






- 执行计划分析
- key_len索引覆盖长度
创建数据库和表并写入数据:
create database school default charset utf8mb4 collate utf8mb4_bin;
use school;
create table test (id int,k1 char(2) not null,k2 varchar(2) not null,k3 char(4),k4 varchar(4)) default charset utf8mb4 collate utf8mb4_bin;
insert into test values (1,'aa','中国','aaaa','汉唐雄风');
insert into test values (2,'bb','美国','bbbb','开心自由');
insert into test values (3,'cc','日本','cccc','抱残守缺');
insert into test values (4,'dd','韩国','dddd','宇宙大国');
desc test;
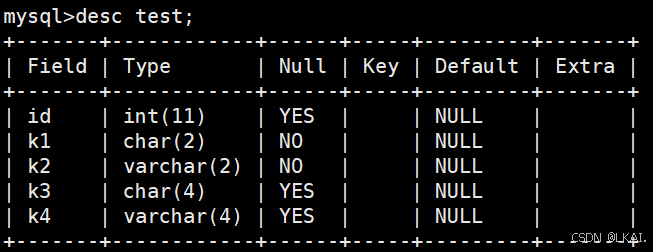
char:定长
varchar:可变长
mb4一个汉字占四个字节,不是mb4占三个字节
创建索引:
alter table test add index idx_k1(k1);
alter table test add index idx_k2(k2);
alter table test add index idx_k3(k3);
alter table test add index idx_k4(k4);
desc select * from test where k1='aa';

char:2位占用8个字节
desc select * from test where k2='韩国';

varchar:2位占用10个字节(有2位存储长度),实际长度+2位存储长度
desc select * from test where k3='cccc';

16+1:多了一个字节,是因为NULL就会占用1个字节存储是否为空,为了提高读写效率
desc select * from test where k4='宇宙大国';

实际长度+2位存储长度+1位NULL长度
4*4+2+1
删除索引:
alter table test drop index idx_k1;
alter table test drop index idx_k2;
alter table test drop index idx_k3;
alter table test drop index idx_k4;
alter table test add index idx_k(k1,k2,k3,k4);

desc test;
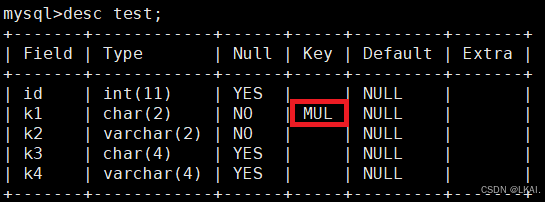
MUL索引显示的第一列k1,所以查询的语句必须加k1才会使用这个索引
desc select * from test where k1='aa' and k2='中国' and k3='aaaa' and k4='汉唐雄风';

索引长度是创建索引列的长度之和
8+10+17+19
desc select * from test where k4='汉唐雄风' and k2='中国' and k3='aaaa' and k1='aa';

条件中不管在什么位置,只要添加了k1,就会使用idx_k索引
desc select * from test where k4='汉唐雄风' and k2='中国' and k3='aaaa';

条件中没有k1,就不会使用索引
总结:
utf8mb4 varchar(20)
可以存放20个任意字符
存放的字符、数字、中文,1个字符最大预留长度为4个字节
中文一般占3个字节,特殊字符占4个字节
1个数字或字母,实际占用1个字节
char用一个字节表示是否为空
varchar用一个字节表示是否为空,用两个字节表示值的长度
Extra: Using filesort
出现Using filesort,说明在查询中有关排序的条件列没有应用索引,MySQL有可能就要进行文件排序。
说明以下的条件没有应用索引
order by
group by
distinct
union
联合索引应用细节
- 在查询时,所有索引列都是等值条件查询,无关排列顺序,唯一值多的列放在最左侧,因为优化器自动做查询条件的排序
如:a的唯一值最多
abcd
acbd
adbc
acbd
- 不连续部分条件
索引是abcd,查询过程:
cda à acd à a
dba à abd à à ab à a
如果类似idx(c,d,a)或idx(d,b,a)查询较多,创建新顺序索引
- 在where查询中如果出现>、<、>=、<=、like ,启用范围range查询
desc select * from test where k1='aa' and k3='aaaa' and k4='aaaaaaaa' and k2>'aaa';

