有不存在了。Why?Java中有多线程,并发线程,具体来说,当多个线程(或进程)对共享资源(如文件,内存数据)进行操作时,由于线程调度的不确定性,一个线程在检查资源状态后、实际执行操作前的瞬间,另一个线程可能修改了资源状态,导致前一线程的假设失效,从而引发错误。因此,"是否存在"取决于环境,而不知是取决于你的代码
Java语法规范将派生于Error类或RuntimeException类的所有异常称为非检查型(unchecked)异常,所有其他异常称为检查型(checked)异常。编译器将检查你是否为所有的检查型异常提供了异常处理器。
检查型异常与非检查型异常对比
检查型异常各阶段行为
- 编译阶段----编译器强制检查,否则代码无法编译,方法若抛出检查型异常,必须通过try-catch或throws处理
- 运行阶段----错误触发:通常是可恢复的(如文件未找到),须引导用户重试或修复
传播方式:若未处理,异常会沿着调用栈向上传播,直到被捕或或程序终止
非检查型异常
- 编译阶段----无需声明或捕获,代码可直接编译通过
- 运行阶段----错误触发:通常是代码逻辑错误,程序可能直接崩溃
传播方式:直接抛出并终止当前线程,除非显示捕获
声明检查型异常
如果遇到了无法处理的情况,Java可以抛出一个异常。这个道理很简单:方法不仅需要告诉编译器需要返回什么值,还要告诉编译器有可能发生的错误。在 Java 中,声明检查性异常是一种在编译期被编译器强制检查的异常类型,其核心目的是要求开发者必须显式处理可能出现的异常情况,以确保代码的健壮性和错误恢复能力。
例如,一段读取文件的代码知道读取的文件有可能不存在,或者可能为空,因此,试图处理文件信息的代码就需要通知编译器可能会抛出IOException类的异常。
public FileInputStream(String name) throws FileNotFoundException就如以上代码所示,需要抛出异常,抛出是在方法首部的进行了修改,以反映这里可能会抛出的检查型异常。
这声明表示这构造器根据给定的String参数生成一个FileInputStream对象,但也有可能出现错误而抛出一个FileNotFoundException异常。若抛出异常,构造器将不会初始化一个新的FileInputStream对象,而是抛出一个FileNotFoundException类对象,这时在运行时系统就会开始搜索知道如何处理FileNotFoundException对象的异常处理器
那么,为什么需要检查性异常?
-
强制错误处理:确保开发者提前考虑潜在问题(如文件丢失、网络中断)。
-
明确责任链:通过throws声明将异常逐层传递,直到有合适的处理逻辑。这里需要注意,抛出只是将异常抛出去了,并没有将异常真正处理掉。它是指当程序遇到无法继续执行的错误时,主动生成一个异常对象并向上层调用者传递该异常的行为。
-
提高代码可靠性:减少未处理异常导致程序崩溃的风险。
在编写你自己的方法时,不必声明你的方法可能抛出的所有throwable对象。关于什么时候需要在所写的方法中用throws子句声明异常,以及要用throws子句声明哪些异常?
