






目录
1.项目背景:
使用LSTM模型的场景,是由于我们进行统计建模大赛进行农业亩产量的预估,为了处理一个三维的数据,准确的说是由(样本数,时间步长,特征数(类似温度,降雨量,光照的数据))三个维度上的量构成的一个数据集,由于一开始采用一般的模型都处理的是两维的模型,未考虑时间,所以我们都是将数据集降维(样本数,时间步长*特征数)进行处理,效果较差,所以选择LSTM模型。废话不多说,直接上代码。
2.代码简介:
进行模型训练主要分为以下几个步骤:
1.数据获取
2.数据预处理
3.构建模型,喂入模型训练
4.查看效果即可
2.1数据获取:
由于数据是存储在matalab里面,所以我们采用loadmat的函数吧数据下载下来,由于data是一个文件夹,里面由weather,yield,area三组数据,其中weather内部存的就是(样本数,特征数,时间步长)类型的数据,yield中存的是(样本数,相关量),yield中都是为二维的数据,其中最后一列(第六列)是我们训练的目标量,即(亩产值)。
# 加载.mat文件
dataset_path = 'data/corn_preprocessed02.mat'
mat_data = loadmat(dataset_path)["data"]
#特征值(27417, 5, 365)
weather_data = mat_data['weather'][0,0]#特征值(27417, 5, 365)
#所有土地数据(27417, 6)
yield_data_all = mat_data['yield'][0,0]
#亩产值
yield_data = yield_data_all[:, 5, None]#亩产值
#训练样本
x_train=weather_data #输入量
y_train=yield_data #目标量2.2数据预处理
我们将数据读取并划分输入量(特征)以及目标量(亩产值),接下来就是对数据进行预处理,其中包括剔除一些异常点,然后进行归一化即可。这里的剔除异常点我们只是采用简单的剔除大于0,小于3000的量,实际上使用的时候,可以根据需要去更改,或者采用其他的异常点剔除的算法,如K—means聚类算法等等,去先进行数据异常点的剔除,剔除代码如下:
#数据筛选 选出一定区间范围中的数据
yield_low =0
yield_high=3000
yield_condition_low = yield_data_all[:,5]>yield_low
yield_condition_high = yield_data_all[:,5]<yield_high
select_condition = yield_condition_low & yield_condition_high
y_train=y_train[select_condition,:]
x_train=x_train[select_condition,:]
##print('训练输入样本:',x_train.shape,'训练目标样本',y_train.shape)接着就是把剔除后的数据进行归一化处理,这里采用的归一化算法也是最简单的最大最小值的归一化,使得数据都能落在(0,1)之间。但是需要注意的一点是,对于特征量的三维处理,由于是三维数据,需要转化成二维数据进行归一化之后,再转化回三维数据,所以涉及到一个降维,由于都是调用的Python中自带的库,所以比较简单,感兴趣的同学可以深入看看这些函数的具体内容,
这里还有一个需要注意的地方,由于LSTM处理的是(样本数n,时间步长m,特征量z),而我们一开始的数据是(27417,5,365),365天作为时间步长,与特征量m=5位置反了,所以进行了一下位置交换,代码如下:
##数据归一化处理
scaler = MinMaxScaler()
x_train_reshaped = x_train.reshape(-1, x_train.shape[1])##转化成二维数组
# 对第二维的5个特征量进行归一化处理
x_train_normalized = scaler.fit_transform(x_train_reshaped)
# 将归一化后的数据重新恢复成原始的三维形状
#归一化后数据
