






什么是 PostgreSQL?
PostgreSQL 是一个开源的对象关系型数据库管理系统,以其强大的功能、稳定性和扩展性著称。它支持标准 SQL 以及各种高级特性,如事务处理、外键、触发器、视图和多版本并发控制(MVCC)。PostgreSQL 的设计目标是提供高性能和可靠性,使其成为处理大规模数据和复杂查询的理想选择。
————————————————
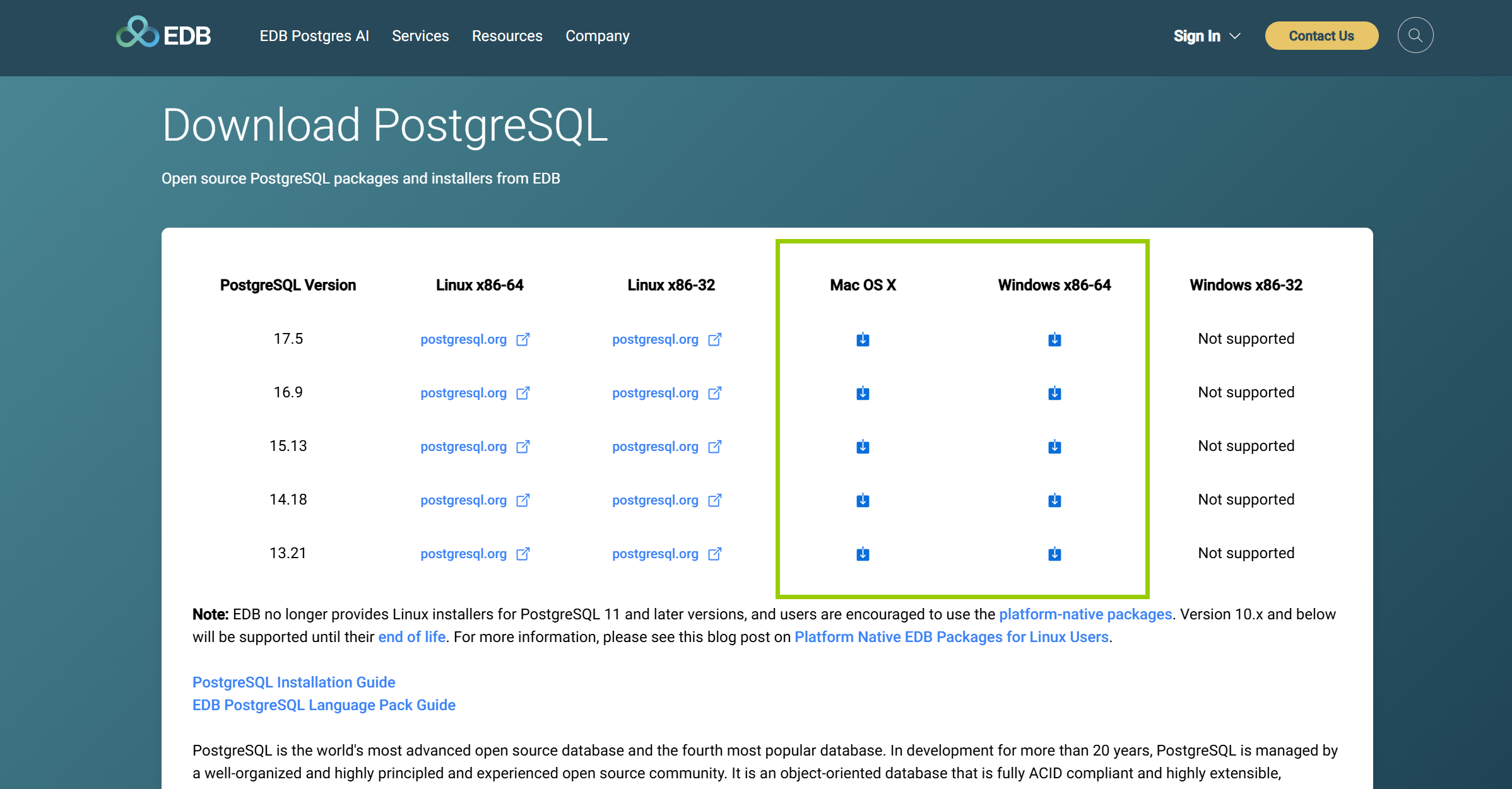
下载网址
EDB: Open-Source, Enterprise Postgres Database Management
安装过程
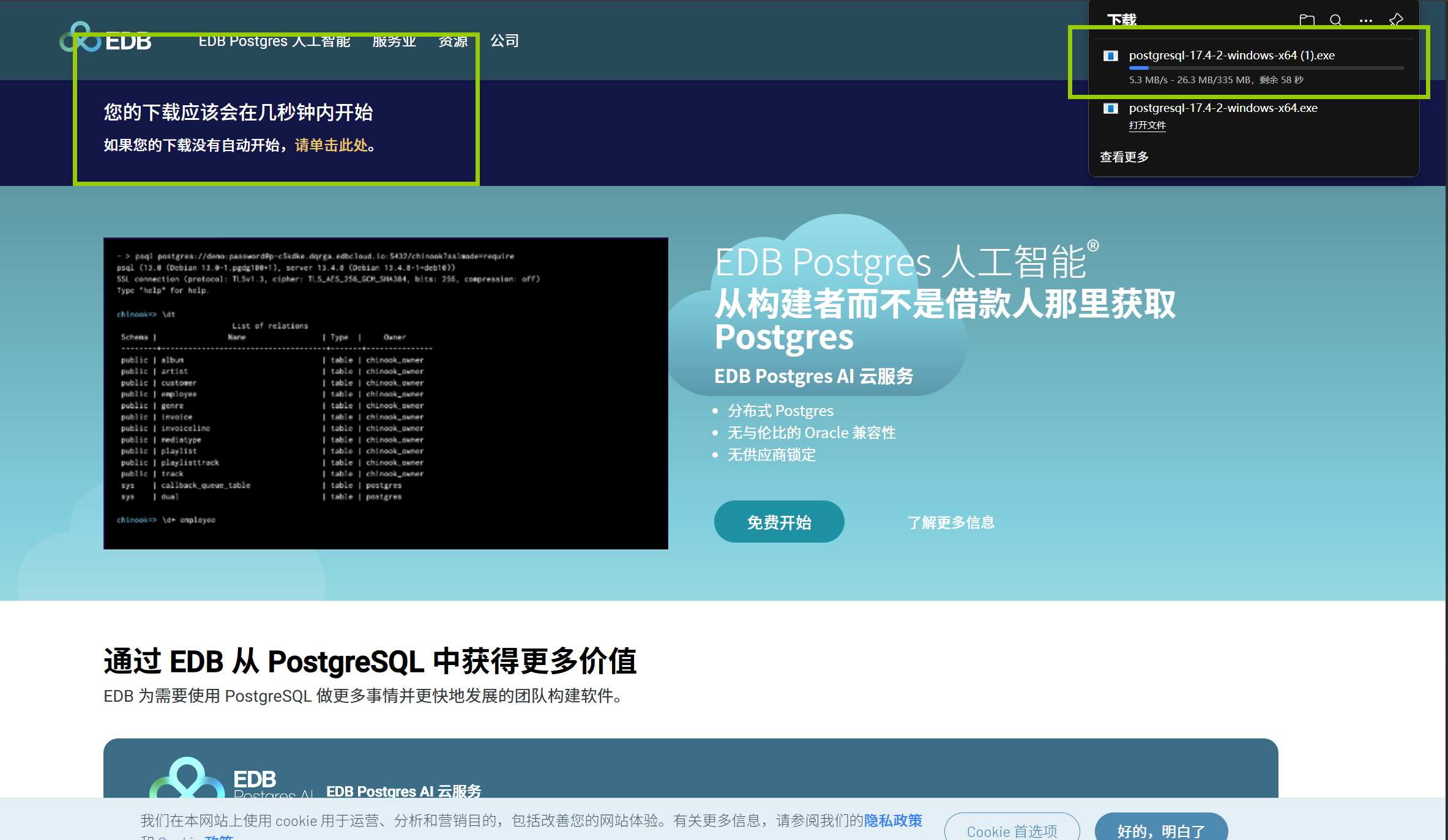
点击后会出现这个:
双击安装
在弹出的setup窗口中点击 Next

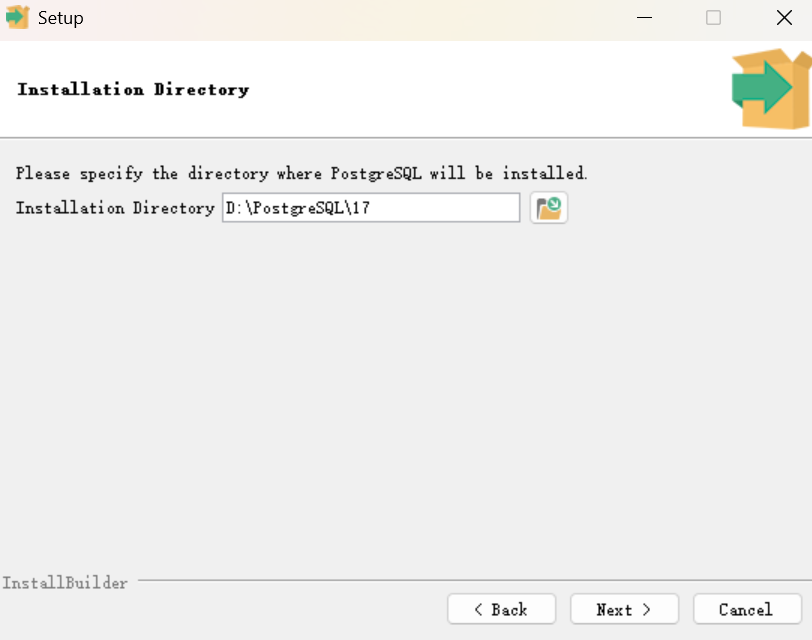
然后自定义文件的安装路径(建议修改除C盘以外的盘符,除非只有C盘)
这里它默认勾选了四个安装插件,默认全选,直接点击 Next
此处的路径为PostgreSQL的数据库存放位置,点击下一步 ->next
当修改前一步的安装路径后,它会自动更改,所以这里我们不需要额外操作。
(此处的默认路径在原来的路径基础上新建了一个data的文件夹用于存放数据库)
接下来对数据库进行用户密码设置,完成后点击 ->next
(可以更改,如果设置别的自己务必记住)
这里的Port是指PostgreSQL的默认端口号:5432,直接点击下一步 ⇒next
此处是设置语言,不建议修改为chinese/简体中文,可能会报错!点击下一步 ⇒next
最后这里将预览文件路径及数据库信息,直接点击下一步 ⇒next
安装程序现在已准备好开始在您的计算机上安装PostgreSQL。
等待安装完成后在弹出的界面取消勾选Stack Builder,然后点击Finish关闭窗口。
Stack Builder是PostgreSQL的一个实用工具,提供了可视化界面,可以根据自己的情况进行安装。
这里先不安装,后续如果想安装可在
这里不运行后续有需要再弄(以下两张图是后续的)
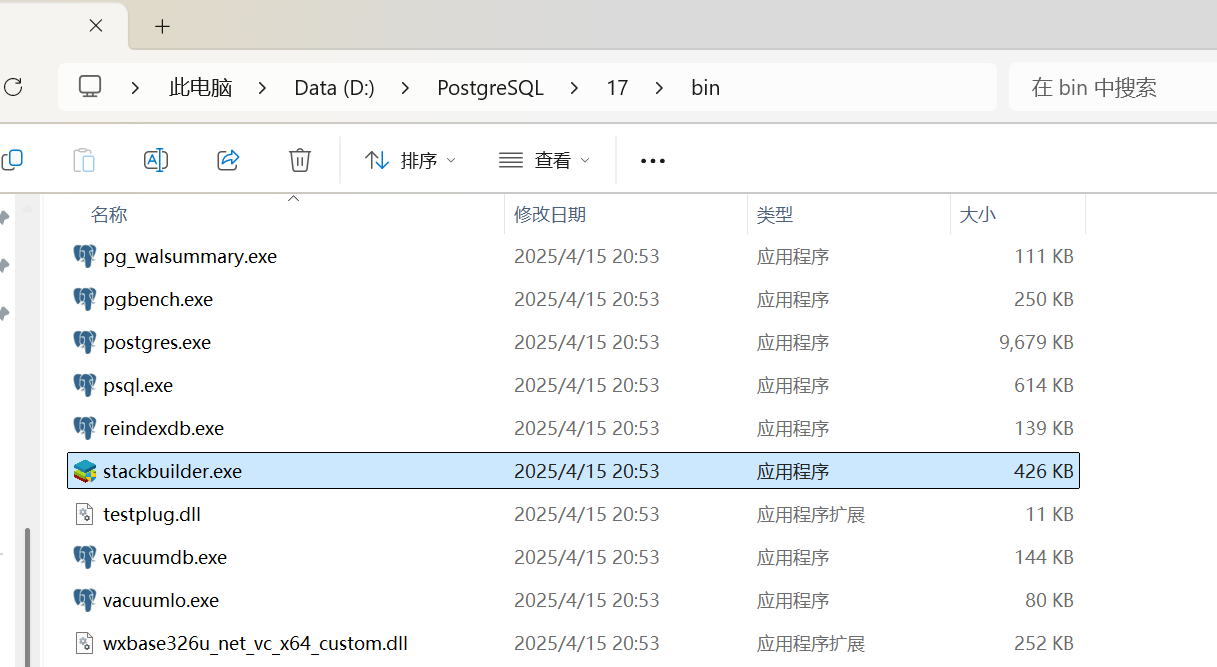

环境变量
1.设置Path变量:
- 首先复制PostgreSQL的
bin路径; - 打开设置搜索