因为是范围查询,所以只走k1和k2
alter table test add index inx1(k1,k3,k4,k2);

desc select * from test where k1='aa' and k3='aaaa' and k4='aaaaaaaa' and k2>'aaa';

alter table test drop index idx_k;

desc select * from test where k1='aa' and k3='aaaa' and k4='aaaaaaaa' and k2>'aaa';

- 多子句查询,应用联合索引
desc select * from test where k1='aa' order by k2;
等值优先

alter table test add index idx3(k1,k2);

desc select * from test where k1='aa' order by k2;

explain\desc使用场景
- MySQL出现性能问题
1)应急性的慢(突然卡住)
数据库卡了,资源耗尽
处理过程:
show processlist:获取导致数据库慢的语句
explain\desc:分析SQL的执行计划,有没有走索引,创建索引,修改索引
2)一段时间慢(持续性的)
记录慢日志slowlog,分析slowlog:
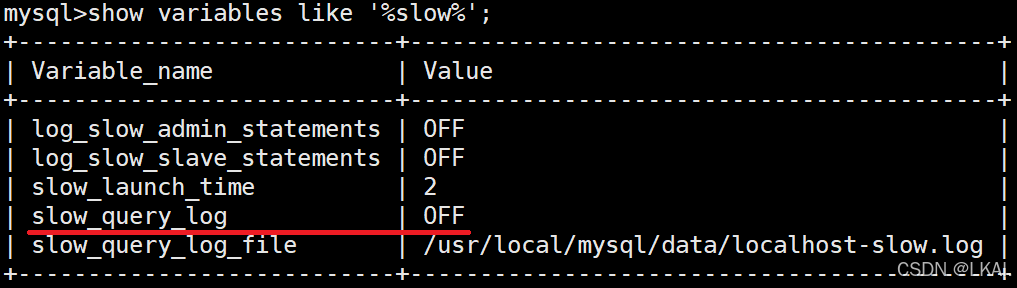
查看慢日志:
show variables like '%slow%';
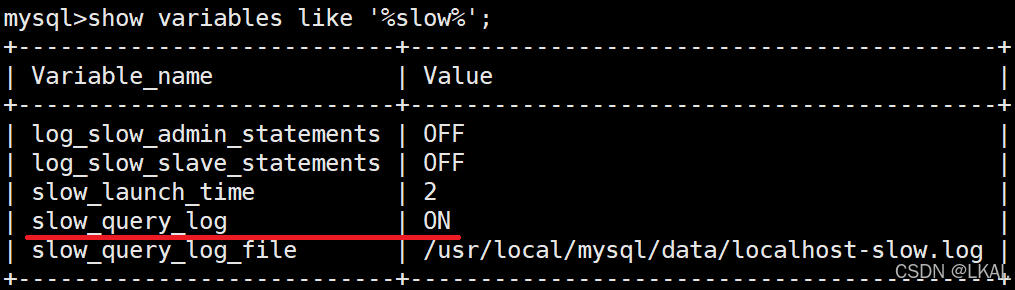
启用慢日志:
set global slow_query_log='on';