需要在遇到以下四种情况时抛出异常
- 调用了一个抛出检查型异常的方法
当你的方法内部调用了另一个方法,且该方法声明了throws检查型异常时,你必须处理该异常(通过try-catch)或在当前方法中继续用throws声明
// 被调用的方法声明了 IOException public void externalMethod() throws IOException { // 可能抛出 IOException } // 这个方法调用 externalMethod() public void myMethod() throws IOException { externalMethod(); // 必须处理或声明抛出 IOException }关键点:
如果选择不捕获异常,则必须声明throws。
如果调用多个可能抛出不同检查型异常的方法,需在throws中列出所有可能抛出的异常类型,每个异常类之间用逗号隔开
- 检查到一个错误,并且利用throw语句抛出一个检查型异常
当你的方法内部检测到错误(如参数不合法、资源不可用),并主动通过throw抛出一个检查型异常时,必须声明该异常。
public void validate(int value) throws IllegalArgumentException { if (value < 0) { // 抛出一个非检查型异常(RuntimeException 的子类),无需声明 throws throw new IllegalArgumentException("值不能为负数"); } } public void readFile(String path) throws IOException { if (path == null) { // 如果抛出的是检查型异常(如 IOException),必须声明 throws throw new IOException("路径不能为空"); } }关键点:
如果抛出的是检查型异常(如
IOException),必须声明throws。如果抛出的是非检查型异常(如
IllegalArgumentException),无需声明throws
- 程序出现错误
当程序因逻辑错误(如空指针、数组越界)导致抛出非检查型异常(Unchecked Exception) 时,不需要声明throws。
public void divide(int a, int b) { // 如果 b=0,会抛出 ArithmeticException(非检查型异常) int result = a / b; }关键点:
非检查型异常(RuntimeException 或 Error 的子类) 无需声明。
这类异常通常由代码逻辑错误引起,应通过修复代码避免,而不是声明throws
- Java虚拟机或运行时库出现内部错误
当发生 JVM 内部错误(如
OutOfMemoryError、StackOverflowError)时,这些是Error 的子类,属于 非检查型异常,无需声明throwspublic void triggerOOM() { // 可能抛出 OutOfMemoryError(非检查型异常) List<Object> list = new ArrayList<>(); while (true) { list.add(new Object()); } }关键点:
Error及其子类表示严重问题,通常无法恢复,也不建议捕获或声明
如果出现前两种情况,则必须告诉使用这个方法的程序员有可能抛出异常。因为任何一个抛出异常的方法都有可能是一个死亡陷阱。如果没有处理器捕获这个异常,当前的执行线程就会终止。
前面已经提到过,我们应该更加注意的是检查型异常,而并非将精力花费在非检查型异常,因为他要么是我们无法处理的,要么就是我们可以通过修改代码而可以避免的。对于检查型异常,一个方法必须声明所有可能抛出的检查型异常,如果你没有声明所有可能发生的检查性异常,编译器就会发出一个错误信息。
警告:如果在子类中覆盖了超类的一个方法,子类方法中声明的检查型异常不能比超类方法中声明的异常更通用(子类方法可以抛出更特定的异常,或者根本不抛出任何异常)。还需要注意的是,如果超类方法没有抛出非检查型异常,子类也不能抛出任何非检查型异常。
异常处理的规则与多态性
在 Java 中,异常的类型体系基于继承关系,而异常处理的规则与多态性(Polymorphism)密切相关
当一个方法声明可能抛出某个异常类型时,它实际抛出的异常可以是:
-
该异常类的实例。
-
该异常类的任意子类实例(得益于多态性)
为什么允许抛出子类异常?
Java 的多态性允许子类对象被当作父类类型使用。因此,如果方法声明抛出父类异常,实际抛出的可以是父类或其子类的实例。
public void readFile() throws IOException { // 父类异常
if (fileNotFound) {
throw new FileNotFoundException(); // 子类异常
}
if (permissionDenied) {
throw new AccessDeniedException(); // 另一个子类异常
}
}
//FileNotFoundException 和 AccessDeniedException 都是 IOException 的子类。
//调用者只需处理 IOException,即可覆盖所有可能的子类异常
这样做的好处就在于 便于未来的拓展,更加灵活(无需关心子类的具体抛出类型),简化异常处理。
接下来就开始进入真正环节了,准备好了吗
如何抛出异常
在 Java 中,抛出异常是处理程序运行期间错误或异常情况的核心机制。正确抛出异常可以帮助程序优雅地处理错误,避免崩溃,并提供清晰的调试信息
throw(主动抛出异常)关键字
用途:
在方法内部显式抛出一个异常对象,用于表示程序运行中遇到的错误或异常情况
基本语法
//使用 throw 主动抛出异常
throw new ExceptionType("错误信息");-
ExceptionType:必须是 Throwable或其子类(如Exception,RuntimeException,自定义异常等)。 -
错误信息:可选,用于描述异常原因。
例如
public void divide(int a, int b) {
if (b == 0) {
throw new ArithmeticException("除数不能为零");
}
System.out.println(a / b);
}使用场景
1.参数合法性检查
方法接收非法参数时,抛出异常(如
IllegalArgumentException)public void setAge(int age) { if (age < 0) { throw new IllegalArgumentException("年龄不能为负数"); } this.age = age; }
2.业务逻辑错误
当程序无法按预期执行时,主动抛出异常
public void withdraw(double amount) { if (amount > balance) { throw new InsufficientFundsException("余额不足"); } balance -= amount; }
3.封装底层异常
捕获底层异常后,抛出更明确的业务异常
public void processFile() { try { readFile(); } catch (IOException e) { throw new DataProcessingException("文件处理失败", e); } }
关键点
-
throw在方法内部使用,每次只能抛出一个异常对象。 -
如果抛出的是 检查型异常,必须通过
try-catch处理或在方法签名中用throws声明。 -
如果抛出的是 非检查型异常(如
RuntimeException),无需声明
throws(声明方法可能抛出的异常)关键字
用途
在方法签名中声明该方法可能抛出的异常类型,通知调用者需要处理这些异常
语法
public void methodName() throws ExceptionType1, ExceptionType2 {
...