高级系统设置,然后点击高级系统设置,再点击环境变量,在系统变量中找到Path变量; - 选中
Path变量,点击编辑,然后点击新建,将复制好的bin路径复制进去,最后点击三个确定。
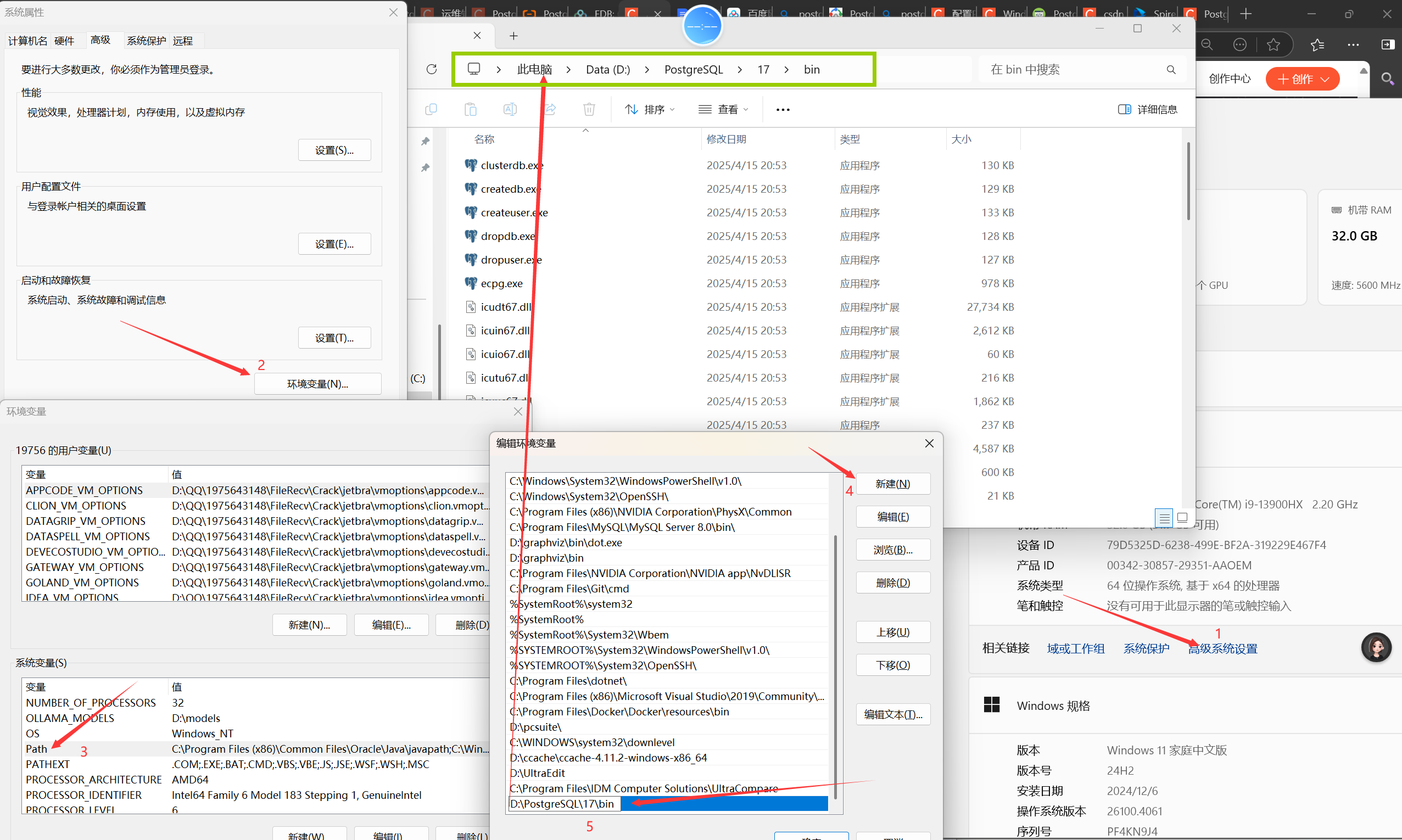
2.设置PG_HOME变量:
- 首先复制PostgreSQL文件的安装路径,即在安装step3的第二步时选择的路径,我的是
D:\PostgreSQL\17;
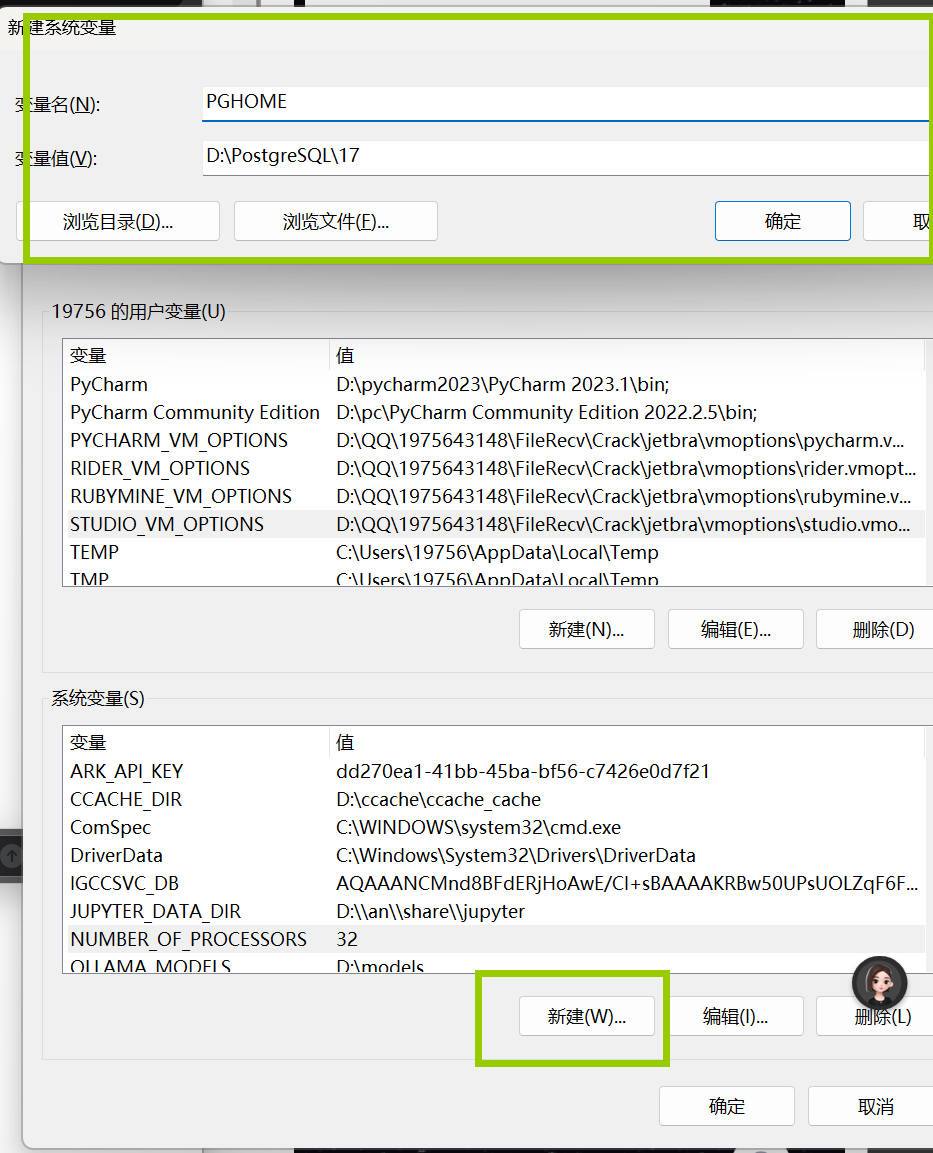
PGDATA
自此,PostgreSQL的环境变量已成功配置完成!
services.msc
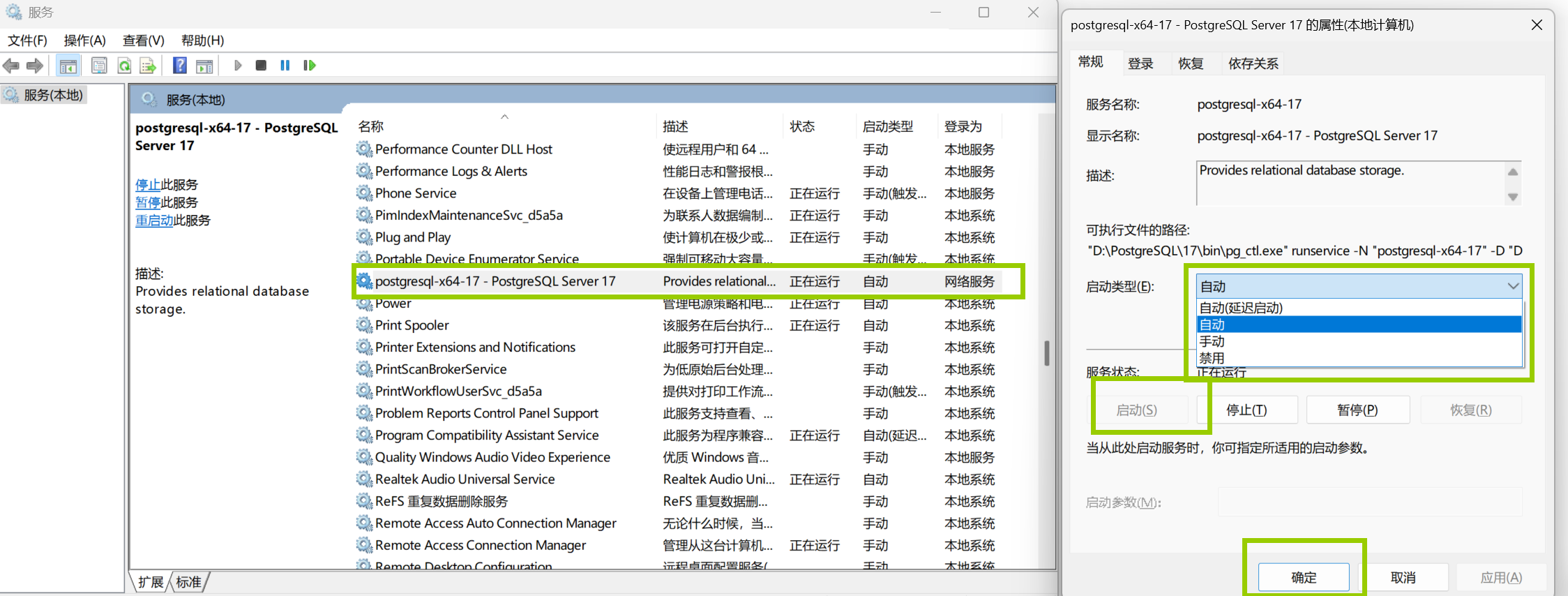
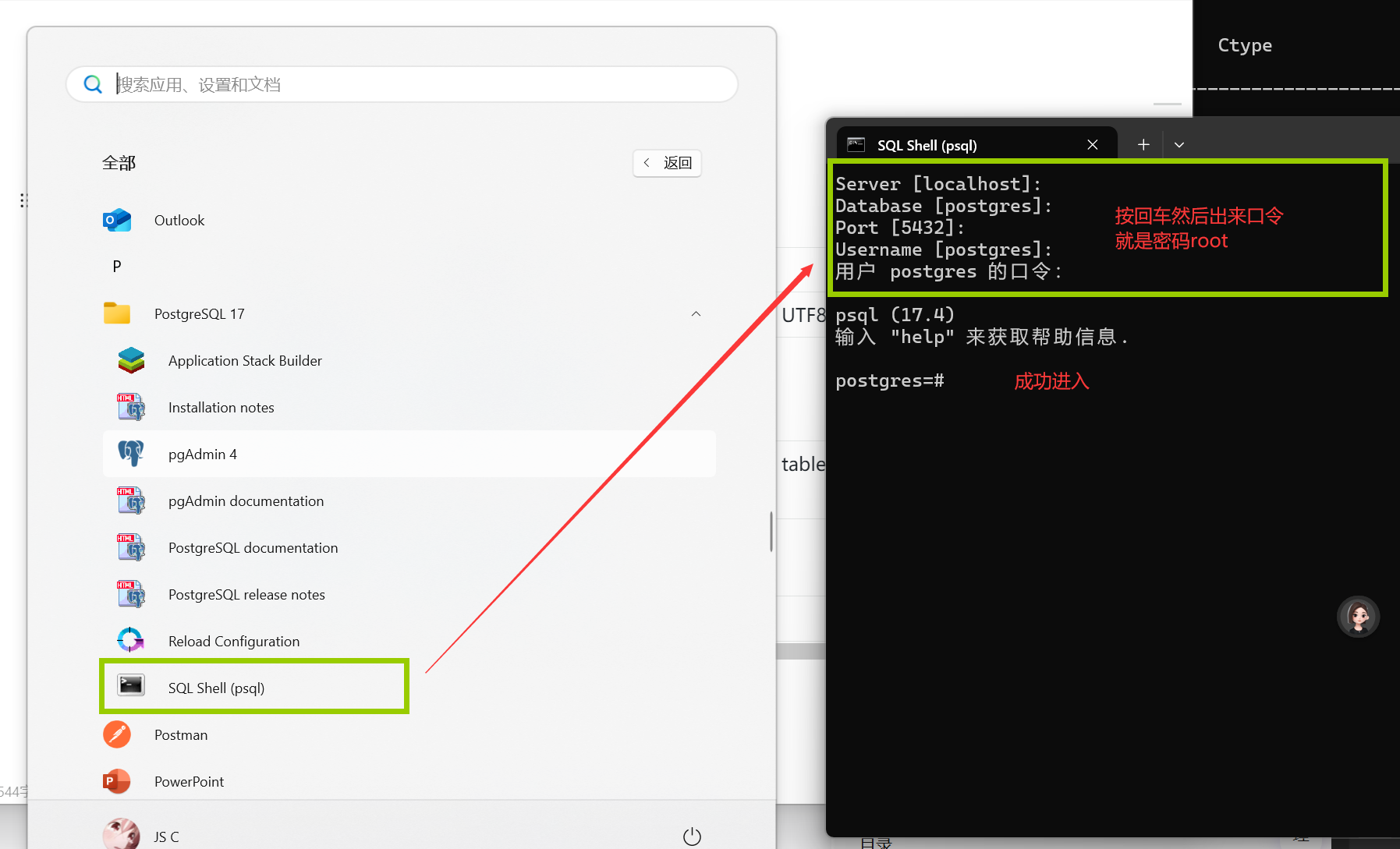
尝试登录PostgreSQL
1.打开dos命令窗(快捷键:Win + R)
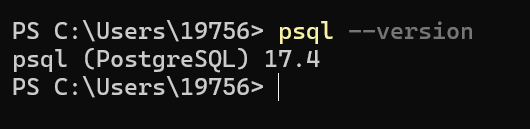
psql --version
2.上面的services.msc这个页面启动了这里就不需要在启动了除非它提示没启动
在打开的dos命令窗口中启动数据库指令pg_ctl start,输入及执行结果如下:
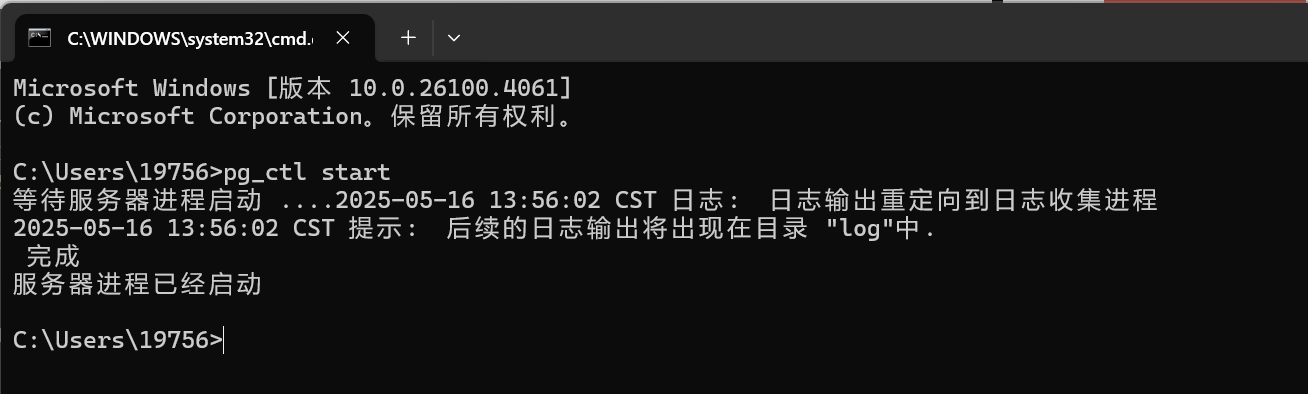
3.启动成功后接下来可以输入登录指令(若启动不成功可以尝试以管理员身份运行dos窗口)
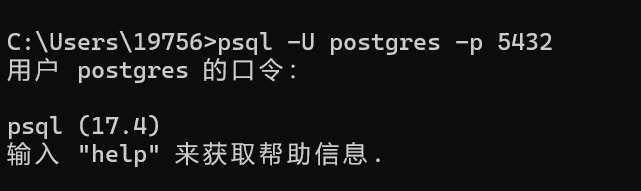
登录指令格式为:psql -U 用户名 -d 数据库名 -h 主机地址 -p 5432;登录成功后如下所示:
# 基础登录(默认用户 postgres,默认数据库 postgres)
psql -U 用户名 -d 数据库名 -h 主机地址 -p 端口
运行这个:psql -U postgres -p 5432
| 命令 | 说明 | 示例输出片段 | ||
|
| 列出所有数据库 | `mydb \ | myuser \ | UTF8` |
|
| 切换数据库 |
| ||
|
| 列出当前数据库的所有表 | `public \ | users \ | table` |
|
| 查看表结构详情 | 列名、类型、约束等信息 | ||
|
| 退出 psql | - |
psql (17.4)
输入 "help" 来获取帮助信息.
