






要了解哈夫曼树,首先要了解哈夫曼树的几个概念:
路径和路径长度
在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1。
结点的权
若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权
哈夫曼树的定义
带权路径长度是从根节点到该节点路径的长度与该节点权值乘积,树的带权路径长度是所有叶子节点的带权路径长度之和(WPL),WPL最小的就是哈夫曼树
如何构建哈夫曼树
以下面节点为例
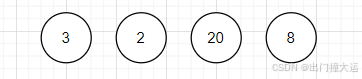
1、将待构建哈夫曼树的节点由小到大进行排序 2 、3 、8 、20
2、取出根节点权值最小的两个二叉树 2 、3
3、组成一棵新的二叉树,新的二叉树根节点的权值为前两个二叉树根节点权值之和
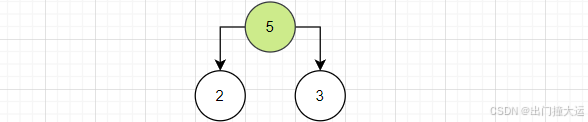
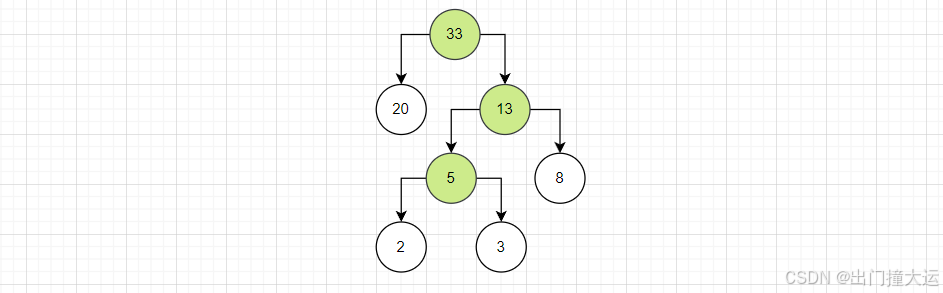
4、将这个二叉树以根节点权值大小再次进行排序,重复1234直到所有的数据都被处理
就得到一棵哈夫曼树
哈夫曼编码
发送信息 i like bananas ——> 二进制0101010101110010(ASCII码)(定长编码)
14(字符)* 8(位)= 112(位)
占用位数太多,需要进行数据压缩(变长编码)
人为去给字符设置编码,容易和其他编码的前缀相同而造成歧义,所以用到哈夫曼编码
哈夫曼编码创建过程
步骤 1:统计频率
首先,你需要统计每个符号(字符或数据块)在待编码数据中出现的频率。假设我们有以下字符及其频率:
| 字符 | 频率 |
|---|---|
| i | 2 |
| l | 1 |
| k | 1 |
| e | 1 |
| b | 1 |
| a | 3 |
| n | 2 |
| s | 1 |
| 空格 | 2 |
步骤 2:创建初始节点
将每个字符和其对应的频率作为节点,放入一个优先队列(或最小堆),根据频率进行排序。初始的节点如下:
i(2), l(1), k(1), e(1), b(1), a(3), n(2), s(1),空(2)
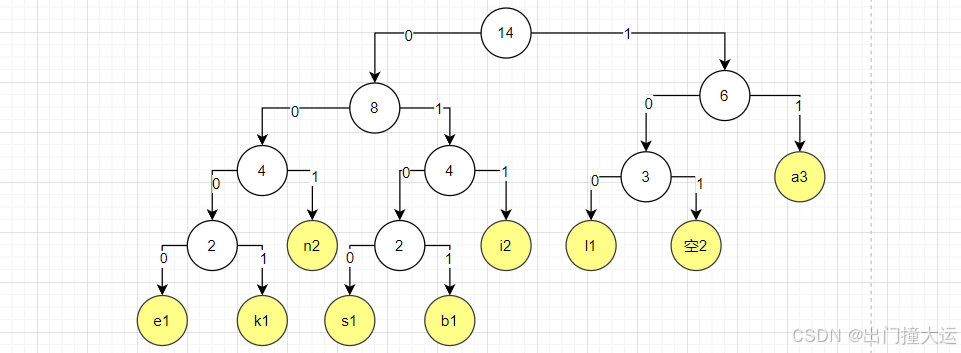
步骤 3:构建哈夫曼树
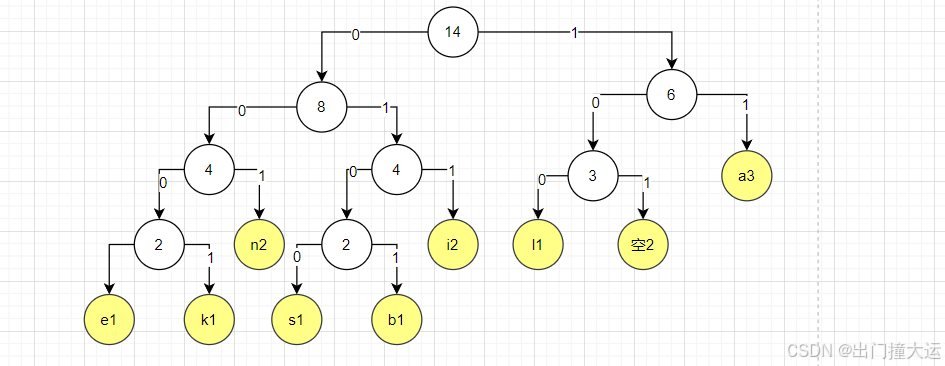
步骤 4:生成哈夫曼编码
从哈夫曼树的根节点出发,给每个左边的分支标记为 0,右边的分支标记为 1,直到到达每个叶子节点。对应的编码如下:
i: 011l: 100k: 0001e: 0000b: 0101a: 11n: 001s: 0100空:101
步骤 5:编码数据
i: 011l: 100k: 0001e: 0000b: 0101a: 11n: 001s: 0100空:101
使用生成的哈夫曼编码替换原始数据中的字符。例如,字符串 "i like bananas" 可以编码为:
0111011000110001000010101011100111001110100
步骤 6:解码
在解码时,可以利用哈夫曼树,逐位读取编码,按照树的分支方向向下走,直到到达一个叶子节点,再返回到根节点,重复该过程直到整个编码被解码完。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