}-
可以声明多个异常类型,用逗号分隔。
-
声明的异常类型必须是Throwable的子类
使用场景
1.调用抛出检查型异常的方法
如果方法内部调用了另一个声明了throws的方法,且未捕获异常,则当前方法必须声明
Throwspublic void readConfigFile() throws IOException { FileReader reader = new FileReader("c.txt"); // FileReader 构造函数声明了 throws IOException ... }
2.主动抛出检查型异常
如果方法内部通过throw抛出检查型异常,且未捕获,则必须声明throws
String readDate(Scanner in)throws EOFException { ... while(...) { if(!in.hasNext()) //EOF encountered { if(n <len) throw new EOFException(); } ... } return s; }
throw的作用:
- 是实际触发异常的动作,表示“这里有一个错误,我要抛出一个异常对象”。
- 在代码逻辑中,当检测到错误条件时(如提前遇到 EOF),使用
throw生成异常对象并终止当前流程。
throws的作用:
- 是方法对外的承诺,表示“调用我时,你需要注意我可能会抛出这些异常”。
在方法签名中声明
throws EOFException,告诉调用者:“调用readDate()时,必须处理EOFException,否则编译失败”
创建异常类
你的代码可能会遇到任何标准异常类都无法描述清楚的问题。在这种情况下,创建自己的异常类就成了一种准顺理成章的事情了。我们要做的只是定义一个派生于Exception类,或者派生于Exception的某个子类,如IOException。习惯做法是,自定义的这个类用该包含两个构造器,一个是默认构造器,另一个是包含详细描述信息的构造器(超类Throwable的toString方法会返回一个返回值,其中包含这个详细信息)
class FileFormat extends IOException
{
public FileFormatException(){
public FileformatException(String gripe)
{
super(gride);
}
}
String readDate(Scanner in) throws FileformatException
{
...
while(...)
{
if(ch == -1)
{
if(n < len)
throw new FileformatException();
}
...
}
return s;
}大多数情况下优先用 非检查型异常(继承 RuntimeException),避免代码中到处写 try-catch。
只有调用方必须处理的错误才用检查型异常(如网络超时)
3.传递异常给上层调用者
在分层架构中,将异常逐层传递到合适的处理层
前面提到过一点,抛出异常只是将异常抛出并没有真正将异常给处理掉,异常处理需要捕获
为什么要抛出处理,因为处理不掉,所以抛出。简单来说就是我干不了,我甩锅。
举一个例子
点外卖的异常传递
假设你通过外卖平台点餐,系统分为三层:
你(用户层):下单、查看结果。
外卖平台(业务层):处理订单逻辑。
餐厅(数据层):准备餐品。
异常传递流程
1.餐厅发现错误:
比如「菜品卖光了」,餐厅直接告诉外卖平台:“我做不了这个菜”(抛出异常)。
2.外卖平台处理:
它可以选择:
(1)自己解决:换一家餐厅(捕获异常,内部处理)。
(2)告诉你:直接告诉你“菜卖光了”(继续抛出异常)。
3.你最终处理:
如果是外卖平台直接告诉你异常,你决定:“换一个菜”或“取消订单”(最终处理异常)
关键思想
底层(餐厅):只负责报告问题(抛出异常),不决定如何解决。
中层(平台):可以选择处理异常,或继续向上传递。
上层(你):最终决定如何处理异常(比如提示用户)。
这样设计的好处
(1)每层专注自己的事
餐厅只管做菜,不操心用户怎么处理问题。
你只管决定是否换菜,不用关心餐厅内部问题。
(2)灵活处理异常
中层可以灵活选择处理或传递异常,比如换一家餐厅(处理)或直接让用户决定(传递)。