postgres=# \l
# 创建库
postgres=# create database student;
postgres=# \l
# 删除库
postgres=# drop database student;
postgres=# \l
CREATE SEQUENCE users_id_seq; -- 创建序列
CREATE TABLE users (
id INT DEFAULT nextval('users_id_seq'), -- 使用序列作为默认值
name VARCHAR(100),
age INT,
email VARCHAR(255)
);
-- 插入数据时不需要显式指定 id
INSERT INTO users (name, age, email)
VALUES ('John Doe', 30, 'johndoe@example.com');
-- 查询语句
SELECT * FROM users;- Create (插入数据)
插入数据使用 INSERT INTO 语句。假设我们有一个 users 表,其中包括 id、name、age 和 email 字段:
-- 插入单行数据
INSERT INTO users (name, age, email)
VALUES ('John Doe', 30, 'johndoe@example.com');
-- 插入多行数据
INSERT INTO users (name, age, email)
VALUES
('Alice Smith', 25, 'alice.smith@example.com'),
('Bob Brown', 28, 'bob.brown@example.com');- Read (查询数据)
查询数据使用 SELECT 语句。可以通过指定列名、条件等来进行查询。
-- 查询所有数据
SELECT * FROM users;
-- 查询特定列
SELECT name, email FROM users;
-- 使用 WHERE 条件查询
SELECT * FROM users WHERE age > 25;
-- 查询前几行数据
SELECT * FROM users LIMIT 5;
-- 使用 LIKE 进行模糊查询
SELECT * FROM users WHERE email LIKE '%example.com';
-- 查询并排序
SELECT * FROM users ORDER BY age DESC;- Update (更新数据)
更新数据使用 UPDATE 语句,通过 SET 设置字段的新值,并使用 WHERE 来指定需要更新的行。
-- 更新单行数据
UPDATE users
SET age = 31
WHERE name = 'John Doe';
-- 更新单行数据
