






编译器:程序
核心功能:
源代码
→
翻译成
目标代码
源代码\overset{\text{翻译成}}{\rightarrow}目标代码
源代码→翻译成目标代码
源代码: C/C++, Java, C#, html
目标代码:x86, IA64, ARM, MIPS
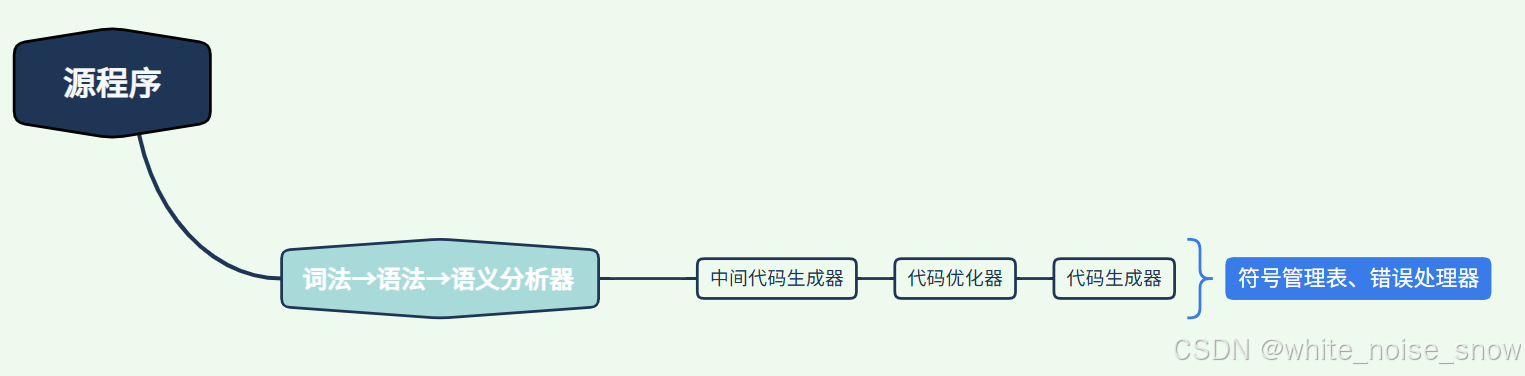
编译器结构
编译器具有非常模块化的高层结构
编译器可看成多个阶段构成的“流水线”结构
每个阶段将源程序从一种表示
→
转换成
\overset{\text{转换成}}{\rightarrow}
→转换成另一种表示
随着编译器各个阶段的进展,源程序内部表示不断发生变化
词法分析器任务
字符流
→
词法分析器
→
单词流
字符流\rightarrow词法分析器\rightarrow单词流
字符流→词法分析器→单词流
从左到右,一个字符一个字符地读入源程序,对构成源程序的字符流进行扫描和分解,从而识别出单词
语法分析器任务
单词流
→
语法分析器
→
语法树
单词流\rightarrow语法分析器\rightarrow语法树
单词流→语法分析器→语法树
根据语言的语法规则,把单词符号串组成各类语法单位.
语法分析:是否符合语法
- 不符合:返回出错处理信息
- 符合:在单词流基础上建立一个层次结构——建立语法树
核心模块:处理程序输入+产生编译器需要的重要结构
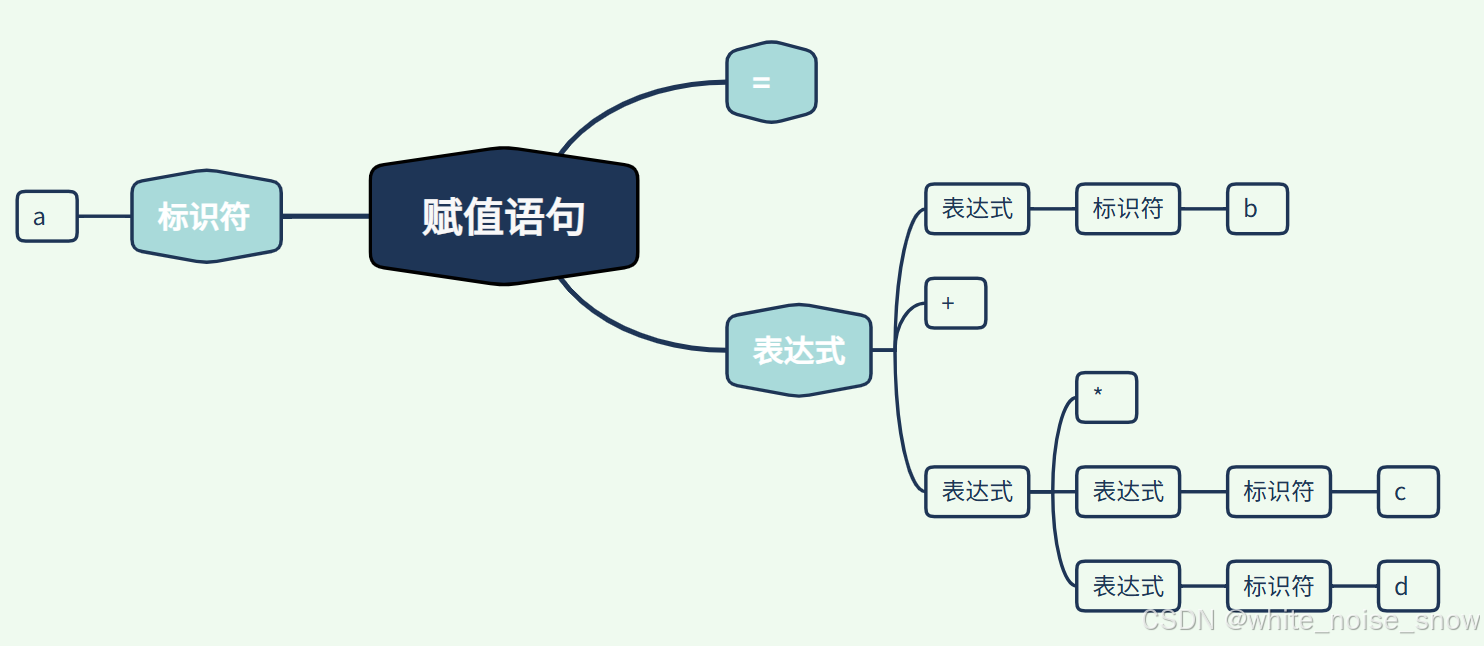
语法分析
a = b + c ∗ d a = b + c * d a=b+c∗d
<id,a>
<=,->
<id, b>
<+,->
<id, c>
<*,->
<id, d>
语义分析任务
收集标识符属性信息:类型Type,种属Kind,存储位置、长度,值,作用域,参数和返回值信息
语义检查
变量或过程未经声明就使用/重复声明,运算分量类型不匹配,操作符与操作数类型不匹配
中间代码
抽象层次逐渐降低
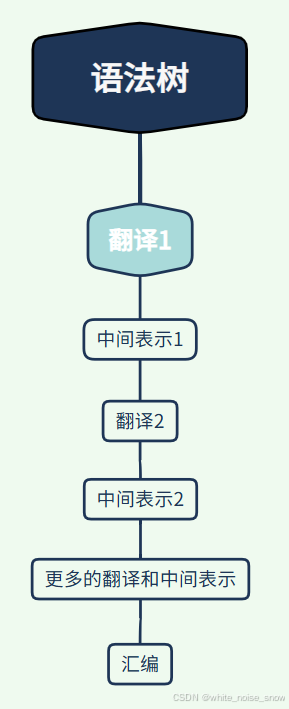
最简单的结构
以前常用,目前少用:维护难度大
语法树
→
翻译
1
(
代码生成
