






01
开源模型近况
尽管GPT-4 Turbo和其他封闭的AI模型的性能正在提高,但开源模型正在迅速赶超。最近,中国的01.AI发布了一个名为Yi-34B的开源模型,在几个基准测试上超过了其他开源同行。
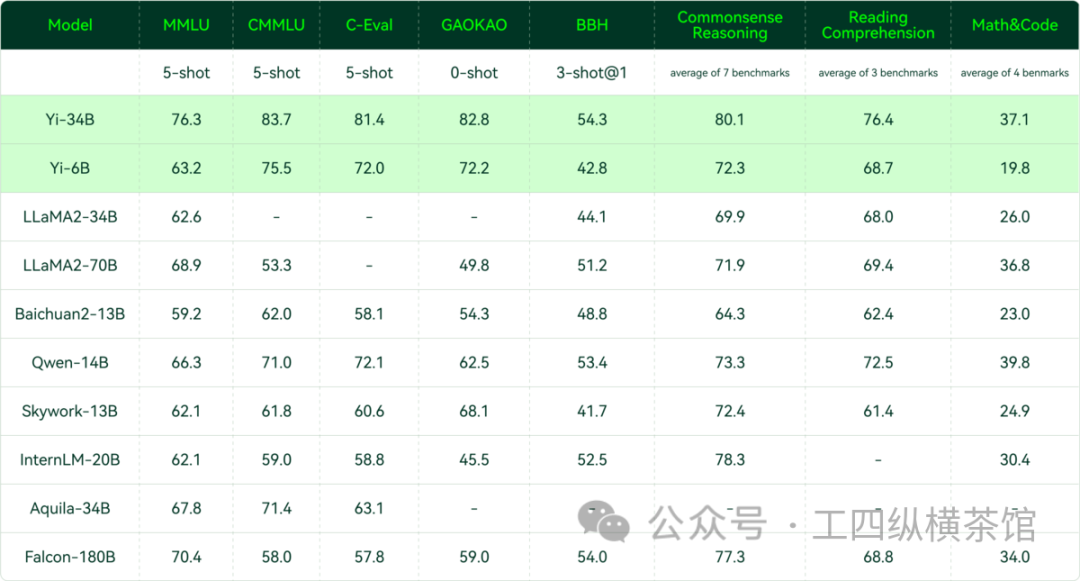
比如,在涵盖57个主题的MMLU基准测试中,Yi-34B的得分为76.3%,超过了其他开源模型,如Meta Platforms的LLaMA2-70B和TII的Falcon-180B分别为68.9%和70.4%。透明且免费的开源模型似乎受益于多样化的开发者团体的贡献,这些开发者团体持续为基础模型做出贡献。
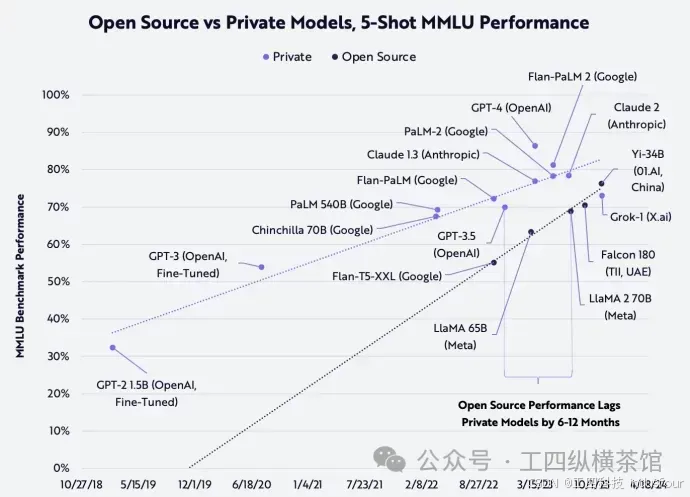
ARK的研究证实,私有和开源模型之间的性能差距正在缩小,如下所示。虽然OpenAI的GPT-4仍然优于所有其他竞争对手,但下面的趋势线表明,开源模型正在赶超,并且可能仅在几个月内赶上更昂贵、私有、闭源模型的性能。
02
为什么要关注及使用AI
小投入大回报: 通过采用AI智能,尤其是开源模型,企业可以以较小的投入获取最大的回报。免费获取先进技术、避免重复研发、利用社区支持等都为企业提供了经济高效的方式应用人工智能。
提高业务效率: 使用AI模型可以自动化和优化多个业务流程,从而提高整体业务效率。这包括自动化决策、预测分析、自动化生产等方面。
加速创新:通过使用先进的开源模型,企业能够更快地推出新产品或服务,促使创新,从而在市场上保持竞争优势。
03
算力资源效能最大化
要实现AI智能, GPU算力必不可少, 如何高效利用算力降本增效不可忽视。
加速训练和推理:GPU在深度学习任务中能够显著提高计算速度,通过GPU算力的池化和虚拟化,企业可以更有效地利用这些资源来加速模型的训练和推理。
智能分配算力:通过智能分配算力,企业可以根据不同任务的需求,动态调整GPU资源的分配。这样可以避免资源浪费,确保算力的高效利用。
弹性适应性:GPU算力池化使企业能够弹性地应对计算需求的波动。在需要处理大规模任务时,可以动态调配更多的GPU资源,而在需求减少时则可以释放这些资源,减少成本。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