关键点
-
throws仅用于声明 检查型异常,非检查型异常(如RuntimeException)无需声明。 -
调用者必须处理这些异常(通过
try-catch或继续throws)
捕获异常
现在已经知道如何抛出异常了,想必,你一定很好奇到底怎样才能将异常真正处理掉吧那接下来将进行讲解
捕获异常概述
如果发生了某个异常,但没有在任何地方捕获这个异常,程序就会终止,并在控制台上打印一个消息,其中包括这个异常的类型和一个栈轨迹。不过,图形用户界面程序可能会捕获异常,打印栈轨迹消息,然后返回用户界面处理循环
基础语法
要想捕获一个异常,需要建立try/catch语句块。
try
{
code
more code
}
catch (ExceptionType e)
{
handler for this type
}try块
- 作用:包裹可能会出问题的代码
catch 块
-
作用:捕获特定类型的异常,并处理它
e是什么:异常对象,包含错误信息(比如e.getMessage()可以获取错误描述)
如果try语句块中的任何代码抛出了catch子句中指定的一个异常类,那么
1.程序将跳过try语句块的其余代码
2.程序将执行catch子句中的处理器代码(catch 块中的代码)
如果try语句块中的代码没有抛出任何异常,那么程序将跳过catch子句
如果方法中的任何一个代码抛出了一个异常,但不是catch子句中指定的异常类型,那么这个方法会立即退出(希望他的调用者为这种类型的异常提供了catch子句)
//一个很典型的读取数据的代码
public void read (String filename)
{
try
{
var in = new FileInputStream(filename);
int b;
while((b = in.read()) != -1)
{
process input;
}
}
catch (IOException exception)
{
exception.printStackTrace();
}
}注意:try子句中的大多数代码都很容易理解:读取并处理字节,直到遇到文件结束符为止。正如在Java API中看到的那样,read方法有可能抛出一个IOException异常。在这种情况下,将跳出整个while循环,进入catch语句,并生成一个栈轨迹。对于一个"玩具类"的简单程序来说,这样处理异常看上去很有道理。还有其他选择吗?
通常,最好的选择是什么也不做,而只是将异常继续传递给调用者。如果read方法出现了错误,就让read方法的调用者去操心这个问题!如果采用这种方式,就必须声明这个方法可能会抛出一个IOException
public void read(String filename) throws IOException
{
var in = new FileInputStream(filename);
int b;
while((b = in.read())!= -1)
{
process input;
}
}请记住,编译器严格的执行throws说明符。如果调用了一个抛出检查型异常的方法,就必须处理这个异常,或者继续传播这个异常
那么,这两种方法哪一个更好呢?一般是,要捕获那些你知道如何处理的异常,继续传播那些你不知道怎样处理的异常。
如果想传播一个异常,就必须在方法的首部添加一个throws说明符,提醒调用者这个方法可能会抛出一个异常。
这里需要补充一个 Java 异常处理的核心原则之一"将异常交给胜任的处理器处理要比压制异常更好",应该通过合理的异常传递机制让合适的代码(“胜任的处理器”)处理问题,而不是简单压制(忽略或吞没异常)。
这里用生活例子理解“不要压制异常”
想象你是一个餐厅的服务员,负责把顾客点的菜传给后厨。如果后厨发现某个菜没食材了(异常发生了),做法是:
1. 压制异常(错误做法)
后厨:“没食材了,但我啥也不说,假装正常。”
服务员继续上菜,结果顾客等半天发现菜没来,气炸了!
结果:顾客不知道问题,餐厅信誉受损。
2. 交给处理器(正确做法)
后厨:“没食材了!快告诉服务员!”(抛出异常)
服务员(处理器)收到消息,立刻告诉顾客:“抱歉,这个菜没了,可以给您换个菜吗?”
结果:顾客虽然失望,但能及时调整,餐厅保持信誉
那么,什么是“压制异常”?