x_train_1 = x_train_normalized.reshape(x_train.shape)
x_train_1=np.transpose(x_train_1, (0, 2, 1))#这里的话是改变原来三维数据的结构,把第二维和第三维互换位置
y_train_1=scaler.fit_transform(y_train)
##print(x_train_1.shape,y_train_1.shape)接下来就是划分训练模型的样本集、训练集和测试集,较为简单,可以直接复用,代码如下:
##数据集划分
# 定义划分比例
train_ratio = 0.7 # 训练集比例
val_ratio = 0.2 # 验证集比例
test_ratio = 0.1 # 测试集比例
# 划分训练集和剩余数据
x_train_val, x_test, y_train_val, y_test = train_test_split(x_train_1, y_train_1, test_size=test_ratio)
# 根据剩余数据的比例划分验证集和测试集
relative_val_ratio = val_ratio / (val_ratio + train_ratio)
x_train, x_val, y_train, y_val = train_test_split(x_train_val, y_train_val, test_size=relative_val_ratio)
# 输出划分后的数据集大小
'''print("训练集大小:", x_train.shape, y_train.shape)
print("验证集大小:", x_val.shape, y_val.shape)
print("测试集大小:", x_test.shape, y_test.shape)'''2.3构建模型
先看代码,如果需要复用的话,一般来说是需要改动这个input_shape(365,5),为自己训练样本的结构即可,代码如下:
##LSTM模型
# 构建模型
model = Sequential()
# 添加LSTM层
model.add(LSTM(units=50, input_shape=(365, 5))) # units为LSTM层的神经元数量,input_shape为输入数据的形状
# 添加输出层
model.add(Dense(units=1)) # 输出层为一个全连接层,units为1,因为这是一个回归问题
# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error') # 编译模型,使用adam优化器和均方误差损失函数
# 训练模型
history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val))
# 使用测试集评估模型
loss = model.evaluate(x_test, y_test)
print("Test Loss:", loss)
y_pred = model.predict(x_test)具体的内容,比如LSTM内部的一些知识点,这里就不过多介绍,秉承着零基础教学,拿来主义,后面再补相关知识也来得及。
2.4查看模型效果
这一段首先是对训练后模型预测的数据进行了反归一化处理,得到我们预测的亩产值,并且将预估值与实际值保存成CSV文件进行其他操作,然后进行了一些RMAE、MAE的计算,以及绘制图像,代码如下
#反归一化数据
y_pred_inverse = scaler.inverse_transform(y_pred)
y_test_inverse = scaler.inverse_transform(y_test)
mae = np.mean(np.abs((y_test_inverse - y_pred_inverse) ))
# 计算 RMAE (相对平均绝对误差)
rmae = np.mean(np.abs((y_test_inverse - y_pred_inverse) / y_test_inverse))
# 打印评估结果
print("MAE (平均绝对误差):", mae)
print("RMAE (相对平均绝对误差):", rmae)