UPDATE users
SET email = 'bob.brown@newdomain.com'
WHERE name = 'Bob Brown';
-- 使用条件更新多个字段
UPDATE users
SET age = 32, email = 'alice.smith@newdomain.com'
WHERE name = 'Alice Smith';
- Delete (删除数据)
删除数据使用 DELETE FROM 语句。使用 WHERE 进行条件删除,如果不加 WHERE,则会删除所有记录。
-- 删除单行数据
DELETE FROM users WHERE name = 'John Doe';
-- 删除多行数据
DELETE FROM users WHERE age < 30;
-- 删除所有数据
DELETE FROM users; -- 警告:如果没有 WHERE 条件,将删除所有数据!
在同一数据库内切换表
要是你想在同一个数据库里对不同的表执行操作,并不需要专门的 “切换表” 命令。只需在 SQL 语句里直接指定表名就行,例如:
-- 查询表中的数据
SELECT * FROM table_name;
-- 向表中插入数据
INSERT INTO table_name (column1, column2) VALUES (value1, value2);
-- 更新表中的数据
UPDATE table_name SET column1 = value1 WHERE condition;
-- 删除表中的数据
DELETE FROM table_name WHERE condition;

图形管理界面的操作
5、使用 pgAdmin4 图形化创建和管理 PostgreSQL 数据库-CSDN博客
pgAdmin 4的安装与使用_pgadmin安装教程-CSDN博客
点击servers

从这里可以换语言(自带不用下载)
密码root(安装的时候设置的)
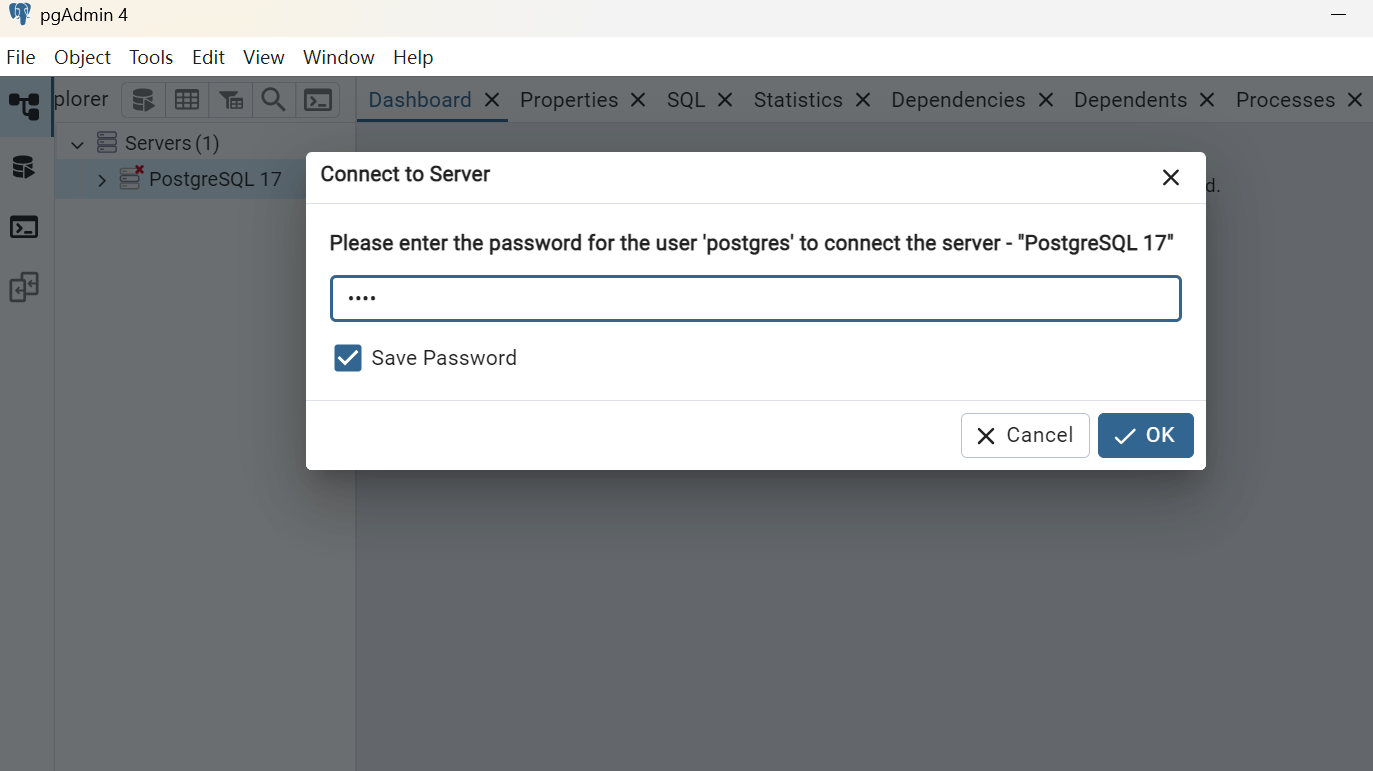
中文界面
登陆进去后就可以看到数据库的界面了。
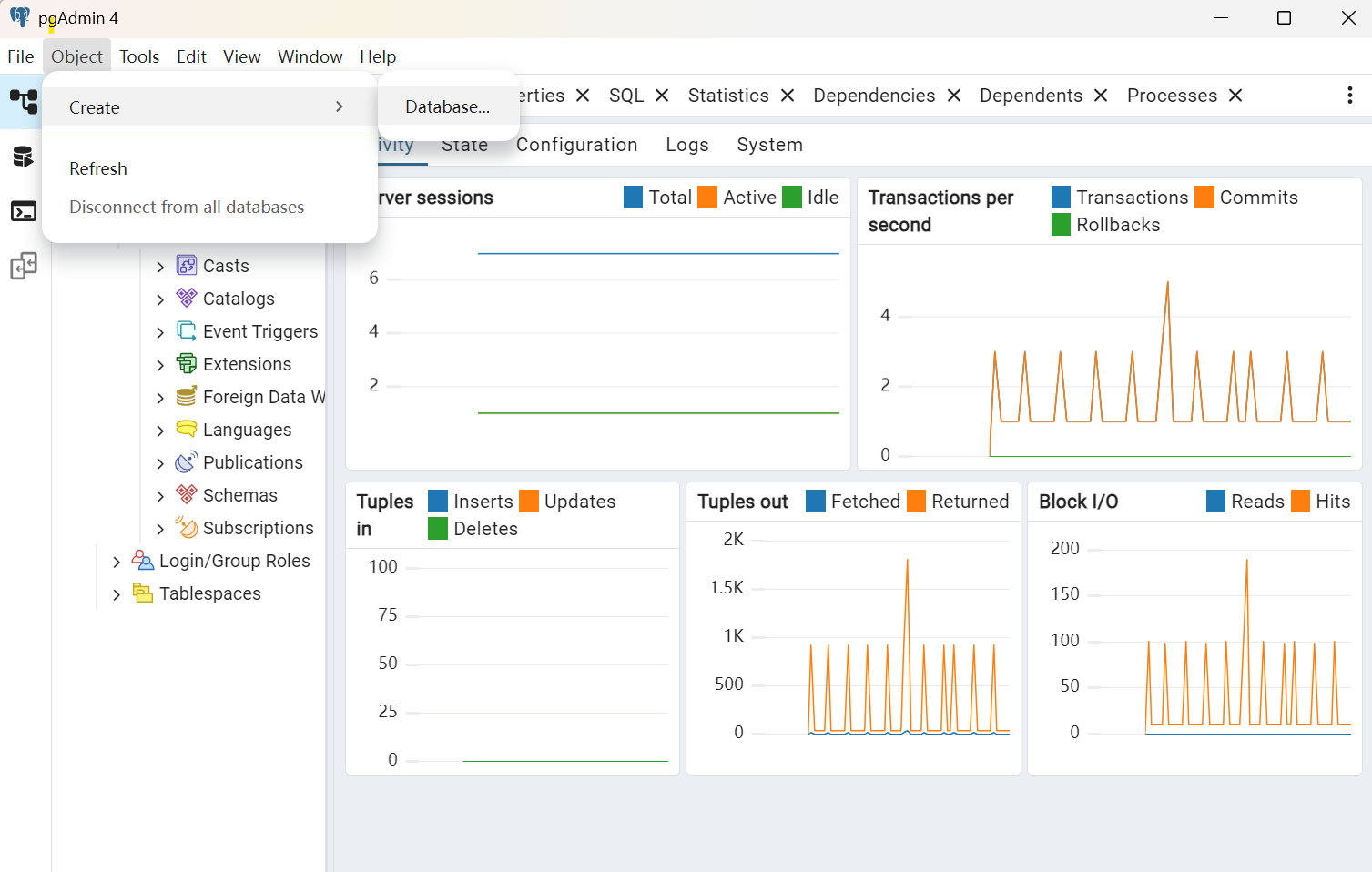
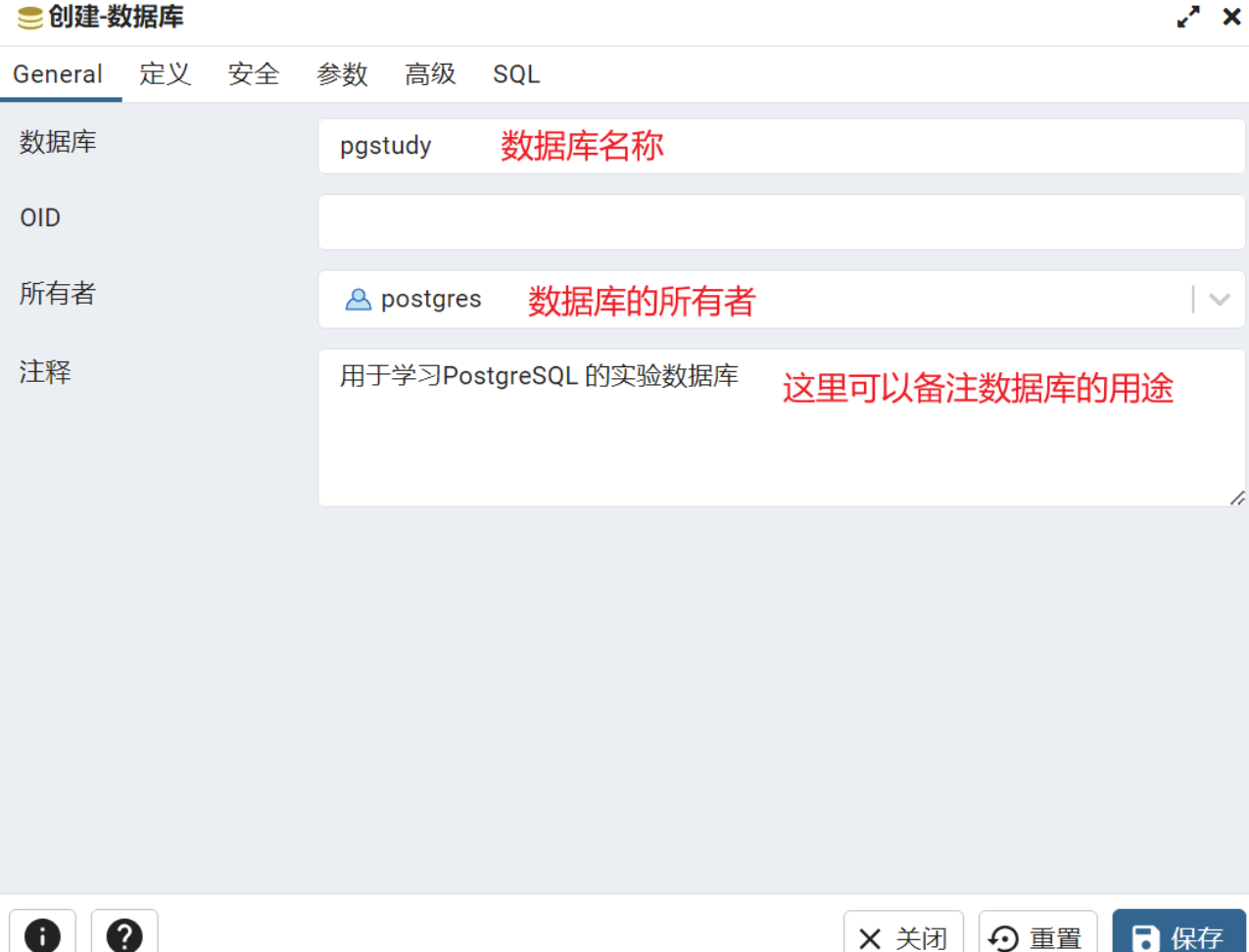
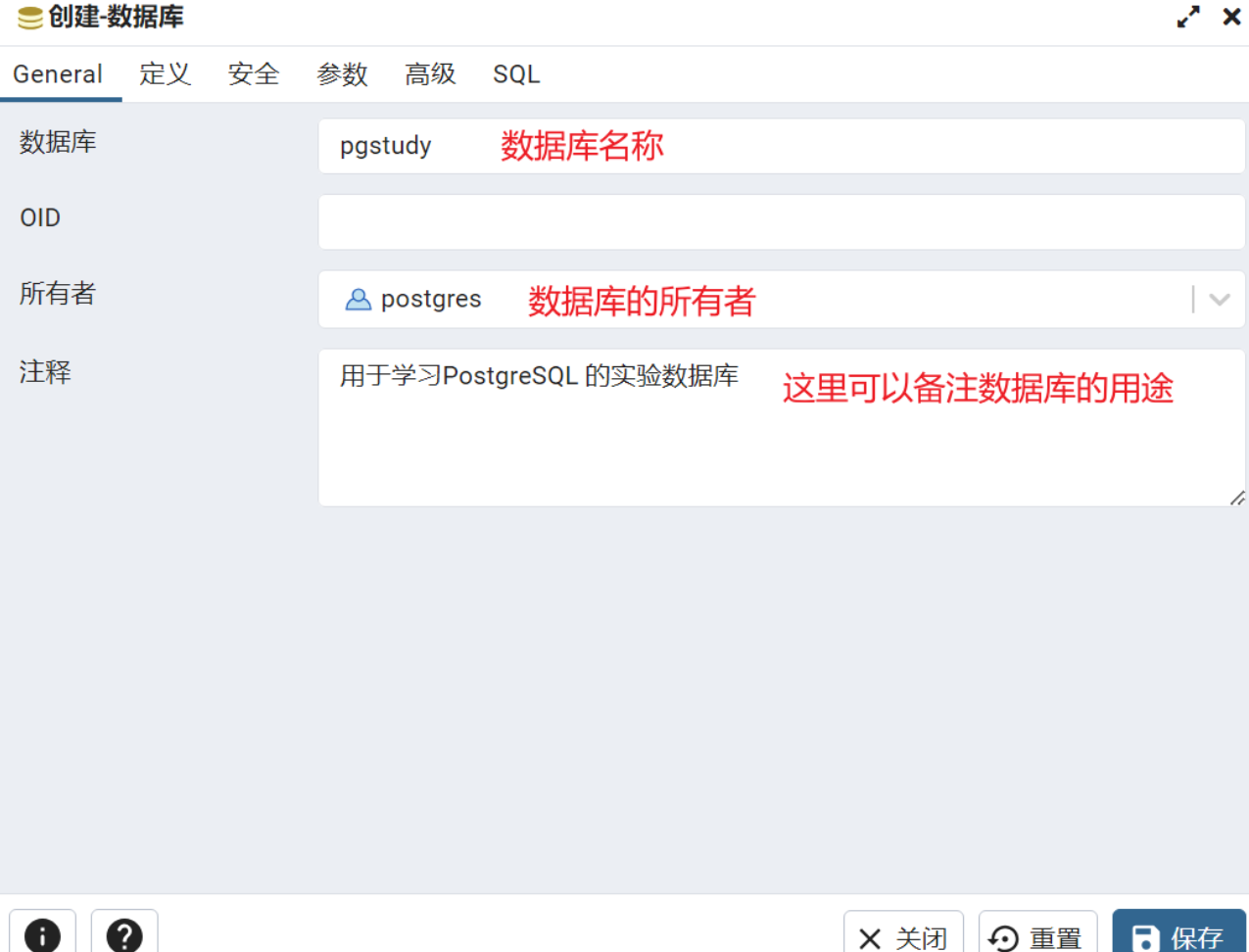
创建数据库 两种方法1.
新建数据库
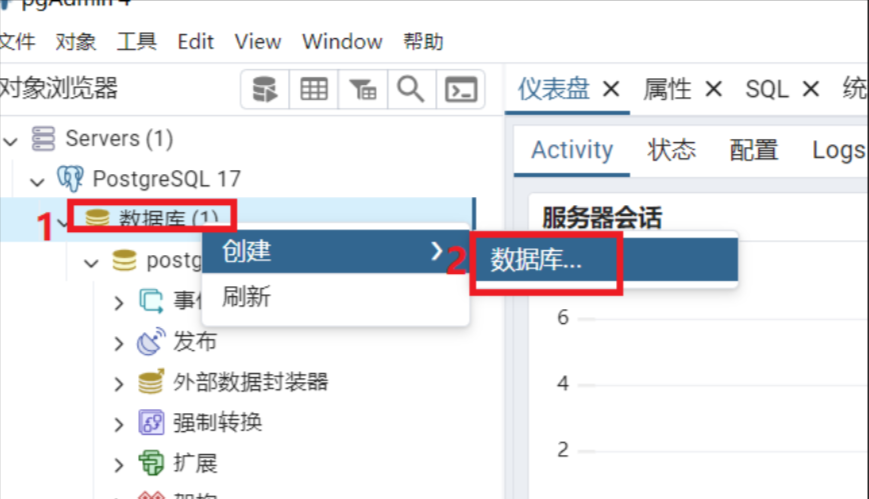
鼠标右键点击数据库,在弹出的菜单中选择数据库
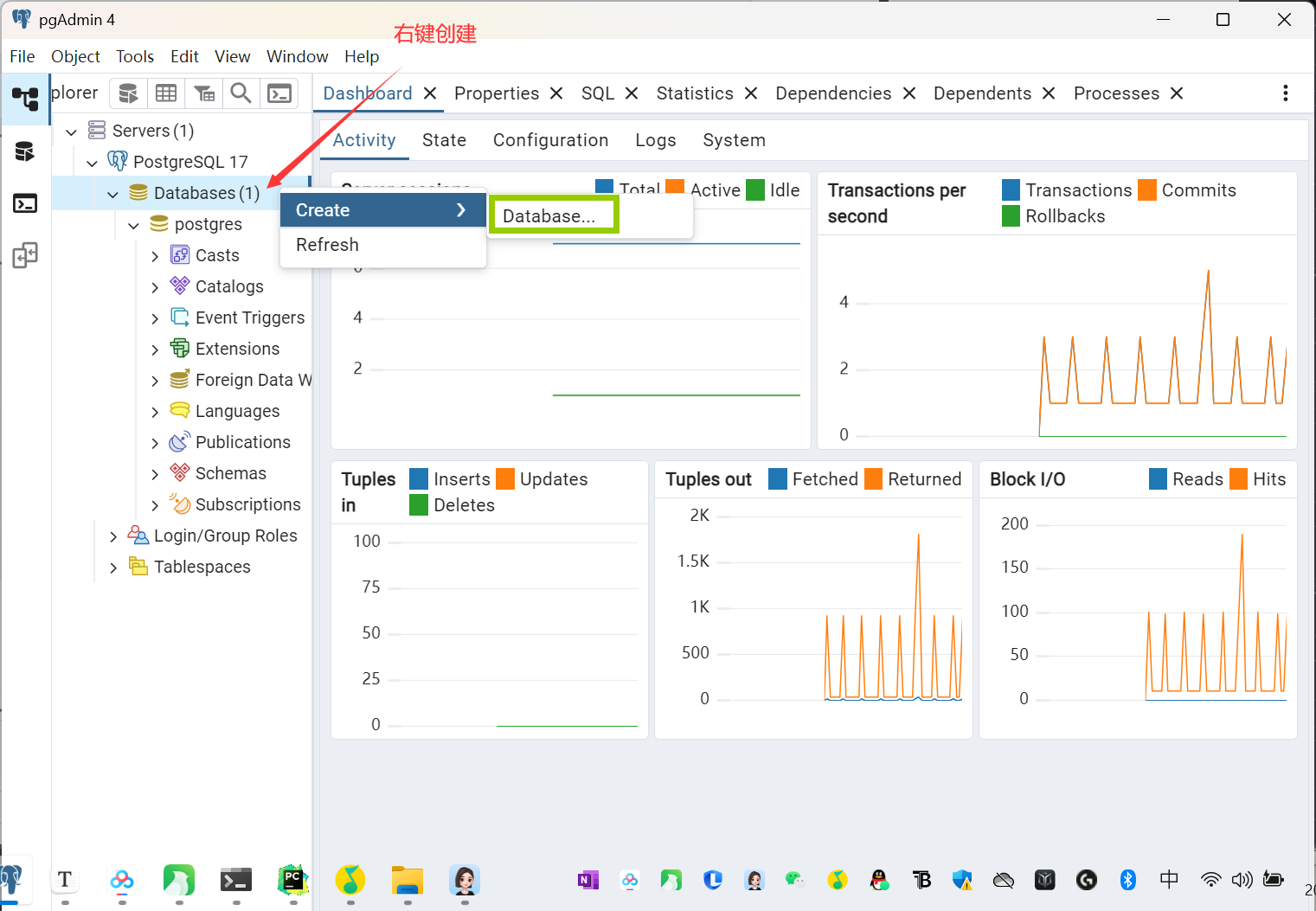
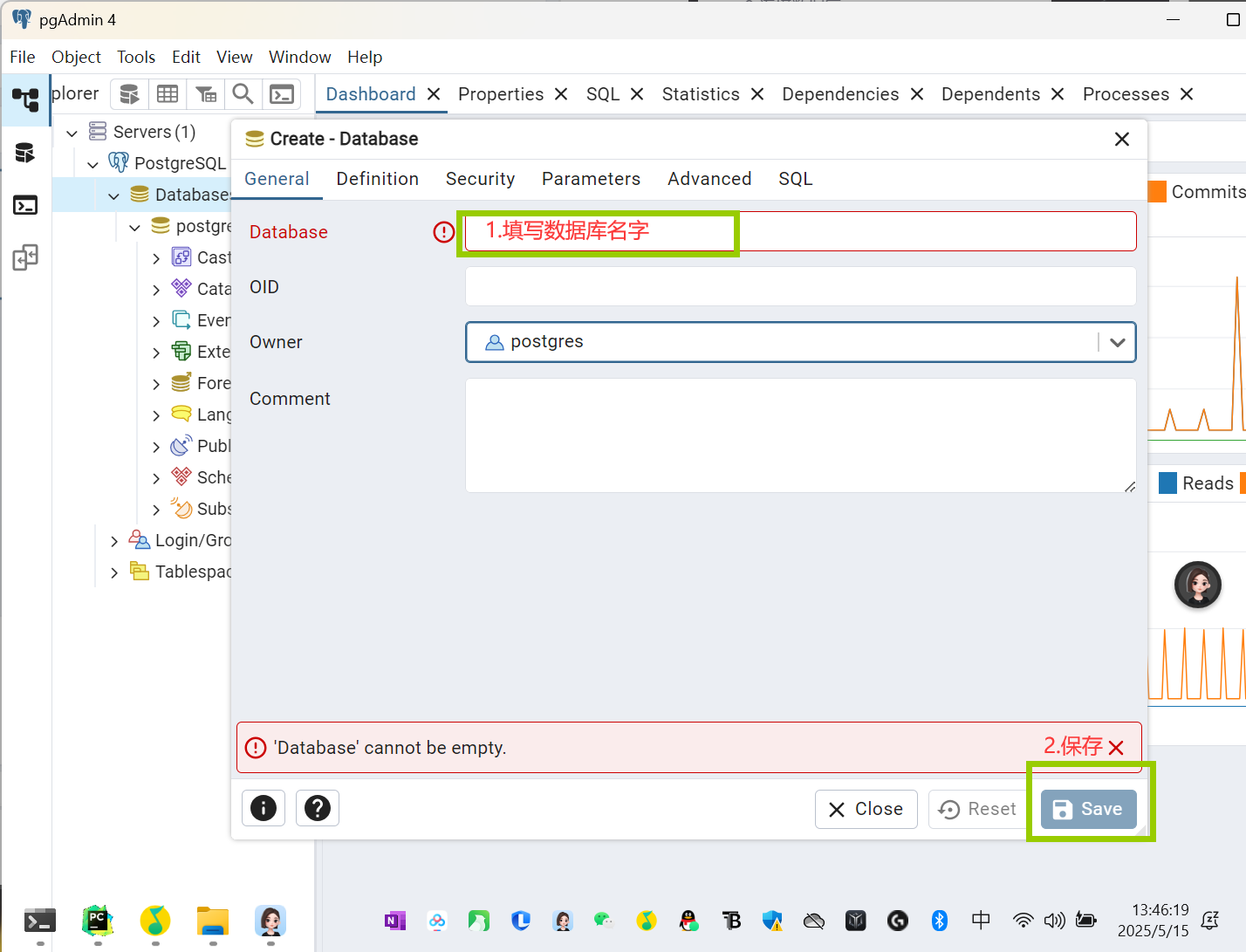
2.