压制异常 指的是在捕获异常后,未正确处理或传递错误信息,导致程序掩盖了问题。
以下是常见的压制方式
1.空的catch块:捕获异常后什么都不做
try { riskyOperation(); } catch (Exception e) { //什么也不做 }2.仅打印日志不处理:记录异常但不采取任何恢复或传递措施。
try { riskyOperation(); } catch (Exception e) { logger.error("出错啦", e); // 仅记录,未恢复或传递 }如何正确传递异常
1.向上抛出异常
2.转换为业务异常
3.顶层统一处理(是最终处理)
同时请记住,前面曾经提到过这个规则有一个例外。如果编写一个覆盖超类方法的方法,而这个超类方法没有抛出异常,就必须捕获你的方法代码中出现的每一个检查型异常。子类的throws列表中不允许出现超类方法中未出现的异常类。
捕获多个异常
在一个try语句块中可以捕获多个异常类型,并对不同类型的异常做出不同的处理。要为每个异常类型使用一个单独的catch子句
基础语法
1.多个独立的catch块
try {
// 可能抛出多种异常的代码
} catch (异常类型1 e) {
// 处理异常类型1
} catch (异常类型2 e) {
// 处理异常类型2
}异常对象可能包含有关异常性质的信息。要想获得这个对象的更多信息可以尝试使用e.getMessage(),得到详细的错误消息,或者使用e.getClass().getName()得到异常对象的实际类型
2.合并捕获
用 | 分隔多个异常类型
try {
// 可能抛出多种异常的代码
} catch (异常类型1 | 异常类型2 e) {
// 统一处理两种异常
}只有当捕获的异常类型彼此之间不存在子类关系时才需要这个特性
注:捕获多个异常时,异常变量隐含为final变量,不能修改异常对象 e
捕获多个异常不仅会让你的代码看起来简单,还会更高效。生成的字节码只包含对应公共catch子句的一个代码块
再次抛出异常与异常链
再次抛出异常
当在catch块中捕获一个异常后,可以选择不直接处理它,而是重新抛出(rethrow)这个异常,或者抛出一个新的异常。这常用于
子系统封装:
底层代码(如数据库操作)抛出技术细节异常(如SQLException),但上层(如web)需要业务级异常(如ServletException)以隐藏实现细节
异常类型适配:
将底层异常转换为符合调用方预期的类型,例如将IOException转换为DataProcessingException
异常信息增强:
在抛出异常时附加上下文信息,便于问题定位
常见的再次抛出
try
{
access the database
}
catch (SQLException e)
{
throw new ServleException("database error:"+ e.getMessage());
}在这个代码中,构造ServleException时提供了异常的消息文本
有一个更好的想法,可以把原始异常设置为新异常的"原因",这是异常链的核心思想
异常链
什么是异常链
异常链是指将原始异常(根本原因)作为新异常的"原因"(cause)保存,形成链式关联。就像破案时保留证据链:
-
原始异常:数据库连接失败(
SQLException) -
新异常:订单创建失败(
OrderException) -
链式关系:
OrderException内部持有SQLException
try
{
access the database
}
catch (SQLException original)
{
var e = new ServletException("database error");
e.initCause(orininal);
throw e;
}捕获到这个异常时,可以使用下面这条语句获取原始异常:
Throwable original = caughtException.getCause();建议使用这种包装技术。这样可以在子系统中抛出更高层次异常,而不会丢失原始异常的细节信息
核心方法:
Throwable.getCause():
获取当前异常的原始原因(即链中的前一个异常)
Throwable.initCause(Throwablecause):
显示设置异常的原因(需在构造函数未设置原因时使用)
构造函数的直接支持
许多异常类(如ServletException)提供直接设置原因的构造函数:
try{
//数据库操作
} catch (SQLException e) {
throw new ServletException("数据库错误",e);//直接传递原始异常
}
在这里主要是进行了隐式调用:initCause():
异常链的调试价值
保留完整的堆栈轨迹(Stack Trace),避免关键调试信息丢失
包装检查型异常的场景
当方法签名不允许抛出检查型异常时(如实现某个接口方法),可将其包装为RuntimeException
public void loadConfig() {
try {
Files.readString(Path.of("config.json"));
} catch (IOException e) {
throw new RuntimeException("配置加载失败", e); // 转换为运行时异常
}
}何时保留检查型异常
调用方有能力且需要处理该异常时(如文件未找到需提示用户重试)
有时你可能希望捕获异常后记录日志,然后原封不动地重新抛出同一个异常,不改变异常类型
try {
access the database; // 可能抛出 SQLException
} catch (Exception e) {
logger.log("出错了", e); // 记录日志
throw e; // 重新抛出原异常
}Java 7 之前的问题
如果方法声明为 throws SQLException,但 catch 块捕获的是 Exception,编译器会认为 throw e`可能抛出任何 Exception 类型(如 IOException、NullPointerException 等)。