)
→
汇编
语法树\rightarrow翻译1(代码生成)\rightarrow汇编
语法树→翻译1(代码生成)→汇编
中间代码生成阶段
本阶段将产生源程序的一个显式中间表示
可以看成是某种抽象的程序,通常与平台无关
重要性质:1.易于产生2.易于翻译成目标程序
用三地址码和四元式表示的例子
(
o
p
,
a
r
g
1
,
a
r
g
2
,
r
e
s
u
l
t
)
(op, arg1, arg2, result)
(op,arg1,arg2,result)
temp1=c*d
temp2=b+temp1
a=temp2
(* , c , d , temp1)
(+ , b, temp1 , temp2)
(= , temp2 , - , a)
嵌套循环伪代码和控制流图表示
while a < b do
if c < 5 then
while x > y do
z = x + 1;
else
x = y;
代码优化阶段——生成可重定位的机器代码或汇编代码
一个重要任务是为程序中使用的变量合理分配寄存器
试图改进中间代码,以产生执行速度较快的机器代码
对中间代码进行优化处理后,产生如下代码:
temp1=c*d
a=b+temp1
Mov R2,c
Mul R2, d
Mov R1, b
Add R2, R1
Mov a, R2
符号表——数据结构
每个标识符在符号表中都有一条记录
基本功能:记录源程序中使用的标识符并收集与每个标识符相关的各种属性信息,并将它们记载到符号表中。
int a,b;
float e,f
char ch1,ch2;
先说明——定义变量类型,也就规定了变量在内存中的存放形式,在其上所能进行的运算,解决符号地址到存贮地址上的映射
错误处理器
处理方式:报告错误,应继续编译
大部分错误在语法、语义分析阶段检测出来
词法分析:字符无法构成合法单词
语法分析:单词流违反语法结构规则
语义分析:语法结构正确,但无实际意义
编译器设计的重要问题是如何合理的划分组织各个阶段——接口清晰,编译器容易实现与维护


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