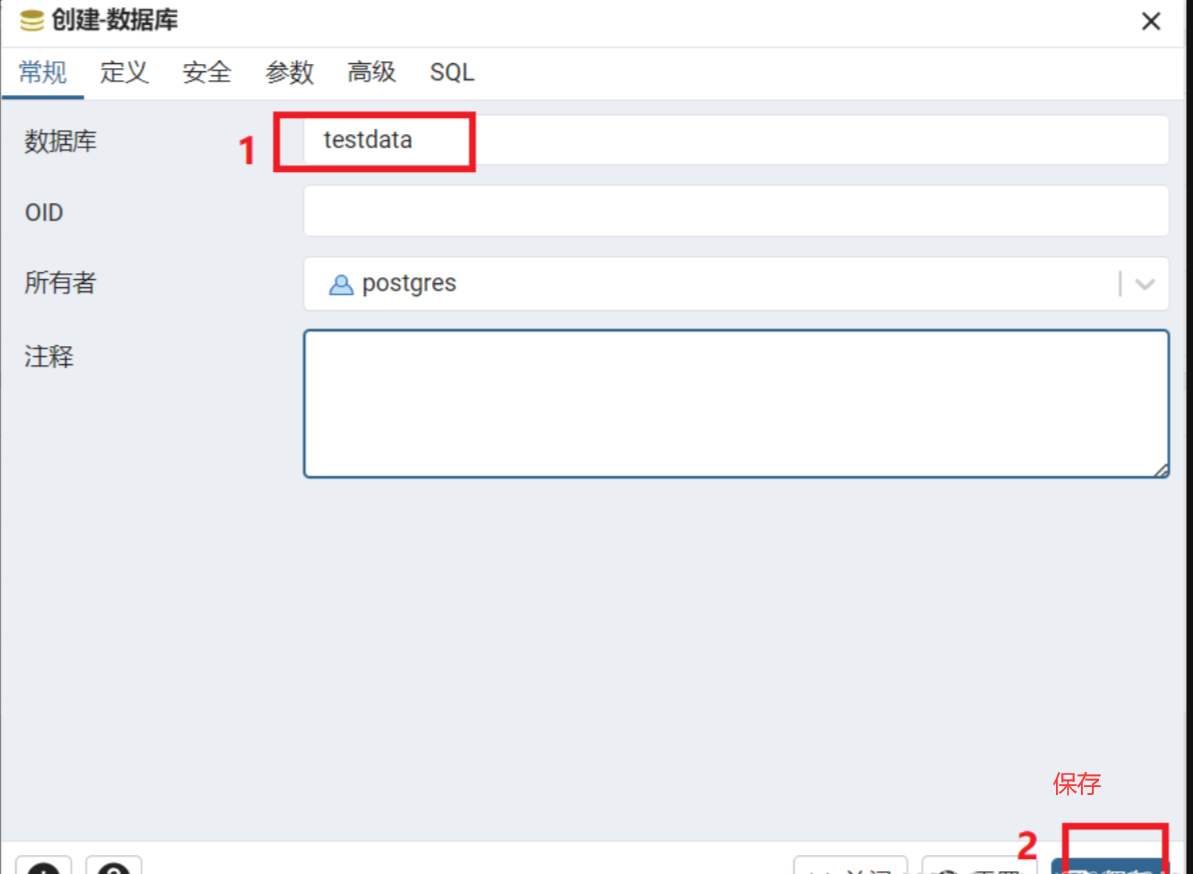
中文
中文
5.新建表
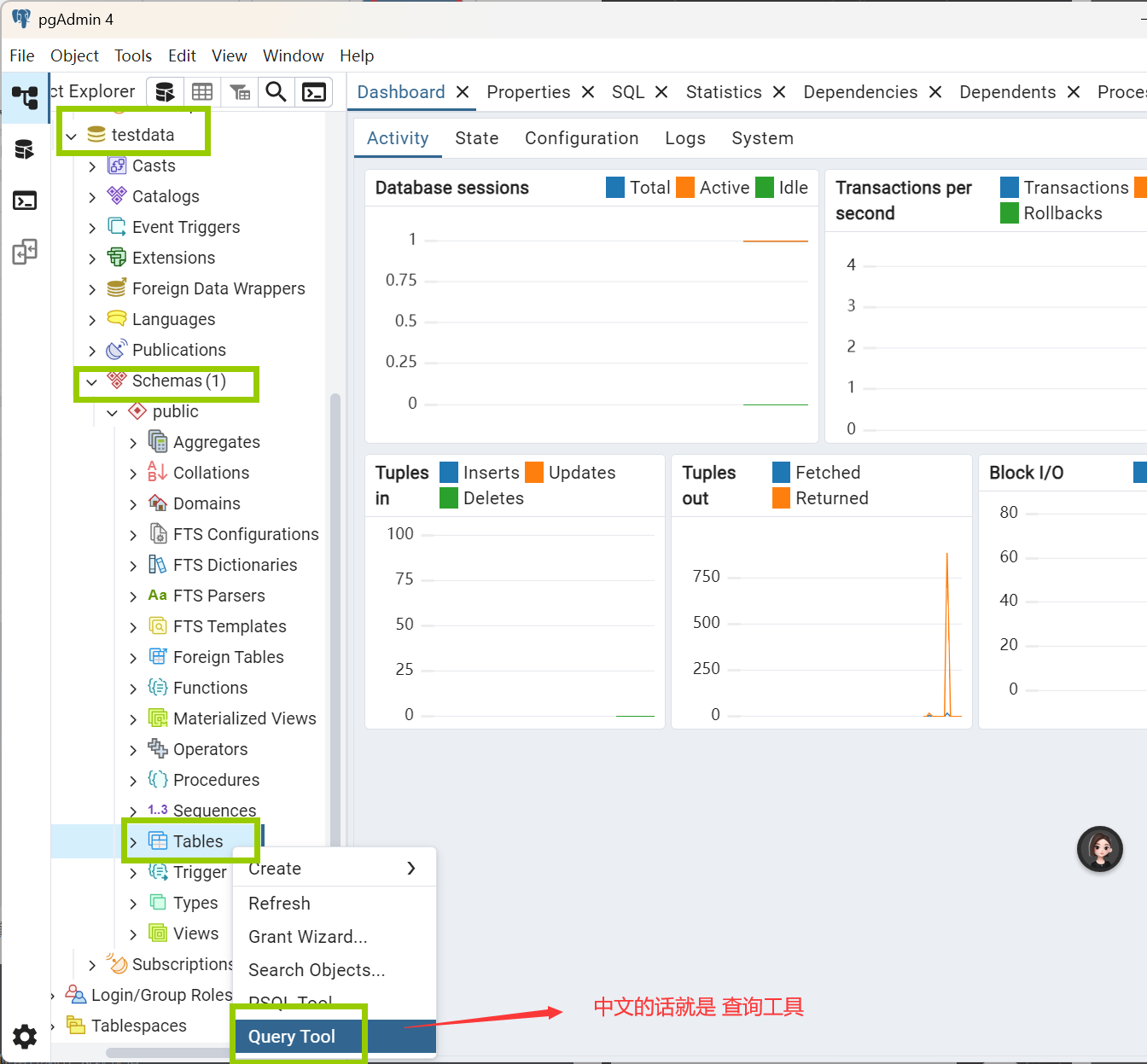
中文
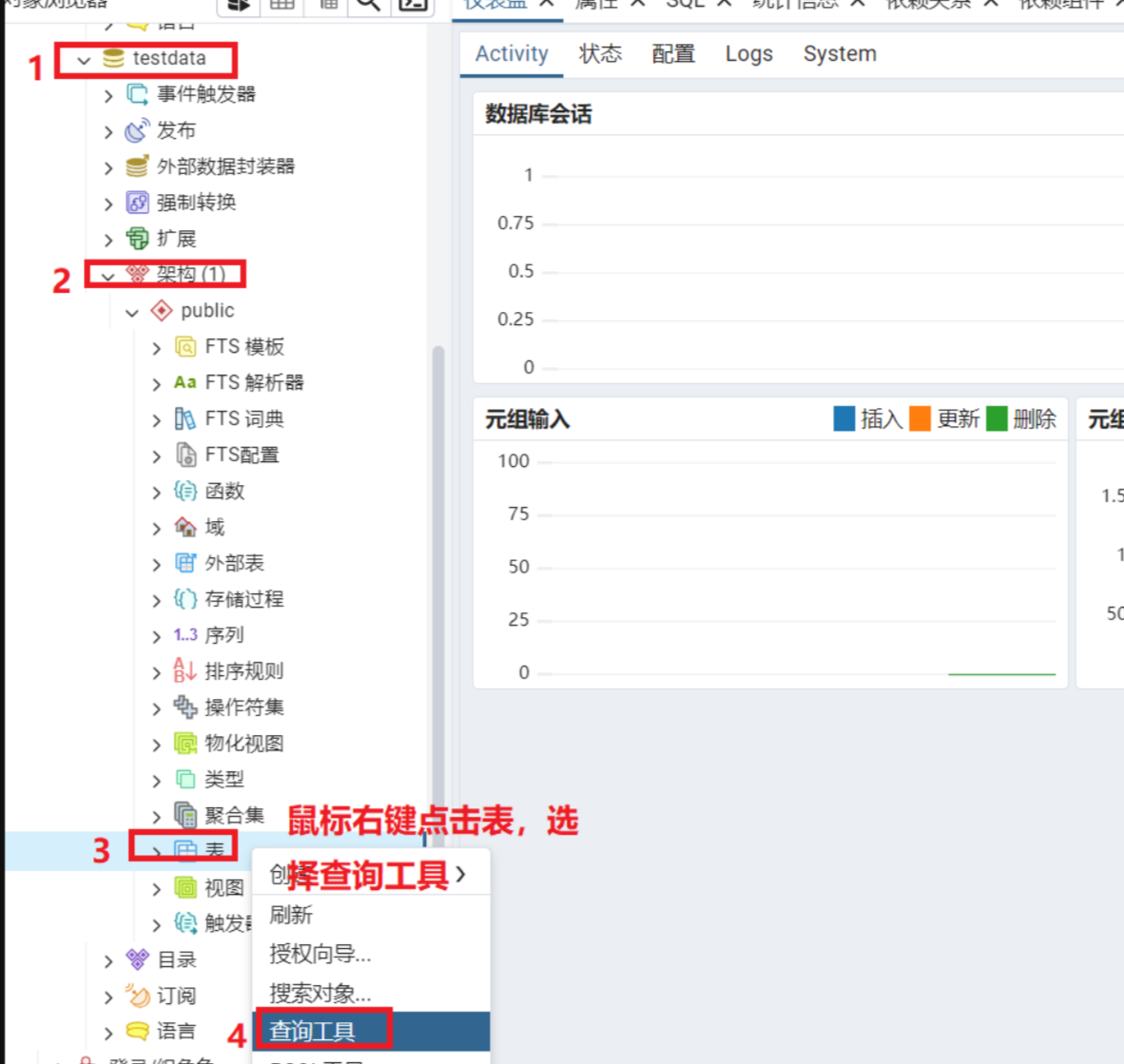
第1行为创建序列用于自增字段。3-8行为创建表,11-12行为插入演示数据
CREATE SEQUENCE users_id_seq; -- 创建序列
CREATE TABLE users (
id INT DEFAULT nextval('users_id_seq'), -- 使用序列作为默认值
name VARCHAR(100),
age INT,
email VARCHAR(255)
);
-- 插入数据时不需要显式指定 id
INSERT INTO users (name, age, email)
VALUES ('John Doe', 30, 'johndoe@example.com');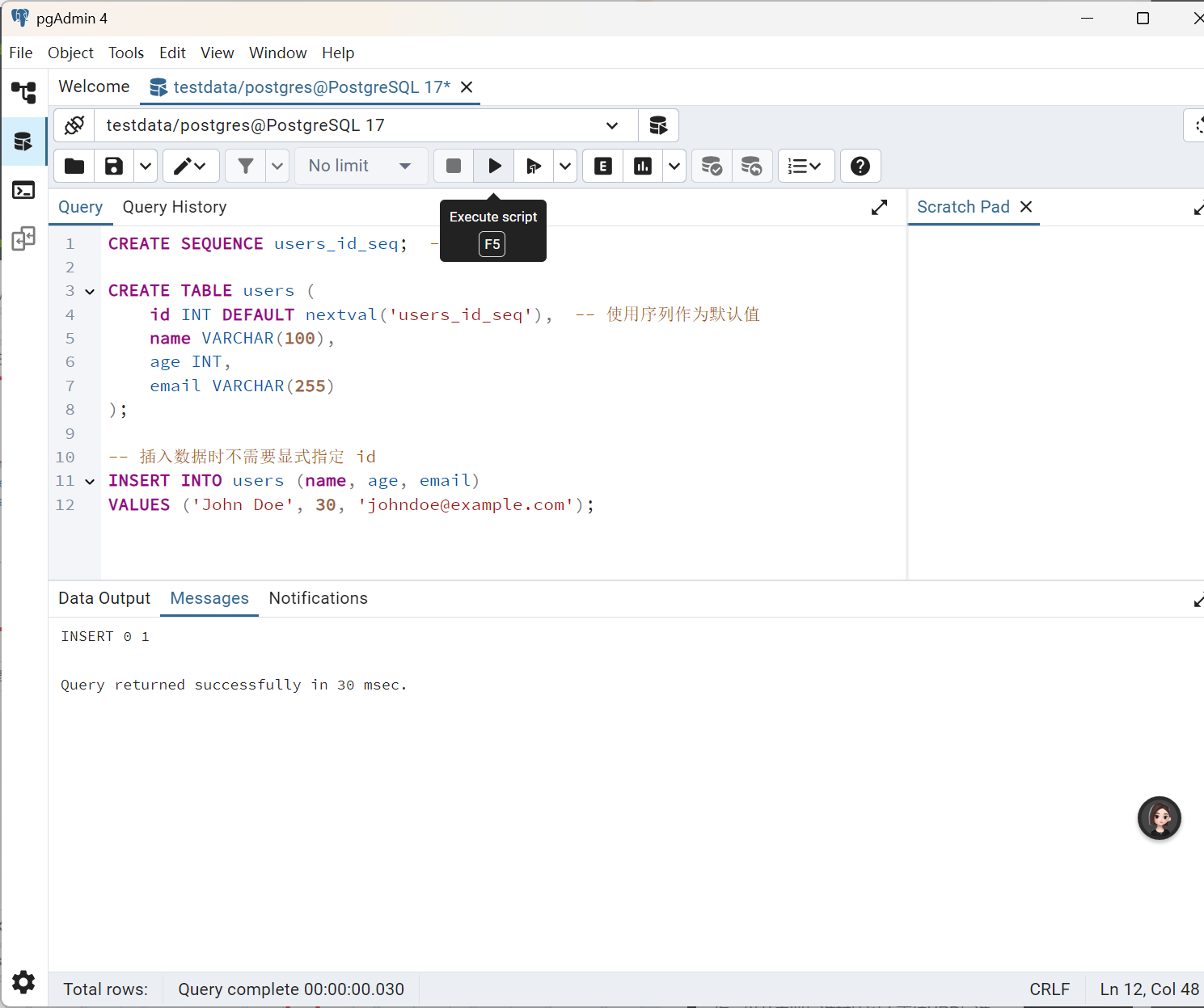
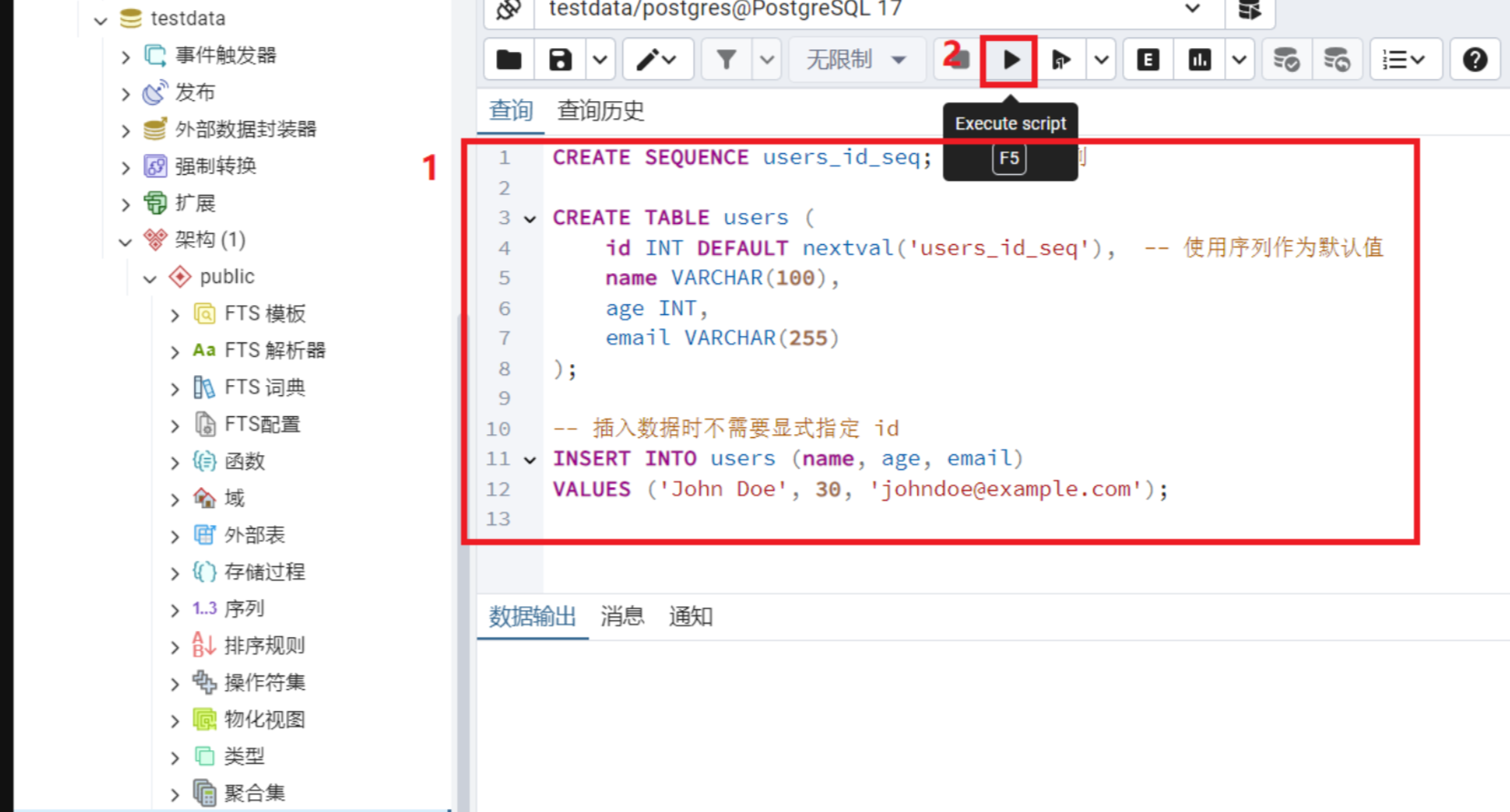
表已经建好,查询已经可以看到插入的数据
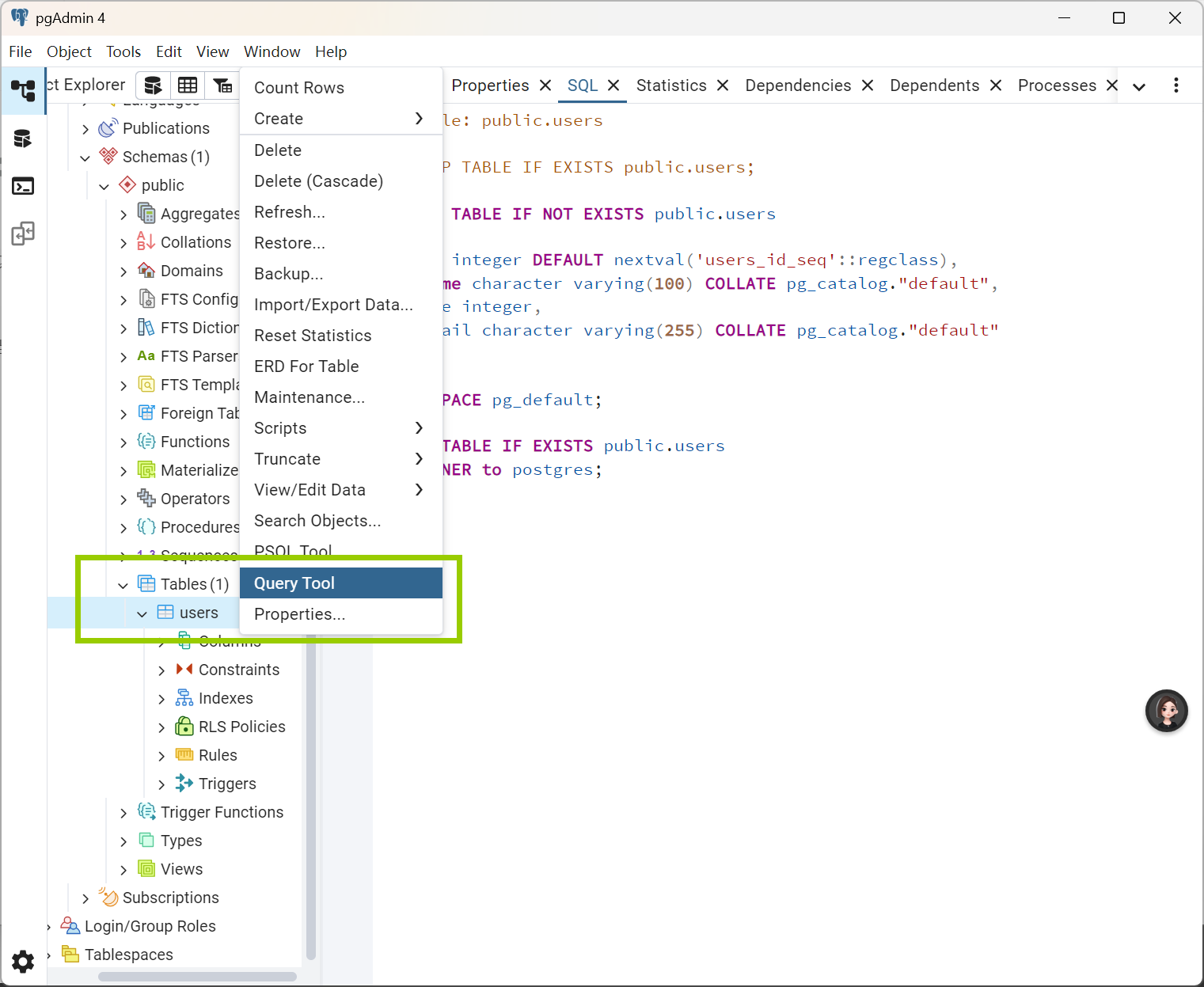
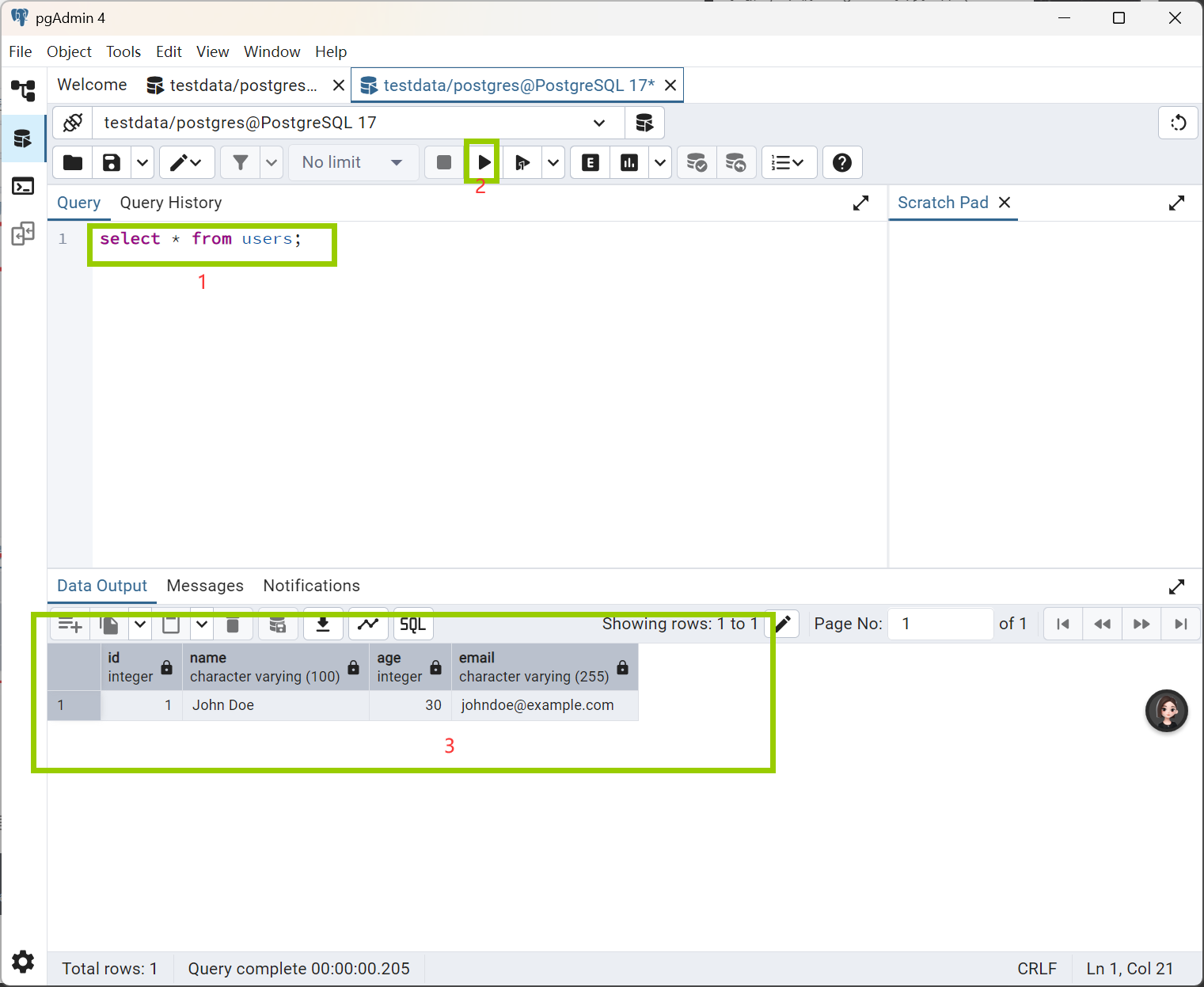
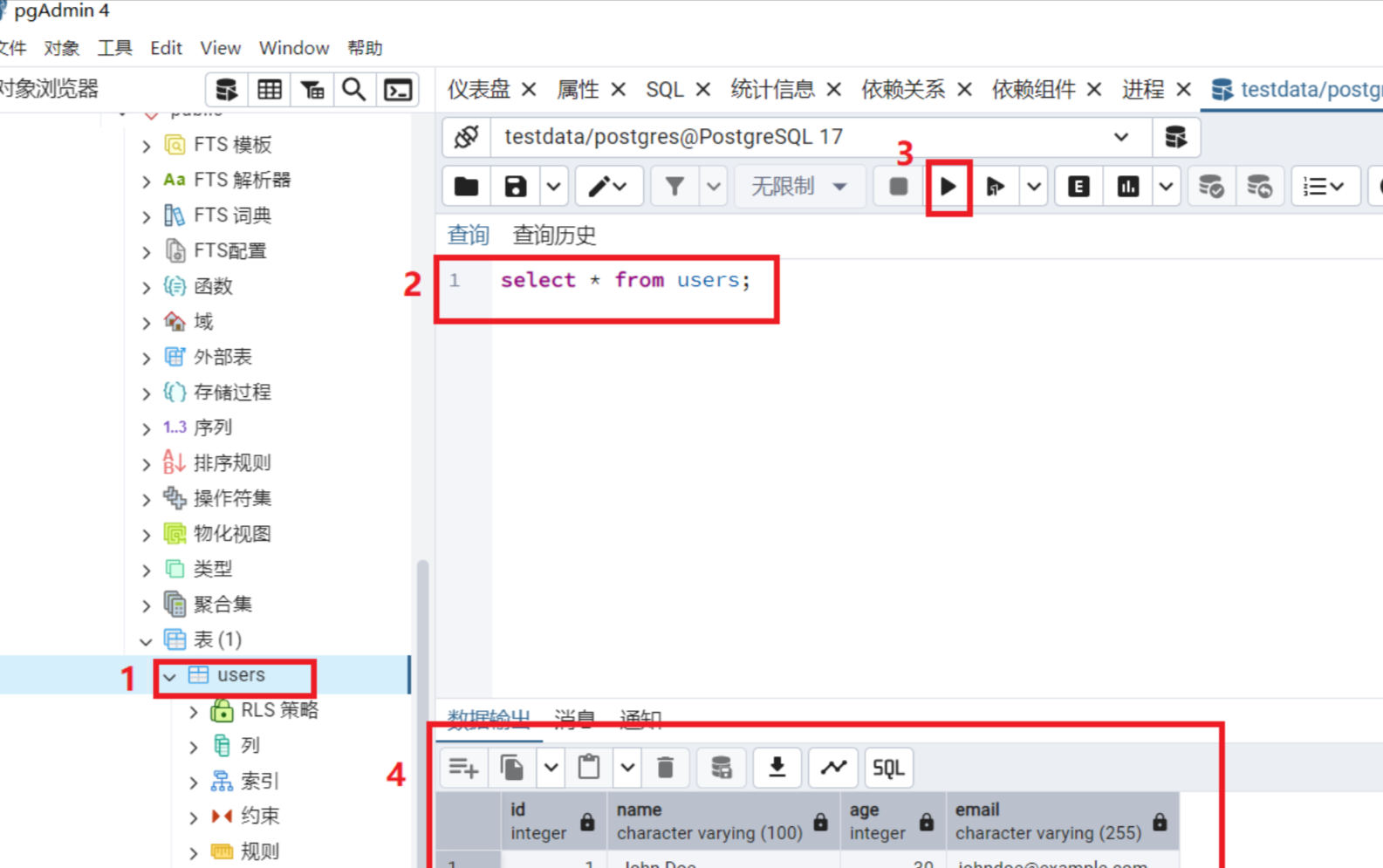
1.选中要执行的代码段:
用鼠标左键拖动选择其中一条查询
![文字图示:代码被蓝色高亮选中]
2.点击工具栏的 ▷ 执行 按钮,或按 F5
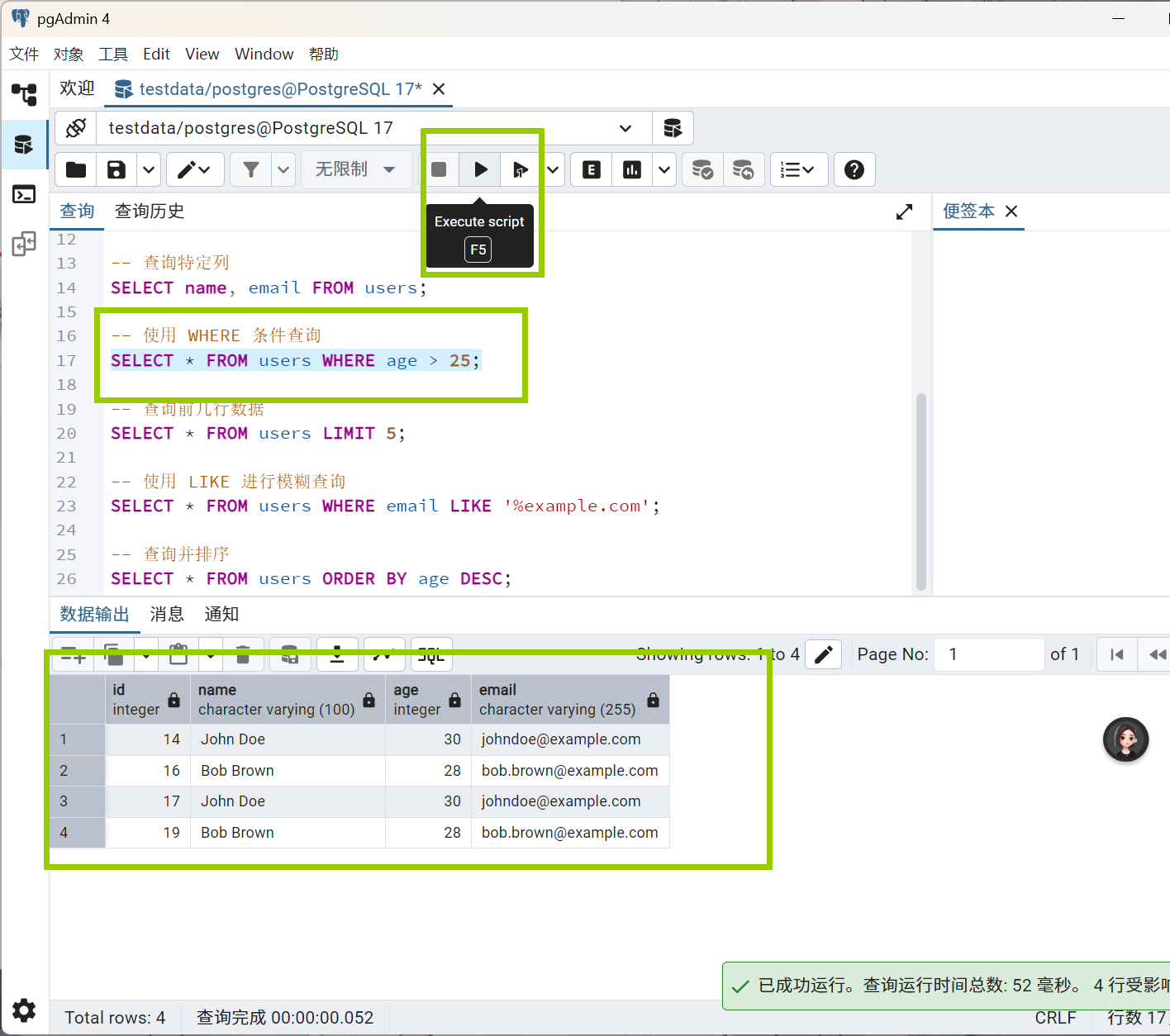
增删改查代码
- Create (插入数据)
插入数据使用 INSERT INTO 语句。假设我们有一个 users 表,其中包括 id、name、age 和 email 字段:
-- 插入单行数据
INSERT INTO users (name, age, email)
VALUES ('John Doe', 30, 'johndoe@example.com');
-- 插入多行数据
INSERT INTO users (name, age, email)
VALUES
('Alice Smith', 25, 'alice.smith@example.com'),
('Bob Brown', 28, 'bob.brown@example.com');- Read (查询数据)
查询数据使用 SELECT 语句。可以通过指定列名、条件等来进行查询。
-- 查询所有数据
SELECT * FROM users;
-- 查询特定列
SELECT name, email FROM users;
-- 使用 WHERE 条件查询
SELECT * FROM users WHERE age > 25;
-- 查询前几行数据
SELECT * FROM users LIMIT 5;
-- 使用 LIKE 进行模糊查询
SELECT * FROM users WHERE email LIKE '%example.com';
-- 查询并排序
SELECT * FROM users ORDER BY age DESC;- Update (更新数据)
更新数据使用 UPDATE 语句,通过 SET 设置字段的新值,并使用 WHERE 来指定需要更新的行。
-- 更新单行数据
UPDATE users
SET age = 31
WHERE name = 'John Doe';
-- 更新单行数据
UPDATE users
SET email = 'bob.brown@newdomain.com'
WHERE name = 'Bob Brown';
-- 使用条件更新多个字段
UPDATE users
SET age = 32, email = 'alice.smith@newdomain.com'
WHERE name = 'Alice Smith';
- Delete (删除数据)
删除数据使用 DELETE FROM 语句。使用 WHERE 进行条件删除,如果不加 WHERE,则会删除所有记录。
-- 删除单行数据
DELETE FROM users WHERE name = 'John Doe';
-- 删除多行数据
DELETE FROM users WHERE age < 30;
-- 删除所有数据
DELETE FROM users; -- 警告:如果没有 WHERE 条件,将删除所有数据!
这是链接管理,被链接的地方需要有库和数据
连接其他地方(这里了解,本地先不用)
SQL命令行增删改查
直接搜sql就行
常用元命令
| 命令 | 说明 | 示例输出片段 | ||
|
| 列出所有数据库 | `mydb \ | myuser \ | UTF8` |
|
| 切换数据库 |
| ||
|
| 列出当前数据库的所有表 | `public \ | users \ | table` |
|
| 查看表结构详情 | 列名、类型、约束等信息 | ||
|
| 退出 psql | - |
安装中出现的问题
如果连接不成功,则需要检查输入的服务器IP地址和密码是否正确,客户端电脑和服务器的防火墙设置是否正确。
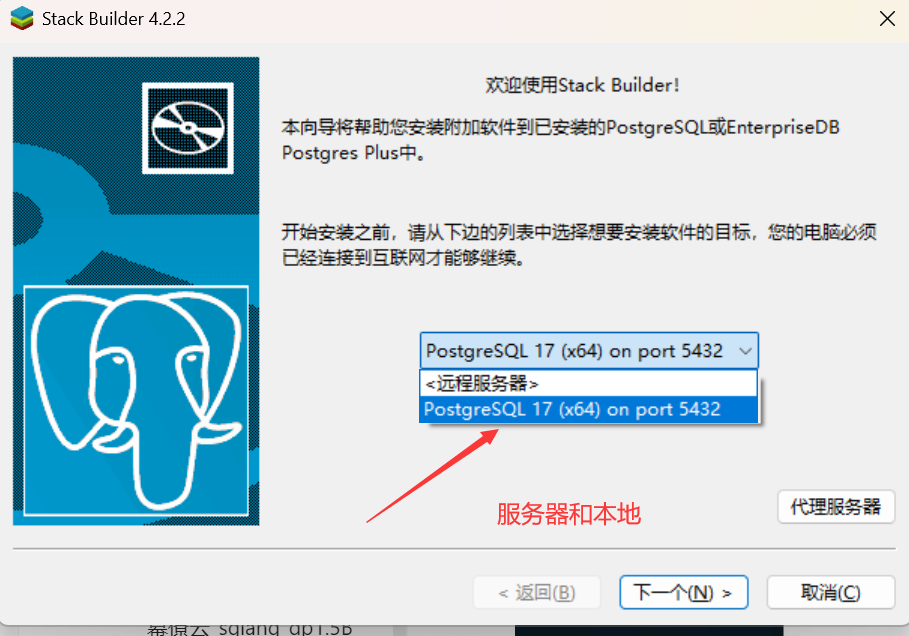