因此,编译器要求方法必须声明 throws Exception,而不是 throws SQLException,导致异常声明不精确。
Java 7 的改进
编译器会跟踪 e的来源:如果 try 块中实际抛出的异常只有 SQLException,且 catch 块中没有修改 e,则编译器允许方法声明 throws SQLException。
这样既保留了精确的异常声明,又简化了代码。
finally子句
代码在抛出异常时就会停止处理这个方法中剩余的代码,并退出这个方法。如果这个方法已经获得了只有他自己知道的一些本地资源,而且这些资源必须经过清理,这就会有问题。一种解决方案是捕获所有的异常,完成资源的清理,再重新抛出异常,比较繁琐,因为既需要在正常的代码中清理资源分配,又需要在异常的代码中清理资源分配。finally子句可以解决这个问题
不管是否捕获到异常,finally子句中的代码都会执行。在下面例子中,所有程序都将关闭输入流。
var in = new FileInputStream(...);
try
{
//1
code that might throw exceptions
//2
}
catch (IOException e)
{
//3
show error message
//4
}
finally
{
//5
in.close();
}
//6(1)代码没有抛出异常。这种情况下,程序先执行try语句块中的所有代码,然后执行finally子句中的代码,然后执行紧跟着finally子句的第一条语句。因而,最终的执行顺序是,1,2,5,6
(2)代码抛出一个异常并在catch语句中捕获。这种情况下,程序先执行try语句块中的所有代码,直到抛出异常为止,在抛出异常之后,将跳过try语句块中的剩余代码,转去执行与该异常匹配的catch子句中的代码,然后执行finally子句中的代码
如果catch子句没有抛出异常,程序将执行finally子句之后的第一条语句。在这种情况下程序执行的顺序是1,3,4,5,6
如果catch子句抛出了一个异常,异常将被抛回到这个方法的调用者。执行的顺序是1,3,5
(3)代码抛出了一个异常,但没有任何catch子句捕获这个异常。在这种情况下,程序将执行try语句块中的所有语句,直到抛出异常为止。在抛出异常之后,将跳过try语句块中的剩余代码,然后执行finally子句中的代码,并将异常抛回给这个方法的调用者。在这里执行的顺序只是1,5
try语句可以只有finally子句,而没有catch子句。例如,以下的try语句
InputStream in = ...;
try
{
code that might throw exceptions
}
finally
{
in.close();
}无论try语句块是否遇到异常,finally子句中的in.close()语句都会执行。如果遇到一个异常,这个异常将会被重新抛出,并且必须由另一个catch子句捕获
InputStream in = ...;
try
{
try
{
code that might throw exceptions
}
finally
{
in.close();
}
}
catch (IOException e)
{
show error message
}内层的try语句块来确保关闭输入流。外层的try语句块确保报告出现的错误。这种解决方案不仅更清楚,而且功能更强:将会报告finally子句中出现的错误
这里需要注意:不要把改变控制流的语句放在finally子句中
以下进行解释
在 Java 中,
finally子句的设计初衷是确保无论是否发生异常,某些关键代码(如资源释放)必须执行。然而,如果在finally块中使用了return语句,可能会导致以下两种意想不到的结果,严重时甚至破坏程序的逻辑完整性1.覆盖
try或catch中的返回值当
try或catch块中已经存在返回值,但finally块中也有return时,finally的返回值会覆盖前者,导致程序逻辑与预期不符public static int testFinally() { try { return 1; // 预期返回 1 } catch (Exception e) { return -1; } finally { return 2; // 实际返回 2 } }原因
JVM 会先执行
try或catch中的return,将返回值暂存到局部变量表中。接着执行
finally块,覆盖暂存的返回值。最终返回的是
finally中的值。2.抑制异常传播
如果
try或catch中抛出了异常,但finally中有return,原始异常会被丢弃,程序不会向上层抛出异常,导致错误被隐藏。public static void main(String[] args) { try { testException(); } catch (Exception e) { System.out.println("捕获到异常:" + e.getMessage()); // 不会执行! } } public static void testException() { try { throw new IOException("文件读取失败"); // 抛出异常 } finally { return; // 抑制异常,直接退出 } }原因
finally中的return会强制方法正常返回,忽略try中的异常。(解释:清除已记录的异常,将方法标记为“正常返回”)上层代码无法捕获到异常,导致错误无法被正确处理。
try-with-resources语句
try-with-resources 是 Java 7 引入的一种语法结构,旨在自动管理资源(如文件、数据库连接、网络连接等)的关闭,避免资源泄漏。它的核心机制是通过 AutoCloseable 接口,确保在代码块执行完毕后自动调用资源的 close() 方法,无需手动编写 finally 块
那么为什么要引入 try-with-resources呢?