# 将预测值和真实值转换为 NumPy 数组
y_pred_array = np.array(y_pred_inverse)
y_test_array = np.array(y_test_inverse)
# 将预测值和真实值保存到文件中,例如 CSV 文件
# 将 NumPy 数组保存到 CSV 文件
np.savetxt('predicted_values02.csv', y_pred_array, delimiter=',')
np.savetxt('true_values02.csv', y_test_array, delimiter=',')
# 创建散点图比较预测值和真实值
y_test_array1=y_test_array[:,0]
y_pred_array1=y_pred_array[:,0]
# 创建散点图
plt.figure(figsize=(8, 6))
sns.scatterplot(x=y_test_array1, y=y_pred_array1)
# 设置图表标题和标签
plt.title('测试集预测值与真实值')
plt.xlabel('真实值')
plt.ylabel('预测值')
# 添加对角线
plt.plot([min(y_test_array), max(y_test_array)], [min(y_test_array), max(y_test_array)], color='red', linestyle='--', label='Perfect Prediction')
# 显示图例
plt.legend()
# 显示图表
plt.show()3模型效果
以上就是LSTM预测亩产的一个全部过程,下面是模型输出的一些结果,可以看到预测的准确度在85%左右,效果相对而言还是较为不错,但是因为农产物亩产预测确实相交于其他的数据预测具有时间跨度长,特征量变化不显著的一些问题,所以效果还是可以接受,如果是一些短期的,比如以24小时,30天为时间步长的数据,效果可能会更好。
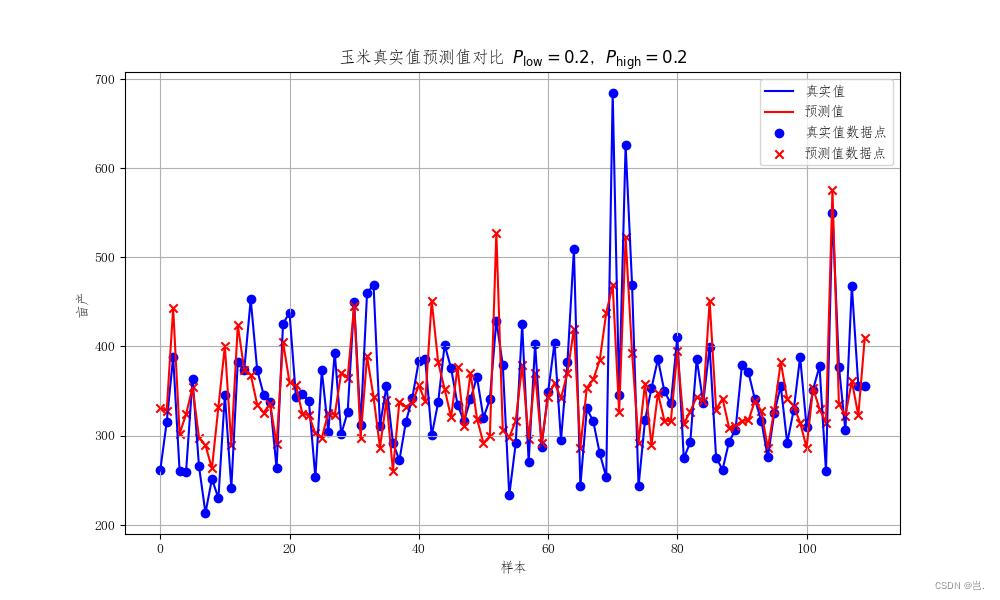
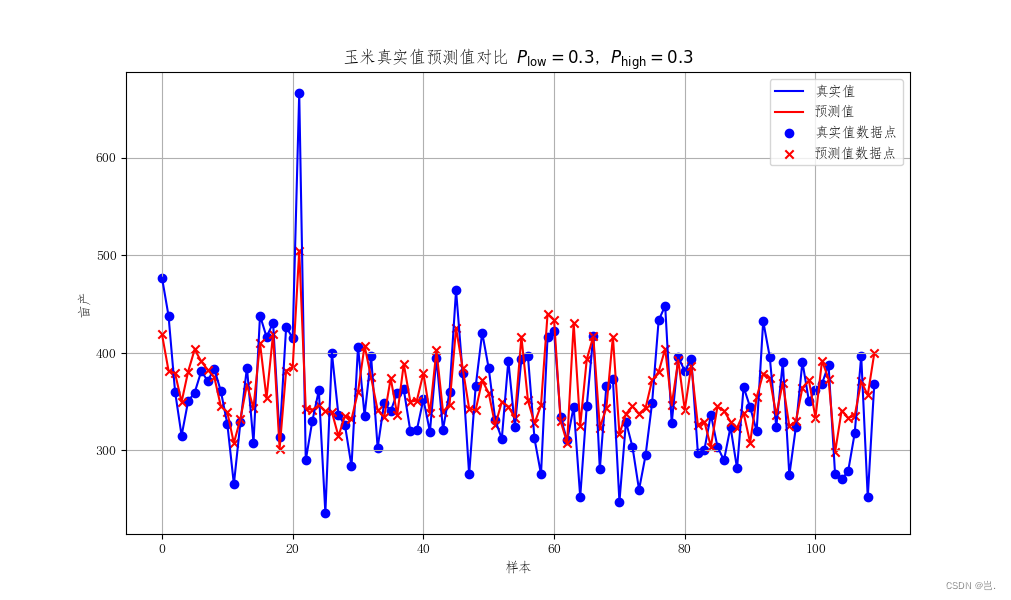
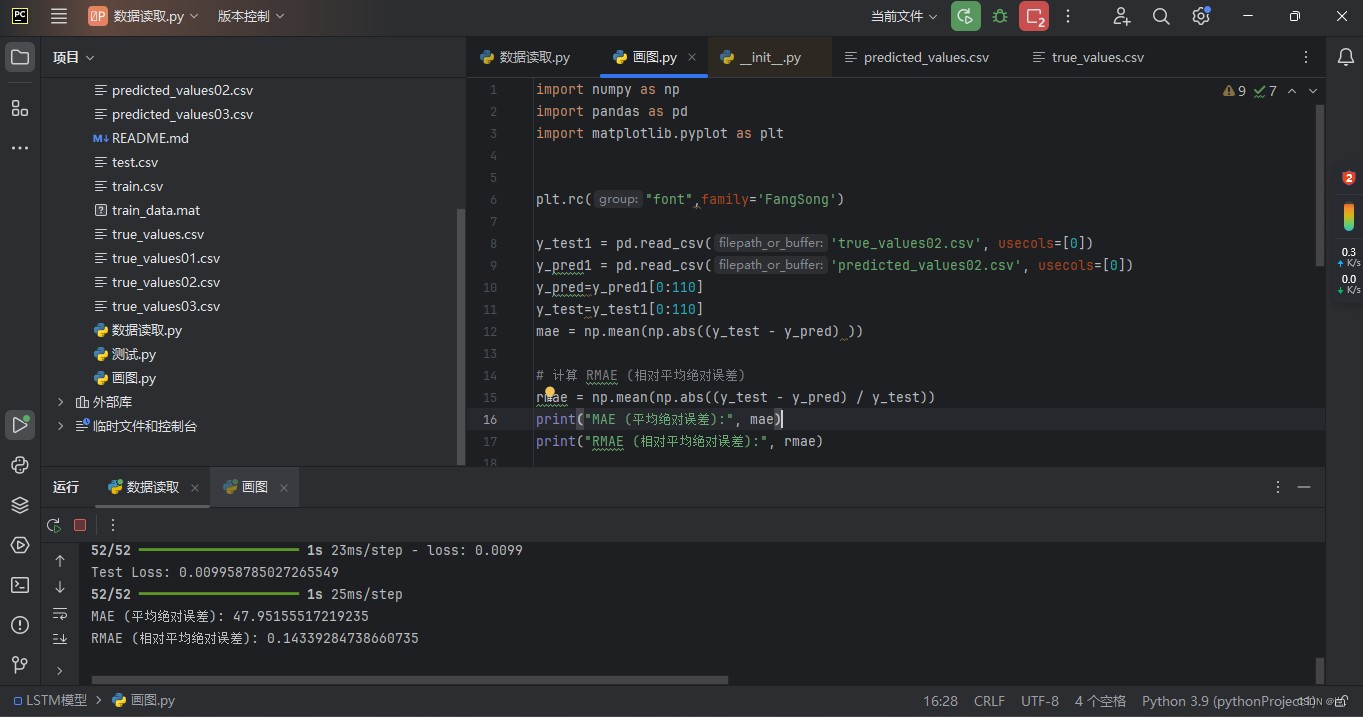
4.全部代码:
训练代码
from scipy.io import loadmat
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from tensorflow.keras import Sequential
from tensorflow.keras.layers import LSTM, Dense,Dropout
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import r2_score, mean_absolute_error
from tensorflow.keras.optimizers import Adam
plt.rc("font",family='FangSong')
# 加载.mat文件
dataset_path = 'data/corn_preprocessed02.mat'
mat_data = loadmat(dataset_path)["data"]
#特征值(27417, 5, 365)
weather_data = mat_data['weather'][0,0]#特征值(27417, 5, 365)
#所有土地数据(27417, 6)
yield_data_all = mat_data['yield'][0,0]
#亩产值
yield_data = yield_data_all[:, 5, None]#亩产值
#训练样本
x_train=weather_data #输入量
y_train=yield_data #目标量
#数据筛选 选出一定区间范围中的数据
yield_low =0
yield_high=3000
yield_condition_low = yield_data_all[:,5]>yield_low
yield_condition_high = yield_data_all[:,5]<yield_high