在图中界面的下拉菜单里,已显示找到的本地 PostgreSQL 17(x64)实例在 5432 端口 ,选中它。若要配置远程服务器,选择 “<远程服务器>” ,后续按提示输入远程服务器相关连接信息(地址、端口、认证信息等)。
设置代理(若需)
若网络环境需通过代理服务器访问互联网:
- 点击 “代理服务器” 按钮。
- 在弹出对话框,于 “http proxy” 或 “ftp proxy” 字段输入代理服务器 IP 地址和端口号 。目前 Stack Builder 模块多通过 http 代理传输,ftp 代理信息常被忽略。

然后选择自己需要安装的插件配置
安装过程中可能遇到的问题
可能有些朋友下载后找不到对应的Server服务,这是下载过程中出现了差错,我第一次也遇到了。
建议就是直接删掉,然后重新下载,不然是用不了的。
然后就是编码报错的问题了。
出现这个错误的原因可能是你电脑的登陆用户用的是中文需要改成英文。
pycharm连接postgreSQL
- 工具
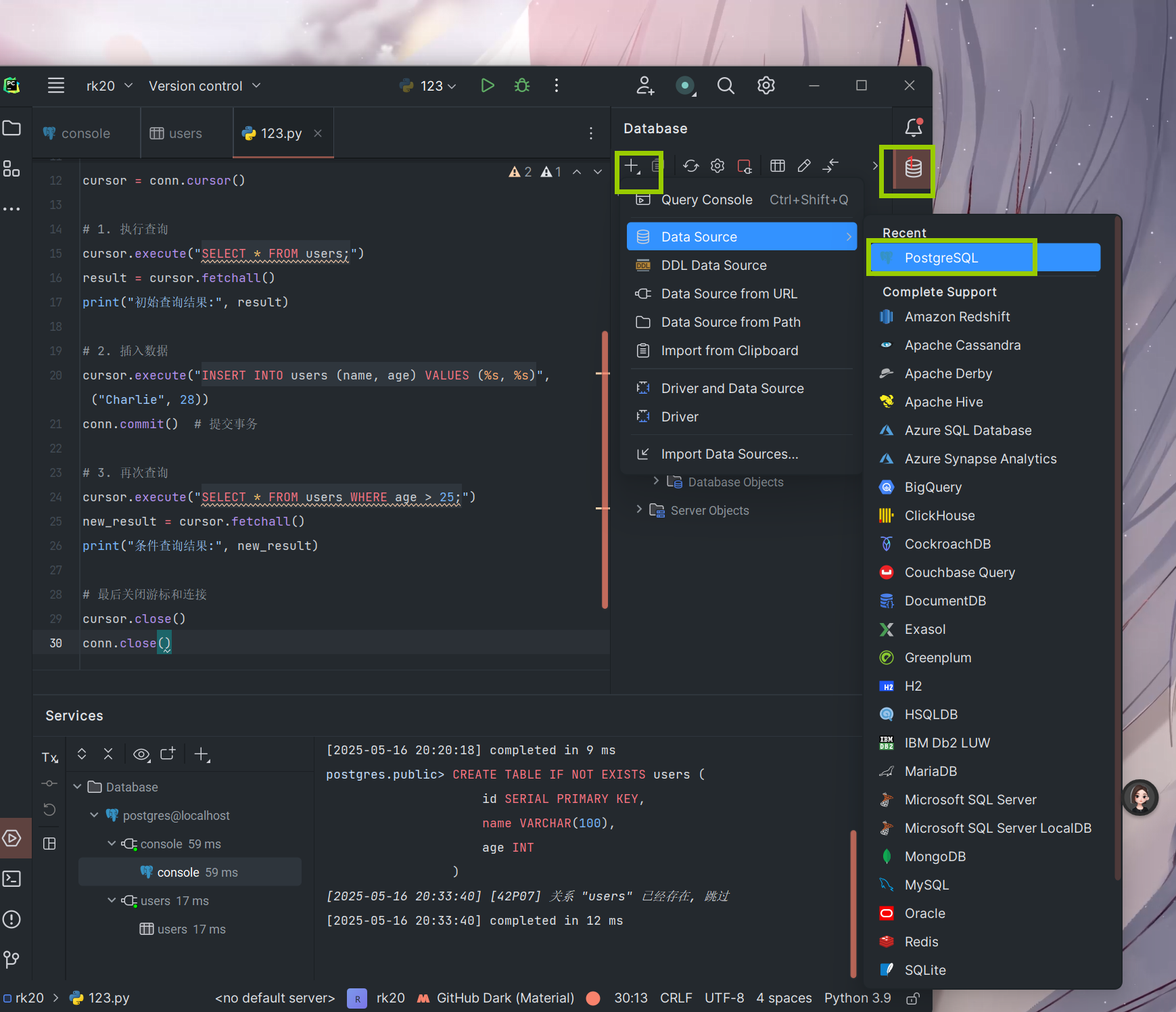
点击左下角的下载然后创建前可以测试
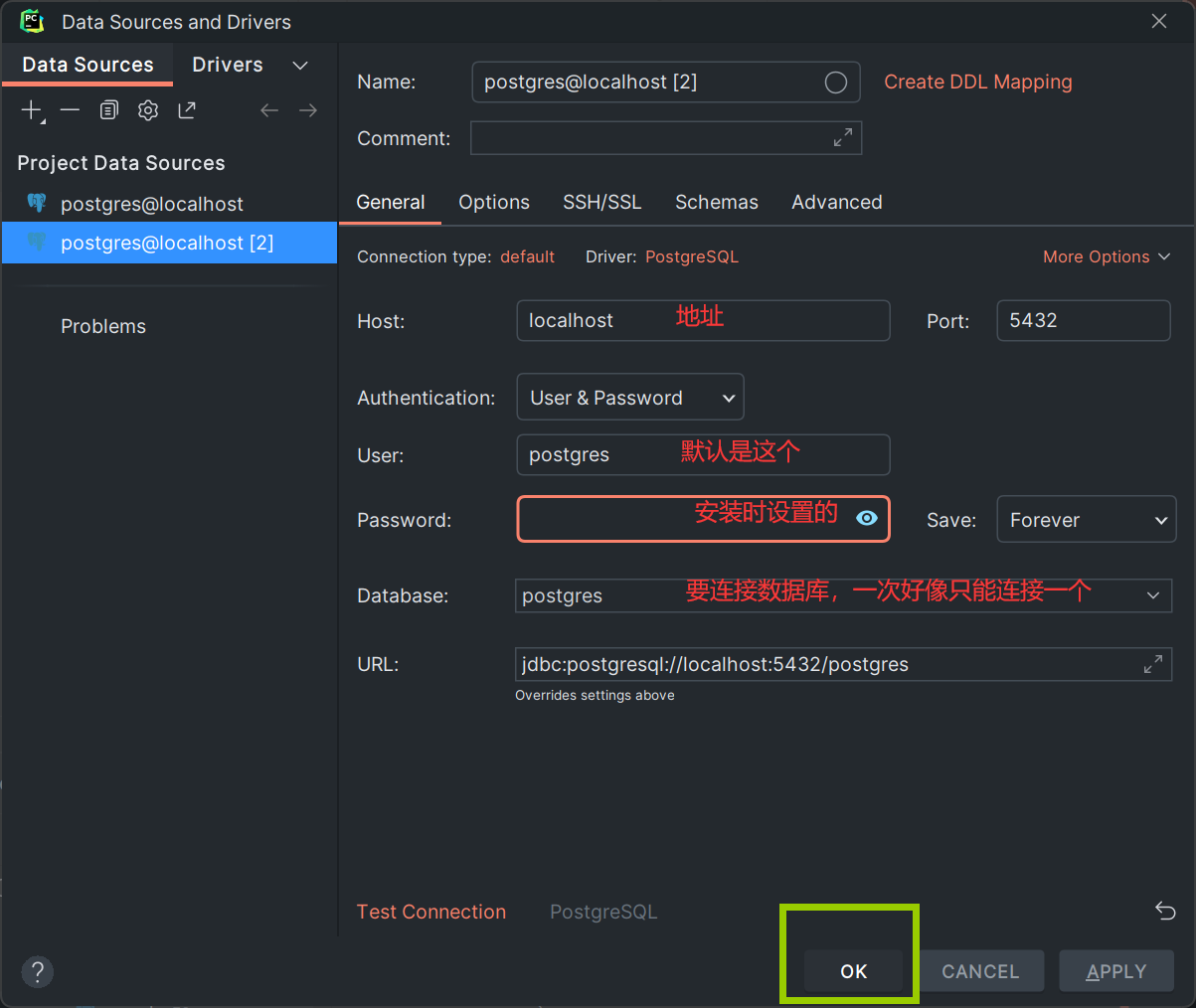
通过(PyCharm 的 Database 工具窗口或 Python 代码)连接数据库后,编写的 SQL 语法与 pgAdmin 中的语法完全一致。
如果想运行单步代码也是选中单亮块执行
CREATE TABLE IF NOT EXISTS users (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
age INT
);
INSERT INTO users (name, age) VALUES ('Charlie', 28);
SELECT * FROM users;- 代码
先下载这个包 pip install psycopg2
import psycopg2
# 连接数据库
conn = psycopg2.connect(
host="localhost",
port=5432,
dbname="postgres",
user="postgres",
password="root" # 确保密码正确
)
cursor = conn.cursor()
#
# 1. 执行查询
cursor.execute("SELECT * FROM users;")
result = cursor.fetchall()
print("初始查询结果:", result)
# 2. 插入数据
cursor.execute("INSERT INTO users (name, age) VALUES (%s, %s)", ("Charlie", 28))
conn.commit() # 提交事务
# 3. 再次查询
cursor.execute("SELECT * FROM users WHERE age > 25;")
new_result = cursor.fetchall()
print("条件查询结果:", new_result)
# 最后关闭游标和连接
cursor.close()
conn.close()psql指令大全
一、命令行工具(psql 之外)
| 命令 | 作用 | 示例 |
|
| 创建新数据库 |
|
|
| 删除数据库 |
|
|
| 导出数据库备份 |
|
|
| 导出所有数据库备份 |
|
|
| 从备份文件恢复数据库 |
|
|
| 控制 PostgreSQL 服务 |
|
|
| 初始化数据库集群(数据目录) |
|
|
| 进入交互式命令行工具 |
|
|
| 重建数据库索引 |
|
|
| 清理和分析数据库 |
|
二、SQL 常用命令
1. 数据库操作
| 命令 | 说明 | 示例 |
|
| 创建数据库 |
|
|
| 删除数据库 |
|
|
| 列出所有数据库(psql内) |
|
|
| 切换数据库(psql内) |
|
2. 表操作
| 命令 | 说明 | 示例 |
|
| 创建表 |
|
|
| 删除表 |
|
|
| 修改表结构 |
|
|
| 清空表数据 |
|
|
| 列出当前数据库所有表(psql内) |
|
3. 数据操作(DML)
| 命令 | 说明 | 示例 |
|
| 插入数据 |
|
|
| 查询数据 |
|
|
| 更新数据 |
|
|
| 删除数据 |
|
4. 索引与优化
| 命令 | 说明 | 示例 |
|
| 创建索引 |
|
|
| 分析查询执行计划 |
|
|
| 清理表空间 |
|
|
| 重建索引 |
|
5. 用户与权限
| 命令 | 说明 | 示例 |
|
| 创建用户 |
|
|
| 授权权限 |
|
|
| 撤销权限 |
|
|
| 修改用户属性 |
|
三、psql 内部快捷命令
| 命令 | 说明 | 示例 |
|
| 查看所有 psql 快捷命令 | - |
|
| 退出 psql | - |
|
| 列出表、视图、序列等 |
|
|
| 列出所有用户和角色 |
|
|
| 切换扩展显示模式(列转行) |
|
|
| 用默认编辑器编辑最后执行的 SQL | - |
|
| 执行外部 SQL 文件 |
|
|
| 显示查询执行时间 |
|
|
| 导入/导出 CSV 数据 |
|
四、备份与恢复
1. 逻辑备份
# 导出单个数据库
pg_dump -U user -d mydb -f mydb.sql
# 导出所有数据库
pg_dumpall -U postgres -f all.sql
# 导出为自定义格式(支持压缩)
pg_dump -Fc mydb > mydb.dump2. 物理备份