show variables like '%slow%';
索引应用规范
- 建立索引的原则
- 建表必须要有主键,一般是无关列,自增长
- 经常作为where条件列建立索引,(order by、group by、join on、distinct)不一定走索引
- 最好使用唯一键多的列作为联合索引前导列,其他的按照联合索引优化细节来做
- 列值长度较长的索引列,我们建议使用前缀索引
- 降低索引条目,一方面不要创建没用索,不常使用的索引清理,percona toolkit(pt-duplicate-key-checker检查冗余索引)
- 索引维护要避开业务繁忙期
- 小表不建索引
- 不走索引的情况
- 没有查询条件或者查询条件没有建立索引
- 查询结果集是原表中的大部分数据,25%以上
- 索引本身失效,统计数据不真实(刚更新数据,索引还没有同步)
- 查询条件使用函数在索引列上或者对索引列进行运算,运算包括(+、-、*、/、! 等)
- 隐式转换导致索引失效(浮点数转字符串)
- <> 、not in 不走索引
- like "%aa" 百分号在最前面不走索引
- 联合索引不查第一个值
视图
- 视图的定义
一张虚表,和真实的表一样。视图包含一系列带有名称的行和列数据。
视图是从一个或多个基表中导出来的,可以通过insert、update、delete来操作视图。
- 视图的优点
简单化:看到的就是需要的。视图不仅可以简化用户对数据的理解,也可以简化操作。经常被使用的查询可以制作成一个视图。
安全性:通过视图用户只能查询和修改所能见到的数据,数据库中其他的数据既看不见也取不到。数据库授权命令可以让每个用户对数据库的检索限制到特定的数据库对象上,但不能授权到数据库特定的行,列上。
逻辑数据独立性:视图可帮助用户屏蔽真实表结构变化带来的影响。
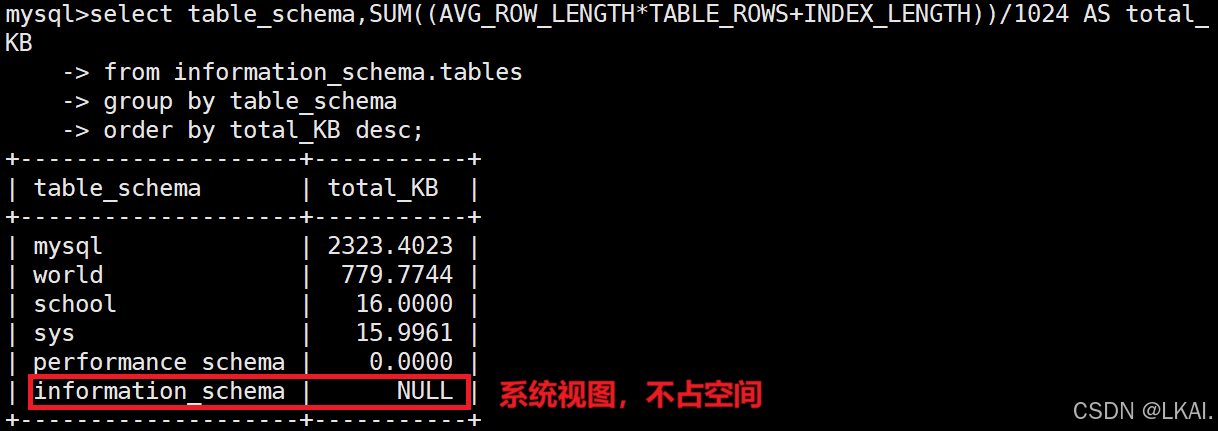
查看系统视图空间:
select table_schema,SUM((AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH))/1024 AS total_KB
from information_schema.tables
group by table_schema
order by total_KB desc;
- 创建单表视图
创表并插入数据:
create table t(quantity int,price int);
insert into t values(3,50);
创建视图:
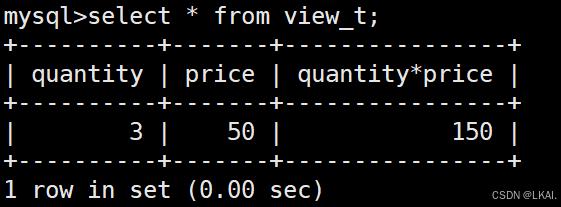
create view view_t as select quantity,price,quantity*price from t;

查看视图:
select * from view_t;
show tables;
- 创建多表视图
创建表并插入数据:
create table student( s_id int(3) primary key,s_name varchar(30),s_age int(3),s_sex varchar(8));
create table stu_info(s_id int(3),class varchar(50),addr varchar(100)) default charset utf8mb4 collate utf8mb4_bin;
insert into student values (1,'z3',20,'m'),(2,'L4',30,'m'),(3,'w5',40,'f');
insert into stu_info (s_id,class,addr) values(1,'二班','安徽'),(2,'三班','重庆'),(3,'一班','山东');
创建视图:
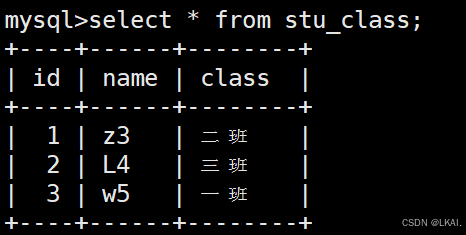
create view stu_class(id,name,class) as select student.s_id,student.s_name,stu_info.class from student,stu_info where student.s_id=stu_info.s_id;