select_condition = yield_condition_low & yield_condition_high
y_train=y_train[select_condition,:]
x_train=x_train[select_condition,:]
##print('训练输入样本:',x_train.shape,'训练目标样本',y_train.shape)
##数据归一化处理
scaler = MinMaxScaler()
x_train_reshaped = x_train.reshape(-1, x_train.shape[1])##转化成二维数组
# 对第二维的5个特征量进行归一化处理
x_train_normalized = scaler.fit_transform(x_train_reshaped)
# 将归一化后的数据重新恢复成原始的三维形状
#归一化后数据
x_train_1 = x_train_normalized.reshape(x_train.shape)
x_train_1=np.transpose(x_train_1, (0, 2, 1))
y_train_1=scaler.fit_transform(y_train)
##print(x_train_1.shape,y_train_1.shape)
##数据集划分
# 定义划分比例
train_ratio = 0.7 # 训练集比例
val_ratio = 0.2 # 验证集比例
test_ratio = 0.1 # 测试集比例
# 划分训练集和剩余数据
x_train_val, x_test, y_train_val, y_test = train_test_split(x_train_1, y_train_1, test_size=test_ratio)
# 根据剩余数据的比例划分验证集和测试集
relative_val_ratio = val_ratio / (val_ratio + train_ratio)
x_train, x_val, y_train, y_val = train_test_split(x_train_val, y_train_val, test_size=relative_val_ratio)
# 输出划分后的数据集大小
'''print("训练集大小:", x_train.shape, y_train.shape)
print("验证集大小:", x_val.shape, y_val.shape)
print("测试集大小:", x_test.shape, y_test.shape)'''
##LSTM模型
# 构建模型
model = Sequential()
# 添加LSTM层
model.add(LSTM(units=50, input_shape=(365, 5))) # units为LSTM层的神经元数量,input_shape为输入数据的形状
# 添加输出层
model.add(Dense(units=1)) # 输出层为一个全连接层,units为1,因为这是一个回归问题
# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error') # 编译模型,使用adam优化器和均方误差损失函数
# 训练模型
history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val))
# 使用测试集评估模型
loss = model.evaluate(x_test, y_test)
print("Test Loss:", loss)
y_pred = model.predict(x_test)
# 计算 MAE (平均绝对误差)
# 使用模型对测试集进行预测
#反归一化数据
y_pred_inverse = scaler.inverse_transform(y_pred)
y_test_inverse = scaler.inverse_transform(y_test)
mae = np.mean(np.abs((y_test_inverse - y_pred_inverse) ))