# 使用 pg_basebackup(需配置归档)
pg_basebackup -D /backup -Ft -z -U replicator3. 恢复
# 从 SQL 文件恢复
psql -U user -d newdb -f mydb.sql
# 从自定义格式恢复
pg_restore -U user -d newdb mydb.dump五、维护与监控
1. 服务管理
# 启动服务
pg_ctl start -D /data
# 停止服务
pg_ctl stop -D /data
# 重启服务
pg_ctl restart -D /data2. 日志分析
# 查看日志文件(默认路径)
tail -f /var/lib/postgresql/data/log/postgresql-*.log3. 性能监控
-- 查看活跃连接
SELECT * FROM pg_stat_activity;
-- 查看表大小
SELECT pg_size_pretty(pg_total_relation_size('users'));
-- 查看锁信息
SELECT * FROM pg_locks;六、高级功能
1. 扩展管理
-- 安装扩展(如 PostGIS)
CREATE EXTENSION postgis;
-- 列出已安装扩展
\dx2. 分区表
-- 创建分区表
CREATE TABLE logs (log_date DATE, message TEXT) PARTITION BY RANGE (log_date);3. 全文搜索
-- 创建全文搜索索引
CREATE INDEX idx_content_search ON articles USING GIN (to_tsvector('english', content));七、注意事项
- 权限安全:
-
- 避免使用超级用户(
postgres)运行日常操作。 - 限制用户权限(遵循最小权限原则)。
- 避免使用超级用户(
- 备份策略:
-
- 定期测试备份文件的恢复可行性。
- 结合物理备份和逻辑备份。
- 性能优化:
-
- 定期执行
VACUUM和ANALYZE。 - 使用
EXPLAIN分析慢查询。
- 定期执行
- 版本兼容性:
-
pg_dump备份文件可能不兼容跨大版本的 PostgreSQL。
掌握这些命令后,你将能高效管理 PostgreSQL 数据库!如需更详细说明,可查阅 PostgreSQL 官方文档。
和mysql的区别(事务概念)
MySQL 和 PostgreSQL 是两种广泛使用的关系型数据库管理系统(RDBMS),但它们在设计理念、功能支持和适用场景上有显著区别。以下是两者的主要差异:
1. 设计理念
- MySQL:
最初以 简单、高性能、易用 为目标,适合快速开发和读写密集型场景(如 Web 应用)。
早期版本对复杂查询的支持较弱,但后续版本(如 8.0+)逐步增强。 - PostgreSQL:
强调 标准兼容性、扩展性和数据完整性,支持复杂的查询和数据类型(如 JSON、GIS、自定义类型),适合复杂业务场景。
2. SQL 标准兼容性
- MySQL:
部分支持 SQL 标准(如早期版本不支持窗口函数、CTE),语法和功能偏向“实用主义”。
在 8.0+ 版本中逐步增强(如支持窗口函数、JSON 增强)。 - PostgreSQL:
高度兼容 SQL 标准(如窗口函数、CTE、OVER子句),支持更复杂的查询语法和功能。
3. 数据类型
- MySQL:
支持基础类型(如 INT、VARCHAR、JSON),但复杂类型有限。
JSON 类型支持查询,但性能不如 PostgreSQL 的 JSONB。 - PostgreSQL:
支持更丰富的原生类型(如数组、JSONB、UUID、范围类型、几何/GIS 类型),并允许用户自定义类型。
4. 事务与并发
- MySQL:
-
- 默认存储引擎 InnoDB 支持 ACID 事务和行级锁。
- 在高并发写入场景下可能因锁竞争导致性能下降。
- PostgreSQL:
-
- 通过 MVCC(多版本并发控制)实现高效并发,支持更复杂的锁机制。
- 写并发性能通常优于 MySQL,尤其是在高负载场景。
5. 扩展性
- MySQL:
-
- 扩展性较弱,主要依赖存储引擎(如 InnoDB、MyISAM)。
- 支持插件式架构,但自定义功能开发较复杂。
- PostgreSQL:
-
- 支持丰富的扩展(如 PostGIS、TimescaleDB、全文搜索)。
- 允许用多种语言(如 Python、PL/pgSQL)编写存储过程和函数。
- 支持部分索引、表达式索引等高级功能。
6. 复制与高可用
- MySQL:
-
- 主从复制(异步/半同步)、组复制(InnoDB Cluster)。
- 工具生态成熟(如 MHA、Orchestrator),适合传统主从架构。
- PostgreSQL:
-
- 流复制(物理复制)、逻辑复制、同步复制。
- 支持更灵活的复制拓扑(如级联复制),配合 Patroni、pgPool 等工具实现高可用。
7. 性能
- MySQL:
-
- 简单查询和读操作性能优异,适合 OLTP 场景(如电商、社交应用)。
- 对硬件资源要求较低。
- PostgreSQL:
-
- 复杂查询(如多表 JOIN、分析型查询)性能更好,适合 OLAP 混合场景。
- 对 CPU 和内存优化更高效。
8. 安全性
- MySQL:
-
- 提供基础权限管理(库、表、列级权限)。
- 支持 SSL 加密和审计插件。
- PostgreSQL:
-