查询视图:
select * from stu_class;
查看视图的基本信息:
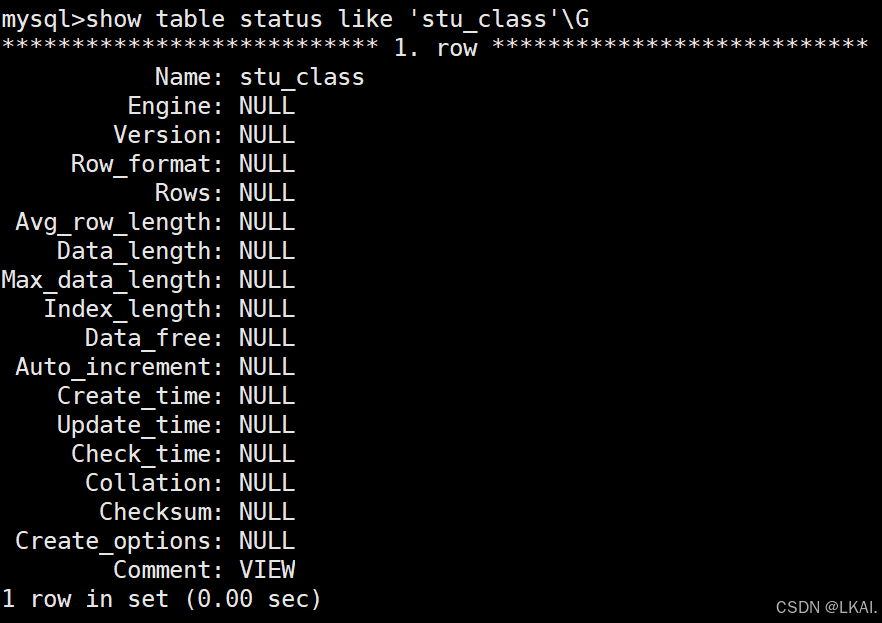
show table status like 'stu_class'\G
查看视图的详细信息:
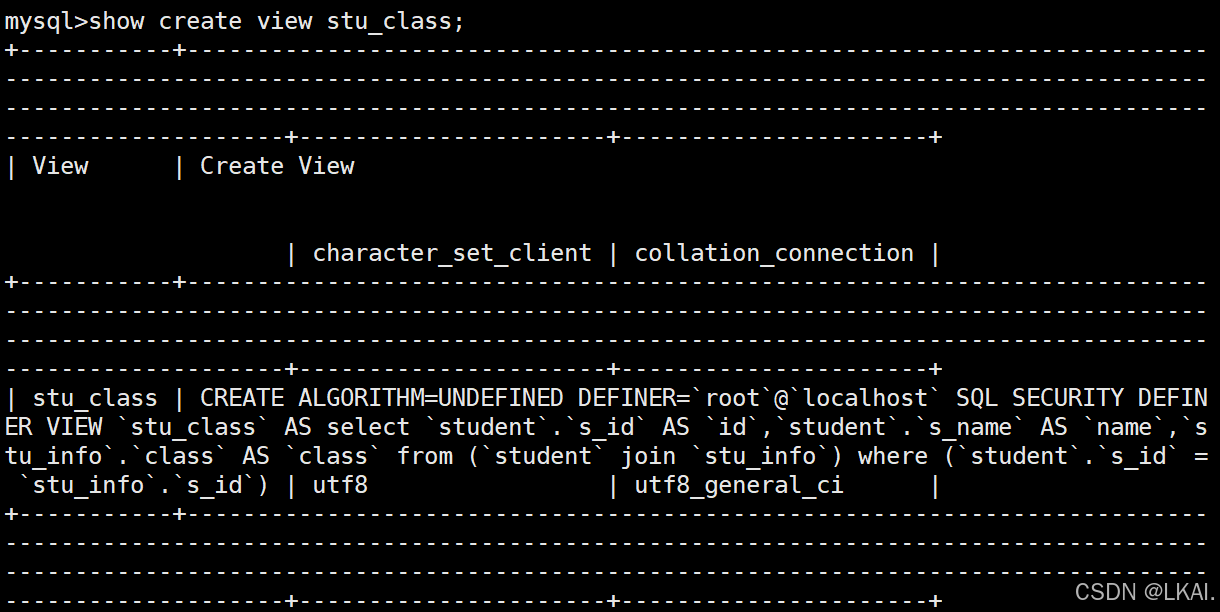
show create view stu_class;
- 查看MySQL中所有视图
select * from information_schema.views\G
![]()
- 修改视图
语法:
create or replace view 视图名 as 查询语句;
或
alter view 视图名 as 查询语句;
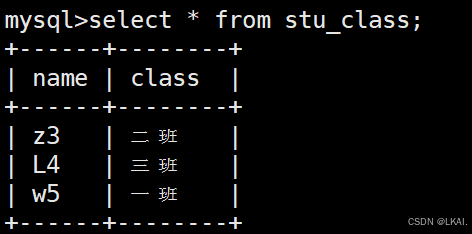
alter view stu_class(name,class) as select student.s_name,stu_info.class from student,stu_info where student.s_id=stu_info.s_id;