传统 try-finally 的缺点
-
代码冗余:需要手动编写
finally块关闭资源,代码重复且易出错。 -
异常覆盖:如果
try块和finally块同时抛出异常,finally中的异常会覆盖try中的原始异常,导致调试困难。 -
资源泄漏风险:若忘记关闭资源,或关闭逻辑有误,会导致资源泄漏。
try-with-resources 的优势
-
自动关闭资源:资源在代码块结束后自动关闭。
-
异常抑制机制:保留主逻辑异常,关闭异常作为“被抑制异常”附加。
-
代码简洁性:减少冗余代码,提高可读性。
基本语法
单资源声明
try (ResourceType resource = new ResourceType()) {
// 使用资源
} catch (Exception e) {
// 处理异常
}多资源声明
多个资源用分号分隔,按声明顺序逆序关闭
try (
InputStream in = new FileInputStream("input.txt");
OutputStream out = new FileOutputStream("output.txt")
) {
// 使用资源
} catch (IOException e) {
// 处理异常
}Java 9+ 的改进
支持使用已存在的 final 或等效 final 变量
InputStream in = new FileInputStream("input.txt");
try (in) { // Java 9+ 允许直接引用外部变量
// 使用资源
}使用要求:AutoCloseable 接口
资源类必须实现 AutoCloseable 接口(或其子接口 Closeable),该接口定义了 close() 方法
AutoCloseable:Java 7 引入,close() 声明为 throws Exception。
Closeable:Java 5 引入(主要用于 IO 流),close() 声明为 throws IOException
public interface AutoCloseable {
void close() throws Exception;
}自定义资源
class MyResource implements AutoCloseable {
@Override
public void close() throws Exception {
System.out.println("资源已关闭");
}
}如何使用这个类?
结合 try-with-resources 语法自动调用 close()
public static void main(String[] args) {
try (MyResource resource = new MyResource()) {
// 使用资源
System.out.println("使用资源中...");
} catch (Exception e) {
e.printStackTrace();
}
}
//使用资源中...
//资源已关闭异常处理机制
异常抑制
如果 try 块和资源关闭(close())均抛出异常,主异常会被保留,关闭异常作为“被抑制异常”附加。
可通过 Throwable.getSuppressed() 获取被抑制的异常
try-with-resources 通过自动关闭资源和合理的异常处理机制,显著提升了代码的健壮性和可维护性。
相信你肯定不想手动编程来处理传统try-catch所带来的问题,那就尽力来使用try-with-resources吧
最后,简单来说一下使用异常的技巧
使用异常的技巧
-
异常处理不能代替简单的测试
只在异常情况下使用异常,避免因频繁捕获异常导致性能下降。 -
不要过分地细化异常
避免将每个操作单独包裹在try块中,应将完整任务封装在单个try块中,分离正常处理与错误处理。 -
合理利用异常层次结构
不要仅抛出RuntimeException,应选择合适子类或自定义异常类。区分检查型和非检查型异常,避免为逻辑错误抛出检查型异常。 -
不要压制异常
避免在catch块中忽略异常(如直接空捕获),应正确处理异常而非静默忽略。 -
在检测错误时,“苛刻”要比放任更好
在错误发生时直接抛出异常(如EmptyStackException),而非返回虚拟值(如null)。 -
不要羞于传递异常
允许异常向调用链上层传递,由更高层方法处理错误,而非强制在底层捕获所有异常。 -
使用标准方法报告 null 指针和越界异常
利用Objects类方法(如requireNonNull,checkIndex)进行参数校验,生成标准异常消息。 -
不要向最终用户显示栈轨迹
将异常栈轨迹记录到日志中,仅向用户展示简洁的错误摘要,避免暴露实现细节。
好啦,到现在也就把异常处理机制简单说了一下,其中还有很多知识需要你去学习,比如,断言,日志,等,感兴趣的小伙伴可以再去找一些资源学习。文章中有知识性错误的还请在评论区留言,我一定进行更改


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