- 更细粒度的权限控制(如行级安全策略、列级加密)。
- 支持 SELinux 集成和证书认证。
9. 许可证与生态
- MySQL:
-
- 采用 GPL 协议(社区版),商业版由 Oracle 提供。
- 广泛用于 Web 应用(如 LAMP 架构),社区庞大。
- PostgreSQL:
-
- 采用 BSD 协议,完全开源且无商业限制。
- 企业级应用和复杂场景更常见(如地理信息、金融系统)。
10. 适用场景
- 选择 MySQL:
-
- 需要快速开发、简单查询和高并发读操作。
- 典型场景:Web 应用、内容管理系统(如 WordPress)、小型 OLTP。
- 选择 PostgreSQL:
-
- 需要复杂查询、数据完整性、扩展性。
- 典型场景:企业级应用、地理信息系统(PostGIS)、数据分析、金融系统。
总结
| 特性 | MySQL | PostgreSQL |
| 设计目标 | 简单、高性能 | 标准兼容、扩展性强 |
| 复杂查询 | 一般(8.0+ 增强) | 优秀 |
| 数据类型 | 基础类型 | 丰富(JSONB、GIS、自定义类型) |
| 并发控制 | 行级锁 | MVCC(无锁读,高效写并发) |
| 扩展性 | 有限 | 极强(支持扩展、自定义函数) |
| 适用场景 | Web 应用、OLTP | 企业级应用、OLAP/OLTP 混合 |
最终选择建议:
- 如果追求 快速开发、简单架构,选 MySQL。
- 如果需求涉及 复杂逻辑、数据完整性或扩展性,选 PostgreSQL。
事务(Transaction) 是数据库管理系统(DBMS)中的一个核心概念,指 一组不可分割的数据库操作序列。这些操作要么全部成功执行,要么全部失败回滚,确保数据在并发操作和故障场景下的一致性。
事务的核心特性(ACID)
事务必须满足以下四个特性,简称 ACID:
- 原子性(Atomicity)
-
- 事务中的所有操作是一个整体,像原子一样不可分割。
- 要么全部成功(提交),要么全部失败(回滚)。
- 例如:转账操作中,A 账户扣款和 B 账户收款必须同时成功或同时取消。
- 一致性(Consistency)
-
- 事务执行前后,数据库必须保持逻辑一致性(如约束、触发器)。
- 例如:转账后,A 和 B 的账户总额应保持不变。
- 隔离性(Isolation)
-
- 多个并发事务执行时,互相不干扰,仿佛串行执行。
- 通过锁或 MVCC(多版本并发控制)实现。
- 例如:事务 A 修改数据时,事务 B 不能读到未提交的中间结果。
- 持久性(Durability)
-
- 事务一旦提交,结果永久保存,即使系统故障也不丢失。
- 例如:事务提交后,数据写入磁盘,断电后仍能恢复。
事务的典型应用场景
- 银行转账:扣款和收款必须同时生效。
- 订单支付:库存减少和订单生成需保持一致。
- 批量操作:多条数据插入/更新要么全部成功,要么全部失败。
事务的控制语句
在 SQL 中,通过以下命令控制事务:
| 命令 | 作用 |
|
| 开启一个事务。 |
|
| 提交事务,永久保存所有操作。 |
|
| 回滚事务,撤销所有未提交的操作。 |
|
| 在事务中设置保存点,允许部分回滚(如回滚到某个中间状态)。 |
示例(MySQL)
BEGIN; -- 开启事务
UPDATE accounts SET balance = balance - 100 WHERE user_id = 1; -- A 账户扣款
UPDATE accounts SET balance = balance + 100 WHERE user_id = 2; -- B 账户收款
COMMIT; -- 提交事务
-- 若发生错误,回滚:
ROLLBACK;事务的隔离级别
多个事务并发执行时,可能出现脏读、不可重复读、幻读等问题。数据库通过定义不同的 隔离级别 来平衡性能与一致性:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 性能 |
| 读未提交(Read Uncommitted) | ✔️ | ✔️ | ✔️ | 高 |
| 读已提交(Read Committed) | ❌ | ✔️ | ✔️ | 中 |
| 可重复读(Repeatable Read) | ❌ | ❌ | ✔️ | 中低 |
| 串行化(Serializable) | ❌ | ❌ | ❌ | 低 |
- MySQL 默认隔离级别:可重复读(Repeatable Read)。
- PostgreSQL 默认隔离级别:读已提交(Read Committed)。
为什么需要事务?
- 数据一致性:防止部分操作失败导致数据混乱(如转账只扣款未收款)。
- 故障恢复:系统崩溃时,未提交的事务自动回滚。
- 并发控制:协调多个用户同时操作同一数据,避免冲突。
常见问题
- 哪些数据库引擎支持事务?
-
- MySQL 的 InnoDB 支持事务,而 MyISAM 不支持。
- PostgreSQL 的所有操作默认在事务中执行。
- 事务会影响性能吗?
-
- 事务的锁机制和日志记录会带来额外开销,但通过合理设计隔离级别和事务范围可以优化。
- 何时使用显式事务?
-
- 当需要确保多个操作原子性时(如金融交易、订单处理)。
总结
事务是数据库保证数据一致性和可靠性的核心机制,通过 ACID 特性确保复杂操作的安全执行。在涉及资金、订单等关键业务时,事务是必不可少的工具。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