select * from stu_class;
- 更新视图(通过视图改源表)
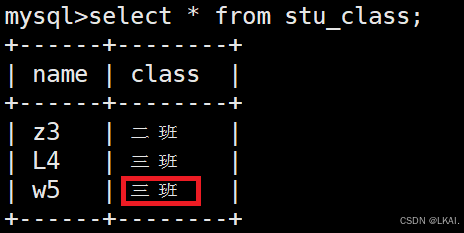
update stu_class set class='三班' where name='w5';

select * from stu_class;
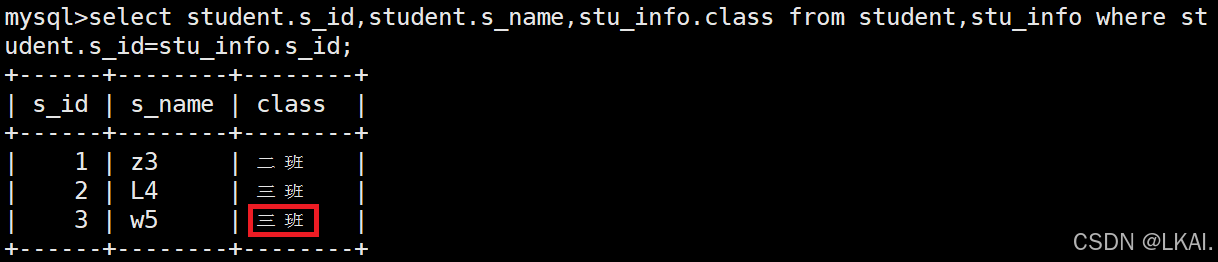
select student.s_id,student.s_name,stu_info.class from student,stu_info where student.s_id=stu_info.s_id;
- 删除视图内容
delete from 视图名
- 删除视图
drop view 视图名
- 视图和表的区别
- 视图是已经编译好的SQL语句,是基于SQL语句的结果集的可视化的表。而表不是
- 视图没有实际的物理记录,而表有
- 表是内容,视图是窗口
- 表占物理空间,视图不占用物理空间(创建视图的语句会占),视图只是逻辑概念存在,而表可以及时对数据进行修改,但是视图只能用创建语句来修改
- 视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL 语句的集合。从安全角度来说,视图可以防止用户接触数据表,因而不知道表结构
- 表属于全局模式中的表,是实表。而视图属于局部模式的表,是虚表
- 视图的建立和删除只影响视图本身,而不影响对应表的基本表
- 视图和表的联系
视图是在基本表之上建立的表,它的结构和内容都来自于基本表,它依赖基本表存在而存在。
一个视图可以对应一个基本表,也可以对应多个基本表。视图是基本表的抽象和逻辑意义上建立的关系。
- 视图的优缺点
优点:
简化查询,把复杂的单表或多表查询语句,简单化。
提供安全层,可以针对特定用户限制访问某些基表的特殊列。
缺点:
视图嵌套,影响查询效率。
视图与基表有依赖关系,频繁修改基表会比较繁琐。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