# 计算 RMAE (相对平均绝对误差)
rmae = np.mean(np.abs((y_test_inverse - y_pred_inverse) / y_test_inverse))
# 打印评估结果
print("MAE (平均绝对误差):", mae)
print("RMAE (相对平均绝对误差):", rmae)
# 将预测值和真实值转换为 NumPy 数组
y_pred_array = np.array(y_pred_inverse)
y_test_array = np.array(y_test_inverse)
# 将预测值和真实值保存到文件中,例如 CSV 文件
# 将 NumPy 数组保存到 CSV 文件
np.savetxt('predicted_values02.csv', y_pred_array, delimiter=',')
np.savetxt('true_values02.csv', y_test_array, delimiter=',')
# 创建散点图比较预测值和真实值
y_test_array1=y_test_array[:,0]
y_pred_array1=y_pred_array[:,0]
# 创建散点图
plt.figure(figsize=(8, 6))
sns.scatterplot(x=y_test_array1, y=y_pred_array1)
# 设置图表标题和标签
plt.title('测试集预测值与真实值')
plt.xlabel('真实值')
plt.ylabel('预测值')
# 添加对角线
plt.plot([min(y_test_array), max(y_test_array)], [min(y_test_array), max(y_test_array)], color='red', linestyle='--', label='Perfect Prediction')
# 显示图例
plt.legend()
# 显示图表
plt.show()
画图代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rc("font",family='FangSong')
y_test1 = pd.read_csv('true_values02.csv', usecols=[0])
y_pred1 = pd.read_csv('predicted_values02.csv', usecols=[0])
y_pred=y_pred1[0:110]
y_test=y_test1[0:110]
mae = np.mean(np.abs((y_test - y_pred) ))
# 计算 RMAE (相对平均绝对误差)
rmae = np.mean(np.abs((y_test - y_pred) / y_test))
print("MAE (平均绝对误差):", mae)
print("RMAE (相对平均绝对误差):", rmae)
# 绘制原始数据与预测数据的对比图
plt.figure(figsize=(10, 6))
plt.plot(y_test,color='blue', label='真实值')
plt.plot(y_pred,color='red', label='预测值')
plt.scatter(range(len(y_test)), y_test, color='blue', marker='o', label='真实值数据点') # 标记真实值数据点
plt.scatter(range(len(y_pred)), y_pred, color='red', marker='x', label='预测值数据点') # 标记预测值数据点
plt.xlabel('样本')
plt.ylabel('亩产')
plt.title('玉米真实值预测值对比 $P_{\mathrm{low}} = 0.2$, $P_{\mathrm{high}} = 0.2$')
plt.grid(True)
plt.legend()
plt.show()















 8231
8231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









